
- 1Python基础与拾遗7:Python中的数据类型总结
- 2小程序组件引用外部样式_小程序自定义组件引入样式
- 3uniapp开发WebRTC语音直播间支持app(android+IOS)和H5,并记录了所有踩得坑_uniapp webrtc
- 4jQuery基本选择器_jquery 选择器 并且、
- 5基于微信小程序叽喳音乐微信小程序的设计与实现-计算机毕业设计源码+LW文档_基于微信小程序音乐
- 6【数据结构】二叉树的建立及先中后序遍历完整C语言代码_二叉树的建立与遍历完整代码
- 7有趣且重要的JS知识合集(18)浏览器实现前端录音功能_js 录音
- 8Git命令基础使用之GitLab拉取项目、提交分支、切换分支、合并分支、删除分支。_gitlab切换分支
- 9Facebook广告投放数据分析_fb roas 获量
- 10「Kanboard」- 个人看板工具 @20210125_kanboard 插件
CogView中的Transformer_checkpoint_activations
赞
踩
入门小菜鸟,希望像做笔记记录自己学的东西,也希望能帮助到同样入门的人,更希望大佬们帮忙纠错啦~侵权立删。
目录
(7)将 num_layer 个 transformer layer打包在一起,以列表形式保存
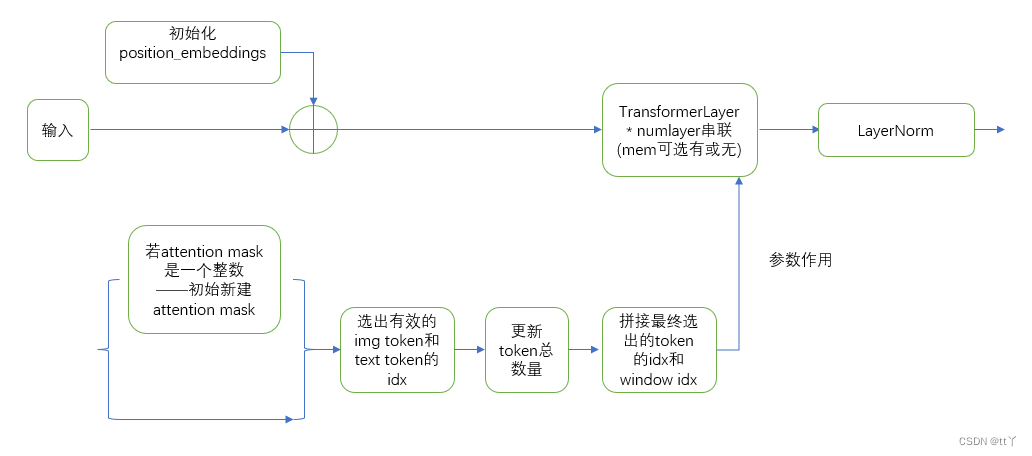
(6)获取下一层的输入——分为是否采取检查点激活两种情况来分析
一、原理
1、总体介绍
将n个的 transformer blocks 打包在一起,即 n * transformer layer + final layernorm 两部分组成
2、具体实现
(1)不采取稀疏处理(默认)
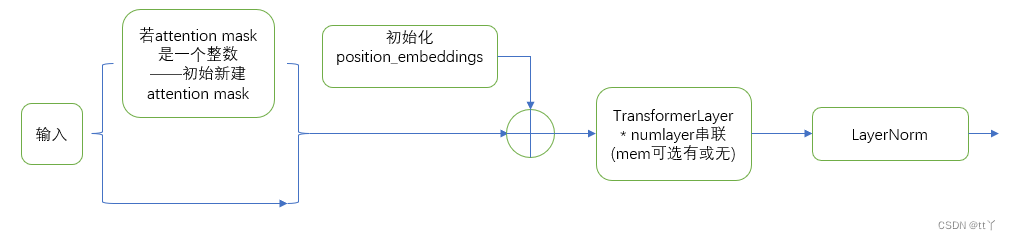
(2)采取稀疏训练
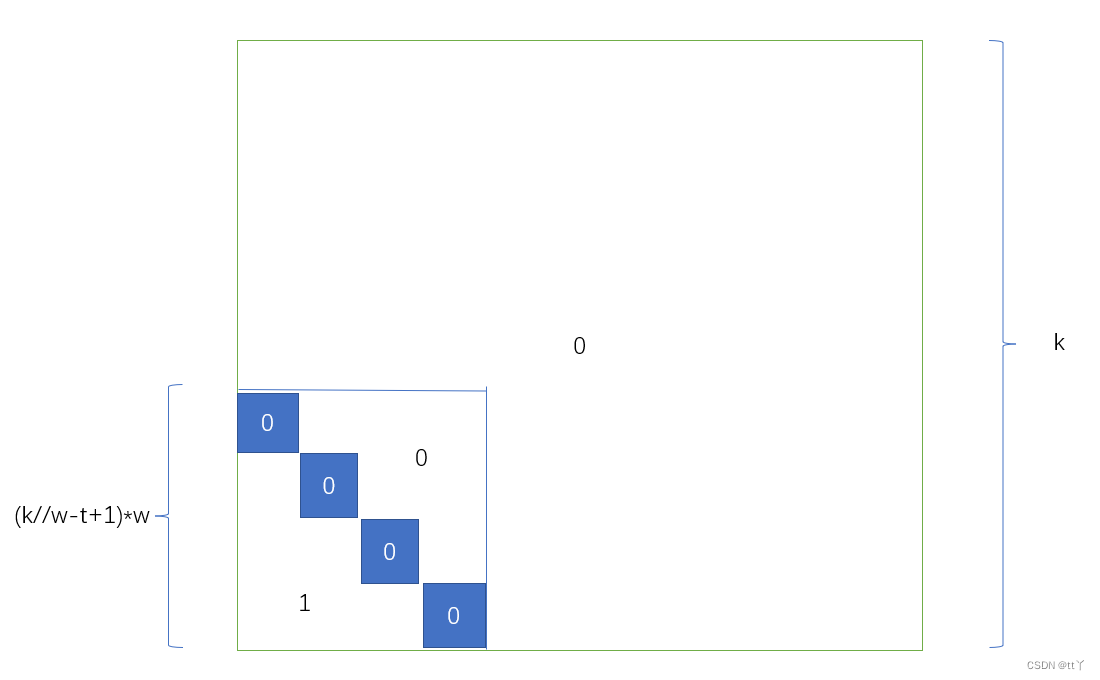
 新建的rmask(k为输入的总列数;w为窗口大小;t为调整窗口数量所用)
新建的rmask(k为输入的总列数;w为窗口大小;t为调整窗口数量所用)
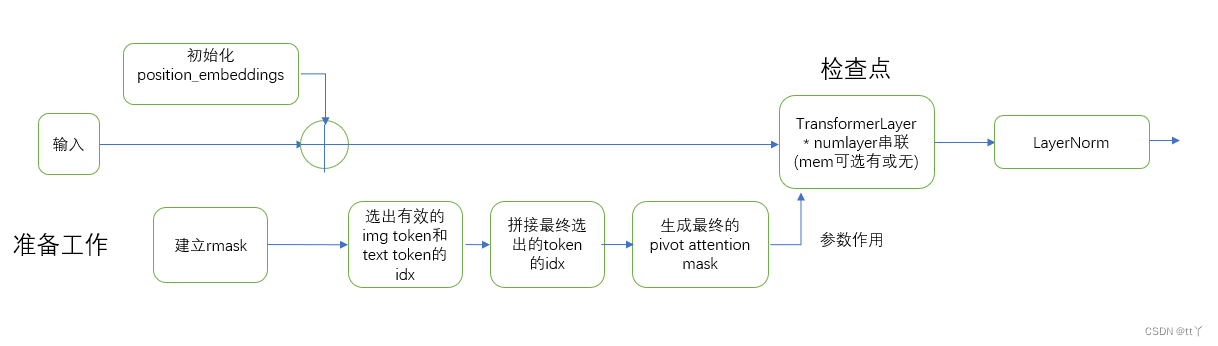
 (3)稀疏推断
(3)稀疏推断
二、代码解析
1、__init__
(1)参数设定
- class GPT2ParallelTransformer(torch.nn.Module):
- """GPT-2 transformer.
- This module takes input from embedding layer and it's output can
- be used directly by a logit layer. It consists of L (num-layers)
- blocks of:
- layer norm
- self attention
- residual connection
- layer norm
- mlp
- residual connection
- followed by a final layer norm.
- Arguments:
- num_layers: Number of transformer layers.
- hidden_size: The hidden size of the self attention.
- num_attention_heads: number of attention head in the self
- attention.
- attention_dropout_prob: dropout probability of the attention
- score in self attention.
- output_dropout_prob: dropout probability for the outputs
- after self attention and final output.
- checkpoint_activations: if True, checkpoint activations.
- checkpoint_num_layers: number of layers to checkpoint. This
- is basically the chunk size in checkpoitning.
- layernorm_epsilon: epsilon used in layernorm to avoid
- division by zero.
- init_method_std: standard deviation of the init method which has
- the form N(0, std).
- use_scaled_init_for_output_weights: If Ture use 1/sqrt(2*num_layers)
- scaling for the output weights (
- output of self attention and mlp).
- """
- def __init__(self,
- num_layers,
- hidden_size,
- num_attention_heads,
- max_sequence_length,
- max_memory_length,
- embedding_dropout_prob,
- attention_dropout_prob,
- output_dropout_prob,
- checkpoint_activations,
- checkpoint_num_layers=1,
- layernorm_epsilon=1.0e-5,
- init_method_std=0.02,
- use_scaled_init_for_output_weights=True,
- query_window=128,
- key_window_times=6,
- num_pivot=768
- ):
- super(GPT2ParallelTransformer, self).__init__()

- num_layers:transformer层的数量;
- hidden_size:自我注意力模块的隐藏大小(嵌入向量的维度);
- num_attention_heads:自我注意力模块中attention head的数量;
- max_sequence_length:词典大小;
- max_memory_length:最大记忆长度;
- embedding_dropout_prob:嵌入层(该模块的输入部分)中元素被dropout的概率(为了解决过拟合问题而随机丢弃一部分元素);
- attention_dropout_prob:同样道理,注意力模块中注意力得分被dropout的概率;
- output_dropout_prob:同理,输出层后的输出被dropout的概率;
- checkpoint_activations:是否执行检查点激活;
- checkpoint_num_layers:检查点的层数。这基本上是checkpoitning中的块大小;
- layernorm_epsilon:在layernform中用于避免被零除的ε(用于防止分母为0);
- init_method_std:初始化方法(使用让权重呈现正态分布的方法)中正态分布的方差;
- use_scaled_init_for_output_weights:是否对自注意力和mlp的输出的权重调用scaled_init_method进行初始化;
- query_window:稀疏处理中的窗口大小;
- key_window_times:用于调整窗口数量;
- num_pivot:transformer里图像token和文本token的总和数量
(2)存储激活检查点标志
- # Store activation checkpoiting flag.
- #首先先记录是否执行检查点激活,检查点的层数,最大记忆长度和最大序列长度信息
- self.checkpoint_activations = checkpoint_activations
- self.checkpoint_num_layers = checkpoint_num_layers
- self.max_memory_length = max_memory_length
- self.max_sequence_length = max_sequence_length
(3)定义输出层初始化方法
由use_scaled_init_for_output_weights决定,若为False则不进行初始化缩放,若为true则调用scaled_init_method进行初始化
- #输出层初始化方法定义——由use_scaled_init_for_output_weights决定,若为False则不进行初始化缩放,若为true则调用scaled_init_method进行初始化
- output_layer_init_method = None
- if use_scaled_init_for_output_weights:
- output_layer_init_method = scaled_init_method(init_method_std,
- num_layers)
scaled_init_method函数——返回初始化方法:初始权重呈均值为0,方差为init_method_std//sqrt(2*num_layers)的正态分布。
- def scaled_init_method(sigma, num_layers):
- """Init method based on N(0, sigma/sqrt(2*num_layers)."""
