
- 1SQL数据库三种删除方式_删除sql
- 2mybatis-plus实现多租户_mybatis-plus tenant_id
- 3李廉洋:4.5黄金原油会受非农影响有大数据吗?晚间走势分析及建议。
- 4组播调试工具_网管自研实战|城域网组播快速改造系统
- 5YOLOv8添加多种attention注意力机制_yolov8添加注意力机制
- 6基于Java+SpringBoot+Vue流浪猫狗救助救援系统设计和实现_流浪猫狗救助系统
- 7(附源码)计算机毕业设计SSM基于的二手房交易系统
- 8GitHub使用(1):鉴权失败/推送到远程仓库(TortoiseGit小乌龟操作)_ubuntu鉴权失败
- 9生鲜超市管理系统(JavaSSH)
- 10cmd打开当前文件所在目录,cmd进入当前文件目录,cmd进入指定目录
GitHub 热门:各大网站的 Python 爬虫登录汇总_爬虫github模拟登录
赞
踩
不论是自然语言处理还是计算机视觉,做机器学习算法总会存在数据不足的情况,而这个时候就需要我们用爬虫获取一些额外数据。这个项目介绍了如何用
Python 登录各大网站,并用简单的爬虫获取一些有用数据,目前该项目已经提供了知乎、B 站、和豆瓣等 18 个网站的登录方法。
收集了一些网站的登陆方式和爬虫程序,有的通过 selenium 登录,有的则通过抓包直接模拟登录。作者希望该项目能帮助初学者学习各大网站的模拟登陆方式,并爬取一些需要的数据。
作者表示模拟登陆基本采用直接登录或者使用 selenium+webdriver 的方式,有的网站直接登录难度很大,比如 qq 空间和 bilibili 等,采用 selenium 登录相对轻松一些。虽然在登录的时候采用的是 selenium,但为了效率,我们也可以在登录后维护得到的 cookie。登录后,我们就能调用 requests 或者 scrapy 等工具进行数据采集,这样数据采集的速度可以得到保证。
目前已经完成的网站有:
- 无需身份验证即可抓取 Twitter 前端 API
- 微博网页版
- 知乎
- QQZone
- CSDN
- 淘宝
- Baidu
- 果壳
- JingDong 模拟登录和自动申请京东试用
- 163mail
- 拉钩
- Bilibili
- 豆瓣
- Baidu2
- 猎聘网
- 微信网页版登录并获取好友列表
- Github
- 爬取图虫相应的图片
如下所示,如果我们满足依赖项,那么就可以直接运行代码,它会在图虫网站中下载搜索到的图像。
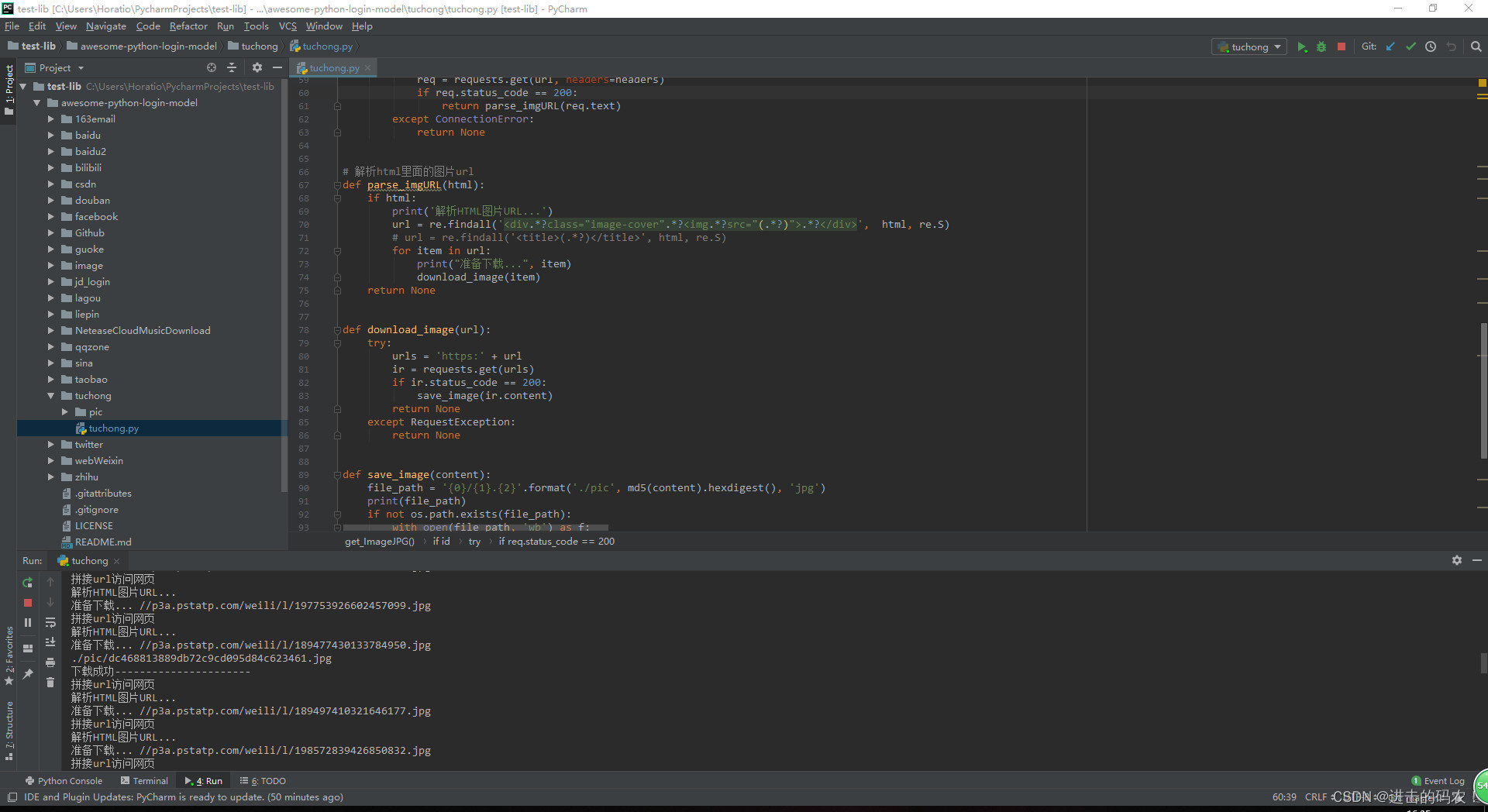 如下所示为搜索「秋天」,并完成下载的图像:
如下所示为搜索「秋天」,并完成下载的图像:

每一个网站都会有对应的登录代码,有的还有数据的爬取代码。以豆瓣为例,主要的登录函数如下所示,它会获取验证码、处理验证码、返回登录数据完成登录,并最后保留 cookies。
def login():
captcha, captcha_id = get_captcha()
# 增加表数据
datas['captcha-solution'] = captcha
datas['captcha-id'] = captcha_id
login_page = session.post(url, data=datas, headers=headers)
page = login_page.text
soup = BeautifulSoup(page, "html.parser")
result = soup.findAll('div', attrs={'class': 'title'})
#进入豆瓣登陆后页面,打印热门内容
for item in result:
print(item.find('a').get_text())
# 保存 cookies 到文件,
# 下次可以使用 cookie 直接登录,不需要输入账号和密码
session.cookies.save()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
其中获取并解决验证码的函数如下:
def get_captcha(): ''' 获取验证码及其ID ''' r = requests.post(url, data=datas, headers=headers) page = r.text soup = BeautifulSoup(page, "html.parser") # 利用bs4获得验证码图片地址 img_src = soup.find('img', {'id': 'captcha_image'}).get('src') urlretrieve(img_src, 'captcha.jpg') try: im = Image.open('captcha.jpg') im.show() im.close() except: print('到本地目录打开captcha.jpg获取验证码') finally: captcha = input('please input the captcha:') remove('captcha.jpg') captcha_id = soup.find( 'input', {'type': 'hidden', 'name': 'captcha-id'}).get('value') return captcha, captcha_id

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
当然这些都是简单的演示,在 GitHub 项目中可以找到更多的示例。此外,作者表明由于网站策略或者样式改变而导致代码失效,我们也可以提 Issue 或 Pull Requests。最后,该项目未来还会一直维护,很多东西哦也会慢慢改进,项目作者表明:
项目写了一段时间后,发现代码风格、程序易用性、可扩展性、代码的可读性,都存在一定的问题,所以接下来最重要的是重构代码,让大家可以更容易的做出一些自己的小功能;
如果读者觉得某个网站的登录很有代表性,可以在项目 issue 中提出;
网站的登录机制有可能经常的变动,所以当现在的模拟的登录的规则不能使用的时候,请项目在 issue 中提出。
最后:关于Python技术储备
学好 Python 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、Python必备开发工具

