
引言
- Google提出的Inception系列是分类任务中的代表性工作,不同于VGG简单地堆叠卷积层,Inception重视网络的拓扑结构。本文关注Inception系列方法的演变,并加入了Xception作为对比。
PS1:这里有一篇blog,作者Bharath Raj简洁明了地介绍这系列的工作:https://towardsdatascience.com/a-simple-guide-to-the-versions-of-the-inception-network-7fc52b863202,强烈建议阅读。
PS2:我看了比较多的blog,都没有介绍清楚V2和V3的区别。主要是因为V2的提出涉及到两篇paper,并且V2和V3是在一篇论文中提到的。实际上,它们两者的区别并不大。
InceptionV1
Going Deeper with Convolutions
核心思想
由于图像的突出部分可能有极大的尺寸变化,这为卷积操作选择正确的内核大小创造了困难,比如更全局的信息应该使用大的内核,而更局部的信息应该使用小内核。不妨在同一级运行多种尺寸的滤波核,让网络本质变得更"宽"而不是”更深“。

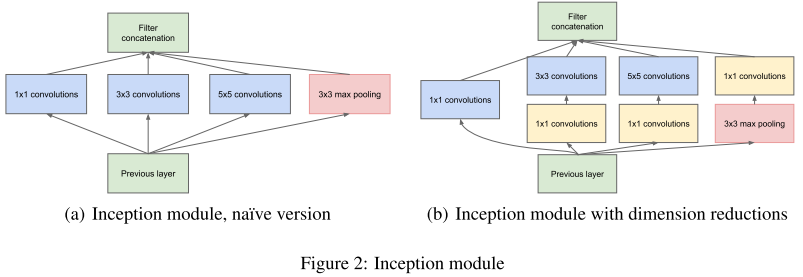
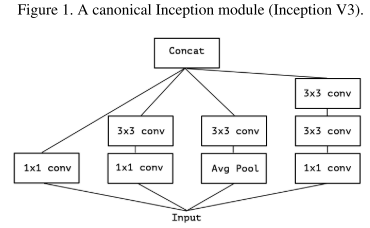
- 提出Inception模块(左),具有三种不同的滤波器(1x1,3x3,5x5)和max pooling。为降低计算量,GooLeNet借鉴Network-in-Network的思想,用1x1卷积降维减小参数量(右)。可在保持计算成本的同时增加网络的深度和宽度。
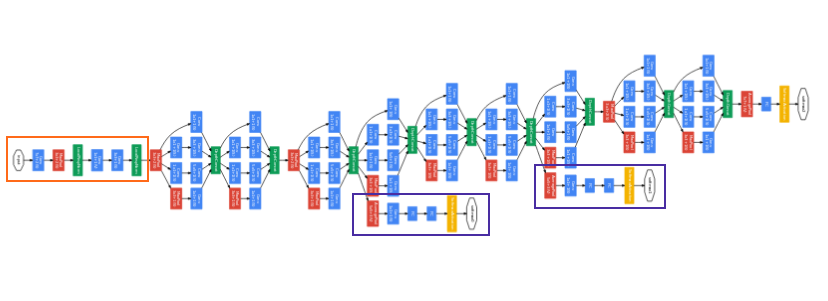
网络架构
- GoogLeNet具有9个Inception模块,22层深(27层包括pooling),并在最后一个Inception模块使用全局池化。
- 由于网络深度,将存在梯度消失vanishing gradient的问题。
- 为了防止网络中间部分消失,作者提出了两个辅助分类器auxiliary classifiers(紫色),总损失是实际损失和辅助损失的加权求和。
- # The total loss used by the inception net during training.