- std = sigma / math.sqrt(2.0 * num_layers)
- def init_(tensor):
- return torch.nn.init.normal_(tensor, mean=0.0, std=std)
-
- return init_
(4)Position embedding
先进行嵌入层的dropout(防止过拟合),然后调用torch.nn.Embedding()方法按词典大小max_sequence_length和嵌入向量的维度hidden_size来定义词向量格式,然后将词向量的值初始化为呈以0为均值,以init_method_std为方差的正态分布。
- # Embeddings dropout嵌入层dropout
- self.embedding_dropout = torch.nn.Dropout(embedding_dropout_prob)
-
- # Position embedding (serial).初始化含位置信息的词向量方法
- self.position_embeddings = torch.nn.Embedding(max_sequence_length,
- hidden_size)#随机以max_sequence_length为词典的大小(词的个数),以hidden_size来嵌入向量的维度(即用多少维来表示一个符号)初始化词向量,默认词向量值在正态分布N(0,1)中随机取值
- # Initialize the position embeddings.词向量值在正态分布N(0,init_method_std)中随机取值
- torch.nn.init.normal_(self.position_embeddings.weight, mean=0.0, std=init_method_std)
(5)窗口定义
- self.query_window = query_window
- self.key_window_times = key_window_times
- self.num_pivot = num_pivot
(6)Transformer layers设置
首先定义了一个get_layer()函数来获得对应层id的网络层(transformer layer)
- #获得对应层id的网络层
- def get_layer(layer_id):
- return GPT2ParallelTransformerLayer(
- hidden_size,
- num_attention_heads,
- attention_dropout_prob,
- output_dropout_prob,
- layernorm_epsilon,
- unscaled_init_method(init_method_std),
- output_layer_init_method=output_layer_init_method,
- query_window=query_window,
- key_window_times=key_window_times,
- scale_normalization=True
- )
这里调用了GPT2ParallelTransformerLayer类
(7)将 num_layer 个 transformer layer打包在一起,以列表形式保存
- # Transformer layers.
- self.layers = torch.nn.ModuleList(
- [get_layer(layer_id) for layer_id in range(num_layers)])
(8)output层的LayerNorm处理
- # Final layer norm before output.
- self.final_layernorm = LayerNorm(hidden_size, eps=layernorm_epsilon)
(9)激活点检查
- if deepspeed.checkpointing.is_configured():
- global get_cuda_rng_tracker, checkpoint
- get_cuda_rng_tracker = deepspeed.checkpointing.get_cuda_rng_tracker
- checkpoint = deepspeed.checkpointing.checkpoint
- self.rmask = None#是否进行稀疏处理
2、forward
- def forward(self, hidden_states, position_ids, attention_mask, txt_indices_bool, img_indices_bool, is_sparse=0, *mems):
- '''''
- hidden_states:输入的网络层;
- position_ids:位置编码;
- attention_mask;
- txt_indices_bool:选取文本token有效的索引矩阵
- img_indices_bool:选取图像token有效的索引矩阵
- is_sparse:是否稀疏处理,稀疏训练,稀疏推断
- mems:记忆模块;
- '''''
(1)获取最终的输入层的相关信息
获取b,s和最终的输入列数(hidden_states和记忆模块的concat的结果)
- batch_size, query_length = hidden_states.size()[:2]#获取batchsize(b)和读取的序列长度(s)
- memory_length = mems[0].size(1) if mems else 0#获取记忆模块的序列长度(模块列数)
- key_length = query_length + memory_length#得到最终的序列长度(类似concat维数增加)
(2)attention mask建立
最终shape[1,1,s,s](无记忆模块情况下,有记忆为[1,1,s,s+m],m为memory_length)
- # conventional transformer
- #建立常规transformer的attention mask
- def build_mask_matrix(query_length, key_length, sep):
- m = torch.ones((1, query_length, key_length), device=hidden_states.device, dtype=hidden_states.dtype)#初始化为全一矩阵
- assert query_length <= key_length
- m[0, :, -query_length:] = torch.tril(m[0, :, -query_length:])#返回m[0, :, -query_length:]区域(最后两维)是下三角矩阵的矩阵
- m[0, :, :sep + (key_length - query_length)] = 1#注意力标记
