
- 1Android Studio开发学习(二)———修改主题颜色、应用名称和应用图标_2023版本android studio 如何更改themes里面的文件
- 2机器学习简史及发展趋势预测_机器学习的发展史
- 3android实用技巧系列之顶部输入框的实现_android 输入框上方布局
- 4Android Permission介绍_android:permission
- 5AI 绘画Stable Diffusion 研究(九)sd图生图功能详解-老照片高清修复放大
- 6【新版】系统架构设计师 - 案例分析 - 架构设计<SOA与微服务>_系统架构设计师案例
- 7机器学习笔记——决策树(Decision Tree)_决策树的时间空间复杂度
- 82023,你还在做公众号吗?_2023公众号出路
- 9SVR,时间序列分析的评价指标,python数据标准化_python中 svr预测怎么查看误差
- 10图解NLP模型发展:从RNN到Transformer
NLP八股
赞
踩
I. 模型通用
1.隐藏层/全连接层/输出层/Dropout层/池化层/残差
问:解释并推导如何在神经网络中使用Dropout技术来防止过拟合,并给出其数学表达式。
答:Dropout是一种减少神经网络过拟合的技术,通过在训练过程中随机“丢弃”(即将输出设为0)一些神经元。对于某一层的输出 ,应用 Dropout 后的输出为: 其中 表示元素乘法, 是一个随机向量,其元素独立地从 分布中采样得到,p是保留神经元的概率。这样,每次前向传播时,网络的一部分神经元不参与计算,减少了复杂的共适应关系,增强了模型的泛化能力。
1.1 隐藏层

1.2 池化层
整个图像中的这种“卷积”会产生大量的信息,这可能会很快成为一个计算噩梦。进入池化层,可将其全部缩小成更通用和可消化的形式。有很多方法可以解决这个问题,但最受欢迎的是“最大池”(Max Pooling),它将每个特征图编辑成自己的“读者文摘”版本,因此只有红色、茎或曲线的最好样本被表征出来。
在车库春季清理的例子中,如果我们使用著名的日本清理大师 Marie Kondo 的原则,将不得不从每个类别堆中较小的收藏夹里选择“激发喜悦”的东西,然后卖掉或处理掉其他东西。 所以现在我们仍然按照物品类型来分类,但只包括实际想要保留的物品。其他一切都卖了。
这时,神经网络的设计师可以堆叠这一分类的后续分层配置——卷积、激活、池化——并且继续过滤图像以获得更高级别的信息。在识别图片中的苹果时,图像被一遍又一遍地过滤,初始层仅显示边缘的几乎不可辨别的部分,比如红色的一部分或仅仅是茎的尖端,而随后的更多的过滤层将显示整个苹果。无论哪种方式,当开始获取结果时,完全连接层就会起作用
2.损失函数 /目标函数(训练) vs 评估函数(验证)
2.1.交叉熵损失

2.2.反向传播 — 链式法则 — 复合函数求导
问:解释和推导基于梯度的学习算法中的反向传播算法。
答:反向传播算法用于计算神经网络中的梯度,以便通过梯度下降法更新权重。对于具有L层的网络,给定损失函数L,对于第l层的权重 ,梯度通过链式法则计算: 其中, 是第l层的输出。反向传播算法首先计算损失函数相对于输出层激活的梯度,然后从输出层到输入层反向计算每层权重的梯度。这些梯度随后用于更新网络的权重,以最小化损失函数。
2.3.Metric
NLP模型的性能评估方法依赖于特定任务,常用的指标包括准确率、召回率、F1分数和BLEU分数(用于机器翻译)。此外,针对特定任务可能还会使用更专门的评估指标
3.正则项-范数-L1,L2区别 —— 损失函数惩罚项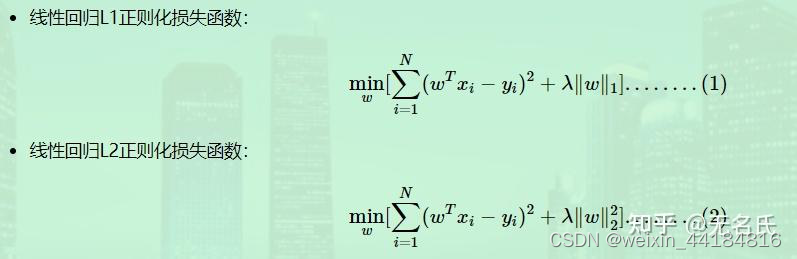
L1正则化容易得到稀疏解,即稀疏权值矩阵,L2正则化容易得到平滑解
因此L1范数也被叫做稀疏规则算子。 通过L1可以实现特征的稀疏,去掉一些没有信息的特征,从而方便提取特征。
L2范数通常会被用来做优化目标函数的正则化项,防止模型为了迎合训练集而过于复杂造成过拟合的情况,从而提高模型的泛化能力
L1和L2正则先验分别服从什么分布,L1是拉普拉斯分布,L2是高斯分布
4.激活函数
激活函数是向神经网络中引入非线性因素,通过激活函数神经网络就可以拟合各种曲线。激活函数主要分为饱和激活函数(Saturated Neurons)和非饱和函数(One-sided Saturations)
Sigmoid和Tanh是饱和激活函数,而ReLU以及其变种为非饱和激活函数。非饱和激活函数主要有如下优势:
1.非饱和激活函数可以解决梯度消失问题。
2.非饱和激活函数可以加速收敛
如何选择激活函数
1.除非在二分类问题中,否则请小心使用Sigmoid函数。
2.可以试试Tanh,不过大多数情况下它的效果会比不上 ReLU 和 Maxout。
3.如果你不知道应该使用哪个激活函数, 那么请优先选择ReLU。
4.如果你使用了ReLU, 需要注意一下Dead ReLU问题, 此时你需要仔细选择 Learning rate, 避免出现大的梯度从而导致过多的神经元 “Dead” 。
5.如果发生了Dead ReLU问题, 可以尝试一下leaky ReLU,ELU等ReLU变体, 说不定会有很好效果。
**实例:**比如LSTM用到Tanh,Transfromer中用到的ReLU,Bert中的GeLU,YOLO的Leaky ReLU
4.1.sigmoid,转化为0-1区间
![]()
求导方便 y’ =d sigmoid(x)/d(x) = y(1-y)
在反向传播中,容易就会出现梯度消失,无法完成深层网络的训练
4.2.tanh,转化为-1到1区间
![]()
4.3.relu,
4.4.softmax 函数/ 层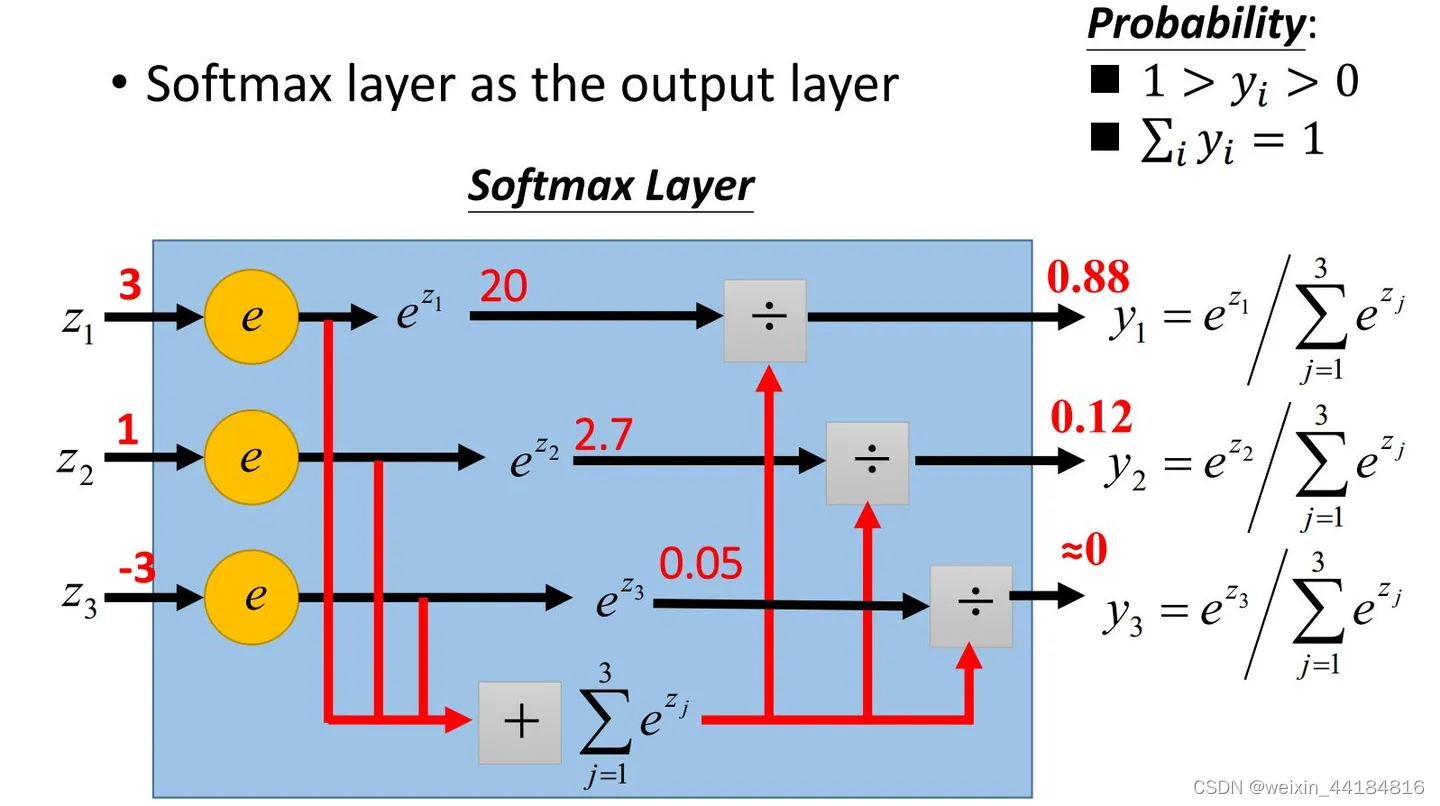
sigmoid的导数,只有在0附近,具有较好的激活性,而在正负饱和区的梯度都接近于0,会造成梯度弥散/梯度消失;而relu的导数,在大于0时,梯度为常数,不会导致梯度弥散。
relu函数在负半区的导数为0 ,当神经元激活值进入负半区,梯度就会为0,也就是说,这个神经元不会被训练,即稀疏性;
relu函数的导数计算更快,程序实现就是一个if-else语句;而sigmoid函数要进行浮点四则运算,涉及到除法
在神经网络中,隐含层的激活函数,最好选择ReLU
5.优化器-优化算法- 优化函数
SGD -> SGDM -> NAG/SGD with Nesterov Acceleration->AdaGrad -> AdaDelta/RMSProp -> Adam -> Nadam
梯度,梯度一阶导,梯度二阶导,下降梯度
速度,加速度,加加速度
方向,转向,转向快慢
5.1.SGD
最大的缺点是下降速度慢,而且可能会在沟壑的两边持续震荡,停留在一个局部最优点
5.2.SGDM