- total_loss = real_loss + 0.3 * aux_loss_1 + 0.3 * aux_loss_2
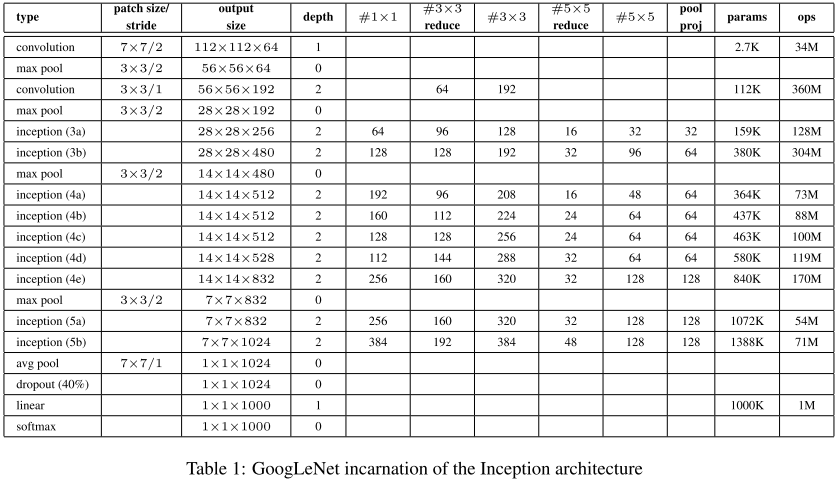
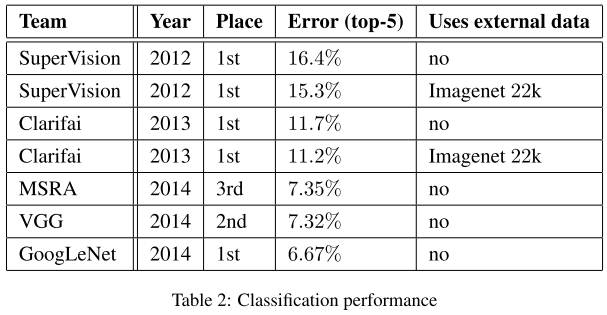
实验结果
InceptionV2
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Rethinking the Inception Architecture for Computer Vision
核心思想
- 使用Batch Normalization
将输出归一化为N(0,1正态分布,一方面可以采用较大的学习速率,加快收敛;另一方面BN具有正则效应。


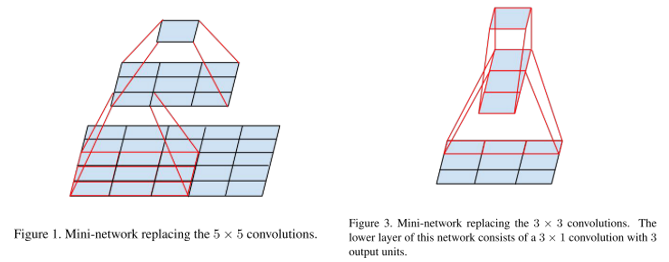
- 卷积分解Factorizing Convolutions
当卷积没有彻底改变输入维度时,神经网络表现更好。过度减小尺寸会导致信息丢失,称为"representational bottleneck",巧妙地使用分解(factorization)方法,可提高卷积的计算效率。
- 分解为更小的卷积:卷积可分解为两个卷积以提升计算效率,计算效率为原来的
- 分解为非对称卷积:卷积可分解为和的卷积。
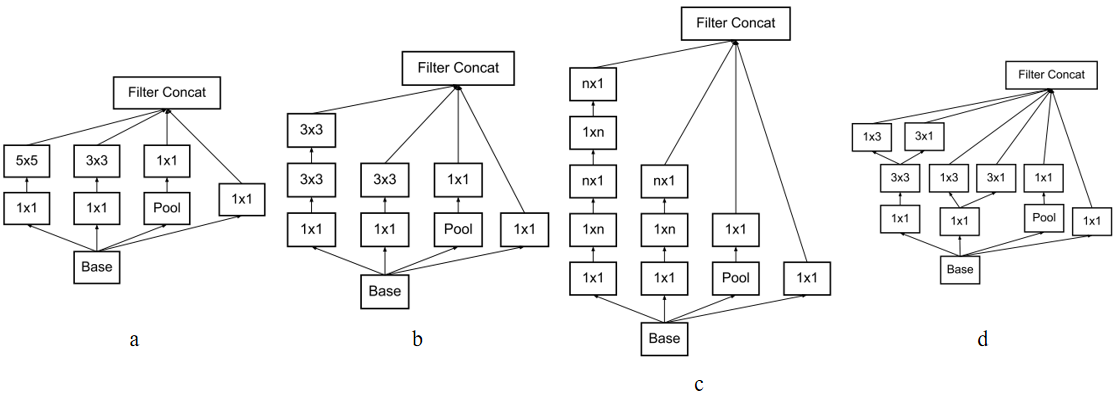
Inception的演化
a为InceptionV1;用两个3x3卷积替换5x5得到b;再将3x3卷积分解为3x1、1x3得c;在高层特征中,卷积组被拓展为d已产生更多不一样的特征。
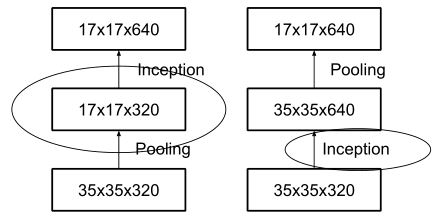
