
- 1Unity学习日志_NGUI简介
- 2Deep Learning and Backpropagation_"1 hidden layer is \"good enough\",why deep?"
- 3华为软件测试笔试真题,抓紧收藏不然就看不到了_华为软件测试机试题
- 4mac安装Redis后 mac zsh: command not found: redis-cil 如何解决_zsh: command not found: redis-cli
- 5使用Keil创建stm32f030xx工程模板,记录_stm32f030 pack
- 6图像数据增广_图像增广
- 7LLM:检索增强生成(RAG)_ig检索增强
- 8QT5.15.2搭建Android环境_qt配置安卓kit
- 9PCB大电流承载方法(100~150A)_pcb走150a大电流处理方式
- 10Python wordcloud词云:源码分析及简单使用_valueerror: couldn't find space to draw. either th
Data Lakehouse (湖仓一体) 到底是什么
赞
踩
0、背景
Data Lakehouse(湖仓一体)是新出现的一种数据架构,它同时吸收了数据仓库和数据湖的优势,数据分析师和数据科学家可以在同一个数据存储中对数据进行操作,同时它也能为公司进行数据治理带来更多的便利性。
0.1 目前数据存储的方案
一直以来,我们都在使用两种数据存储方式来架构数据:
- 数据仓库:主要存储的是以关系型数据库组织起来的结构化数据。数据通过转换、整合以及清理,并导入到目标表中。在数仓中,数据存储的结构与其定义的schema是强匹配的。
- 数据湖:存储任何类型的数据,包括像图片、文档这样的非结构化数据。数据湖通常更大,其存储成本也更为廉价。存储其中的数据不需要满足特定的schema,数据湖也不会尝试去将特定的schema施行其上。相反的是,数据的拥有者通常会在读取数据的时候解析schema(schema-on-read),当处理相应的数据时,将转换施加其上。
现在许多的公司往往同时会搭建数仓、数据湖这两种存储架构,一个大的数仓和多个小的数据湖。这样,数据在这两种存储中就会有一定的冗余。
一、Data Lakehouse特性
Data Lakehouse的出现试图去融合数仓和数据湖这两者之间的差异,通过将数仓构建在数据湖上,使得存储变得更为廉价和弹性,同时lakehouse能够有效地提升数据质量,减小数据冗余。在lakehouse的构建中,ETL起了非常重要的作用,它能够将未经规整的数据湖层数据转换成数仓层结构化的数据。
Data Lakehouse概念是由Databricks中提出的,在提出概念的同时,也列出了如下一些特性:
- 事务支持:Lakehouse可以处理多条不同的数据管道。这意味着它可以在不破坏数据完整性的前提下支持并发的读写事务。
- Schemas:数仓会在所有存储其上的数据上施加Schema,而数据湖则不会。Lakehouse的架构可以根据应用的需求为绝大多数的数据施加schema,使其标准化。
- 报表以及分析应用的支持:报表和分析应用都可以使用这一存储架构。Lakehouse里面所保存的数据经过了清理和整合的过程,它可以用来加速分析。同时相比于数仓,它能够保存更多的数据,数据的时效性也会更高,能显著提升报表的质量。
- 数据类型扩展:数仓仅可以支持结构化数据,而Lakehouse的结构可以支持更多不同类型的数据,包括文件、视频、音频和系统日志。
- 端到端的流式支持:Lakehouse可以支持流式分析,从而能够满足实时报表的需求,实时报表在现在越来越多的企业中重要性在逐渐提高。
- 计算存储分离:我们往往使用低成本硬件和集群化架构来实现数据湖,这样的架构提供了非常廉价的分离式存储。Lakehouse是构建在数据湖之上的,因此自然也采用了存算分离的架构,数据存储在一个集群中,而在另一个集群中进行处理。
- 开放性:Lakehouse在其构建中通常会使Iceberg,Hudi,Delta Lake等构建组件,首先这些组件是开源开放的,其次这些组件采用了Parquet,ORC这样开放兼容的存储格式作为下层的数据存储格式,因此不同的引擎,不同的语言都可以在Lakehouse上进行操作。
Lakehouse的概念最早是由Databricks所提出的,而其他的类似的产品有Azure Synapse Analytics。Lakehouse技术仍然在发展中,因此上面所述的这些特性也会被不断的修订和改进。
二、Data lakehouse解决了什么问题
那说完了Data Lakehouse的特性,它到底解决了什么问题呢?
这些年来,在许多的公司里,数仓和数据湖一直并存且各自发展着,也没有遇到过太过严重的问题。但是仍有一些领域有值得进步的空间,比如:
- 数据重复性:如果一个组织同时维护了一个数据湖和多个数仓,这无疑会带来数据冗余。在最好的情况下,这仅仅只会带来数据处理的不高效,但是在最差的情况下,它会导致数据不一致的情况出现。Data Lakehouse统一了一切,它去除了数据的重复性,真正做到了Single Version of Truth。
- 高存储成本:数仓和数据湖都是为了降低数据存储的成本。数仓往往是通过降低冗余,以及整合异构的数据源来做到降低成本。而数据湖则往往使用大数据文件系统(譬如Hadoop HDFS)和Spark在廉价的硬件上存储计算数据。而最为廉价的方式是结合这些技术来降低成本,这就是现在Lakehouse架构的目标。
- 报表和分析应用之间的差异:报表分析师们通常倾向于使用整合后的数据,比如数仓或是数据集市。而数据科学家则更倾向于同数据湖打交道,使用各种分析技术来处理未经加工的数据。在一个组织内,往往这两个团队之间没有太多的交集,但实际上他们之间的工作又有一定的重复和矛盾。而当使用Data Lakehouse后,两个团队可以在同一数据架构上进行工作,避免不必要的重复。
- 数据停滞(Data stagnation):在数据湖中,数据停滞是一个最为严重的问题,如果数据一直无人治理,那将很快变为数据沼泽。我们往往轻易的将数据丢入湖中,但缺乏有效的治理,长此以往,数据的时效性变得越来越难追溯。Lakehouse的引入,对于海量数据进行catalog,能够更有效地帮助提升分析数据的时效性。
- 潜在不兼容性带来的风险:数据分析仍是一门兴起的技术,新的工具和技术每年仍在不停地出现中。一些技术可能只和数据湖兼容,而另一些则又可能只和数仓兼容。Lakehouse灵活的架构意味着公司可以为未来做两方面的准备。
三、Data Lakehouse存在的问题
现有的Lakehouse架构仍存在着一些问题,其中最为显著的是:
- 大一统的架构:Lakehouse大一统的架构有许多的有点,但也会引入一些问题。通常,大一统的架构缺乏灵活性,难于维护,同时难以满足所有用户的需求,架构师通常更倾向于使用多模的架构,为不同的场景定制不同的范式。
- 并非现有架构上本质的改进:现在对于Lakehouse是否真的能够带来额外的价值仍存在疑问。同时,也有不同的意见 - 将现有的数仓、数据湖结构与合适的工具结合 - 是否会带来类似的效率呢?
- 技术尚未成熟:Lakehouse技术当前尚未成熟,在达到上文所提的能力之前仍有较长的路要走。
四、各大公司的落地实例
下图是阿里云湖仓一体的架构:
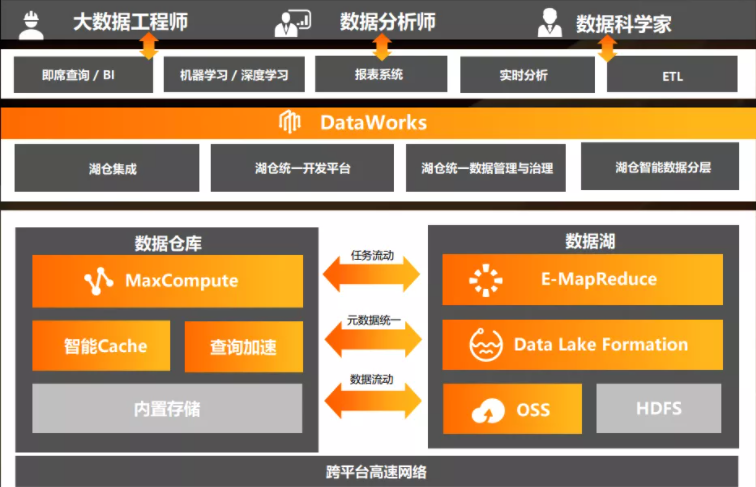
阿里云这套架构是把两个产品:数据仓库MaxCompute和数据湖EMR给打通了。
这个打通应该不是简单的把两个网段互通,而是要考虑数据快速访问,安全等原因,底层的网络拓扑可能都需要重新设计。
之后再在上面加一层统一的元数据管理,这样整个湖仓一体就完成了。
阿里云做湖仓一体的初衷来自于新浪微博的业务场景:

微博有大量的文本、图片,后台需要对这些数据做反垃圾、反作弊,经过大量的训练提取特征、训练模型,想用SQL对结果做分析,需要有大量的数据同步,如果将两套系统打通,就不会有这些问题了。
下图是华为云的湖仓一体解决方案:
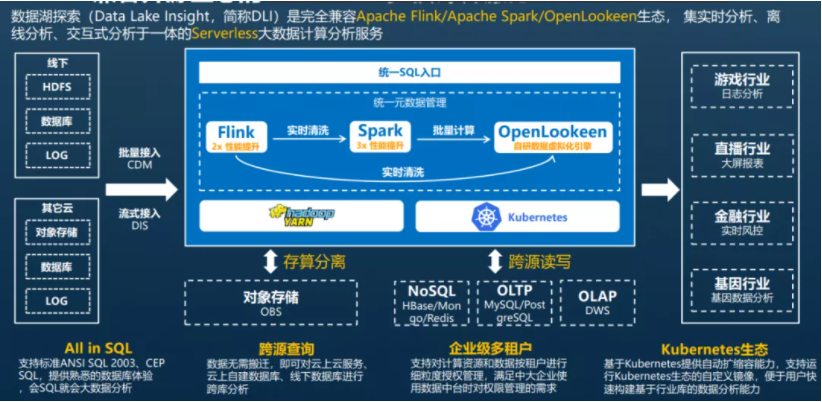
看起来比华为云的方案更好,统一SQL入口、基于对象存储的存算分离、支持跨数据源查询、多租户隔离、并支持云原生。
除了国内厂商,国外如亚马逊的Redshift,谷歌的BigQuery都是类似的解决方案。
阿里云、华为云提出的湖仓一体方案,可能是因为他们的用户场景复杂多样导致的。
从上图中可以看到华为云的用户都是各种不同行业的,而不同行业对数据访问的需求也是不同的:
-
电商行业可能存在多种数据源,那么做数据分析时就需要做跨源查询
-
金融行业的风控系统对实时性要求很高,那么对流处理会有更多需求
-
大型企业,部门众多,对租户隔离会有更多要求
-
政府部分,内部技术人员一般熟悉SQL,对SQL的易用性有要求
不同的行业催生了不同的需求,经过整合、迭代,最后各大企业都纷纷提出 湖仓一体解决方案,相信也是有实际需求,并不是空穴来风。
五、湖仓一体落地路径与成本
A:现在大多数企业都已经有了自己的一套大数据架构,他们如何基于已有的架构落地湖仓一体?有哪些可行的落地路径?成本可能主要会来自哪里?
Q:现在有一部分企业已经有了自己的大数据架构,这些企业相对来说可能诞生的比较早,大多数都是选的 Hadoop 体系,或是自建的 Hadoop 体系,或是使用云上托管的 Hadoop 体系。这些企业可以有很多选择,他可以选择像 Databricks 那样的方案,也可以选择像 MaxCompute 这样的方案。
这两条路径都相对可行,那怎么选?这通常要看企业是不是希望在大数据技术栈上做更多投入。如果企业觉得没必要在基础设施上投很多资源,而是要把更多资源放在业务上,那选一个更偏全托管版的湖仓一体解决方案更有价值。反之,如果企业技术人员很多,希望底层基础设施足够灵活并且是自己可控的,就可以选择在湖上建仓的模式。
还有一些比较新的企业,比如过去三年内成立的,它们有很多都处于高速增长阶段。这些企业其实天生就长在云上,甚至一开始选的大数据架构就已经是云数仓的架构,这类企业基于现有的架构向前演进相对比较简单。只要尽量使用云基础设施,开通几个云服务就能形成一套湖仓一体架构了,这是一个简单直接且相对单一化的路径。
那成本主要来自哪里?如果企业选择全托管的湖仓一体解决方案,则成本主要来自于对当前数据,比如数仓迁移、数据整理等一次性开支,一旦这部分工作做完,后续在数据治理上形成正循环,整体成本不会太高。如果企业选择自己维护一套湖仓一体架构,则成本主要来自持续维护和调优整套基础设施的人力成本和硬件成本。
A:根据您的了解,当前企业尝试落地湖仓一体的时候遇到的问题和挑战主要有哪些?现在是采用湖仓一体的好时机吗?
Q:现在大多数企业都还没有用到湖仓一体的新架构,他们要么选择了数据湖方案,要么选择了数仓方案。湖仓一体作为一个新兴架构,很多企业目前还在早期探索阶段。有些企业在把数据放到数据湖上之后,发现在数据湖上做好数据治理或者数据管理相对比较困难,这个时候再去采用湖仓一体模式,在现有相对更灵活但不够管理化的数据上,再抽象一层数仓层和治理层,对数据做更好的管理和治理。对于数仓的用户,如果采用的数仓系统支持湖仓一体架构,直接挂载数据湖就好了。
企业尝试落地湖仓一体时会遇到的问题和挑战主要有几点。首先,如果团队没有足够好的数据治理或数据管理经验,挑战会比较大。这也是为什么我们推出的方案几乎都在向全托管或全服务的 SaaS 模式走,就是希望能够降低门槛。
其次,对于自建湖仓一体的企业,他们会遇到的挑战主要是湖仓一体的高复杂度,特别是湖仓之间如何协同的问题,这里面涉及到两套系统存储打通的问题、元数据一致性问题、湖和仓上不同引擎之间数据交叉引用的问题,以及带宽问题、安全问题,等等。另外,由于湖仓一体架构底层是一个二元体系,那向上面向用户的时候,用户是不是能看到两个体系?如果用户能够看到两个体系的话,如何区分和引导?如果用户看不到的话,那底下开发需要做什么样的封装?这些都是自建湖仓体系会遇到的问题。
总之,如果企业并不是一定要大力投入做基础设施的话,直接采用全托管版本的湖仓一体的架构会简单很多。
参考资料:
1.微信公众号(数据湖技术)-《Data Lakehouse (湖仓一体) 到底是什么》
2.微信公众号(大话算法)-《什么是湖仓一体》
3.微信公众号(数据学堂)-《7000字,详解仓湖一体架构!》