5.3.AdaGrad - 二阶动量,自适应学习率 - vt由过去所有梯度计算

5.4.AdaDelta/RMSProp - 二阶动量修改 - vt只用上一个vt-1和当前gt计算
5.5.Adam
6.Batch Normalization - 批量标准化/归一化
Conv=>BN=>ReLU=>dropout=>Conv
6.1 BN本质上是解决传播过程中的梯度消失问题,归一化是一种在深度神经网络中常用的技术,用于稳定和加速训练
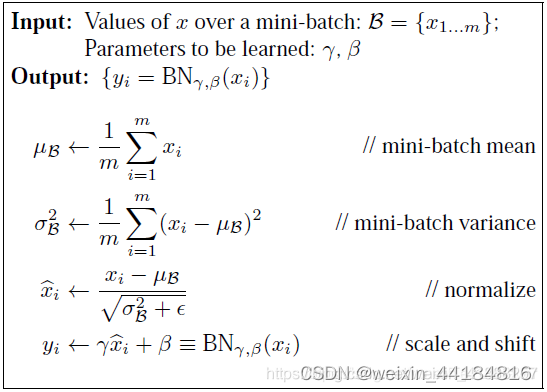
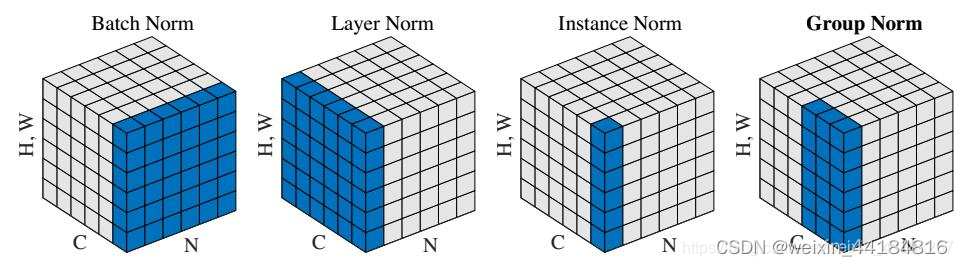
5.2层归一化(Layer Normalization)的数学原理及其作用。
7.过拟合 vs 欠拟合
降低欠拟合:增加特征维度、组合特征、使用非线性模型、
降低过拟合:降低模型复杂度、数据增强、正则化、dropout、早停、清洗异常数据、使用集成方法提高泛化能力、批量正则化/BN
8.梯度消失 vs 梯度爆炸
- 预训练与微调:最开始通过高斯分布随机初始化网络参数,然后逐层地优化网络参数,固定某一层的上一层,并将下一层的节点个数调整成上一层的个数(单隐藏层的自编码器),只训练输入权重矩阵。逐层结束后进行整体微调。
- 梯度剪切与权重正则化:针对梯度爆炸,可以设置一个梯度剪切阈值,当梯度超过这个阈值就进行剪切。权重正则化就是在损失函数中加上网络权重的正则化项,防止权重过大,可以限制梯度爆炸的产生。
- ReLU、LeakReLU、elu等激活函数
- BatchNormalization
- 残差结构
- LSTM
- 残差网络的作用
II. 基础模型
1.Linear
2.LR
2.1 表达式:

2.2 损失函数 — 交叉熵/似然函数

2.3 正则化衍生
L1, lasso
L2,Ridge
2.4 对比
与线性模型
逻辑回归是在线性回归的基础上加了一个 Sigmoid 函数(非线形)映射,使得逻辑回归称为了一个优秀的分类算法。本质上来说,两者都属于广义线性模型,但他们两个要解决的问题不一样,逻辑回归解决的是分类问题,输出的是离散值,线性回归解决的是回归问题,输出的连续值。
我们需要明确 Sigmoid 函数到底起了什么作用:
- 线性回归是在实数域范围内进行预测,而分类范围则需要在 [0,1],逻辑回归减少了预测范围;
- 线性回归在实数域上敏感度一致,而逻辑回归在 0 附近敏感,在远离 0 点位置不敏感,这个的好处就是模型更加关注分类边界,可以增加模型的鲁棒性
与朴素贝叶斯
朴素贝叶斯和逻辑回归都属于分类模型,当朴素贝叶斯的条件概率 服从高斯分布时,它计算出来的 P(Y=1|X) 形式跟逻辑回归是一样的。
两个模型不同的地方在于:
- 逻辑回归是判别式模型 p(y|x),朴素贝叶斯是生成式模型 p(x,y):判别式模型估计的是条件概率分布,给定观测变量 x 和目标变量 y 的条件模型,由数据直接学习决策函数 y=f(x) 或者条件概率分布 P(y|x) 作为预测的模型。判别方法关心的是对于给定的输入 x,应该预测什么样的输出 y;而生成式模型估计的是联合概率分布,基本思想是首先建立样本的联合概率概率密度模型 P(x,y),然后再得到后验概率 P(y|x),再利用它进行分类,生成式更关心的是对于给定输入 x 和输出 y 的生成关系;
- 朴素贝叶斯的前提是条件独立,每个特征权重独立,所以如果数据不符合这个情况,朴素贝叶斯的分类表现就没逻辑会好了
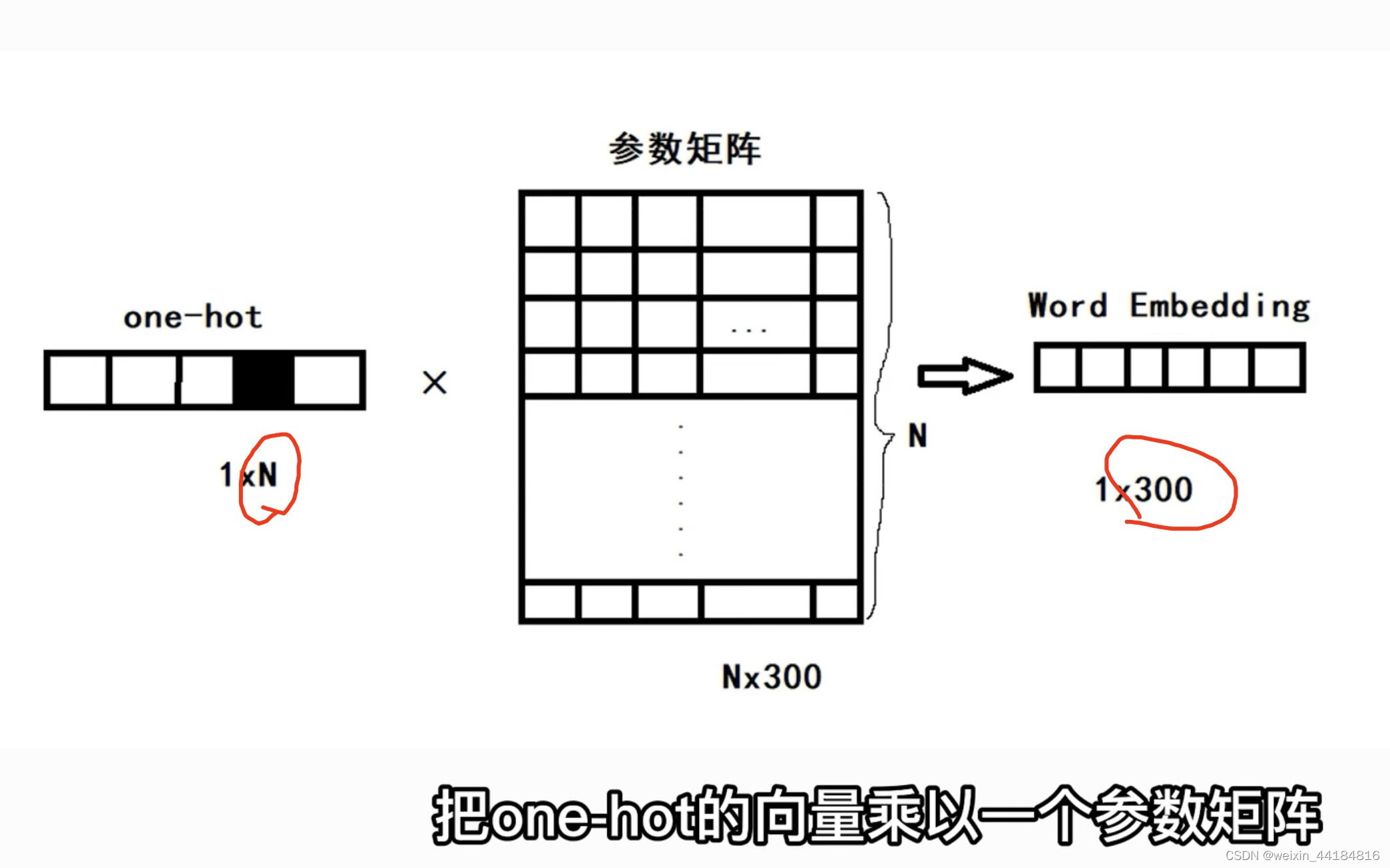
3. 词嵌入 Word2Vec/ Glove/Elmo/Bert
nlp中的词向量对比:word2vec/glove/fastText/elmo/GPT/bert
One-hot
CBOW 上下文去预测一个词的向量
Skip-Gram 一个词去预测上下文
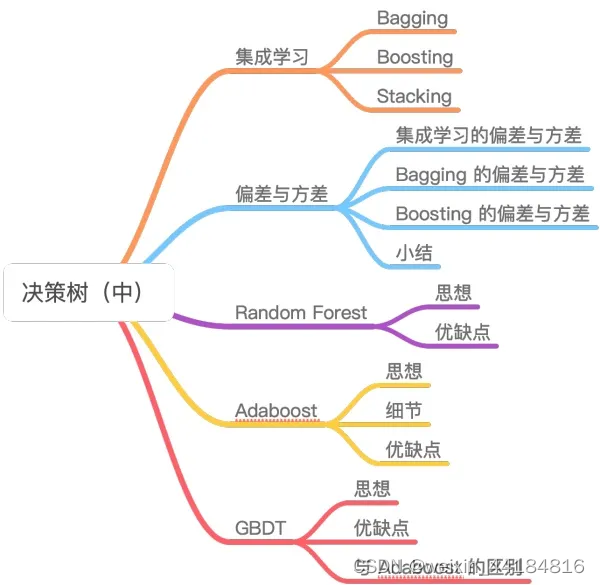
4.XGBoost — 决策树
bagging/boosting
放回,不放回采样
【机器学习】决策树(下)——XGBoost、LightGBM(非常详细) - 知乎
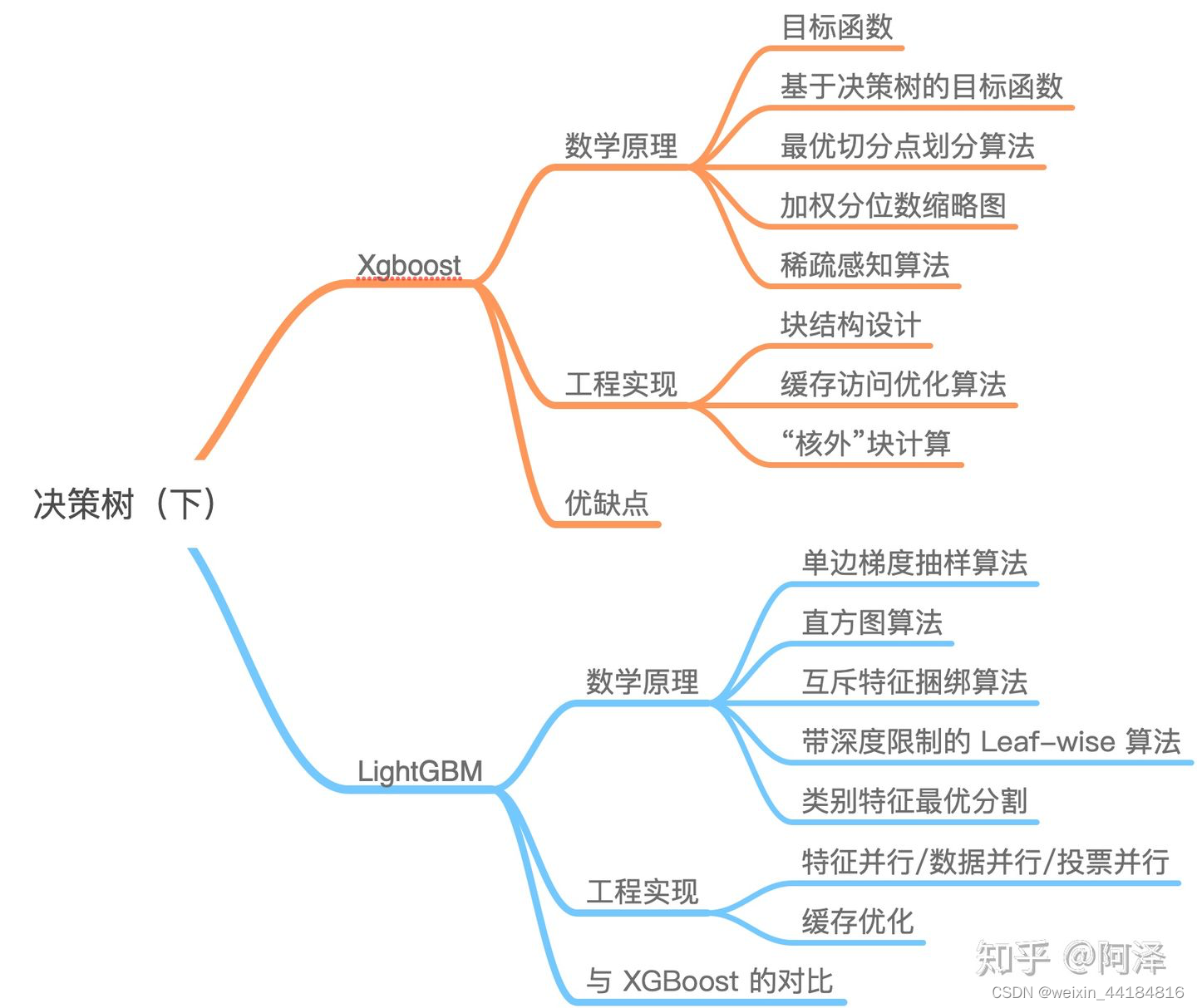
LightGBM
5.LSTM
RNN升级,因为RNN的记忆能力太弱,
简化LSTM得到GRU,只有两个门
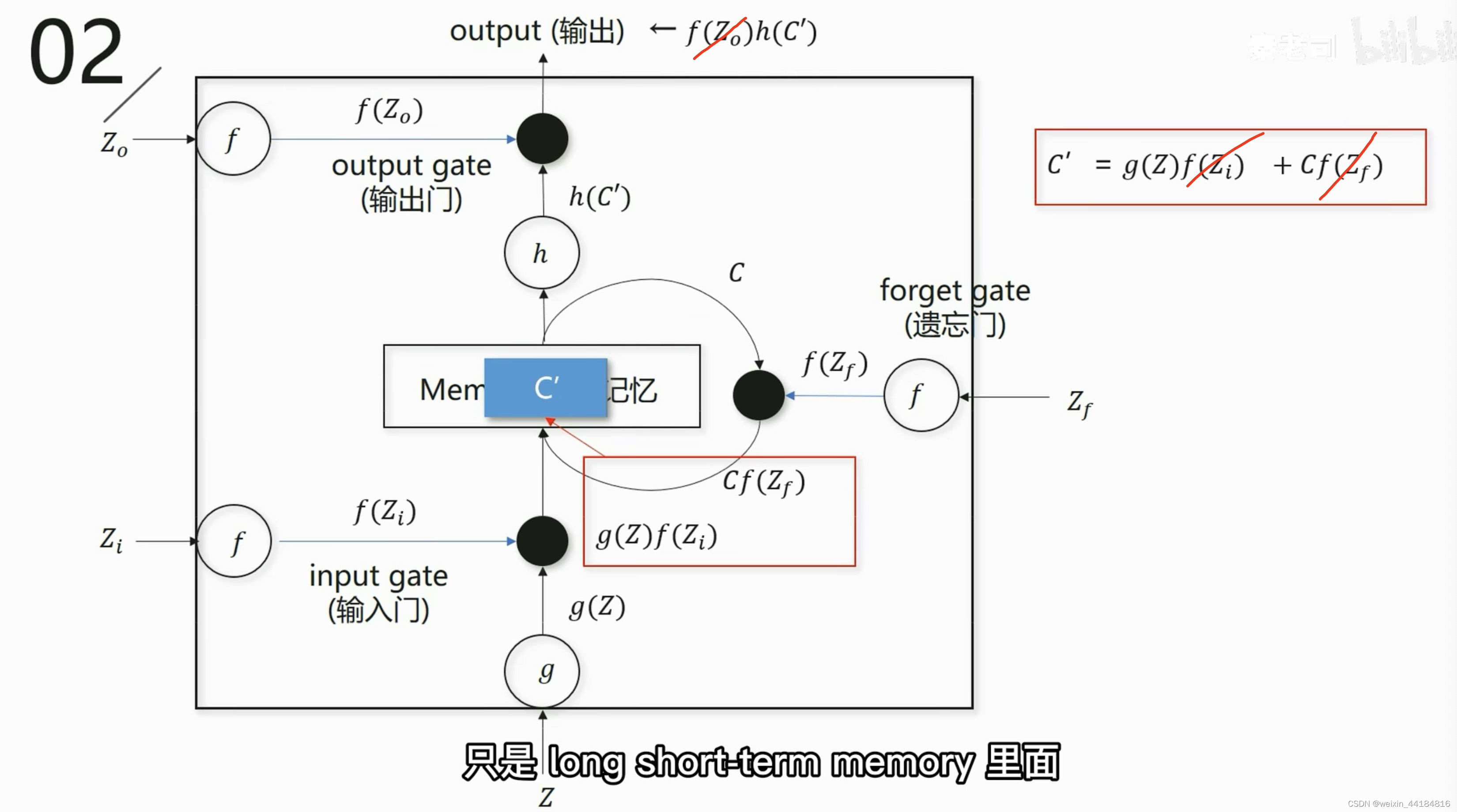
5.1 3个门:
输入门,遗忘门/记忆体,输出门
sigmoid函数用作激活函数,引入非线性,控制门的开闭程度,让信号的输出值保持[0,1]之间
5.2 图解与公式
C_t = g(Z)f(Zi) + C_t-1 f(Zf)
输入门结果 + 遗忘门结果 == memory结果 Ct
== 下一个遗忘门的输入 == 下一个节点输入门的输入
output = f(Zo) h(C_t)
输出门结果 == 下一个节点输入门的输入
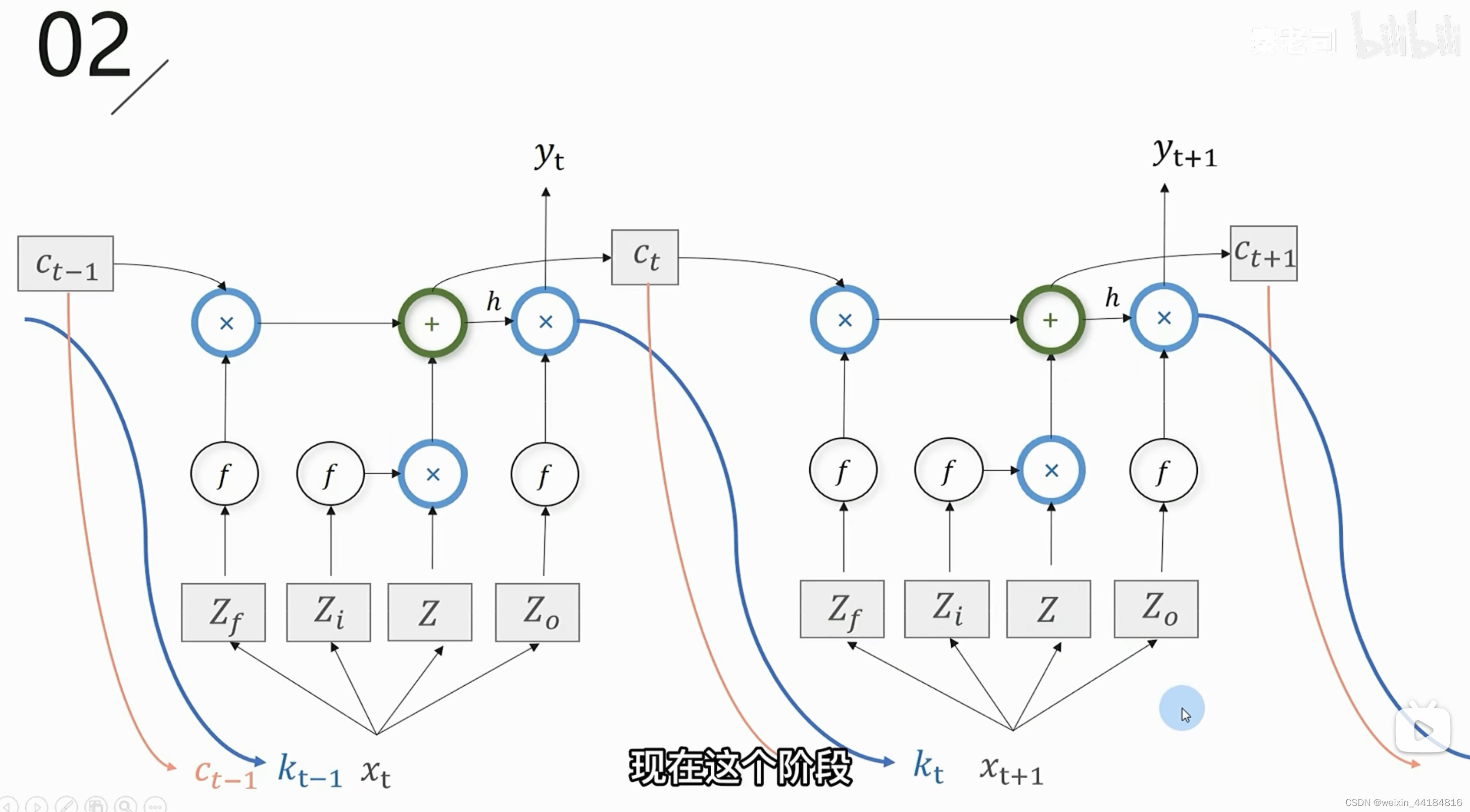
5.3 三个输入
C_t == == 输出门之前的结果 == 记忆体 memory结果复用
K_t == output == y_t == 即是输出也是输入
X_t+1
5.4 RNN的梯度消失与爆炸
记不住靠前的信息,
III. Transformer系列
1.(自)注意力机制 Self-Attention层
1.问:在自注意力机制中,如何计算注意力权重,并解释它如何允许模型捕捉长距离依赖?
答:自注意力机制通过计算序列中每个元素对于其他所有元素的注意力权重来工作。给定一个序列的表示 ,注意力权重 表示位置j的元素对位置i的元素的重要性,通过下式计算: 其中, 是一个打分函数,常见的有点积和加性注意力。通过这种方式,模型能够在生成每个元素的表示时,考虑到与其它所有元素的关系,无论它们在序列中的位置如何,从而允许模型捕捉长距离依赖。
2. 问:解释并推导Transformer模型中多头注意力的数学原理。
答:在Transformer中,多头注意力通过并行运行k个独立的自注意力层(称为“头”)来工作,然后将它们的输出拼接起来,最后通过一个线性层。给定输入\mathbf{X},每个头h的输出为: 其中, 分别是对应于每个头的查询、键、值的投影矩阵。然后,多头的输出拼接后通过一个线性层: 其中, 是另一个线性层的参数。这样,每个头可以学习到不同的表示子空间中的特征,从而提高模型的表达能力
1.词性标注,分词
根据上下文信息,区分是动词还是名词,
有时需要小窗口,简化运算,有时需要大窗口
每个单词的分类结果,都包含整句话的信息,
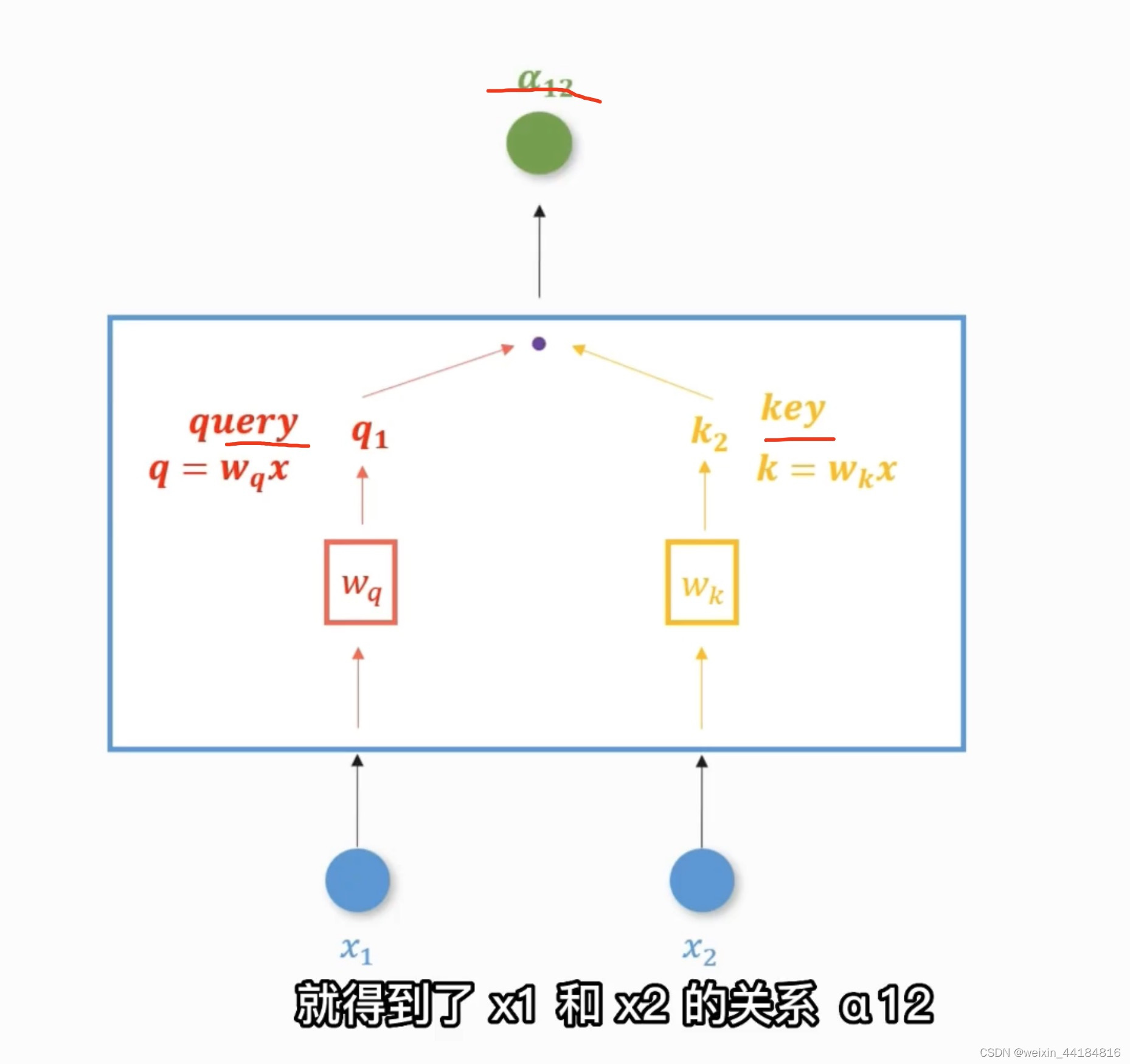
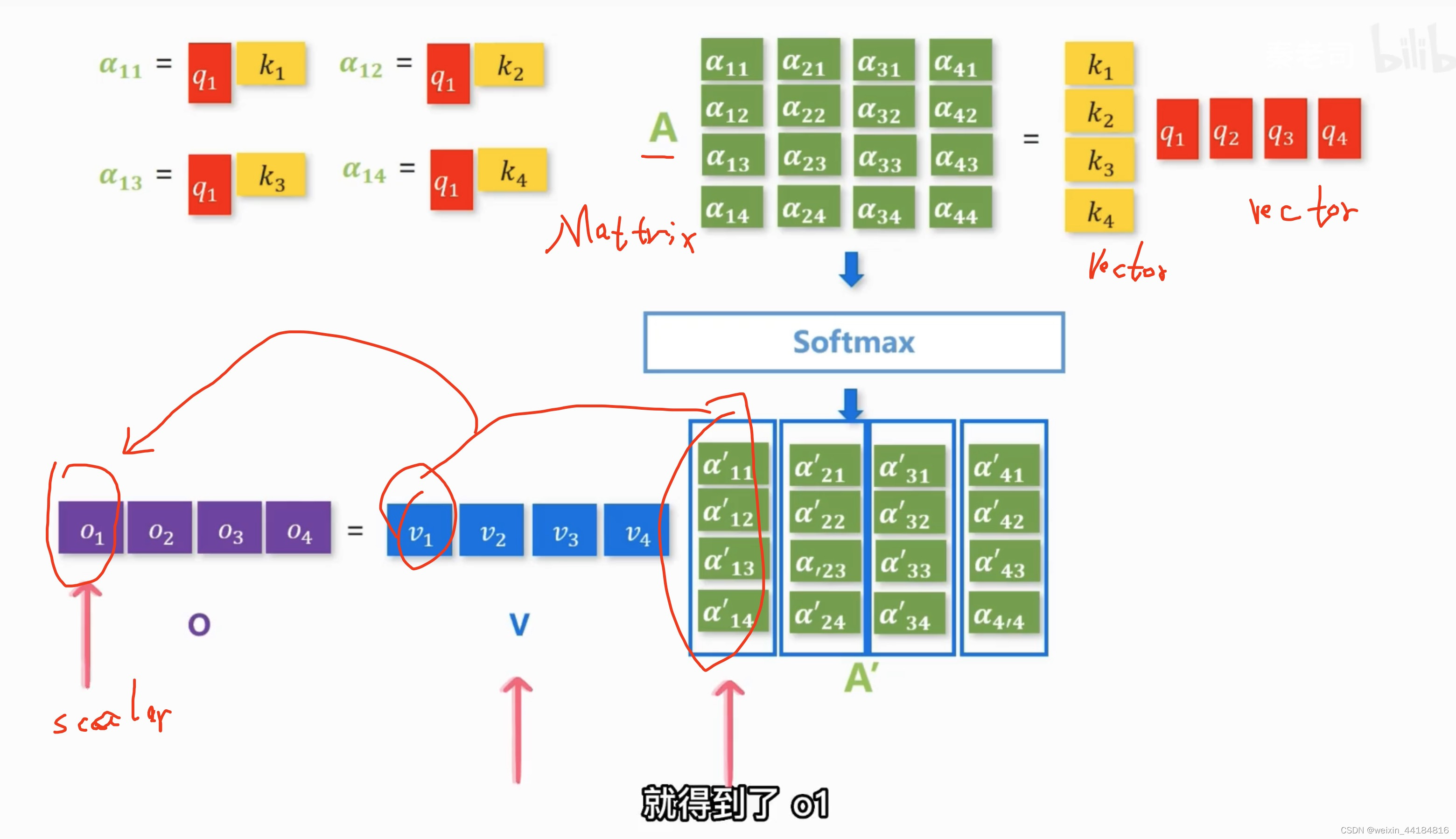
2.q 和 key 的点积相乘得到 alpha,表示 两个输入之间的关系
== 注意力分数
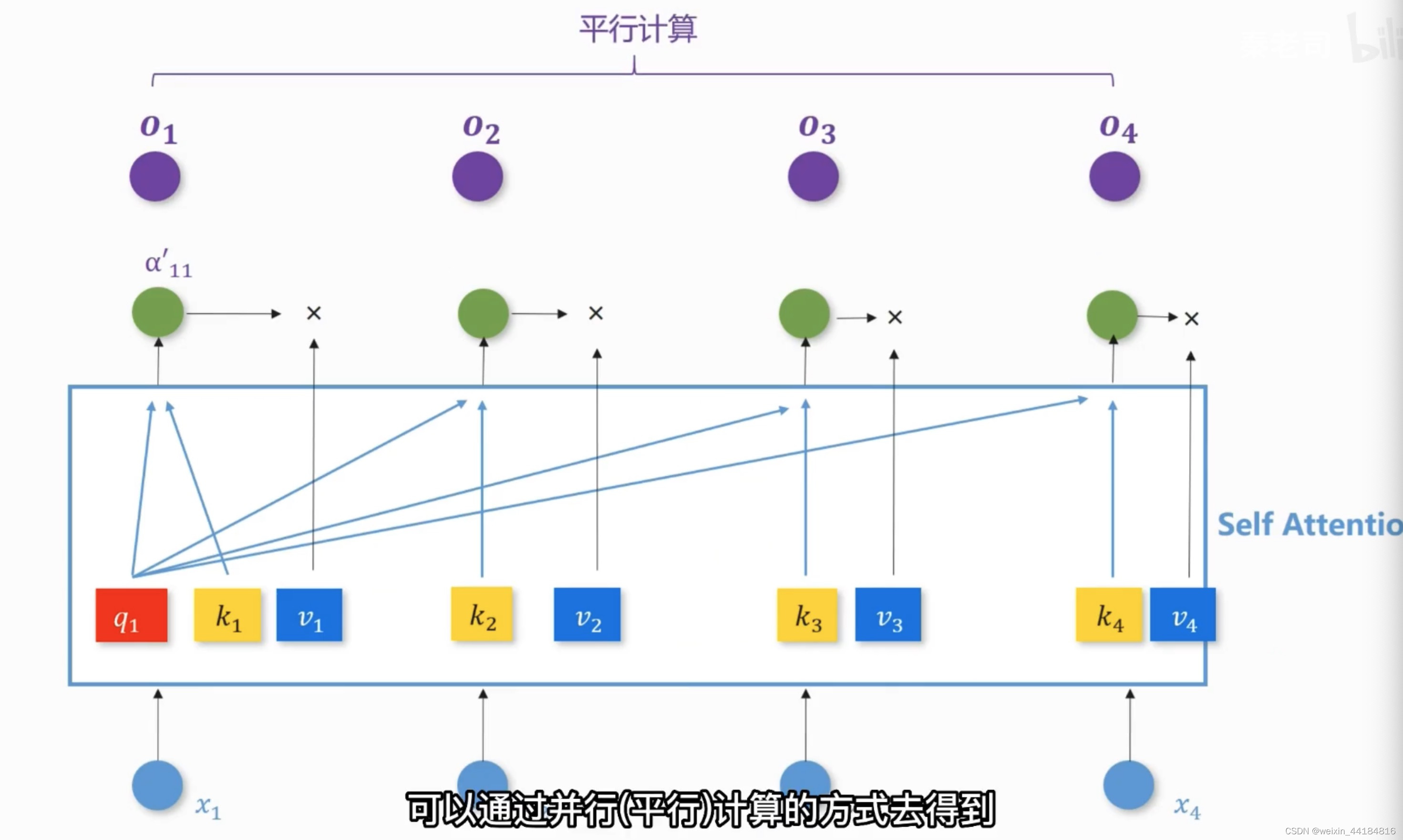
Output = sigma(q_1,k_1) * v_1
可以并行
3.训练 W_q, W_k, W_v, 求得 Q K V 矩阵(向量)
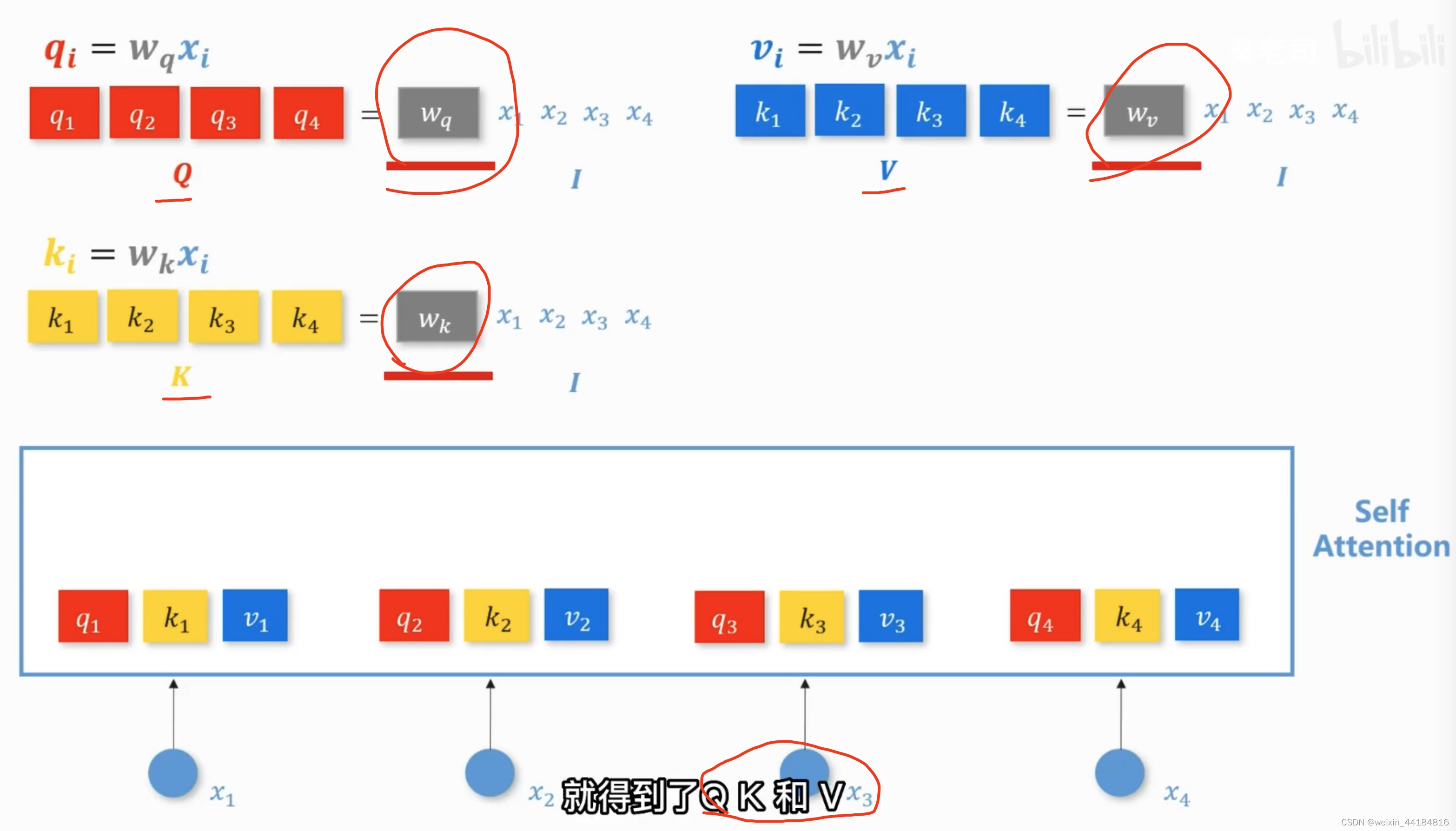
4.求得向量/标量 O_1
2. Seqtoseq
问:详细解释序列到序列(Seq2Seq)模型中的编码器-解码器架构及其数学表示。
答:序列到序列模型通过编码器-解码器架构处理变长的输入输出序列。编码器将输入序列 转换为固定大小的上下文表示 。解码器然后基于\mathbf{c}生成输出序列 。编码器的操作可以表示为: 其中 是在时间步t的隐藏状态, 是最后一个时间步的隐藏状态,作为上下文向量。解码器在每个时间步t生成输出y_t,条件于上下文 和所有先前的输出 : 其中\mathbf{s}_t是解码器在时间步t的隐藏状态, 和 是输出层的参数
3.Auto-Encoder
4.Transformer
4.1 3个小组件
1.Positional Encoding
并行计算时,需要记住单词的位置信息,单词之间的顺序关系
2.Multi-head (self) Attention
多个attention矩阵/过滤器 == 多个头 ==
拼接多个头过线性层压缩,得到一个头
3.Masked Multi-head Attention
self-attention —> Multi-head Attention —> Masked Multi-Head Attention —> Cross-attention
多个self-attention叠加再压缩维度得到,Multi-head Attention
Masked就是只用上文信息,不用下文信息,因为是预测输出任务,在预测下文时,输入不能含有下文信息。
cross-attention: encoder 出 k和v向量, decoder出 q向量

