
- 1sysbench压力测试工具简介和使用(一)_gauss数据库压力测试工具
- 2java的基础算法题_java算法题
- 3个人博客建设必备:精选域名和主机的终极攻略_博客主机
- 4Xilinx XDC功能介绍_xdc怎么添加温度
- 5绘唐3团长是谁阿祖推文AIGC工具
- 6使用ollama跨平台部署大模型_ollama 停止
- 7已解决EROR 1064 (42000): You have an error in. your SOL syntax. check the manual that corresponds to yo_you have an error in your sol syntax; check the ma
- 8阿里云域名动态解析
- 9手把手带你玩转Spark机器学习-使用Spark构建回归模型_spark线性回归 可视化
- 10PyTorch与深度学习:探索人工智能的新前沿
Build a Large Language Model (From Scratch) 从头开始构建大型语言模型(第二章)学习笔记
赞
踩
构建大型语言模型(从头开始)
- 2 理解大型语言模型(Working with Text Data)
- 2.1 理解词嵌入(Understanding word embeddings)
- 2.2 文本Tokenizing(Tokenizing text)
- 2.3 将tokens转换为tokensIDs (Converting tokens into token IDs)
- 2.4 添加特殊上下文tokens (Adding special context tokens)
- 2.4 字节对编码(Byte pair encoding)
- 2.6 滑动窗口数据采样(Data sampling with a sliding window)
- 2.7 创建token嵌入(Creating token embeddings)
- 2.8 编码单词位置 (Encoding word positions)
- 2.9 总结
2 理解大型语言模型(Working with Text Data)
本章涵盖
- 为大型语言模型训练准备文本
- 将文本拆分为单词和子单词tokens
- 字节对编码作为一种更高级的文本tokenizing方式
- 使用滑动窗口方法对训练示例进行采样
- 将tokens转换为输入大型语言模型的向量
在上一章中,我们深入研究了大型语言模型(LLM)的一般结构,并了解到它们是在大量文本上进行预训练的。具体来说,我们的重点是基于 Transformer 架构的纯解码器 LLM,该架构是 ChatGPT 和其他流行的类似 GPT 的 LLM 中使用的模型的基础。
在预训练阶段,LLM一次处理一个单词的文本。使用下一个单词预测任务训练具有数百万到数十亿个参数的LLM,可以产生具有令人印象深刻的功能的模型。然后可以进一步微调这些模型以遵循一般指令或执行特定的目标任务。但在我们在接下来的章节中实现和训练 LLM 之前,我们需要准备训练数据集,这是本章的重点,如图 2.1 所示
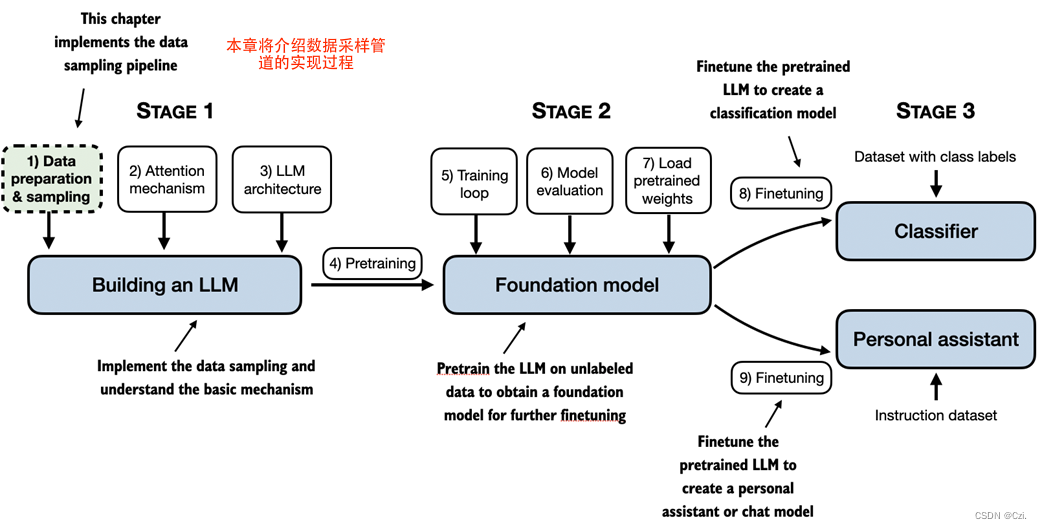
在本章中,您将学习如何为训练LLM准备输入文本。这涉及将文本拆分为单独的单词和子词tokens,然后将其编码为 LLM 的向量表示。您还将了解高级tokenization方案,例如字节对编码,该方案在 GPT 等流行的 LLM 中使用。最后,我们将实施采样和数据加载策略,以生成后续章节中训练LLM所需的输入输出对。
2.1 理解词嵌入(Understanding word embeddings)
深度神经网络模型(包括LLM)无法直接处理原始文本。由于文本是分类的,因此它与用于实现和训练神经网络的数学运算不兼容。因此,我们需要一种将单词表示为连续值向量的方法。
将数据转换为矢量格式的概念通常称为嵌入。使用特定的神经网络层或另一个预训练的神经网络模型,我们可以嵌入不同的数据类型,例如视频、音频和文本,如图2.2所示。

如图2.2所示,我们可以通过嵌入模型处理各种不同的数据格式。然而,值得注意的是,不同的数据格式需要不同的嵌入模型。例如,为文本设计的嵌入模型不适合嵌入音频或视频数据。
嵌入的核心是从离散对象(例如单词、图像甚至整个文档)到连续向量空间中的点的映射——嵌入的主要目的是将非数字数据转换为神经网络可以识别的格式。网络可以处理。
虽然词嵌入是最常见的文本嵌入形式,但也有句子、段落或整个文档的嵌入。句子或段落嵌入是检索增强生成的流行选择。检索增强生成将生成(如生成文本)与检索(如搜索外部知识库)结合起来,在生成文本时提取相关信息,这是一种超出了本书范围的技术。由于我们的目标是训练类似 GPT 的 LLM,它学习一次生成一个单词的文本,因此本章重点讨论单词嵌入。
已经开发了多种算法和框架来生成词嵌入。早期且最流行的示例之一是Word2Vec方法。 Word2Vec 训练神经网络架构,通过预测给定目标单词的单词上下文来生成单词嵌入,反之亦然。 Word2Vec 背后的主要思想是,出现在相似上下文中的单词往往具有相似的含义。因此,当出于可视化目的投影到二维词嵌入时,可以看到相似的术语聚集在一起,如图 2.3 所示。
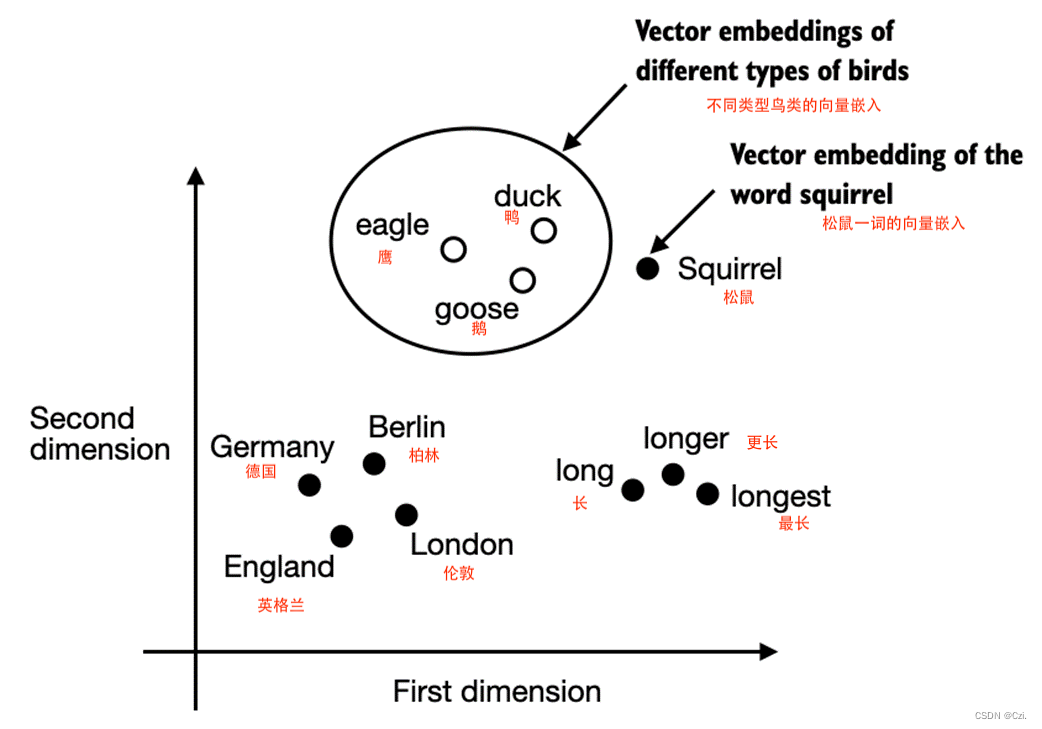
如果词嵌入是二维的,我们可以将它们绘制在二维散点图中以实现可视化目的,如图 2.3所示。当使用单词嵌入技术(例如 Word2Vec)时,与相似概念相对应的单词通常在嵌入空间中彼此靠近出现。例如,与国家和城市相比,不同类型的鸟类在嵌入空间中显得彼此更接近。
词嵌入可以有不同的维度,从一到数千。如图2.3所示,我们可以选择二维词嵌入来实现可视化目的。更高的维度可能会捕获更细微的关系,但代价是计算效率。
虽然我们可以使用 Word2Vec 等预训练模型来生成机器学习模型的嵌入,但LLM通常会生成自己的嵌入,这些嵌入是输入层的一部分,并在训练期间更新。在 LLM 训练中优化嵌入而不是使用 Word2Vec 的优点是嵌入针对特定任务和手头的数据进行了优化。我们将在本章后面实现这样的嵌入层。此外,正如我们在第 3 章中讨论的,LLM还可以创建上下文理解的输出嵌入。
不幸的是,高维嵌入对可视化提出了挑战,因为我们的感官知觉和常见的图形表示本质上仅限于三个维度或更少,这就是为什么图 2.3 在二维散点图中显示了二维嵌入。然而,在使用 LLM 时,我们通常使用比图 2.3 所示更高维度的嵌入。对于 GPT-2 和 GPT-3,嵌入大小(通常称为模型隐藏状态的维度)根据特定模型变体和大小而变化。这是性能和效率之间的权衡。最小的 GPT-2 模型(117M 和 125M 参数)使用 768 维的嵌入大小来提供具体示例。最大的 GPT-3 模型(175B 参数)使用 12,288 维的嵌入大小。
本章接下来的部分将介绍准备 LLM 使用的嵌入所需的步骤,其中包括将文本拆分为单词、将单词转换为tokens以及将tokens转换为嵌入向量。
2.2 文本Tokenizing(Tokenizing text)
本节介绍我们如何将输入文本拆分为单独的tokens,这是为 LLM 创建嵌入所需的预处理步骤。这些tokens要么是单个单词,要么是特殊字符,包括标点符号,这如图 2.4 所示。
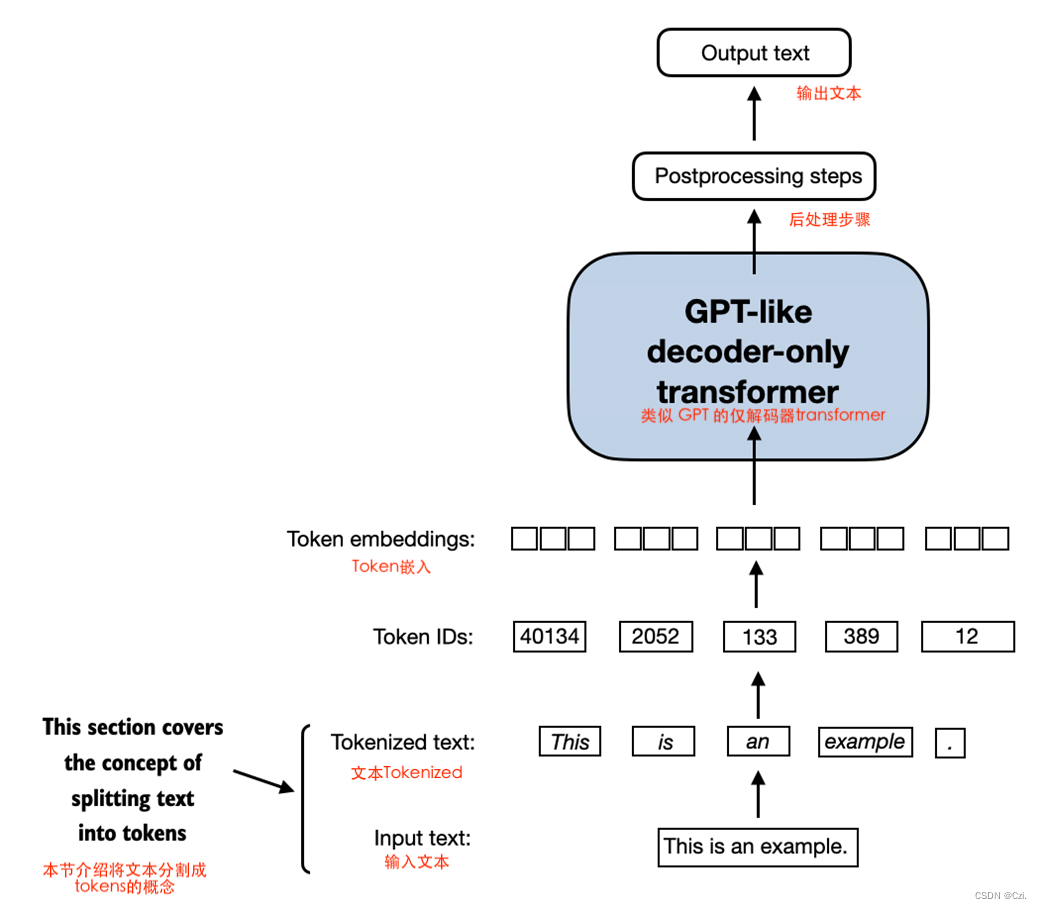
图 2.4 本节在LLM背景下涵盖的文本处理步骤的视图。在这里,我们将输入文本分割成单独的tokens,这些tokens可以是单词或特殊字符,例如标点符号。在接下来的部分中,我们将把文本转换为tokens ID 并创建tokens嵌入。
我们将为 LLM 训练tokenize的文本是 Edith Wharton 的短篇小说《The Verdict》,该小说已发布到公共领域,因此允许用于 LLM 训练任务。该文本可在 Wikisource 上找到,网址为https://en.wikisource.org/wiki/The_Verdict,您可以将其复制并粘贴到文本文件中,我将其复制到文本文件中"the-verdict.txt" 以使用 Python 的标准文件读取实用程序进行加载:
# 清单 2.1 将一个短篇故事作为文本示例读入 Python
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
print("Total number of character:", len(raw_text))
print(raw_text[:99])
- 1
- 2
- 3
- 4
- 5
- 6
或者,您可以在本书的 GitHub 存储库中找到此“the-verdict.txt" 文件: https://github.com/rasbt/LLMs-from-scratch/tree/main/ch02/01_main-chapter-code。
出于说明目的,打印命令打印该文件的总字符数,后跟该文件的前 100 个字符:
Total number of character: 20479 I HAD always thought Jack Gisburn rather a cheap genius--though a good fellow enough--so it was no
我们的目标是将这个 20,479 个字符的短篇故事tokenize为单个单词和特殊字符,然后我们可以将其转化为后续章节中 LLM 训练的嵌入。
文本样本大小
请注意,在与LLM合作时,处理数百万篇文章和数十万本书(数千兆字节的文本)是很常见的。然而,出于教育目的,使用较小的文本样本(例如一本书)就足以说明文本处理步骤背后的主要思想,并使其能够在合理的时间内在消费类硬件上运行。
我们怎样才能最好地分割这个文本以获得tokens列表?为此,我们进行了一次小游览,并使用 Python 的正则表达式库re进行说明。(请注意,您不必学习或记住任何正则表达式语法,因为我们将在本章后面过渡到预构建的分词器。)
使用一些简单的示例文本,我们可以使用re.split具有以下语法的命令来根据空白字符拆分文本:
正则表达式r’(\s)':这里\s代表空白字符(例如空格、换行符等)。圆括号()表示捕获组,意味着在分割的同时,匹配到的空白字符也会作为独立的元素包含在结果列表中。
import re
text = "Hello, world. This, is a test."
result = re.split(r'(\s)', text)
print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
结果是单个单词、空格和标点符号的列表:
‘Hello,’
’ ’
‘world.’
’ ’
…
['Hello,', ' ', 'world.', ' ', 'This,', ' ', 'is', ' ', 'a', ' ', 'test.']
请注意,上面的简单tokenization方案主要用于将示例文本分成单独的单词,但是,某些单词仍然连接到我们希望作为单独列表条目的标点符号。我们也避免将所有文本都小写,因为大写有助于LLM区分专有名词和普通名词,理解句子结构,并学习生成具有正确大写的文本。
让我们修改按空格 ( \s) 和逗号以及句点 ( [,.])分隔的正则表达式:
在正则表达式 r’([,.]|\s)’ 中:
[,.] 指的是一个字符集,匹配任何一个逗号 , 或者句号 .。
| 是一个逻辑或操作符,表示匹配左边的 [,.] 或者右边的 \s。
\s 匹配任何空白字符,包括空格、制表符、换行符等。
圆括号 () 表示捕获组,这意味着在使用 re.split 进行分割时,匹配到的逗号、句号或空白字符也会作为分割结果的一部分返回。
result = re.split(r'([,.]|\s)', text)
print(result)
- 1
- 2
- 3
我们可以看到单词和标点符号现在是单独的列表条目,正如我们想要的那样:
‘Hello’
‘,’
’ ’
‘world’
…
['Hello', ',', '', ' ', 'world', '.', '', ' ', 'This', ',', '', ' ', 'is', ' ', 'a', ' ', 'test', '.', '']
剩下的一个小问题是列表仍然包含空白字符。或者,我们可以安全地删除这些冗余字符,如下所示:
# Strip whitespace from each item and then filter out any empty strings.从每个项中去除空格,然后过滤掉任何空字符串。
result = [item for item in result if item.strip()]
print(result)
- 1
- 2
- 3
生成的无空格输出如下所示:
['Hello', ',', 'world', '.', 'This', ',', 'is', 'a', 'test', '.']
是否删除空格
在开发简单的tokenizer时,我们是否应该将空格编码为单独的字符,或者只是删除它们取决于我们的应用程序及其要求。删除空格可以减少内存和计算需求。但是,如果我们训练对文本的确切结构敏感的模型(例如,对缩进和间距敏感的 Python 代码),保留空格可能会很有用。在这里,为了tokenized输出的简单性和简洁性,我们删除了空格。稍后,我们将切换到包含空格的tokenization方案。
我们上面设计的tokenization方案在简单的示例文本上效果很好。让我们进一步修改它,以便它还可以处理其他类型的标点符号,例如问号、引号和我们之前在Edith Wharton短篇小说的前 100 个字符中看到的双破折号,以及其他特殊字符:
text = "Hello, world. Is this-- a test?"
result = re.split(r'([,.:;?_!"()\']|--|\s)', text)
result = [item.strip() for item in result if item.strip()]
print(result)
- 1
- 2
- 3
- 4
结果输出如下:
['Hello', ',', 'world', '.', 'Is', 'this', '--', 'a', 'test', '?']
从图 2.5 中总结的结果可以看出,我们的tokenization方案现在可以成功处理文本中的各种特殊字符。

图 2.5 到目前为止,我们实现的tokenization方案将文本拆分为单独的单词和标点符号。在此图所示的具体示例中,示例文本被分为== 10 个单独的tokens==。
现在我们已经有了一个基本的tokenizer(分词器),让我们将它应用到Edith Wharton的整个短篇小说中:
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
print(len(preprocessed))
print(preprocessed[:30])
- 1
- 2
- 3
- 4
上面的 print 语句输出4649,它是该文本中的tokens数(不包含空格)。
让我们打印前 30 个tokens以进行快速目视检查:
['I', 'HAD', 'always', 'thought', 'Jack', 'Gisburn', 'rather', 'a', 'cheap', 'genius', '--', 'though', 'a', 'good', 'fellow', 'enough', '--', 'so', 'it', 'was', 'no', 'great', 'surprise', 'to', 'me', 'to', 'hear', 'that', ',', 'in']
结果输出显示我们的tokenizer(分词器)似乎能够很好地处理文本,因为所有单词和特殊字符都被整齐地分开
2.3 将tokens转换为tokensIDs (Converting tokens into token IDs)
在上一节中,我们将Edith Wharton的短篇小说tokenized为单独的tokens。在本节中,我们会将这些tokens从 Python 字符串转换为整数表示形式,以生成所谓的token IDs。此转换是将token ID 转换为embedding vectors之前的中间步骤。
为了将之前生成的 tokens 映射到 token IDs,我们必须首先构建一个所谓的vocabulary。该词汇表定义了我们如何将每个唯一单词和特殊字符映射到唯一整数,如图 2.6 所示。
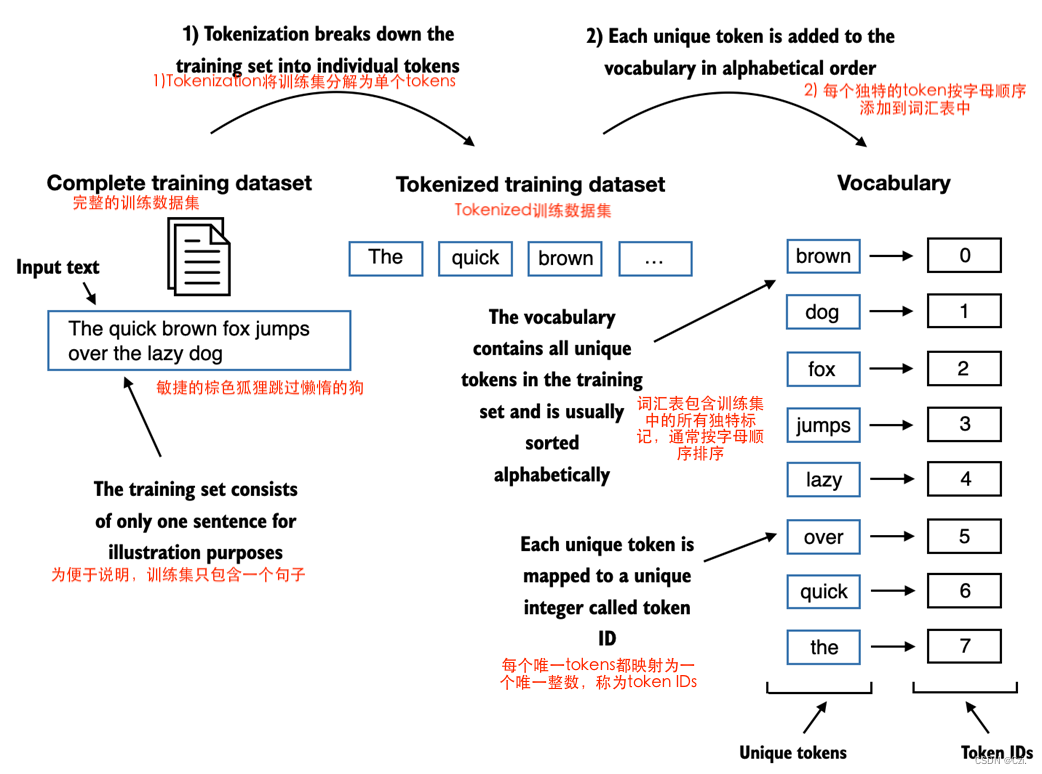
图 2.6 我们通过将训练数据集中的整个文本tokenizing为单独的tokens来构建词汇表。然后将这些单独的tokens按字母顺序排序,并删除重复的tokens。然后,将唯一token聚合到词汇表中,该词汇表定义从每个唯一token到唯一整数值的映射。为了说明的目的,所描绘的词汇量故意较小,并且为了简单起见不包含标点符号或特殊字符。
在上一节中,我们对 Edith Wharton 的短篇小说进行了tokenized,并将其分配给一个名为 的 Python 变量preprocessed。现在让我们创建所有唯一tokens的列表,并按字母顺序对它们进行排序以确定词汇表大小:
all_words = sorted(list(set(preprocessed)))
vocab_size = len(all_words)
print(vocab_size)
- 1
- 2
- 3
- 4
1159
通过上述代码确定词汇表大小为 1,159 后,我们创建词汇表并打印其前 50 个条目以供说明:
注:set集合会去重
vocab = {token:integer for integer,token in enumerate(all_words)}
for i, item in enumerate(vocab.items()):
print(item)
if i >= 50:
break
- 1
- 2
- 3
- 4
- 5
- 6
('!', 0) ('"', 1) ("'", 2) ('(', 3) (')', 4) (',', 5) ('--', 6) ('.', 7) (':', 8) (';', 9) ('?', 10) ('A', 11) ('Ah', 12) ('Among', 13) ('And', 14) ('Are', 15) ('Arrt', 16) ('As', 17) ('At', 18) ('Be', 19) ('Begin', 20) ('Burlington', 21) ('But', 22) ('By', 23) ('Carlo', 24) ('Carlo;', 25) ('Chicago', 26) ('Claude', 27) ('Come', 28) ('Croft', 29) ('Destroyed', 30) ('Devonshire', 31) ('Don', 32) ('Dubarry', 33) ('Emperors', 34) ('Florence', 35) ('For', 36) ('Gallery', 37) ('Gideon', 38) ('Gisburn', 39) ('Gisburns', 40) ('Grafton', 41) ('Greek', 42) ('Grindle', 43) ('Grindle:', 44) ('Grindles', 45) ('HAD', 46) ('Had', 47) ('Hang', 48) ('Has', 49) ('He', 50)
正如我们所看到的,根据上面的输出,字典包含与唯一整数标签关联的各个tokens。我们的下一个目标是应用这个词汇表将新文本转换为token IDs,如图 2.7 所示。
图 2.7 从一个新的文本样本开始,我们对文本进行tokenize,并使用词汇表将文本tokens转换为token IDs。词汇表是根据整个训练集构建的,可以应用于训练集本身和任何新的文本样本。为了简单起见,所描述的词汇不包含标点符号或特殊字符。
在本书后面,当我们想要将 LLM 的输出从数字转换回文本时,我们还需要一种将token IDs 转换为文本的方法。为此,我们可以创建词汇表的逆版本,将token IDs 映射回相应的文本tokens。
让我们在 Python 中实现一个完整的tokenizer类,该类使用encode将文本拆分为tokens并执行字符串到整数的映射以通过词汇表生成token IDs 的方法。此外,我们还实现了一种decode执行反向整数到字符串映射的方法,将token IDs 转换回文本。
该tokenizer实现的代码如下所示:
class SimpleTokenizerV1: def __init__(self, vocab): self.str_to_int = vocab self.int_to_str = {i:s for s,i in vocab.items()} def encode(self, text): preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text) preprocessed = [item.strip() for item in preprocessed if item.strip()] ids = [self.str_to_int[s] for s in preprocessed] return ids def decode(self, ids): text = " ".join([self.int_to_str[i] for i in ids]) # Replace spaces before the specified punctuations text = re.sub(r'\s+([,.?!"()\'])', r'\1', text) return text

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
使用SimpleTokenizerV1 上面的 Python 类,我们现在可以通过现有词汇表实例化新的tokenizer对象,然后使用该对象对文本进行编码和解码,如图 2.8 所示。
1.The encode function turns text into token IDs
2.The decode function turns token IDs back into text

图 2.8 Tokenizer 实现共享两个通用方法:编码方法和解码方法。编码方法接收示例文本,将其分割成单独的token,并通过词汇表将tokens转换为token IDs。解码方法接收token IDs,将它们转换回文本令牌,并将文本令牌连接成自然文本。
让我们从SimpleTokenizerV1类中实例化一个新的tokenizer对象,并对 Edith Wharton 的短篇小说中的一段进行tokenize,以便在实践中进行尝试:
tokenizer = SimpleTokenizerV1(vocab)
text = """"It's the last he painted, you know," Mrs. Gisburn said with pardonable pride."""
ids = tokenizer.encode(text)
print(ids)
- 1
- 2
- 3
- 4
- 5
[1, 58, 2, 872, 1013, 615, 541, 763, 5, 1155, 608, 5, 1, 69, 7, 39, 873, 1136, 773, 812, 7]
接下来,让我们看看是否可以使用decode方法将这些token IDs转回文本:
tokenizer.decode(ids)
- 1
'" It\' s the last he painted, you know," Mrs. Gisburn said with pardonable pride.'
据上面的输出,我们可以看到decode方法成功地将token IDs转换回原始文本。
到目前为止,一切都很好。我们实现了一个tokenizer,能够根据训练集中的片段对文本进行tokenizing和de-tokenizing。现在让我们将其应用于训练集中未包含的新文本样本:
text = "Hello, do you like tea?"
tokenizer.encode(text)
- 1
- 2
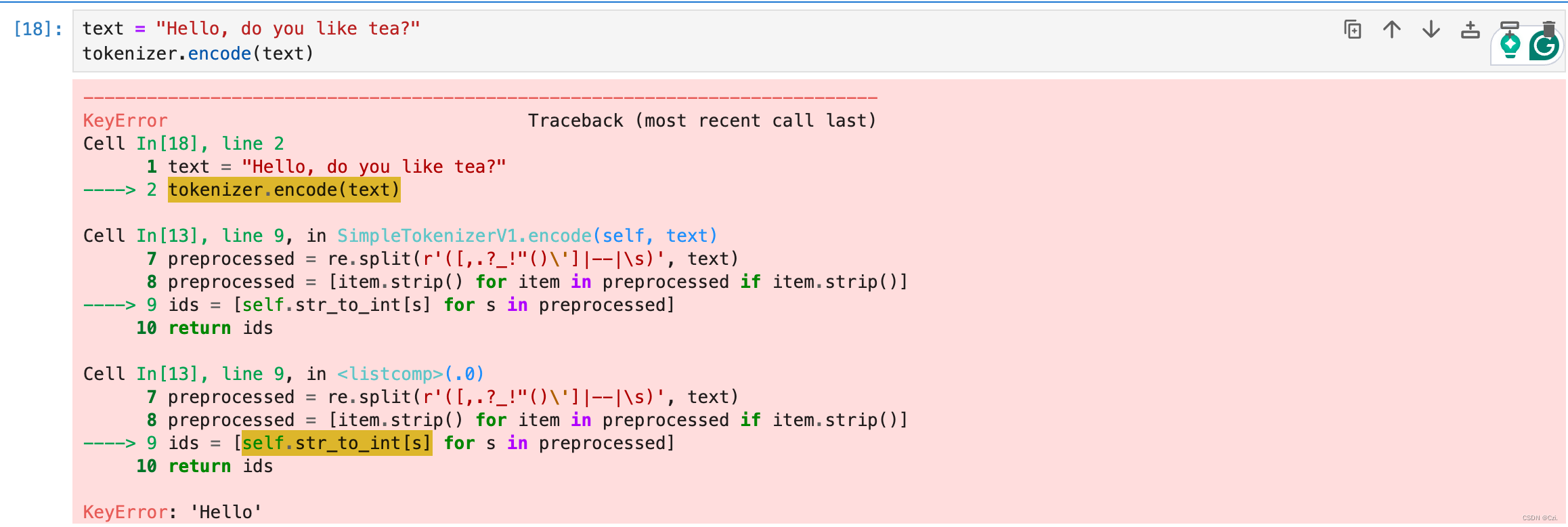
问题是短篇小说中 没有使用“Hello” 这个词。因此,它不包含在词汇中。这凸显了在使用LLM时需要考虑大型且多样化的训练集来扩展词汇量。
在下一节中,我们将在包含未知单词的文本上进一步测试tokenizer,我们还将讨论其他特殊tokens,这些tokens可用于在训练期间为 LLM 提供进一步的上下文。
2.4 添加特殊上下文tokens (Adding special context tokens)
在上一节中,我们实现了一个简单的 分词器(tokenizer) 并将其应用于训练集中的段落。在本节中,我们将修改此分词器以处理未知单词。
我们还将讨论特殊上下文tokens的使用和添加,这些tokens可以增强模型对文本中上下文或其他相关信息的理解。例如,这些特殊tokens可以包括未知单词和文档边界的markers。
特别是,我们将修改上一节中实现的词汇表和分词器 ,SimpleTokenizerV2以支持两个新tokens:<|unk|>和<|endoftext|>,如图 2.9 所示。
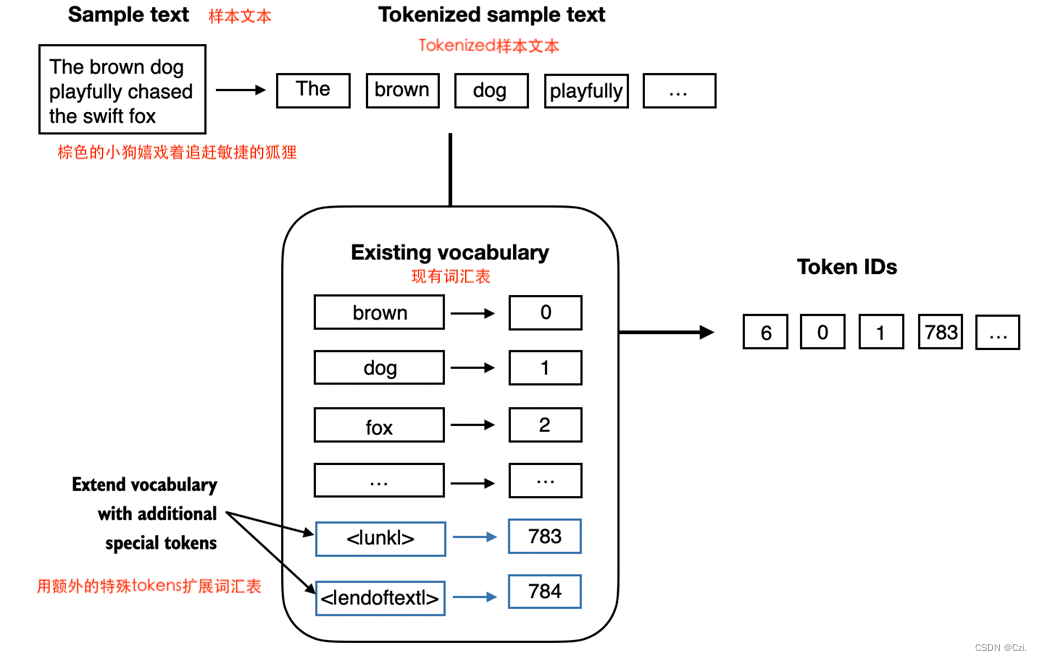
图 2.9 我们向词汇表中添加特殊tokens来处理某些上下文。例如,我们添加一个 <|unk|> tokens来表示新的和未知的单词,这些单词不属于训练数据,因此也不属于现有词汇表。此外,我们添加一个 <|endoftext|> tokens,可用于分隔两个不相关的文本源。
如图 2.9 所示,我们可以修改分词器,使其在遇到不属于词汇表的单词时使用<|unk|>token。此外,我们在不相关的文本之间添加了一个token。例如,当在多个独立文档或书籍上训练类似 GPT 的 LLM 时,通常会在前一个文本源后面的每个文档或书籍之前插入一个token,如图 2.10 所示。这有助于LLM了解,尽管这些文本源是为了训练而串联起来的,但实际上它们是不相关的。

图 2.10 当使用多个独立的文本源时,我们在这些文本之间添加 <|endoftext|> tokens。这些 <|endoftext|> tokens充当markers,表示特定片段的开始或结束,从而允许LLM进行更有效的处理和理解。
现在让我们修改词汇表以包含这两个特殊tokens和<|endoftext|>,将它们添加到我们在上一节中创建的所有唯一单词的列表中:
preprocessed = re.split(r'([,.?_!"()\']|--|\s)', raw_text)
preprocessed = [item.strip() for item in preprocessed if item.strip()]
all_tokens = sorted(list(set(preprocessed)))
all_tokens.extend(["<|endoftext|>", "<|unk|>"])
vocab = {token:integer for integer,token in enumerate(all_tokens)}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
len(vocab.items())
- 1
1161
根据上面 print 语句的输出,新的词汇量为 1161(上一节中的词汇量为 1159)。
作为额外的快速检查,让我们打印更新词汇表的最后 5 个条目:
for i, item in enumerate(list(vocab.items())[-5:]):
print(item)
- 1
- 2
('younger', 1156) ('your', 1157) ('yourself', 1158) ('<|endoftext|>', 1159) ('<|unk|>', 1160)
根据上面的代码输出,我们可以确认这两个新的特殊tokens确实已成功合并到词汇表中。接下来,我们相应地调整代码SimpleTokenizerV1中的分词器,如SimpleTokenizerV2 所示:
class SimpleTokenizerV2: def __init__(self, vocab): self.str_to_int = vocab self.int_to_str = { i:s for s,i in vocab.items()} def encode(self, text): preprocessed = re.split(r'([,.?_!"()\']|--|\s)', text) preprocessed = [item.strip() for item in preprocessed if item.strip()] preprocessed = [item if item in self.str_to_int else "<|unk|>" for item in preprocessed] ids = [self.str_to_int[s] for s in preprocessed] return ids def decode(self, ids): text = " ".join([self.int_to_str[i] for i in ids]) # Replace spaces before the specified punctuations text = re.sub(r'\s+([,.?!"()\'])', r'\1', text) return text
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
与我们在上一节的SimpleTokenizerV1中实现的相比,新的代码SimpleTokenizerV2用 <|unk|> tokens替换了未知单词。
现在让我们在实践中尝试一下这个新的分词器。为此,我们将使用一个简单的文本示例,该示例由两个独立且不相关的句子连接而成:
tokenizer = SimpleTokenizerV2(vocab)
text1 = "Hello, do you like tea?"
text2 = "In the sunlit terraces of the palace."
text = " <|endoftext|> ".join((text1, text2))
print(text)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Hello, do you like tea? <|endoftext|> In the sunlit terraces of the palace.
tokenizer.encode(text)
- 1
[1160, 5, 362, 1155, 642, 1000, 10, 1159, 57, 1013, 981, 1009, 738, 1013, 1160, 7]
在上面,我们可以看到token IDs 列表包含 <|endoftext|> 分隔符令牌 1159 以及两个用于未知单词的 1160 令牌。
让我们对文本进行去de-tokenize以进行快速健全性检查:
tokenizer.decode(tokenizer.encode(text))
- 1
'<|unk|>, do you like tea? <|endoftext|> In the sunlit terraces of the <|unk|>.'
1. “Hello” 和 “palace” 都被编码为相同的 token ID —— 在这种情况下是 <|unk|> —— 那么在解码阶段实际上是无法区分这两个词的。分词器无法从同一的 <|unk|> 代号中重建原始词汇,因为它已经失去了关于哪个 <|unk|> 对应于哪个原始词汇的信息。
2. 在大多数情况下,未知词的确切身份对于模型的后续处理并不重要,因为模型通常依赖于上下文来理解或生成文本。
通过将上面的de-tokenized文本与原始输入文本进行比较,我们知道训练数据集(Edith Wharton的短篇小说《The Verdict》)不包含“Hello”和“palace”一词。
到目前为止,我们已经讨论了tokenization作为处理文本作为LLM输入的一个重要步骤。根据LLM,一些研究人员还考虑其他特殊tokens,例如:
- [BOS](序列开始):此token marks(marks,标记)文本的开始。对于LLM来说,它意味着一段内容的开始。
- [EOS](序列结束):此token位于文本的末尾,在连接多个不相关的文本时特别有用,类似于<|endoftext|>。例如,当组合两篇不同的维基百科文章或书籍时,[EOS]token指示一篇文章的结束位置和下一篇文章的开始位置。
- [PAD](padded):当训练批次大小大于 1 的 LLM 时,批次可能包含不同长度的文本。为了确保所有文本具有相同的长度,较短的文本将使用令牌进行扩展或“padded” [PAD],直到批次中最长文本的长度。
请注意,用于GPT模型的分词器不需要使用上述任何提到的特殊tokens,而只使用一个简单的<|endoftext|> token 。这个<|endoftext|>类似于上面提到的 [EOS] token。此外,该<|endoftext|> token也用于padding。然而,正如我们将在后续章节中探讨的,当在批量输入上训练时,我们通常使用掩码,这意味着我们不关注填充的tokens。因此,选择用于填充的特定tokens变得不重要。
此外,用于GPT模型的分词器也不使用任何专门的<|unk|> token来处理词汇表外的词。相反,GPT模型使用byte pair encoding tokenizer字节对编码分词器,该分词器将单词拆分为子词单元,我们将在下一节中讨论这一点。
2.4 字节对编码(Byte pair encoding)
为了说明的目的,我们在前面的部分中实现了一个简单的tokenization方案。本节介绍基于字节对编码 (BPE) 概念的更复杂的tokenization方案。本节介绍的 BPE tokenizer用于训练 LLM,例如 GPT-2、GPT-3 和 ChatGPT 中使用的原始模型。
由于实现 BPE 可能相对复杂,我们将使用现有的 Python 开源库tiktoken(https://github.com/openai/tiktoken),它基于 Rust 源代码非常有效地实现了 BPE 算法。与其他Python库类似,我们可以通过Python的pip安装程序从终端安装tiktoken库:
# pip install tiktoken
import importlib
import tiktoken
print("tiktoken version:", importlib.metadata.version("tiktoken"))
- 1
- 2
- 3
- 4
- 5
安装完成后,我们可以从 tiktoken 实例化 BPE tokenizer,如下所示:
tokenizer = tiktoken.get_encoding("gpt2")
- 1
这个 tokenizer 的用法与我们之前通过方法实现的 SimpleTokenizerV2 的encode方法类似:
text = "Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace."
integers = tokenizer.encode(text, allowed_special={"<|endoftext|>"})
print(integers)
- 1
- 2
- 3
- 4
- 5
上面的代码打印以下token IDs:
[15496, 11, 466, 345, 588, 8887, 30, 220, 50256, 554, 262, 4252, 18250, 8812, 2114, 286, 617, 34680, 27271, 13]
然后我们可以使用解码方法将token IDs 转换回文本,类似于我们SimpleTokenizerV2之前的操作:
strings = tokenizer.decode(integers)
print(strings)
- 1
- 2
- 3
Hello, do you like tea? <|endoftext|> In the sunlit terraces of someunknownPlace.
根据上面的token IDs 和解码文本,我们可以做出两个值得注意的观察。首先,<|endoftext|>给token分配一个比较大的token ID,即50256。 实际上,用于训练GPT-2、GPT-3等模型以及ChatGPT中使用的原始模型的BPE tokenizer总共有词汇量大小为 50,257,并<|endoftext|>分配了最大的token IDs。
其次,上面的 BPE 分词器可以正确编码和解码未知单词, 例如“someunknownPlace”。 BPE 分词器可以处理任何未知单词。它如何在不使用<|unk|>代币的情况下实现这一目标?
BPE 的底层算法将不在其预定义词汇表中的单词分解为更小的子词单元甚至单个字符,使其能够处理词汇表之外的单词。因此,借助 BPE 算法,如果分词器在tokenization过程中遇到不熟悉的单词,它可以将其表示为一系列子词tokens或字符,如图 2.11 所示。
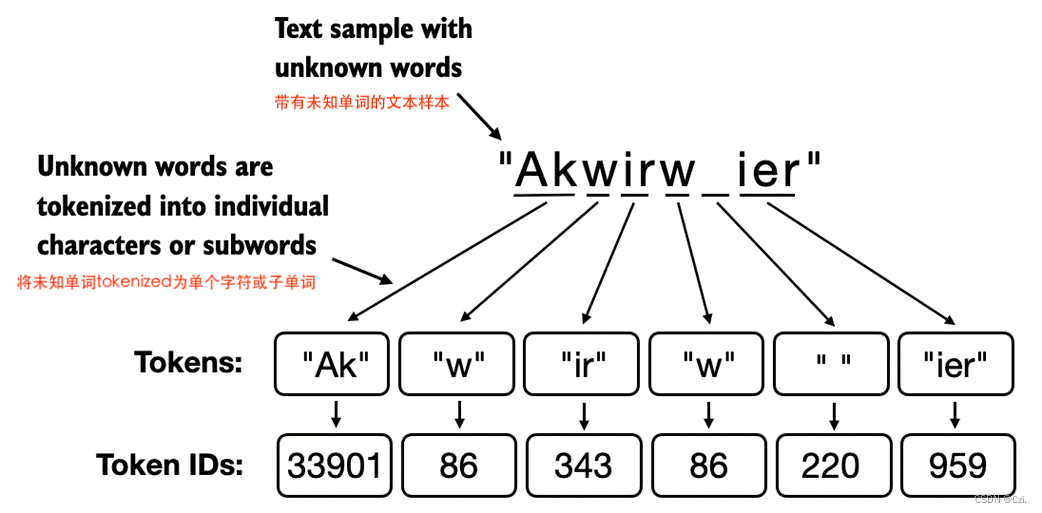
图 2.11 BPE 分词器将未知单词分解为子单词和单个字符。这样,BPE tokenizer就可以解析任何单词,并且不需要用特殊tokens(例如 <|unk|>)替换未知单词。
如图 2.11 所示,将未知单词分解为单个字符的能力确保分词器以及用它训练的LLM可以处理任何文本,即使它包含训练数据中不存在的单词。
练习2.1题目 未知词的字节对编码
尝试使用 tiktoken 库中的 BPE tokenizer生成器处理未知单词“Akwirw ier”,并打印各个token IDs。然后,对该列表中的每个结果整数调用解码函数,以重现图 2.11 中所示的映射。最后,调用token IDs 上的解码方法来检查它是否可以重建原始输入“Akwirw ier”。
答案如下:
#安装环境 import importlib import tiktoken print("tiktoken version:", importlib.metadata.version("tiktoken")) #实例化 tokenizer = tiktoken.get_encoding("gpt2") text = "Akwirw ier" #调用encode integers = tokenizer.encode(text) print(integers) #调用decode strings = tokenizer.decode(integers) print(strings)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
tiktoken version: 0.6.0 [33901, 86, 343, 86, 220, 959] Akwirw ier
BPE 的详细讨论和实现超出了本书的范围,但简而言之,它通过迭代地将频繁出现的字符合并为子词以及将频繁出现的子词合并为单词来构建词汇表。例如,BPE 首先将所有单独的单个字符添加到其词汇表中(“a”、“b”…)。在下一阶段,它将经常一起出现的字符组合合并为子词。例如,“d”和“e”可以合并为子词“de”,这在许多英语单词中很常见,例如“define”、“depend”、“made”和“hidden”。合并由频率截止决定。
2.6 滑动窗口数据采样(Data sampling with a sliding window)
上一节详细介绍了tokenization步骤以及从字符串tokens到整数token IDs 的转换。在我们最终为 LLM 创建嵌入之前,下一步是生成训练 LLM 所需的输入-目标对(input-target pairs)。
这些输入-目标对是什么样的?正如我们在第 1 章中了解到的,LLM 通过预测文本中的下一个单词来进行预训练,如图 2.12 所示。

图2.12 给定一个文本样本,提取输入块作为子样本,作为LLM的输入,LLM在训练期间的预测任务是预测输入块后面的下一个单词。在训练过程中,我们屏蔽掉所有超出目标的单词。请注意,该图中显示的文本将在 LLM 处理之前进行tokenization;然而,为了清楚起见,该图省略了tokenization步骤。
在本节中,我们实现一个数据加载器,它使用滑动窗口方法从训练数据集中获取图 2.12 中所示的输入-目标对。
首先,我们将首先使用上一节中介绍的 BPE 分词器对我们之前处理过的整个 The Verdict 短篇故事进行tokenize:
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
enc_text = tokenizer.encode(raw_text)
print(len(enc_text))
- 1
- 2
- 3
- 4
- 5
5145
应用 BPE 分词器后,执行上述代码将返回 5145,即训练集中的tokens总数。
接下来,出于演示目的,我们从数据集中删除前 50 个tokens,因为这会在接下来的步骤中产生稍微更有趣的文本段落:
enc_sample = enc_text[50:]
- 1
为下一个单词预测任务创建输入-目标对的最简单、最直观的方法之一是创建两个变量x和y,其中x包含输入tokens,y包含目标,即输入移位 1:
context_size = 4
x = enc_sample[:context_size]
y = enc_sample[1:context_size+1]
print(f"x: {x}")
print(f"y: {y}")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
x: [290, 4920, 2241, 287] y: [4920, 2241, 287, 257]
处理输入和目标(即移动一个位置的输入),然后我们可以创建图 2.12 中所示的下一个单词预测任务,如下所示:
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(context, "---->", desired)
- 1
- 2
- 3
- 4
- 5
[290] ----> 4920
[290, 4920] ----> 2241
[290, 4920, 2241] ----> 287
[290, 4920, 2241, 287] ----> 257
箭头 ( ---->) 左侧的所有内容均指 LLM 将接收的输入,箭头右侧的token IDs 表示 LLM 应该预测的目标token IDs。
出于说明目的,让我们重复前面的代码,但将token IDs 转换为文本:
for i in range(1, context_size+1):
context = enc_sample[:i]
desired = enc_sample[i]
print(tokenizer.decode(context), "---->", tokenizer.decode([desired]))
- 1
- 2
- 3
- 4
- 5
and ----> established
and established ----> himself
and established himself ----> in
and established himself in ----> a
我们现在已经创建了输入-目标对,可以将其用于后续章节中的 LLM 训练。
正如我们在本章开头提到的,在我们将tokens转换为embeddings之前,只剩下一个任务:实现一个高效的数据加载器,它迭代输入数据集并将输入和目标作为 PyTorch 张量返回,这可以被认为是作为多维数组。
特别是,我们有兴趣返回两个张量:一个包含 LLM 看到的文本的输入张量和一个包含 LLM 预测目标的目标张量,如图 2.13 所示。

图 2.13 为了实现高效的数据加载器,我们收集张量 x 中的输入,其中每一行代表一个输入上下文。第二个张量 y 包含相应的预测目标(下一个单词),这些目标是通过将输入移动一个位置来创建的。
虽然图 2.13 出于说明目的显示了字符串格式的tokens,但代码实现将直接对token IDs 进行操作,因为encode BPE tokenizer的方法将tokenization和转换为token IDs的方法作为一个步骤执行。
为了实现高效的数据加载器实现,我们将使用 PyTorch 的内置 Dataset 和 DataLoader 类。。
dataset类的代码如下所示:
# 批量输入和目标的数据集 from torch.utils.data import Dataset, DataLoader class GPTDatasetV1(Dataset): def __init__(self, txt, tokenizer, max_length, stride): self.input_ids = [] self.target_ids = [] # Tokenize the entire text token_ids = tokenizer.encode(txt, allowed_special={"<|endoftext|>"}) # Use a sliding window to chunk the book into overlapping sequences of max_length for i in range(0, len(token_ids) - max_length, stride): input_chunk = token_ids[i:i + max_length] target_chunk = token_ids[i + 1: i + max_length + 1] self.input_ids.append(torch.tensor(input_chunk)) self.target_ids.append(torch.tensor(target_chunk)) def __len__(self): return len(self.input_ids) def __getitem__(self, idx): return self.input_ids[idx], self.target_ids[idx]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这段代码定义了一个名为 GPTDatasetV1 的类,它是用于训练 GPT 类型的语言模型的数据集类。这个类继承自 PyTorch 的 Dataset 基类,用于处理文本数据,使其适应于神经网络训练。下面是对这段代码的逐步解读:
-
初始化 (
__init__方法):__init__方法接收四个参数:txt(原始文本数据),tokenizer(用于文本编码的分词器),max_length(输入序列的最大长度),和stride(滑动窗口的步长)。input_ids和target_ids是两个列表,用于存储经过分词和编码后的输入和目标序列。
-
文本编码:
- 使用传入的
tokenizer的encode方法将整个文本txt编码为一个 ID 列表(token_ids)。allowed_special={""}参数的具体用途在这里不太清楚,可能是用于控制哪些特殊字符可以包含在编码中,或者可能是一个错误或遗漏。
- 使用传入的
-
滑动窗口切分:
- 代码通过一个 for 循环和滑动窗口的方法将整个文本分割成重叠的序列。每个窗口包含
max_length个 token。 input_chunk是从位置i到i + max_length的 token 序列,而target_chunk是从位置i + 1到i + max_length + 1的 token 序列。这意味着target_chunk对于input_chunk是向前错一位的,这样设计是为了训练语言模型进行下一个词预测。- 将每个
input_chunk和target_chunk转换成 PyTorch 的torch.tensor,并添加到input_ids和target_ids列表中。
- 代码通过一个 for 循环和滑动窗口的方法将整个文本分割成重叠的序列。每个窗口包含
-
长度 (
__len__方法):- 这个方法返回数据集中样本的总数,即
input_ids列表的长度。
- 这个方法返回数据集中样本的总数,即
-
获取项目 (
__getitem__方法):- 这个方法根据索引
idx返回一个样本,包括一个输入 ID 序列和对应的目标 ID 序列。
- 这个方法根据索引
总的来说,这个类为 GPT 模型的训练准备了处理好的文本数据,通过创建输入序列及其对应的目标序列(每个输入序列的下一个词),以支持模型学习预测下一个词的任务。这种数据准备方式是训练所有类型的自回归语言模型的典型方法。
类GPTDatasetV1基于 PyTorch类,并定义如何从数据集中获取各个行,其中每一行包含许多token IDs (基于 max _ length) ,分配给一个input_chunk 张量。Ttarget_chunk 张量包含相应的目标。我建议继续阅读,看看当我们将数据集与 PyTorch DataLoader 组合时,从该数据集返回的数据是什么样子——这将带来额外的直观性和清晰性。
下面的代码将使用 GPTDatasetV1通过 PyTorch DataLoader 批量加载输入:
def create_dataloader_v1(txt, batch_size=4, max_length=256, stride=128, shuffle=True, drop_last=True, num_workers=0): # Initialize the tokenizer tokenizer = tiktoken.get_encoding("gpt2") # Create dataset dataset = GPTDatasetV1(txt, tokenizer, max_length, stride) # Create dataloader dataloader = DataLoader( dataset, batch_size=batch_size, shuffle=shuffle, drop_last=drop_last, num_workers=0 ) return dataloader
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
这段代码定义了一个名为 create_dataloader_v1 的函数,它用于生成一个 PyTorch 数据加载器 (DataLoader),这个加载器针对的是用于训练 GPT 类型模型的数据集。这个函数的目的是将文本数据转换为适合机器学习训练的格式,同时提供一些灵活的配置选项。下面是对这个函数的详细解读:
-
参数列表:
txt: 用于训练的原始文本数据。batch_size: 数据加载器每批次加载的数据量,默认为4。max_length: 每个输入序列的最大长度,默认为256。stride: 滑动窗口的步长,默认为128。这决定了序列之间的重叠程度。shuffle: 是否在每个训练周期开始时打乱数据,默认为True。drop_last: 是否在数据样本数不足以形成一个完整批次时丢弃最后一批数据,默认为True。num_workers: 用于数据加载的工作进程数,默认为0。
-
初始化分词器:
- 代码中首先初始化一个分词器
tokenizer,这里假设tiktoken.get_encoding("gpt2")是一个获取 GPT-2 模型编码方式的函数。这个分词器用于将文本转换成模型可以理解的数值格式(通常是 token ID)。
- 代码中首先初始化一个分词器
-
创建数据集:
- 使用
GPTDatasetV1类和提供的参数创建一个数据集实例dataset。这个类负责将文本数据按照给定的max_length和stride处理成模型训练所需的格式。
- 使用
-
创建数据加载器:
- 使用 PyTorch 的
DataLoader类创建一个数据加载器dataloader。这个加载器负责管理数据的批处理、洗牌和多进程加载等操作。 shuffle参数控制是否随机打乱数据顺序,这对于训练模型是有好处的,因为它可以减少模型对数据顺序的依赖,提高泛化能力。drop_last参数确保所有的训练批次都有完整的数据量,避免最后一批数据因数量不足影响模型训练。num_workers指定加载数据时使用的进程数,多进程可以加快数据加载速度,特别是在大规模数据集上。
- 使用 PyTorch 的
-
返回值:
- 函数返回创建好的
dataloader,它将被用于模型的训练循环中,提供批量的训练数据。
- 函数返回创建好的
这个函数是一个完整的数据预处理和加载流程的封装,使得使用者可以方便地根据需要配置和使用数据加载器,以适应不同的训练需求。
让我们dataloader对上下文大小为 4 的 LLM 进行批量大小为 1 的测试,以直观地了解GPTDatasetV1类和create_dataloader_v1函数如何协同工作:
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
dataloader = create_dataloader_v1(raw_text, batch_size=1, max_length=4, stride=1, shuffle=False)
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)
second_batch = next(data_iter)
print(second_batch)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这段代码展示了如何使用一个文本文件和之前定义的 create_dataloader_v1 函数来创建和使用数据加载器 (DataLoader),用于生成训练神经网络模型的数据批次。这里是逐步解读:
-
打开并读取文本文件:
- 使用 Python 的
open函数以只读模式打开一个名为 “the-verdict.txt” 的文本文件。文件以 UTF-8 编码方式打开,这通常是处理文本数据的标准编码。 raw_text = f.read()读取文件的全部内容到字符串raw_text中。
- 使用 Python 的
-
创建数据加载器:
- 使用之前定义的
create_dataloader_v1函数创建一个数据加载器。传递参数包括:txt=raw_text:要处理的文本。batch_size=1:每个数据批次包含1个样本。max_length=4:每个数据样本的长度为4个token。stride=1:滑动窗口的步长为1,意味着每个输入序列之间只有1个token的差异。shuffle=False:在训练时不打乱数据,这有助于在测试或演示中看到数据的顺序性。
- 使用之前定义的
-
迭代和提取数据批次:
data_iter = iter(dataloader)创建了一个迭代器data_iter,用于逐个访问数据加载器中的批次。first_batch = next(data_iter)和second_batch = next(data_iter)分别获取数据加载器中的第一个和第二个数据批次。- 打印这些批次以展示它们的内容。因为每个批次的大小 (
batch_size) 为1,且每个样本长度为4,每次调用next(data_iter)应该返回一个包含一个样本的批次。
-
输出解释:
- 打印的每个批次 (
first_batch和second_batch) 应该显示了两组数据:input_ids和target_ids,其中target_ids是input_ids的下一个token序列。例如,如果input_ids是 [token1, token2, token3, token4],那么target_ids将是 [token2, token3, token4, token5]。
- 打印的每个批次 (
通过这种方式,这段代码有效地准备和展示了用于训练序列模型(如 GPT)的数据,其中模型需要从给定的输入序列预测下一个token序列。这对于理解数据加载和预处理流程是非常有帮助的,尤其是在准备自然语言处理任务时。
print(first_batch)
- 1
[tensor([[ 40, 367, 2885, 1464]]), tensor([[ 367, 2885, 1464, 1807]])]
该first_batch变量包含两个张量:第一个张量存储输入token IDs,第二个张量存储目标token IDs。由于max_length被设置为 4,因此两个张量中的每一个都包含 4 个token IDs。请注意,输入大小 4 相对较小,仅为说明目的而选择。训练 LLM 的输入大小至少为 256 是很常见的。
为了说明 的含义stride=1,让我们从此数据集中获取另一批:
print(second_batch)
- 1
[tensor([[ 367, 2885, 1464, 1807]]), tensor([[2885, 1464, 1807, 3619]])]
如果我们比较第一个和第二个批次,我们可以看到第二个批次的 token IDs 与第一个批次相比移动了一个位置(例如,第一个批次输入中的第二个 ID 是 367,这是第二批的第一个 ID输入)。该stride设置规定了输入在批次之间移动的位置数量,模拟滑动窗口方法,如图 2.14 所示。

图 2.14 当从输入数据集创建多个批次时,我们在文本上滑动输入窗口。如果步幅设置为 1,我们在创建下一批时将输入窗口移动 1 个位置。如果我们将步幅设置为等于输入窗口大小,则可以防止批次之间的重叠。
练习 2.2 具有不同步长和上下文大小的数据加载器
为了更直观地了解数据加载器的工作原理,请尝试使用不同的设置来运行它,例如 max_length=2 和 stride=2 以及 max_length=8 和 stride=2。
答案如下
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
dataloader = create_dataloader_v1(raw_text, batch_size=1, max_length=8, stride=1, shuffle=False)
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)
second_batch = next(data_iter)
print(second_batch)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[tensor([[ 40, 367, 2885, 1464, 1807, 3619, 402, 271]]), tensor([[ 367, 2885, 1464, 1807, 3619, 402, 271, 10899]])]
[tensor([[ 367, 2885, 1464, 1807, 3619, 402, 271, 10899]]), tensor([[ 2885, 1464, 1807, 3619, 402, 271, 10899, 2138]])]
with open("the-verdict.txt", "r", encoding="utf-8") as f:
raw_text = f.read()
dataloader = create_dataloader_v1(raw_text, batch_size=1, max_length=8, stride=2, shuffle=False)
data_iter = iter(dataloader)
first_batch = next(data_iter)
print(first_batch)
second_batch = next(data_iter)
print(second_batch)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
[tensor([[ 40, 367, 2885, 1464, 1807, 3619, 402, 271]]), tensor([[ 367, 2885, 1464, 1807, 3619, 402, 271, 10899]])]
[tensor([[ 2885, 1464, 1807, 3619, 402, 271, 10899, 2138]]), tensor([[ 1464, 1807, 3619, 402, 271, 10899, 2138, 257]])]
批量大小为 1(例如我们迄今为止从数据加载器中采样的)对于说明目的很有用。如果您以前有过深度学习的经验,您可能知道小批量在训练期间需要较少的内存,但会导致模型更新的噪声更大。就像常规深度学习一样,批量大小是训练 LLM 时需要进行权衡和实验的超参数。
在我们继续讨论本章的最后两个部分(重点是从token IDs 创建嵌入向量)之前,让我们简要了解一下如何使用数据加载器以大于 1 的批量大小进行采样:
dataloader = create_dataloader_v1(raw_text, batch_size=8, max_length=4, stride=4, shuffle=False)
data_iter = iter(dataloader)
inputs, targets = next(data_iter)
print("Inputs:\n", inputs)
print("\nTargets:\n", targets)
- 1
- 2
- 3
- 4
- 5
- 6
Inputs:
tensor([[ 40, 367, 2885, 1464],
[ 1807, 3619, 402, 271],
[10899, 2138, 257, 7026],
[15632, 438, 2016, 257],
[ 922, 5891, 1576, 438],
[ 568, 340, 373, 645],
[ 1049, 5975, 284, 502],
[ 284, 3285, 326, 11]])
Targets:
tensor([[ 367, 2885, 1464, 1807],
[ 3619, 402, 271, 10899],
[ 2138, 257, 7026, 15632],
[ 438, 2016, 257, 922],
[ 5891, 1576, 438, 568],
[ 340, 373, 645, 1049],
[ 5975, 284, 502, 284],
[ 3285, 326, 11, 287]])
请注意,我们将步长增加到 4。这是为了充分利用数据集(我们不跳过单个单词),但也避免批次之间的任何重叠,因为更多的重叠可能会导致过度拟合增加。
在本章的最后两节中,我们将实现嵌入层,将 token IDs 转换为连续向量表示,作为 LLM 的输入数据格式。
2.7 创建token嵌入(Creating token embeddings)
为 LLM 训练准备输入文本的最后一步是将 token IDs 转换为embedding vectors,如图 2.15 所示,这将是本章最后两个剩余部分的重点。

图 2.15 为 LLM 准备输入文本涉及对文本进行tokenizing、将文本tokens转换为token IDs,以及将token IDs 转换为向量embedding vectors。在本节中,我们考虑前面几节中创建的 token IDs 来创建 token 嵌入向量。
除了图 2.15 中概述的过程之外,值得注意的是,我们使用随机值初始化这些嵌入权重作为初步步骤。此初始化是LLM学习过程的起点。我们将优化嵌入权重,作为第 5 章 LLM 训练的一部分。
连续向量表征或嵌入是必要的,因为类似 GPT 的 LLM 是使用反向传播算法训练的深度神经网络。
让我们通过一个实际示例来说明token IDs 到嵌入向量的转换是如何工作的。假设我们有以下四个 ID 为 2、3、5 和 1 的输入tokens:
input_ids = torch.tensor([2, 3, 5, 1])
- 1
为了简单起见和说明目的,假设我们的词汇量很小,只有 6 个单词(而不是 BPE 分词器词汇表中的 50,257 个单词),并且我们想要创建大小为 3 的嵌入(在 GPT-3 中,嵌入大小为是 12,288 维):
使用vocab_size和output_dim,我们可以在 PyTorch 中实例化嵌入层,将随机种子设置为 123 以实现可重复性:
vocab_size = 6
output_dim = 3
torch.manual_seed(123)
embedding_layer = torch.nn.Embedding(vocab_size, output_dim)
print(embedding_layer.weight)
- 1
- 2
- 3
- 4
- 5
- 6
前面的代码示例中的 print 语句打印嵌入层的底层权重矩阵:
Parameter containing:
tensor([[ 0.3374, -0.1778, -0.1690],
[ 0.9178, 1.5810, 1.3010],
[ 1.2753, -0.2010, -0.1606],
[-0.4015, 0.9666, -1.1481],
[-1.1589, 0.3255, -0.6315],
[-2.8400, -0.7849, -1.4096]], requires_grad=True)
我们可以看到嵌入层的权重矩阵包含小的随机值。这些值在 LLM 训练期间作为 LLM 优化本身的一部分进行优化,我们将在接下来的章节中看到。此外,我们可以看到权重矩阵有六行三列。词汇表中六个可能的tokens各占一行。三个嵌入维度中的每一个维度都有一列。
实例化嵌入层后,现在将其应用于 token IDs 以获得嵌入向量:
print(embedding_layer(torch.tensor([3])))
- 1
- 2
返回的嵌入向量如下:
tensor([[-0.4015, 0.9666, -1.1481]], grad_fn=<EmbeddingBackward0>)
如果我们将token ID 3 的嵌入向量与之前的嵌入矩阵进行比较,我们会发现它与第 4 行相同(Python 从零索引开始,因此它是与索引 3 对应的行)。换句话说,嵌入层本质上是一个查找操作,通过token IDs 从嵌入层的权重矩阵中检索行。
嵌入层与矩阵乘法
对于那些熟悉 one-hot 编码的人来说,上面的嵌入层方法本质上只是一种更有效的方式来实现 one-hot 编码,然后在全连接层中进行矩阵乘法,这在 GitHub 上的补充代码中进行了说明:https
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

