
- 1Project ‘org.springframework.boot:spring-boot-starter-parent:2.6.3‘ not found
- 2Bugku CTF---where is flag_bugku where is flag
- 3Android Studio查看第三方库依赖树_android studio 依赖树
- 4用java写一个多线程异步批量入库_大量数据入库需要多线程异步吗
- 5JAVA面试题分享一百六十四:消息堆积如何解決?_消息太多处理不过来javaweb处理方式
- 6前端安全——最新,网络安全学习路线
- 7开源软件的未来发展趋势与应对新挑战和机遇
- 8【华为OD机试真题 Golang语言】159、星际篮球争霸赛 | 机试真题+思路参考+代码解析
- 9文件跨国传输,不止是快!_跨国传输文件网盘
- 102020人工神经网络第一次作业-参考答案第四部分_验证下图所示的神经网络描述了或逻辑关系,
python爬携程景区评论_python爬取携程景点评论信息
赞
踩
python爬取携程景点评论信息
今天要分析的网站是携程网,获取景点的用户评论,评论信息通过json返回API,页面是这个样子的
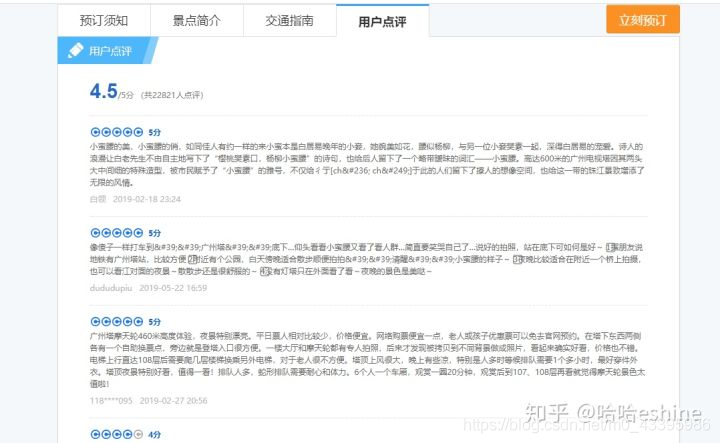
按下F12之后,F5刷新一下
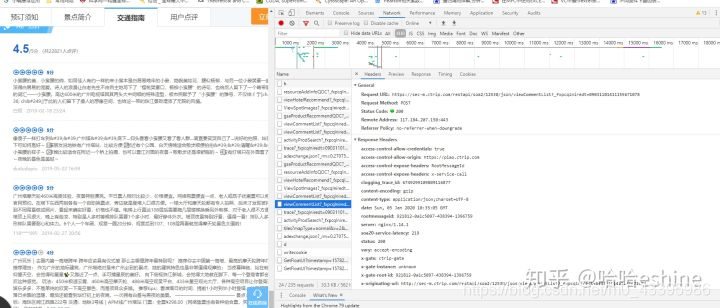
具体需要URL
Request的方式为POST,还需要你提取的哪一页,下面图片显示了页面id,景点id(viewid),pagenum页面数,pagesize页面的项数等等。

最基本的GET请求可以直接用post方法
response = requests.post(“http://www.baidu.com/”, data = data)
对于 POST 请求来说,我们一般需要为它增加一些参数。那么最基本的传参方法可以利用 data 这个参数。
综上所述post的第一个参数URL=‘https://sec-m.ctrip.com/restapi/soa2/12530/json/viewCommentList’
data={
“pageid”: “10650000804”,
“viewid”: 107540,
“tagid”: “0”,
“pagenum”: “1”,
“pagesize”: “50”,
“contentType”: “json”,
“SortType”:“1”,
“head”: {
“appid”: “100013776”,
“cid”: “09031037211035410190”,
“ctok”: “”,
“cver”: “1.0”,
“lang”: “01”,
“sid”: “8888”,
“syscode”: “09”,
“auth”: “”,
“extension”: [
{
“name”: “protocal”,
“value”: “https”
}
]
},
“ver”: “7.10.3.0319180000”
}
因此
html=requests.post(URL,data=json.dumps(data)).text
html=json.loads(html)
部分结果如下
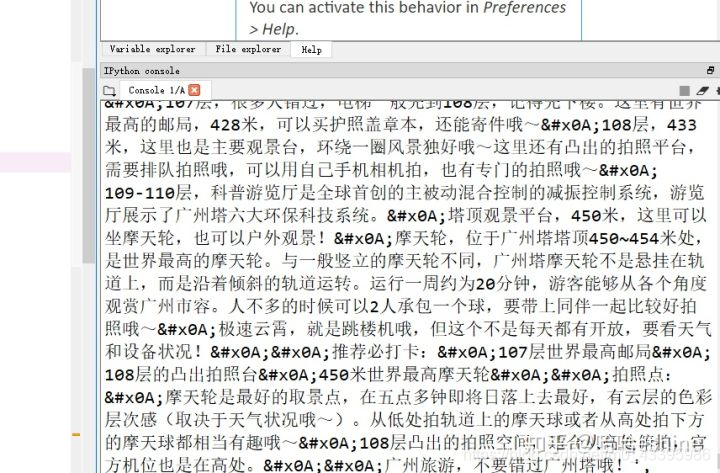
处理json文件后可以得到如下结果
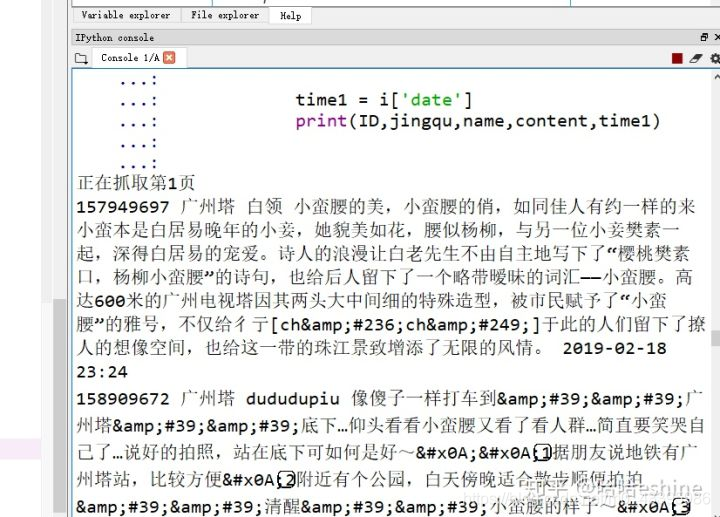
详细代码在我的GitHub中 https://github.com/eshinesimida/ctrip/blob/master/ctrip_comment.py
详细视频在我的哔哩哔哩上 python携程用户评论信息爬取_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili