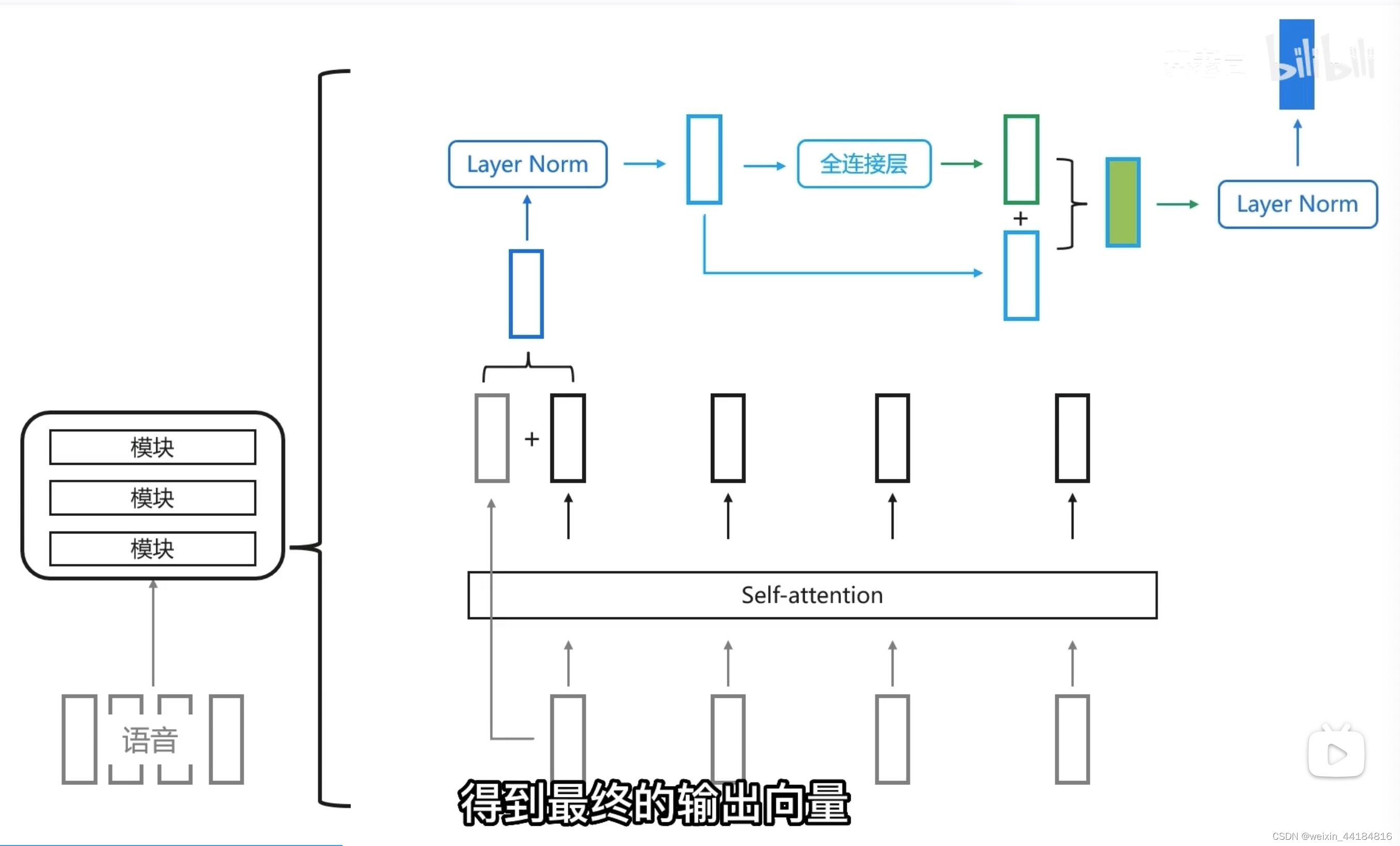
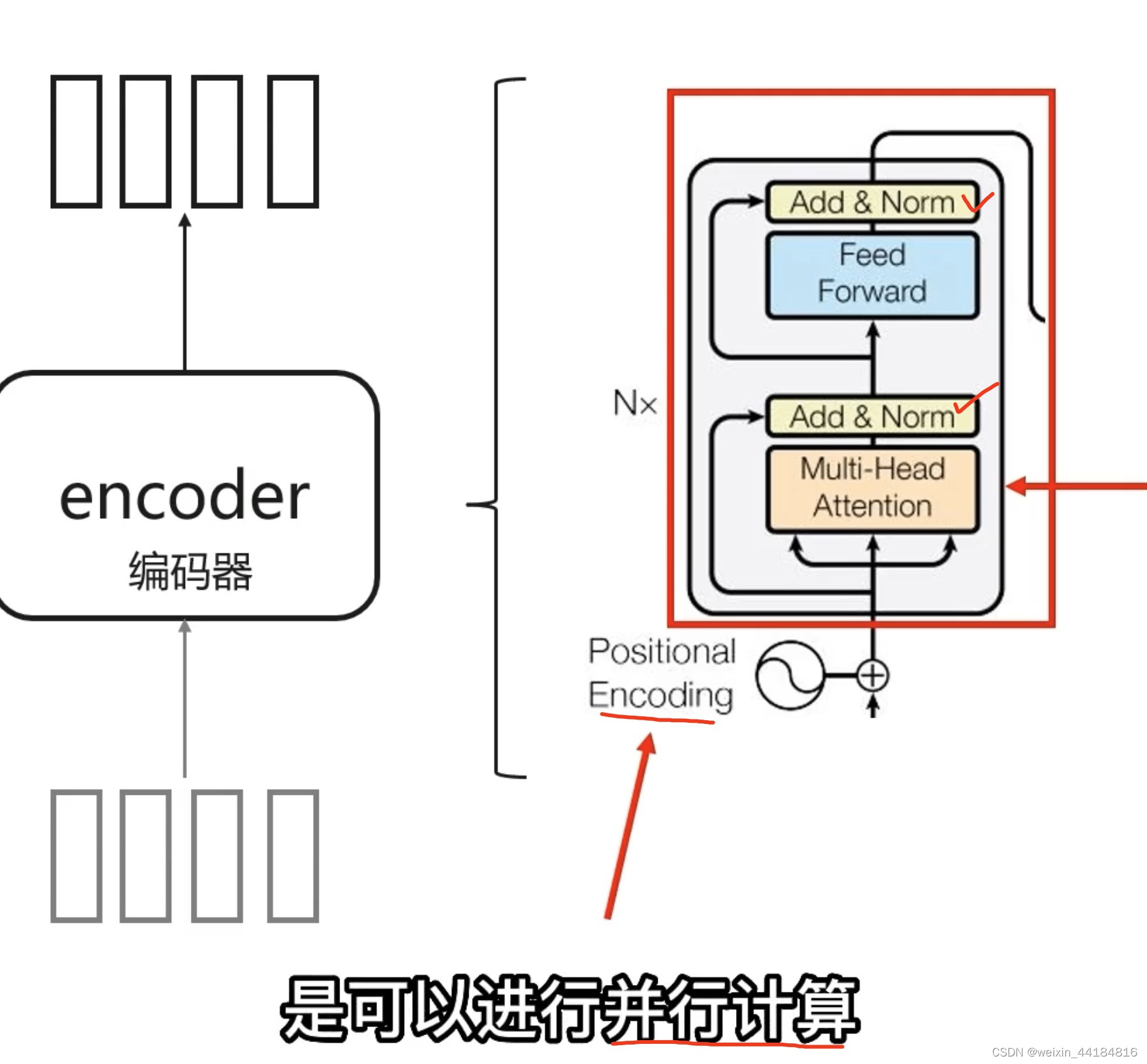
4.2 Encoder
2个 (residual)add + (layer)norm
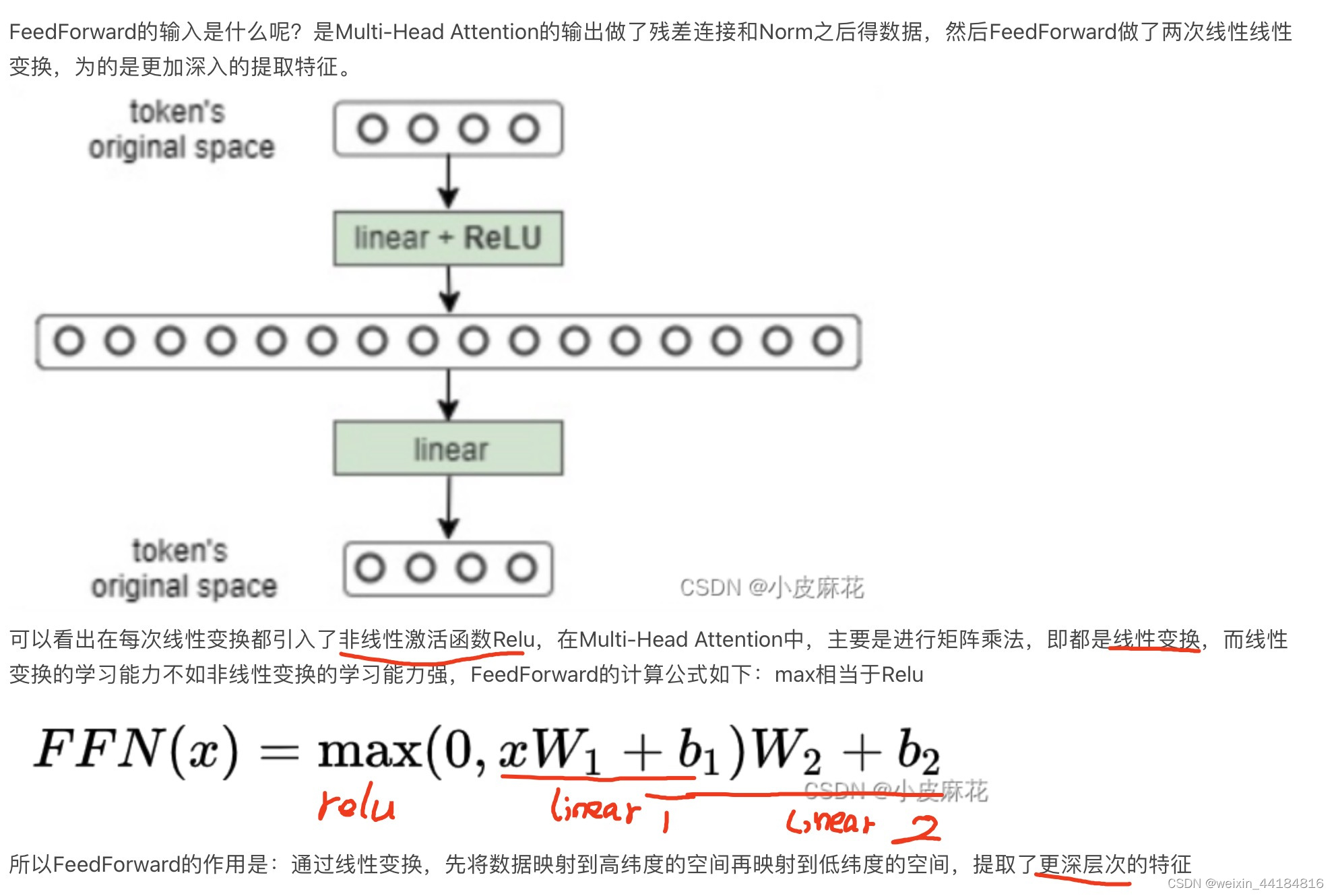
FeedForward层 — 组合层 — linear + relu + linear
4.2 Decoder - 多种选择 - auto regressive
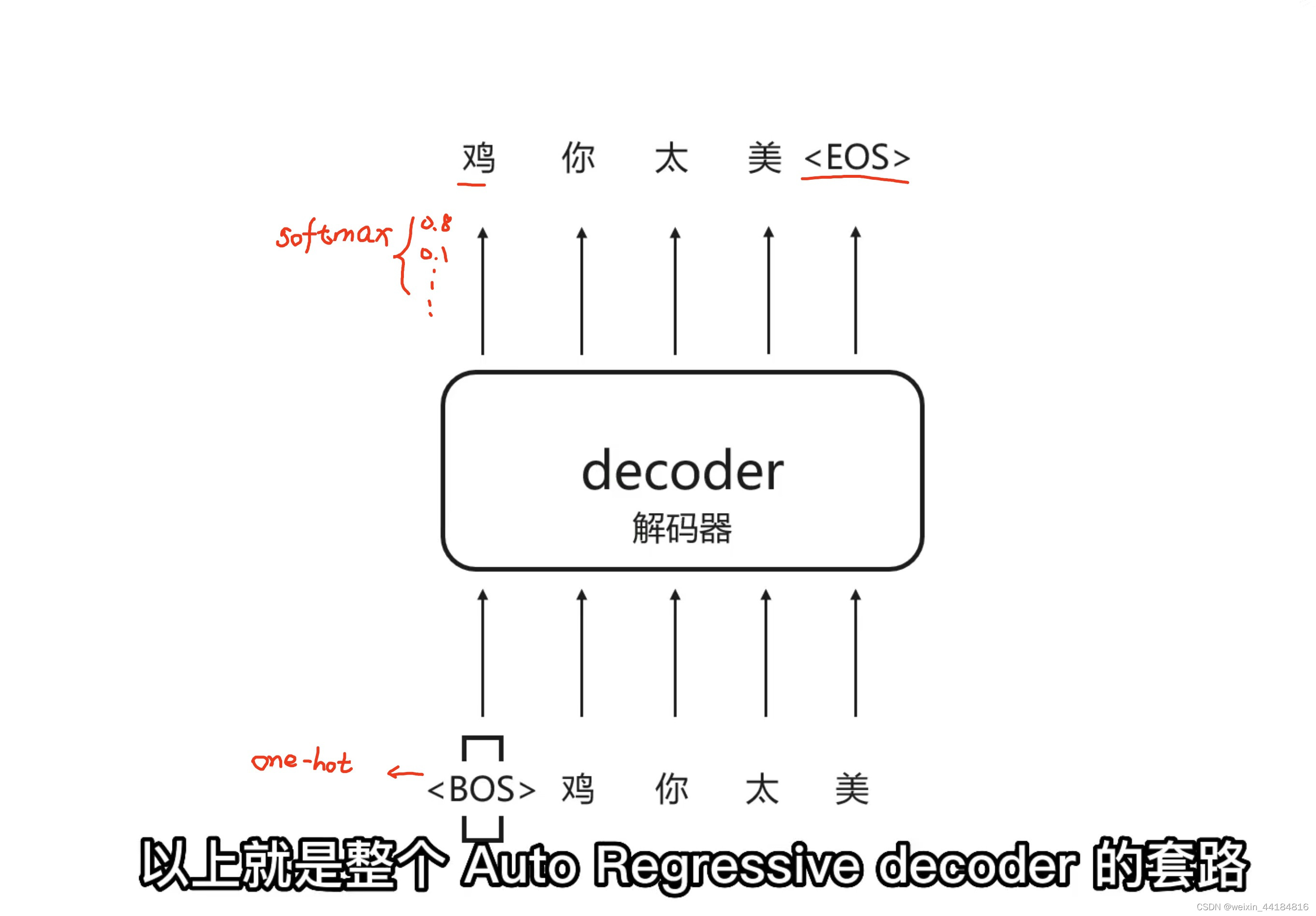
完整示意图

5.Bert - Transformer_Encoder
1.详细解释BERT中的Masked Language Model(MLM)任务的数学原理。
答:BERT的MLM任务通过随机遮蔽输入序列中的词汇并预测它们来训练模型。设输入序列为 ,其中N是序列长度。假设我们随机选择了序列中的一个子集M作为遮蔽目标,其中 ,目标是最大化遮蔽词汇的对数似然: 其中 表示除了位置m的输入序列,\Theta表示模型参数。这个过程迫使模型捕捉句子内的双向上下文信息。
5.1 Pretrain 填空—>NSP—> SOP
masking 填空题
交叉熵作损失函数,越小越好,熵增 == 无序
Next Sentence Prediction —> Sentence Order Prediction
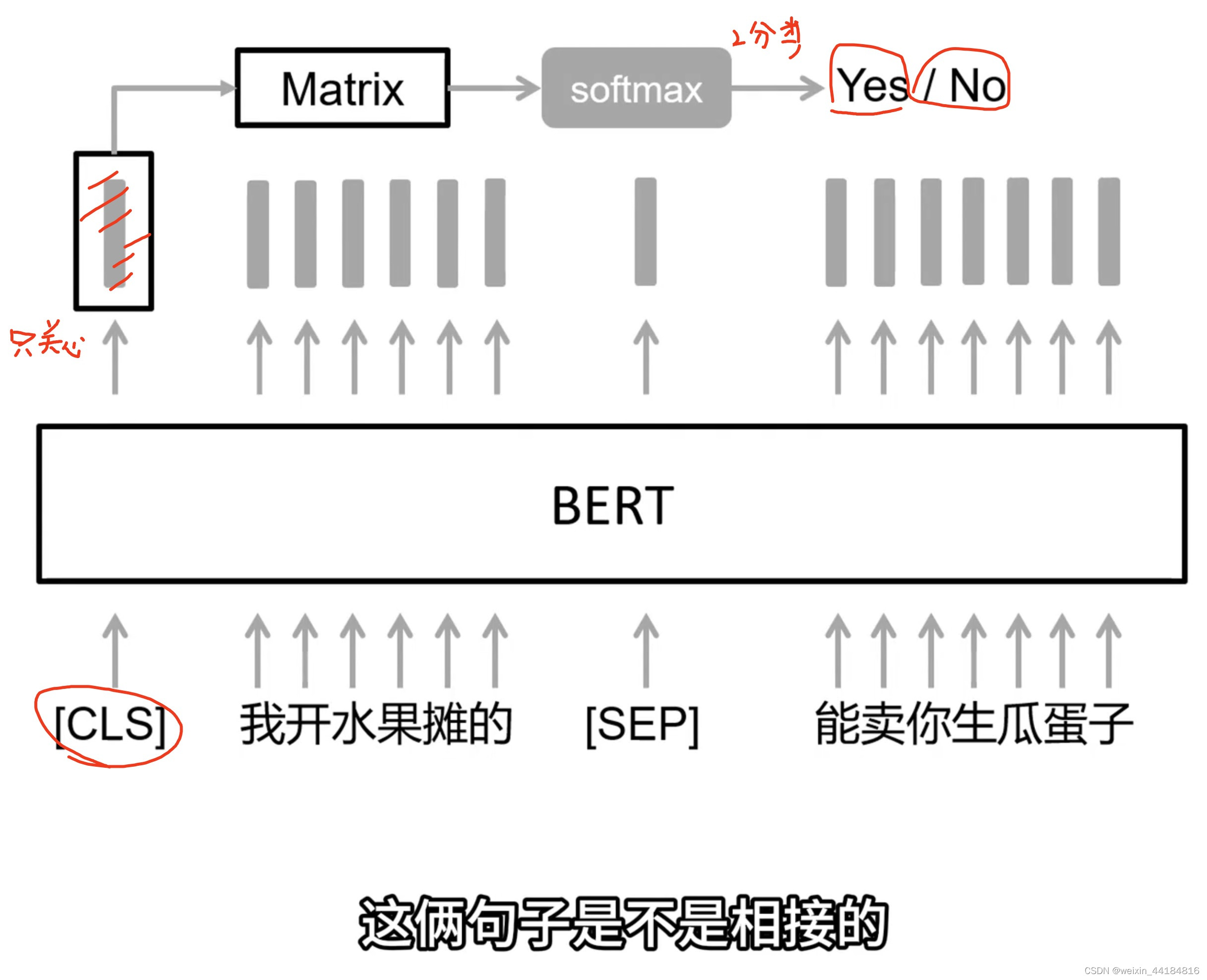
倒转顺序,哪种正确
5.2 Downstream
标注语料微调, 下游任务:QA,情感分析,知识图谱
自监督学习,基石模型
6. RLHF
6.1 A3C



6.2 PPO
6.3 QLearing
IV. 项目
1.word2Vec vs Embeding
问:详细解释Word2Vec模型中的Skip-gram模型及其数学优化目标。
答:Skip-gram模型是Word2Vec的一种实现,旨在通过当前词预测上下文中的词。给定一个词w_t,Skip-gram模型的目标是最大化上下文中所有词的条件概率的对数似然: 其中,c是上下文窗口大小, 通常通过softmax函数计算: 其中,\mathbf{v}_{w_I}和 分别是输入词w_I和输出词w_O的向量表示,V是词汇表的大小。这个模型通过调整词向量来捕捉词之间的语义关系
2.NER 命名实体识别
2.1 概念
看看现在的NER还在做哪些事情,主要分几个方面
- 多特征:实体识别不是一个特别复杂的任务,不需要太深入的模型,那么就是加特征,特征越多效果越好,所以字特征、词特征、词性特征、句法特征、KG表征等等的就一个个加吧,甚至有些中文 NER 任务里还加入了拼音特征、笔画特征。。?心有多大,特征就有多多
- 多任务:很多时候做 NER 的目的并不仅是为了 NER,而是服务于一个更大的目标或系统,比如信息抽取、问答系统等等。如果把整个大任务做一个端到端的模型,就需要做成一个多任务模型,把 NER 作为其中一个子任务;另外,单纯的 NER 也可以做成多任务,比如实体类型过多时,仅用一个序列标注任务来同时抽取实体与判断实体类型,会有些力不从心,就可以拆成两个子任务来做
- 时令大杂烩:把当下比较流行的深度学习话题或方法跟 NER 结合一下,比如结合强化学习的 NER、结合 few-shot learning 的 NER、结合多模态信息的 NER、结合跨语种学习的 NER 等等的,具体就不提了
2.2 方法
1)HMM和CRF等机器学习算法
2)LSTM+CRF
目前做NER比较主流的方法就是采用LSTM作为特征抽取器,再接一个CRF层来作为输出层
NLTK - Hanlp

3)CNN+CRF
4)BERT+(LSTM)+CRF
BERT中蕴含了大量的通用知识,利用预训练好的BERT模型,再用少量的标注数据进行FINETUNE是一种快速的获得效果不错的NER的方法
3.CRF
3.1 框架: 无向图
什么是随机场?什么是马尔可夫随机场?

什么是团?什么是最大团?
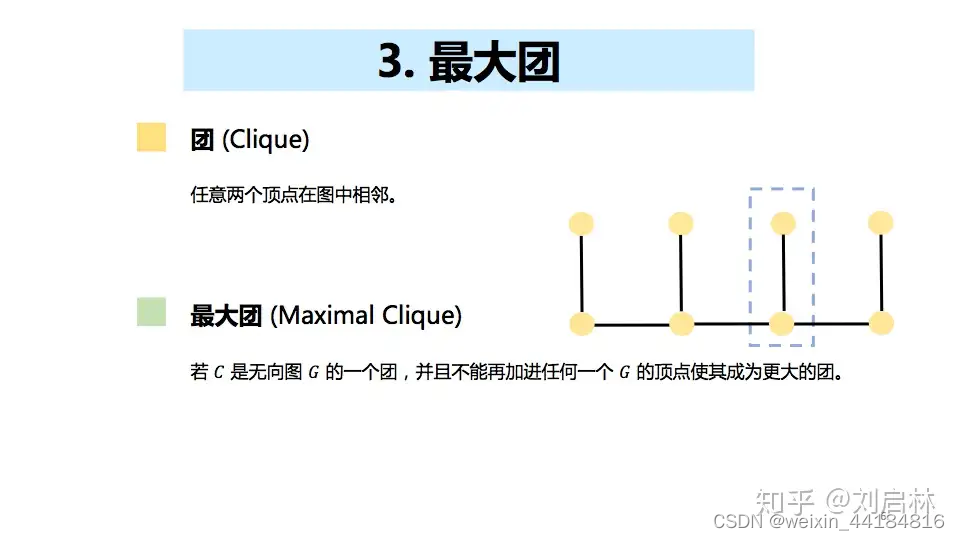
线性链条件随机场

3.2 CRF vs HMM
模型类型:HMM是生成式模型,它同时建模观测序列和隐藏状态序列(相当于标签序列)的联合分布 P ( X , Y ) P(X,Y) P(X,Y),然后通过贝叶斯规则推导条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X)。而CRF直接建模条件概率 P ( Y ∣ X ) P(Y|X) P(Y∣X),更专注于学习决策边界,通常能更好地利用观测数据的特性。 特征表达能力:HMM依赖于固定的转移概率和发射概率,而CRF通过特征函数可以灵活地捕获更复杂的观测与标签之间的关系,允许模型学习到更多的上下文信息。 参数学习:HMM通常使用期望最大化(EM)算法进行参数估计,而CRF通常采用极大似然估计或正则化的极大似然估计,配合梯度上升、拟牛顿法等优化算法求解参数。
3.3 实现
条件随机场(CRF)极简原理与超详细代码解析_条件随机场代码-CSDN博客
CRF的训练目标,是gold_score与norm_score之间的差值,我们希望这两部分尽量接近,也就是真实路径的得分所占全部路径得分之和的比值尽可能大。
那么gold_score,也就是真实得分,是怎么来的呢,它由发射得分和转移得分两部分构成:
计算转移得分
- def calc_unary_score(self, logits, labels, lens):
- """
- 计算发射得分
- logits: (batch, seq_len, num_labels+2)
- labels: (batch, seq_len)
- lens: (batch)
- """
- labels_exp = labels.unsqueeze(-1)
- scores = torch.gather(logits, 2, labels_exp).squeeze(-1)
- mask = sequence_mask(lens).float()
- scores = scores * mask
- return scores
-
-
- def calc_binary_score(self, labels, lens):
- """
- 计算转移得分
- :param labels: (batch, seq_len)
- :param lens: (batch)
- :return:
- """
- batch_size, seq_len = labels.size()
-
- # 1. 扩展label:其实就是对labels在seq_len的维度上扩展了一个开头和末尾
- # A tensor of size batch_size * (seq_len + 2)
- labels_ext = labels.new_empty((batch_size, seq_len + 2)) # 生成一个(batch_size, seq_len + 2)没有初始化的tensor
- labels_ext[:, 0] = self.start # batch中每个instance的第1个位置的值变成start(label_size -2)
- labels_ext[:, 1:-1] = labels
- mask = sequence_mask(lens + 1, max_len=(seq_len + 2)).long() # 开头start位置为True,后边true部分每一位向后移动一位
- pad_stop = labels.new_full((1,), self.end, requires_grad=False) # (batch), 以eos生成一个tensor([6,...,6])
- pad_stop = pad_stop.unsqueeze(-1).expand(batch_size, seq_len + 2) # (batch) -> (batch, seq_len+2)
- labels_ext = (1 - mask) * pad_stop + mask * labels_ext # 被mask的部分变成6,剩下的部分是正确的label
- labels = labels_ext
-
- # 2. 扩展transition:复制了batch份,另batch中的每个instance都有一个transition矩阵
- trn = self.transition # 注意,self.transition的行是from_label, 列是to_label
- trn_exp = trn.unsqueeze(0).expand(batch_size, self.label_size,
- self.label_size)
-
- # 接下来两部分是重点,计算了从一个label转移到另一个label的得分
- # 3. to_label的得分计算
- lbl_r = labels[:, 1:] # 在原始的seq_len上去掉了第一个token
- lbl_rexp = lbl_r.unsqueeze(-1).expand(*lbl_r.size(), self.label_size) # (batch, seq_len+1) -> (batch, seq_len+1, num_labels)
- # score of jumping to a tag
- # 取trn_exp的lbl_rexp中对应的一行(也就是取真实label对应的转移),然后拼起来
- # (batch, num_labels+2, num_labels+2) -> (batch, seq_len-1, num_labels+2)
- trn_row = torch.gather(trn_exp, 1, lbl_rexp) # 这个就是每一个token上,由某个label转移到当前label的得分
-
- # 4. from_label的得分计算
- lbl_lexp = labels[:, :-1].unsqueeze(-1) # (batch, seq_len+1, 1) 每个位置是从哪个label转移来的
- trn_scr = torch.gather(trn_row, 2, lbl_lexp) # (batch, seq_len+1, 1) from_label到to_label的真实得分
- trn_scr = trn_scr.squeeze(-1) # (batch, seq_len+1, 1) -> (batch, seq_len-1)
-
- # 5. mask掉seq_len维度上的start,注意不是mask掉num_labels上的start
- mask = sequence_mask(lens + 1).float()
- trn_scr = trn_scr * mask
- score = trn_scr
-
- return score

4.关系抽取 RE
关系抽取就是从一段文本中抽取出(主体,关系,客体)这样的三元组,用英文表示就是(subject, relation, object)这样的三元组。所以关系抽取,有的论文也叫作三元组抽取。
从关系抽取的定义也可以看出,关系抽取主要做两件事:
1、识别文本中的subject和object(实体识别任务)
2、判断这两个实体属于哪种关系(关系分类)

4.2 难点
联合抽取难点在哪里?联合抽取总体上有哪些方法?各有哪些缺点?
顾名思义,联合模型就是一个模型,将两个子模型统一建模。根据Q1,联合抽取可以进一步利用两个任务之间的潜在信息,以缓解错误传播的缺点(注意⚠️只是缓解,没有从根本上解决)。
联合抽取的难点是如何加强实体模型和关系模型之间的交互,比如实体模型和关系模型的输出之间存在着一定的约束,在建模的时候考虑到此类约束将有助于联合模型的性能。
现有联合抽取模型总体上有两大类[16]:
1、共享参数的联合抽取模型
通过共享参数(共享输入特征或者内部隐层状态)实现联合,此种方法对子模型没有限制,但是由于使用独立的解码算法,导致实体模型和关系模型之间交互不强。
绝大数文献还是基于参数共享进行联合抽取的,这类的代表文献有:
2、联合解码的联合抽取模型
为了加强实体模型和关系模型的交互,复杂的联合解码算法被提出来,比如整数线性规划等。这种情况下需要对子模型特征的丰富性以及联合解码的精确性之间做权衡[16]:
- 一方面如果设计精确的联合解码算法,往往需要对特征进行限制,例如用条件随机场建模,使用维特比解码算法可以得到全局最优解,但是往往需要限制特征的阶数。
- 另一方面如果使用近似解码算法,比如集束搜索,在特征方面可以抽取任意阶的特征,但是解码得到的结果是不精确的。
因此,需要一个算法可以在不影响子模型特征丰富性的条件下加强子模型之间的交互。
此外,很多方法再进行实体抽取时并没有直接用到关系的信息,然而这种信息是很重要的。需要一个方法可以同时考虑一个句子中所有实体、实体与关系、关系与关系之间的交互
5.数据库
Hadoop/RDD
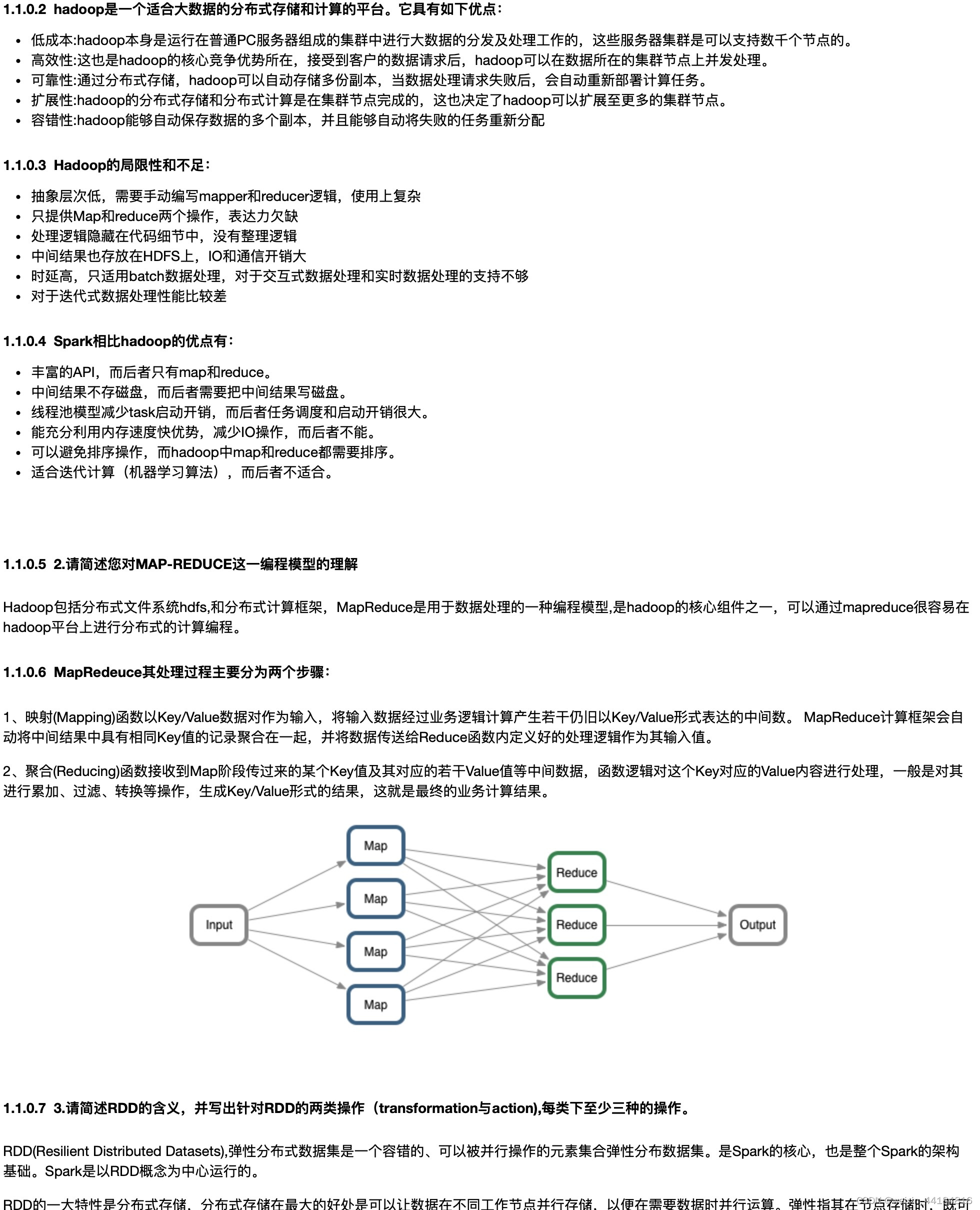

6.演示项目
知识图谱之《海贼王-ONEPICE》领域图谱项目实战(含码源):数据采集、知识存储、知识抽取、知识计算、知识应用、图谱可视化、问答系统(KBQA)等_知识图谱数据采集-CSDN博客
瑞金医院MMC人工智能辅助构建知识图谱大赛_ALGORITHEM_Tianchi competition-Alibabacloud Tianchi introduction
6.1.复旦通用知识图谱
6.2.精灵标注助手

txt — csv
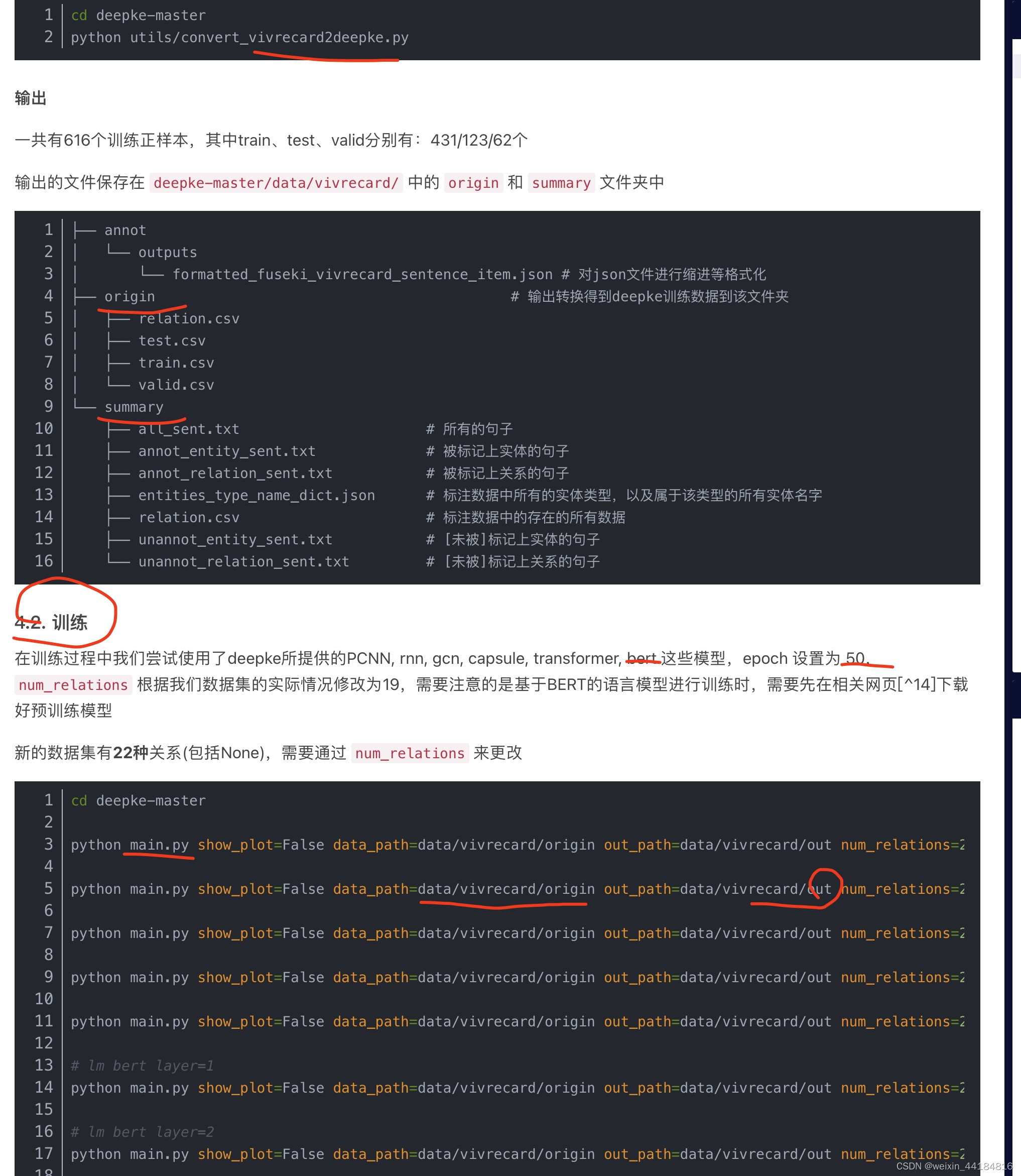
6.3.DeepKe用法
deepke地址
GitHub - zjunlp/DeepKE: [EMNLP 2022] An Open Toolkit for Knowledge Graph Extraction and Construction
PageRank - Neo4j Graph Data Science
deepke示例
deepke文档
DeepKE — DeepKE 0.2.97 documentation
实体+关系,抽取
2个文档输出
deepke训练及结果
6.4.Neo4j语法 - 创建关系的语法
需要deepke输出的nt格式,3元祖格式文件
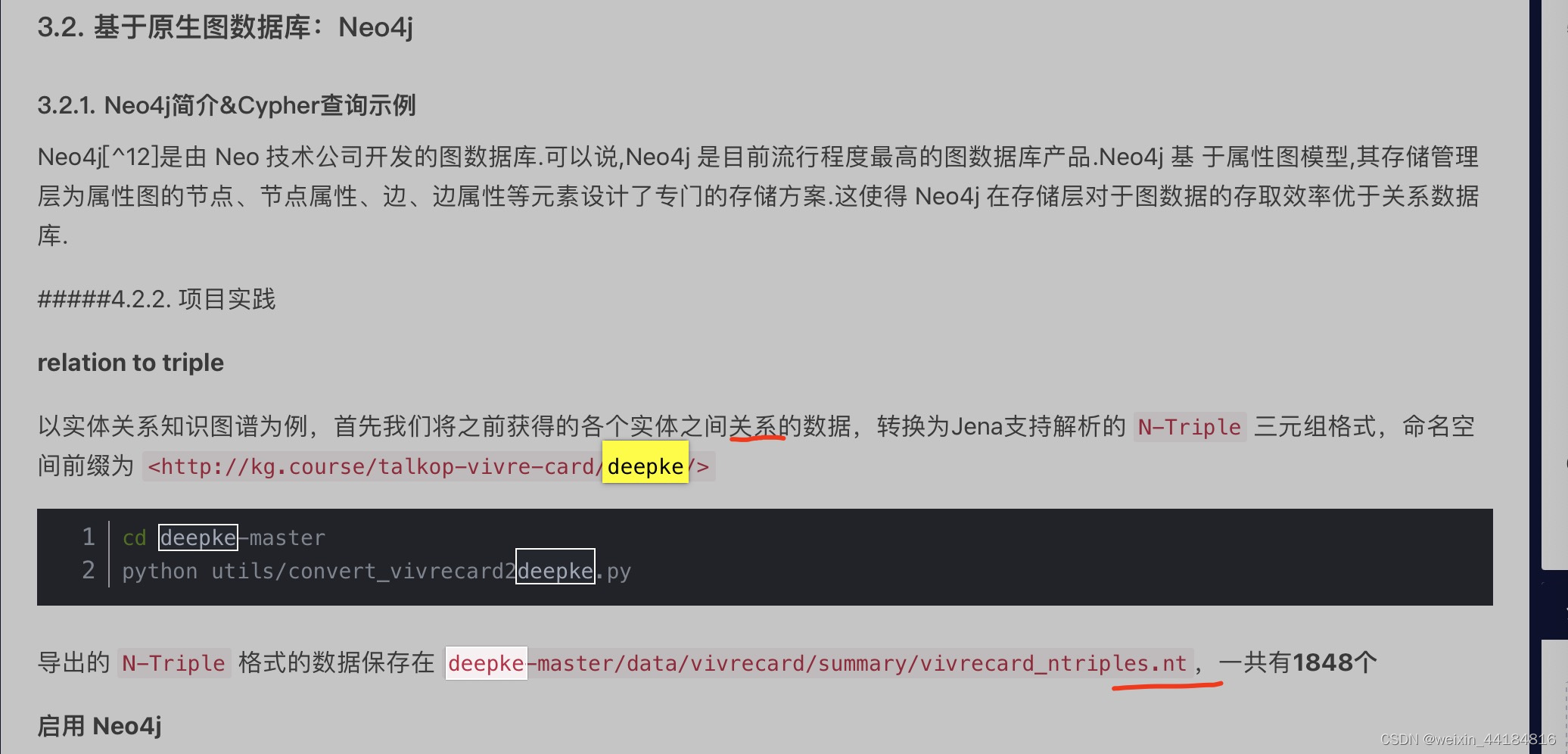
cql教程
备忘录
neo4j 文档 - gds
PageRank - Neo4j Graph Data Science
Linear regression - Neo4j Graph Data Science
图挖掘
1.统计
2.最短路径,有,没有
3.中心度
gds
4.社区,pagerank
6.5.可视化
需要json格式文档
6. 实战项目
知识图谱之《海贼王-ONEPICE》领域图谱项目实战(含码源):数据采集、知识存储、知识抽取、知识计算、知识应用、图谱可视化、问答系统(KBQA)等_知识图谱数据采集-CSDN博客
金融项目1
https://github.com/jm199504/Financial-Knowledge-Graphs
常见cypher指令
https://github.com/jm199504/Financial-Knowledge-Graphs/tree/master/cypher cheetsheet
金融项目2
https://github.com/lemonhu/stock-knowledge-graph
报错及修改
socket.gaierror: [Errno 8] nodename nor servname provided, or not known
urllib.error.URLError: <urlopen error [Errno 8] nodename nor servname provided, or not known>
neo4j_home$ bin/neo4j-admin import --id-type=STRING --nodes=executive.csv --nodes=stock.csv --nodes=concept.csv --nodes=industry.csv --relationships=executive_stock.csv --relationships=stock_industry.csv --relationships=stock_concept.csv
- 集成学习 ...
赞
踩