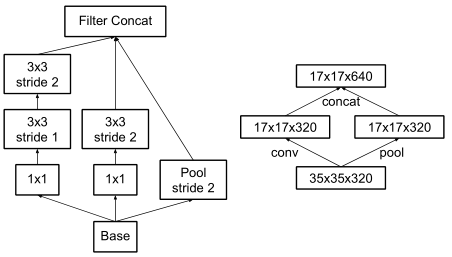
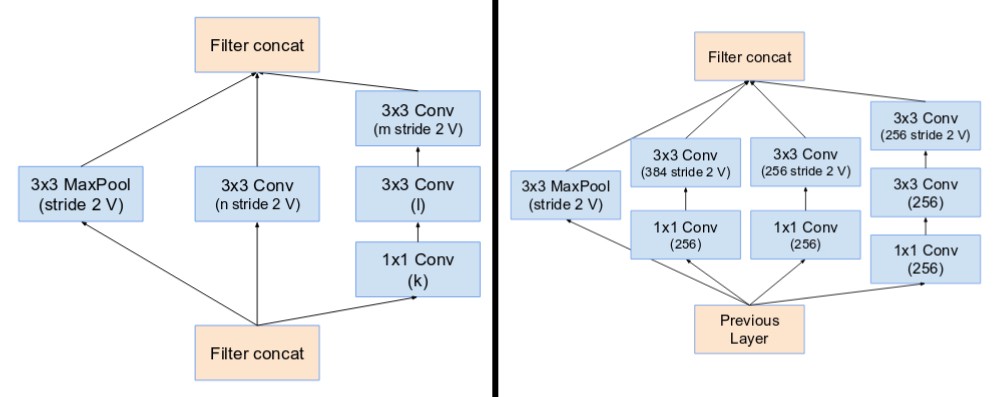
下采样模块
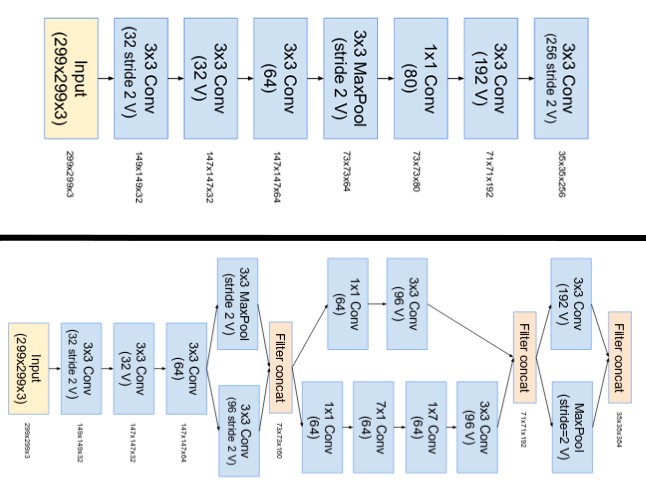
InceptionV3不再使用max pooling下采样,这样导致信息损失较大。于是作者想用conv升维,然后再pooling,但会带来较大的计算量,所以作者设计了一个并行双分支的结构Grid Size Reduction来取代max pooling。
网络结构
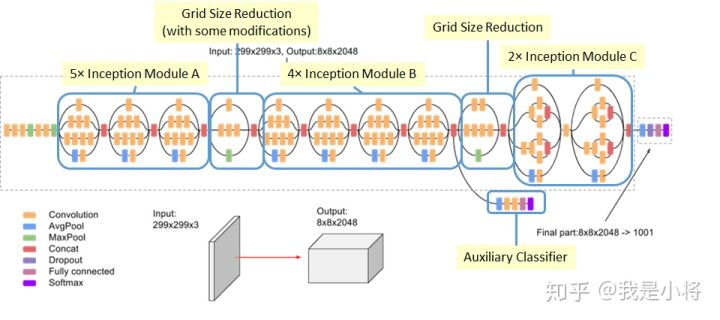
figure5、figure6、figure7分别表示上图的b、c、d,每种block之间加入Grid Size Reduction。

实验结果
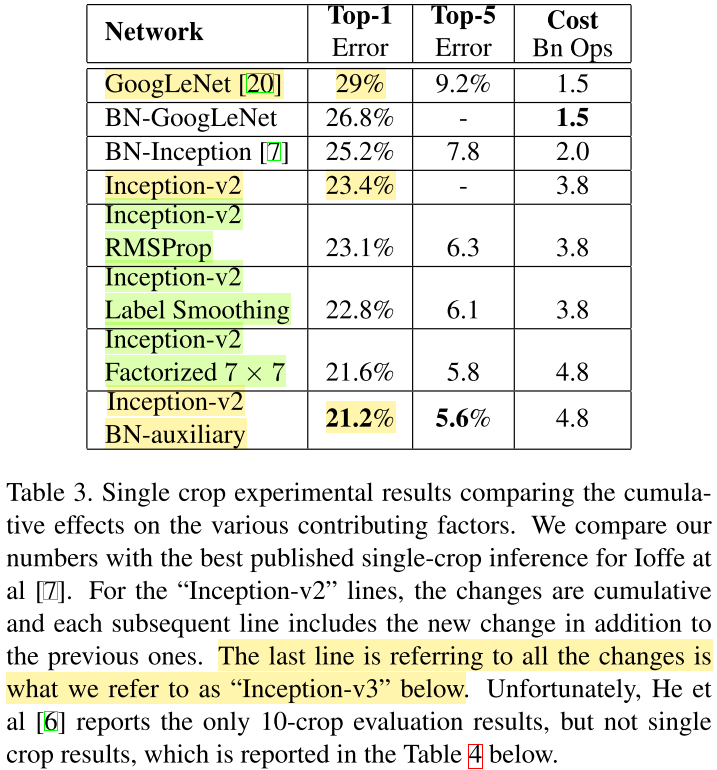
Inceptionv2达到23.4%,而Inceptionv3是指在Inceptionv2上同时使用RMSProp、Label Smoothing和分解7x7卷积、辅助分类器使用BN。
InceptionV3
Rethinking the Inception Architecture for Computer Vision
核心思想
作者指出,辅助分类器在训练即将结束时准确度接近饱和时才会有大的贡献。因此可以作正则化regularizes。
- V3在V2上作了如下改进,见V2实验结果:
- RMSProp Optimizer
- 分解7x7的卷积
- 辅助分类器采用BatchNorm
- Label Smoothing,防止过拟合。
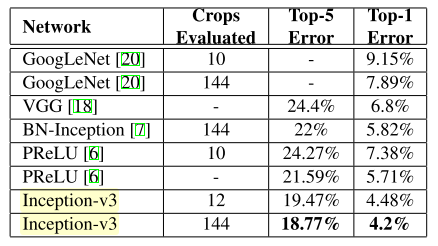
实验结果
InceptionV4
Inception-ResNet and the Impact of Residual Connections on Learning
这篇文章结合ResNet和Inception提出了三种新的网络结构
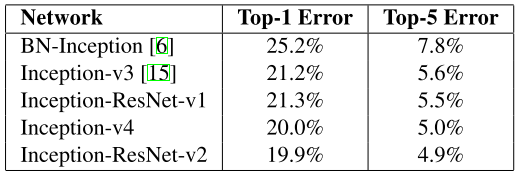
- Inception-ResNet-v1:混合版Inception,和InceptionV3有相同计算成本。
- Inception-ResNet-v2:计算成本更高,显著提高performance。
- InceptionV4:纯Inception变体,无residual连接,媲美Inception-ResNetV2
核心思想
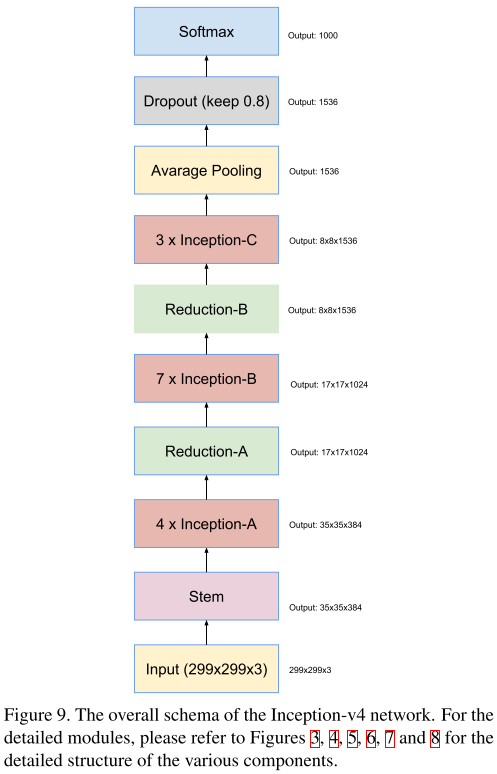
- InceptionV4是对原来的版本进行了梳理,因为原始模型是采用分区方式训练,而迁移到TensorFlow框架后可以对Inception模块进行一定的规范和简化。
网络架构
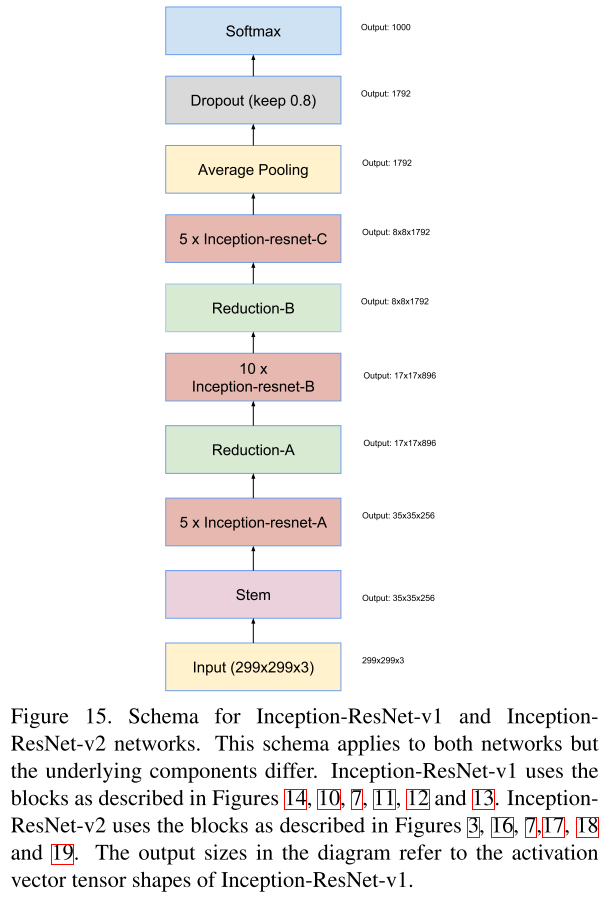
- Stem:Inception-ResNetV1采用了top,Inceptionv4和Inception-ResNetV2采用了bottom。
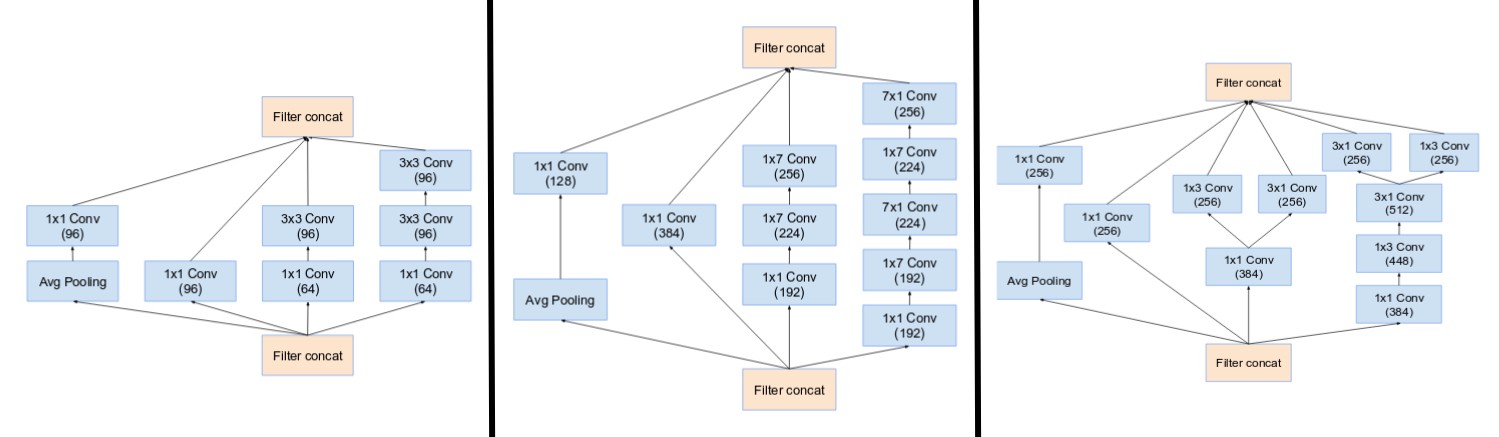
- Inception modules A,B,C
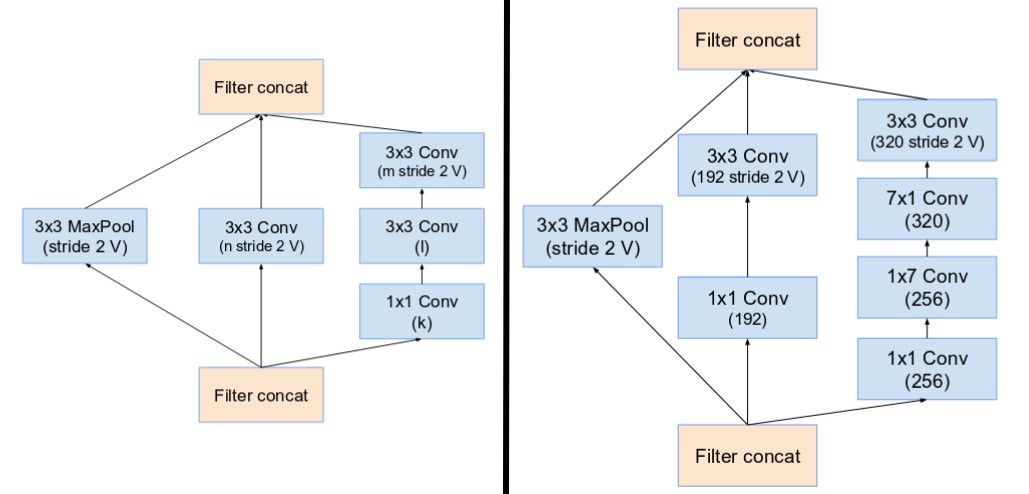
- Reduction Blocks A,B
- Network
Inception-ResNet
核心思想
- 受ResNet启发,提出一种混合版的Inception。Inception-ResNet有v1、v2版本。
- Inception-ResNetV1计算量与InceptionV3相似,Inception-ResNetV2计算量与InceptionV4相似。
- 它们有不同的steam。
- 它们的A、B、C模块相同,区别在于超参数设置。
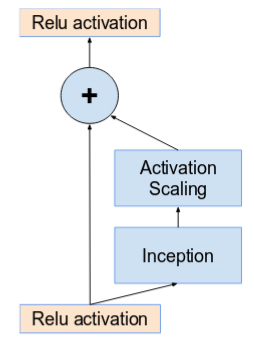
当卷积核数量超过1000时,更深的单元会导致网络死亡。因此为了增加稳定性,作者对残差激活值进行0.1-0.3的缩放。
网络架构
- Steam:见InceptionV4
- Inception-ResNet Module A,B,C

- Residual Blocks A,B
- Network
实验结果
Xception
核心思想
Xception: Deep Learning with Depthwise Separable Convolutions
- 借鉴depth wise separable conv改进InceptionV3。
Inception基于假设:卷积时将通道和空间卷积分离会更好。其1x1的卷积作用于通道,3x3的卷积同时作用于通道和空间,没有做到完全分离。
Xception(Extream Inception)则让3x3卷积只作用于一个通道的特征图,从而实现了完全分离。
InceptionV3到Xception的演化
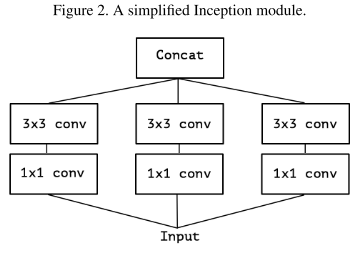
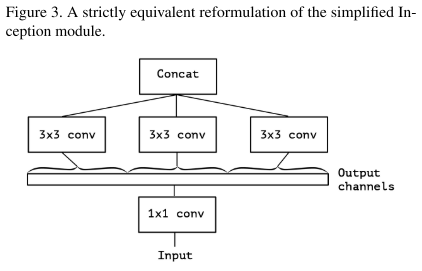
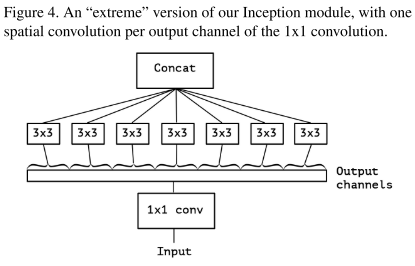
Xception与depthwise separable conv的不同之处:
- depthwise separable conv先对通道进行卷积再1x1卷积,而Xception先1x1卷积,再对通道卷积。
- depthwise separable conv两个卷积间不带激活函数,Xception会经过ReLU。
网络架构
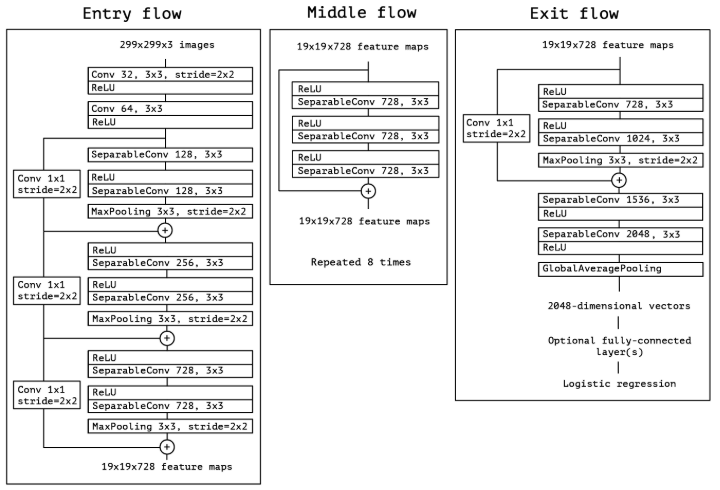
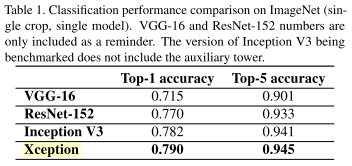
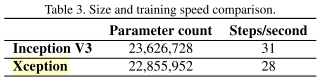
实验结果
总结
GoogLeNet即InceptionV1提出了Inception结构,包含1x1、3x3、5x5的conv和pooling,使网络变宽,增加网络对多尺度的适应性。
- InceptionV2提出了Batch Normalization,使输出归一化为N(0,1)分布,从而加快收敛。并且提出了卷积分解的思想,将大卷积分解为小卷积或非对称卷积,从而降低计算量。
- InceptionV3在InceptionV2的基础上做了一些改进,继续分解7x7卷积、Label Smoothing,并在辅助分类器中也采用BN。
- InceptionV4重新考虑了InceptionV3的结构,降低了不必要的计算量,纯Inception,未引入Residual连接,准确性媲美Inception-ResNetv2。
Inception-ResNet是Inception和Residual Connection的结合,性能有所提升。其有两个版本v1、v2,v1的计算量跟InceptionV3相似,v2的计算量跟InceptionV4相似。
Xception借鉴了depth wise separable conv改进InceptionV3,将空间和通道完全分离,从而提升了性能,降低了参数量。
参考
- paper
[1]Szegedy C, Liu W, Jia Y, et al. Going deeper with convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2015: 1-9.
[2]Ioffe S, Szegedy C. Batch normalization: Accelerating deep network training by reducing internal covariate shift[J]. arXiv preprint arXiv:1502.03167, 2015.
[3]Szegedy C, Vanhoucke V, Ioffe S, et al. Rethinking the inception architecture for computer vision[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 2818-2826.
[4]Szegedy C, Ioffe S, Vanhoucke V, et al. Inception-v4, inception-resnet and the impact of residual connections on learning[C]//Thirty-First AAAI Conference on Artificial Intelligence. 2017.
[5]Chollet F. Xception: Deep learning with depthwise separable convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 1251-1258.
- blog
A Simple Guide to the Versions of the Inception Network