三、精品Python学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。
五、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、Python练习题
检查学习结果。

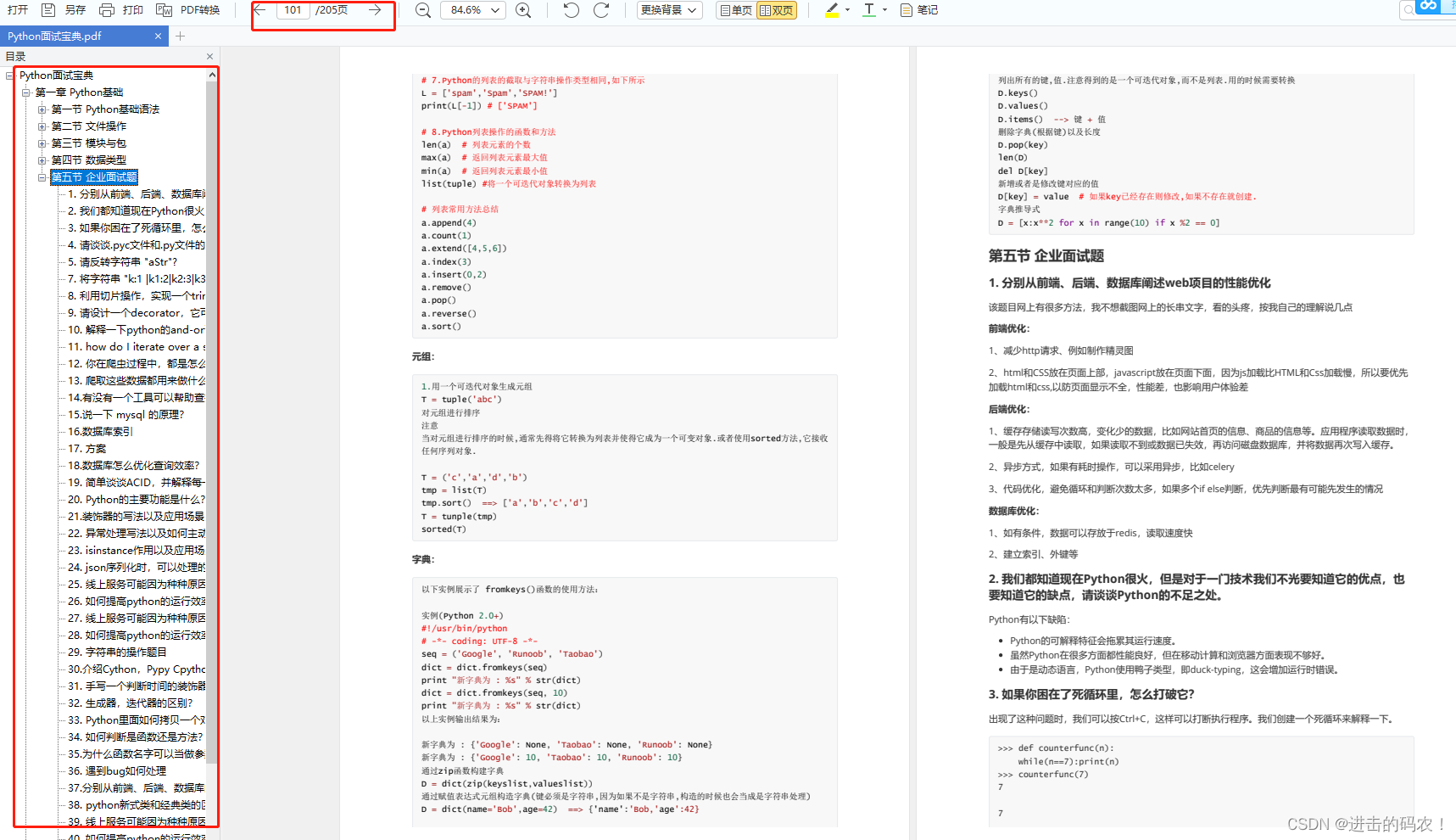
七、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。

最后,千万别辜负自己当时开始的一腔热血,一起变强大变优秀。


