
- 1如何安装官网最新版Android Studio_android studio下载安装
- 2函数压栈的简解(计算顺序与压栈顺序)
- 3ADOP带你了解:下一站,极速:数据中心的400G/800G突破_800g脊叶架构数据中心
- 4springboot整合rabbitmq实现延时队列之TTL方式_spring.rabbitmq ttl
- 5CS224W摘要04.Link Analysis: PageRank_random walk stationary distribution
- 6百度智能云大数据平台技术落地实战直播讲解_李莅 百度
- 7【5G/4G】NAS与AS层 完整性保护与加密算法系列文章_5g nr eia算法
- 82022腾讯后台&综合笔试题解_腾讯后台笔试2022
- 9HBase JAVA API(大章鱼版)_某电商网站,后台有买家信息表,每注册一名新用户网站后台会产生一条日志,日志的数
- 10BSD License 条款是干什么的?底层原理是什么?_bsd 3-clause license
AIGC:Stable Diffusion、DALL-E、Imagen框架介绍_imagen介绍
赞
踩
模型框架
这些生成式 AI 的整体功能为:输入「文字」,返回「图像」,即 Text-to-image Generator:

生成器的内部框架如下所示:
- 第一部分:Text Encoder,输出 Text,返回对应的 Embedding(向量);
- 第二部分:Generation Model,输入为 Text 的 Embedding 与一个随机生成的 Embedding(用于后续的 Diffusion 过程),返回中间产物(可以是图片的压缩版本,也可以是 Latent Representation);
- 第三部分:Decoder,输入为图片的压缩版本,返回最终的图片。

三个模块通常是分开训练,再组合起来,得到 Text-to-image Generator。上述框架为通用框架,即均包含上述三个模块,例如 Stable Diffusion:

DALL-E series:

Imagen:

一、Encoder
GPT、Bert 均可当作文字 Encoder,其对最终结果的影响非常大。如下图所示(来自 Imagen 论文实验图):
- 图(a):曲线越接近框内右下角越好,Encoder 越大效果越好,即 Encoder 见过的数据量越多;
- 图(b):Generation Model 的大小对结果影响不大。

FID (Fréchet Inception Distance)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dyaQKsg2-1687504893255)(C:\Users\86186\AppData\Roaming\Typora\typora-user-images\image-20230602110726014.png)]

CLIP (Contrastive Language-Image Pre-Training)
CLIP 是一个使用了 400 million image-text paris 训练得到的模型,该模型可以用于给 (Text, Generated Image) 打分,即将 Text, Image 分别丢进 Text Encoder 和 Image Encoder 中,其产生的 Embedding 越相近,CLIP Score 越高。

二、Decoder
Generation Model 的训练需要 (Text, Image) 成对的数据,但 Decoder 的训练不需要文字资料,因此可供其训练的数据是更多的。如果 Decoder 的输入是图片的压缩版本,即小图(例如 Imagen),则其训练过程为:将任意一张图片降采样得到一张小图,随后使用(小图,原图)的 pair 进行训练,如下所示:

如果 Decoder 的输入 Latent Representation(例如 Stable Diffusion 与 DALL-E),则训练过程为:训练一个 Auto-encoder,并将其中的 Decoder 作为框架中的模块。Auto-encoder 的训练过程也非常直接,其 Encoder 负责得到图片的 Latent Representation,Decoder 负责根据 Latent Representation 生成对应图片,训练目标是原始图片与生成的图片越接近越好。
通常来说原图尺寸为 (H, W, 3),Latent Representation 的大小为 (h, w, c),其中 h 与 w 分别小于 H 和 W。

三、Generation Model
在 Diffusion Model 中,我们不断地在图片上加噪音,得到一张随机图后,再逐步地去噪,最终训练出去噪的模型,如下所示:

而在 Generation Model 中,噪声不是加在图片上,而是加在中间产物上,即 Decoder 的输入 Latent Representation 上,如下所示:

随后训练一个 Noise Predictor,输入为「第 x 步 + 第 x 步对应的加噪结果 + Text Embedding」,输出为第 x 步所加的噪声。

最后在生成图片时,输入为「Text Embedding + 随机高斯噪声」,每次识别出具体的噪声,再一步一步执行去噪,即可得到最终的 Latent Representation,再输入至 Decoder 即可。
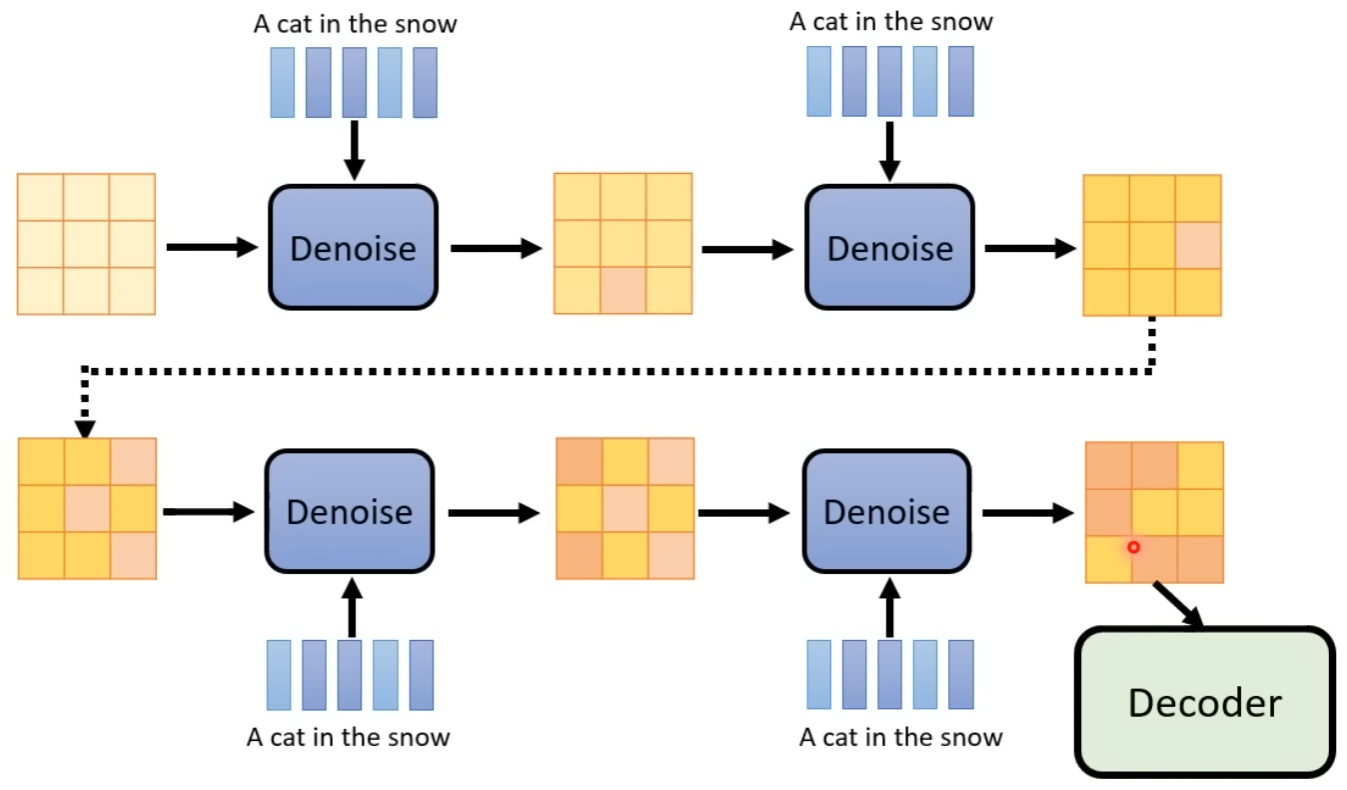
此处需要注意,去噪的过程是「随机高斯噪音」逐步变成「最终 Latent Representation」的过程,该过程中的每一步的 Embedding,丢进 Decoder 均可得到图片,对应于图片生成时,图片逐步变清晰的过程。
其他
参考资料
Hung-yi Lee - 生成式 AI
Stable Diffusion: High-Resolution Image Synthesis with Latent Diffusion Models
DALL-E series: Zero-Shot Text-to-Image Generation
DALL-E series: Hierarchical Text-Conditional Image Generation with CLIP Latents
Imagen: website
Imagen: Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
参考:https://blog.csdn.net/qq_41552508/article/details/129912174