- m = m.unsqueeze(1)#[1,s,s+m]->[1,1,s,s+m]
- return m
- #生成attention_mask,无记忆模块是[1,1,s,s],有记忆是[1,1,s,s+m]
- attention_mask = build_mask_matrix(query_length, key_length, sep)
(3)稀疏训练or推断准备
✨获取稀疏训练的rmask
- #启用稀疏训练生成rmask
- if is_sparse == 1 and (self.rmask is None):
- w, times = self.query_window, self.key_window_times#滑动窗口大小+窗口数的减少量获取
- g = key_length // w#获取全局attention窗口个数
- tmp = torch.ones((g-times+1, w , w), device=hidden_states.device, dtype=hidden_states.dtype)#初始化rmask(可理解为g-times+1个窗口)
- tmp = torch.tril(1 - torch.block_diag(*tmp))#*将三维矩阵变成二维矩阵列表;torch.block_diag将g-times+1个w*w矩阵组合成一个块对角矩阵,1-使得中间块为0,其余为1;torch.tril返回下三角矩阵。shape为((g-times+1)*w,(g-times+1)*w)
- self.rmask = torch.nn.functional.pad(tmp, (0, (times-1)*w, (times-1)*w, 0)) # pad (left, right, top, bottom),这四个元素的位置代表了填充的位置,大小为填充的行数,默认填0,所以最终shape为(g*w,g*w),左下角为一个((g-times+1)*w,(g-times+1)*w)大小的下三角矩阵
✨获取左边界和支点
- if is_sparse == 2:#稀疏推断
- left_boundary = max(0, key_length - self.key_window_times * self.query_window)#获取左边界(将key_length分为n份query_window的块块,做除法后的余数部分为左边界
- window_idx = torch.arange(left_boundary, key_length, device=hidden_states.device, dtype=torch.long).expand(batch_size, -1)#torch.arange获得[left_boundary,...,key_length-1];expand(batch_size, -1)获得batchsize条[left_boundary,...,key_length-1],获得shape为(batchsize*key_length-left_boundary)
- elif is_sparse == 1:#稀疏训练
- left_boundary = key_length#获取左边界
- num_pivot = self.num_pivot#transformer里图像token和文本token的总和数量获取
✨选取每个batch中对应有效的index的image token和txt token
- #选取每个batch中对应有效的index的image token和txt token
- if is_sparse: # 1 or 2
- # select out the real indices for sampling
- img_indices = [img_indices_bool[i][:left_boundary].nonzero(as_tuple=False).view(-1) for i in range(batch_size)]#.nonzero(as_tuple=False)取出非0元素的索引(即取出有效索引);.view(-1)将其展平
- txt_indices = [txt_indices_bool[i][:left_boundary].nonzero(as_tuple=False).view(-1) for i in range(batch_size)]
✨稀疏推断支点数目设定
- #稀疏推断支点数目设定(总token数量增加)
- if is_sparse == 2:
- ratio = self.num_pivot / self.max_sequence_length#支点比例获取
- max_text_num = max(len(text_idx) for text_idx in txt_indices)#获取batch中最长的有效文本token长度
- num_pivot = max_text_num + int((left_boundary - max_text_num) * ratio)#支点数目更新
(4)对输入层的处理
给输入层加入初始化的位置信息词向量并且进行dropout操作
- #对输入层的处理
- position_embeddings = self.position_embeddings(position_ids)#对位置信息position_ids进行词向量的初始化
- hidden_states = hidden_states + position_embeddings#输入层加入初始化的位置信息词向量
- hidden_states = self.embedding_dropout(hidden_states)#对输入层进行dropout
(5)这次是否有产生记忆模块
若拥有最大记忆长度,则产生的记忆模块是输入层,但不需要计算其梯度
- #这次是否有产生记忆模块
-
- if self.max_memory_length > 0:#若拥有最大记忆长度,
- mem_layers = [hidden_states.detach()]#记忆模块赋为输入层,但不需要计算其梯度
- else:#否则没有记忆模块
- mem_layers = []
然后保存一下attention mask
attention_mask_saved = attention_mask#保存attention mask(6)获取下一层的输入——分为是否采取检查点激活两种情况来分析
(都要利用get_layer来实现,所以都要先获取相应的参数输入才可调用)
✨采取检查点激活
①首先是必要的初始化和参数获取
- l = 0#初始化start层id
- num_layers = len(self.layers)#Transformer layers的数量获取
- chunk_length = self.checkpoint_num_layers#检查点的层数
循环获取层
while l < num_layers:②稀疏训练or推断情况下获取下一层的输入的参数
if is_sparse > 0:#稀疏训练or推断Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

