
- 1SQLite3 数据库学习(一):数据库和 SQLite 基础_sqlite3数据库
- 2最新算法:河马优化(HO),帮你试过了,效果还不错!原理公式详解,附matlab代码...
- 3【鸿蒙自定义组件的生命周期】
- 4Chrome命令大全
- 5AI大模型应用入门实战与进阶:开源AI模型与商业AI模型的比较_ai大模型应用入门实战与进阶:开源ai模型与商业ai模型的比较
- 6axios请求不携带Cookie的原因_请求没有cookie
- 7注意力机制 YOLOv8添加注意力机制_yolov8引入注意力机制
- 8pymysql.err.OperationalError: (1136, “Column count doesn‘t match value count at row 1“)报错反省。_pymysql.err.operationalerror: (1136, "column count
- 9软考下午题——java_初级软考java
- 10【每日力扣3】旋转数组_给定一个整数列表,将数组中的元素向右轮转 k 个位置,其中 k 是非负数且小于列表长
XGBoost和时间序列_xgboost 时间序列
赞
踩
XGBoost是功能非常强大且用途广泛的模型。 它的应用范围非常大,并且已经成功地用于解决许多ML分类和回归问题。
尽管它最初并不是为处理时间序列而设计的,但在这种情况下,仍有许多人使用它。 他们这样做正确吗? 让我们来看看数学如何告诉我们有关该用例的信息。
XGBoost和时间序列
在很多领域和比赛中XGBoost已被用于预测此处的时间序列,它表现良好原因的在于为,需要它提供与时间相关的功能:比如滞后,频率,小波系数,周期等
由于XGBoost非常擅长识别数据模式,因此如果您有足够的描述数据集的时间特征,它将提供非常不错的预测。
但是,XGBoost缺少一个对时间序列绝对重要的基本特性。让我们分析这个模型的数学基础,以理解XGBoost要成为时间序列预测的好模型,有哪些关键缺陷。
XGBoost的数学基础
在XGBoost文档中,有一篇非常有教导性的文章详细解释了XGBoost模型是如何从数学公式推导出来的。我强烈建议你也仔细阅读这篇文章,因为它是至关重要的,真正理解超参数的作用,像伽马,alpha,…(https://xgboost.readthedocs.io/en/latest/tutorials/model.html)
大家都知道,XGBoost是一个基于树的模型。它可以堆叠任意多的树,每增加一棵树都试图减少错误。总体思路是将许多简单、弱的预测因素结合起来,建立一个强大的预测因素。
但是让我们关注XGBoost文档中最重要的公式:如何计算预测。这是一个非常简单的公式:
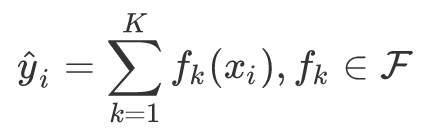
其中estimation y_i是预测,x_i是特征向量,f_k(x_i)是为每棵树计算的值,K是树的总数。
可以看到,对于每棵树来说,XGBoost模型本质上是一个额外的模型。让我们看一下f_k,了解如何计算树的分数,以及我们这里讨论的是哪种函数。
XGBoost文档再次给了我们答案,而且它也很容易理解:
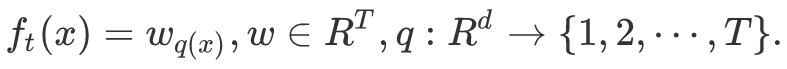
q(x)是一个函数,它将特征x属性赋给当前树t的特定叶子。w_q(x)则是当前树t和当前特征x的叶子得分。
总之,一旦训练好了模型(这是问题中最困难的部分),预测就简单地归结为根据特征识别每棵树的右叶,并对每个叶的值进行汇总。
现在让我们看看这个模型的具体结果,以及它对时间序列预测的影响。
XGBoost无法进行外推!!
再说一次,XGBoost是一个非常强大和高效的分类和回归工具,但是它缺少一个非常关键的特性:它不能外推!(extrapolate)或者至少,它不能外推出比一个简单常数更好的东西。没有线性,二次,或三次插值是可能的。
正如我们在前面的公式中看到的,XGBoost预测仅基于附加到树叶上的值的总和。没有对这些值进行变换没有缩放,没有对数,没有指数,什么都没有。
这意味着XGBoost只能对训练历史中已经遇到的情况做出很好的预测。它不会抓住趋势!
下面的几行代码非常有说服力,应该足以说明这个限制,并让您相信XGBoost无法进行推断:
import matplotlib.pyplot as plt from xgboost import XGBRegressor import numpy as np import pandas as pd # Create an XGBoost model model = XGBRegressor(n_estimators=250) # Create time serie timestamp indices ts = np.linspace(0, 10, 100) X = pd.DataFrame({'ts': ts}) # Generate signal to predict using a simple linear system y = ts * 6.66 # Train XGBoost model model.fit(X, y) # Create prediction inputs. Start with timestamp indices # Shift the initial time range by 0.05 to force interpolation and augment if to force extrapolation x_preds = pd.DataFrame({'ts': list(ts + 0.05) + [11, 12, 13, 14, 15]}) preds = model.predict(x_preds) # Plot results. # XGBoost cannot extrapolate, and keep using the same value for prediction in the future plt.plot(x_preds, x_preds['ts'] * 6.66, label='true values') plt.plot(x_preds, preds, label='XGBoost predicted values') plt.legend() plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
这几行代码试图使用XGBoost模型来预测一个非常基本的纯线性系统的值,该系统的输出与时间成正比。 如下图所示,插值时XGBoost很好,因为您可以看到0到10之间的t预测。

但是,正如我们在分析基本数学模型之后所期望的那样,当尝试进行推断时,它完全失败。 实际上,如上所述,XGBoost模型无法预测不属于其训练的事件。
为什么要用插值呢?
时间序列或至少值得关注的时间序列通常是不平稳的。这意味着它们的统计特征,平均值,方差和标准偏差会随时间变化。
而准确预测这类时间序列需要的模型不仅能捕捉到与时间有关的变化,而且还能进行推断。
我们可以通过两个例子来说明这一点。在第一个例子中,我们想要估算在一个天空从不多云的特定位置接收到的太阳能的数量,这取决于那天。通过几年的数据,XGboost将能够做出一个非常不错的估计,因为接收到的能量数量本质上是一个几何问题,而且地球绕太阳的运动几乎是完美的周期性的。我们面对的是一个静止的系统。
相反,假设我们想要预测的不再是太阳辐照度而是温度。正如我们现在所意识到的,由于人类活动,地球正在克服全球变暖,地球上的平均温度已经上升了一个多世纪。见下面的图:

即使对于给定位置,我们观察到季节性影响,但平均温度在时间上并不稳定。 如果不建立具有所能想象的尽可能多的气象或气候特征的XGBoost模型永远不会对未来产生良好的估计。
我们可以魔改XGBoost来克服这个问题吗?
对于某些模型,有时可能会破解基础数学以扩展其应用范围。
例如,您可以使用简单的线性回归模型来建模和预测非线性系统,只需向它们提供非线性特征即可。比如通过输入风速为7一阶的线性模型,可以获得较好的风力发电性能。
但是不幸的是,无法调整XGBoost模型中用于预测的公式以引入对推断的支持。
将XGBoost强大的模式识别与外推相结合的一种选择是使用负责此工作的侧面模型来扩展XGBoost。
另一种可能是对数据进行标准化处理,以消除非平稳影响并退回平稳情况。
结论
XGBoost和任何其他基于树的模型都不能从数学上执行任何顺序大于0的外推。也就是说,他们只能推断出一个常数值。当试图将这种模型应用于非平稳时间序列时,这是一个需要考虑的巨大限制。
但是,XGBoost仍然是用于吸引具有许多功能的复杂数据中的结构的非常有吸引力的工具。 只要您的目标是固定的,就可以用它来预测时间序列。 如果不是这种情况,则需要对数据进行预处理以确保数据正确,或者考虑将XGBoost与负责处理趋势的其他模型结合使用。
作者:Saupin Guillaume
deephub翻译组

