
- 1【移动机器人技术】move_base参数配置方法及含义_,move_base 手动添加障碍物
- 2超级详细:微服务SpringCloud学习笔记(一)——认识微服务、服务拆分与调用、Eureka注册中心、Ribbon负载均衡、Nacos注册中心
- 3Stable Diffusion软件下载_stable diffusion百度云
- 4FPGA配置之SelectMAP总线
- 5win7 登陆机制Credential Provider_除session 0 之外的每一个session仍会有一个 winlogon 实例, 已通过新的 l
- 6讲述 it工作者 8年经历。_it工作经历
- 7Linux系统下解决使用github提示Please make sure you have the correct access rights and the repository exists的错误_linux please make sure you have the correct access
- 8MySQL~Redo刷盘策略、LogBuffer缓存池和LogFile日志文件理解_每次commit log buffer日志
- 98.11 TCP链接管理与UDP协议_tcp-udp服务管理
- 10[BUUCTF 刷题] Reverse解题方法总结(一)_buuctf reverse
【嵌入式AI】轻量级网络论文解析_嵌入式ai论文
赞
踩
轻量级网络的核心是在尽量保持精度的前提下,从体积和速度两方面对网络进行轻量化改造。
MobileNetv1论文详解
标准卷积、分组卷积和深度分离卷积
标准卷积实际上就是通道维度的全连接,每一个卷积核都要与所有的输入通道进行卷积
而分组卷积和深度分离卷积则只对一部分或者一个通道进行卷积
MobileNet 论文的主要贡献在于提出了一种深度可分离卷积架构(DW+PW 卷积)
深度分离卷积基于假设:卷积层通道间的相关性和空间相关性是可以退耦合(完全可分)的,将它们分开映射,能达到更好的效果
Xception中就有深度分离卷积,不过是先用1*1卷积扩展维度,再用分离卷积,参数量和速度并没有太大的变化。
深度分离卷积
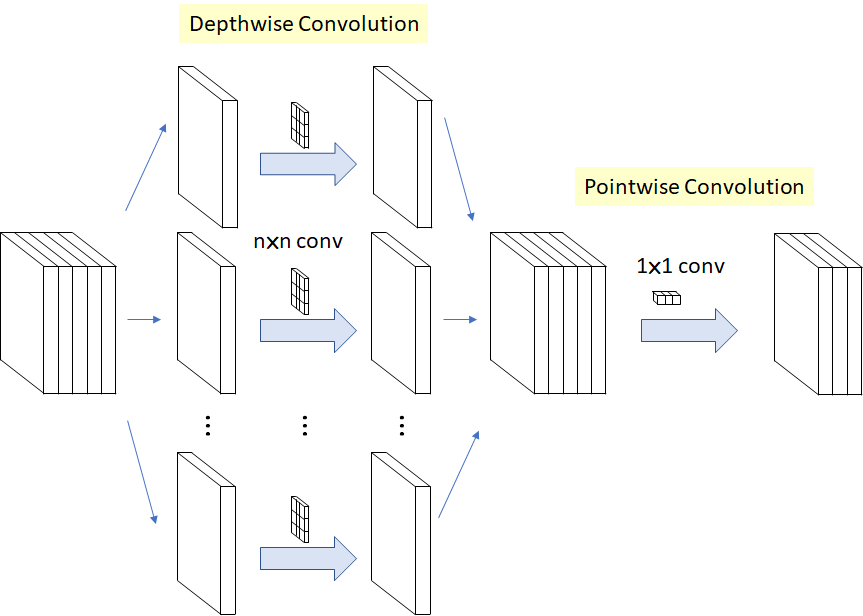
1*1卷积
MobileNet 模型结构将几乎所有计算都放入密集的 1×1 卷积中,1×1 卷积不需要在内存中进行重新排序,可以直接使用 GEMM(最优化的数值线性代数算法之一)来实现。
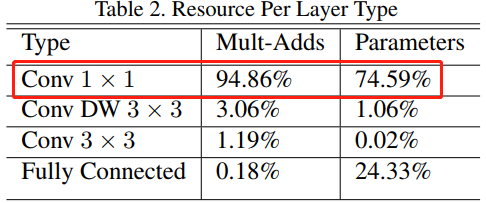
深度分离卷积的缺点
1、参数量基本不变,内存访问代价不变,现代GPU的瓶颈主要是内存访问的耗时
2、在GPU、TPU中通道数与耗时不一定相关,一般是阶梯型

MobileNetv2
V2是在V1基础上主要加入了对残差连接的利用
1、利用Inverted residuals策略,先升维在降维,让深度卷积操作可以在更高的通道的上进行。
2、深度卷积部分的卷积核在训练时特别容易训废掉(很多0),作者认为是Relu激活函数导致的问题。因此提出把最后一格激活层换成线性形式
MobileNetV3
MobileNetV3是对MnasNet进行优化,优化算法为NetAdapt
MnasNet是用NAS搜索的轻量级网络。
MnasNet
优化目标
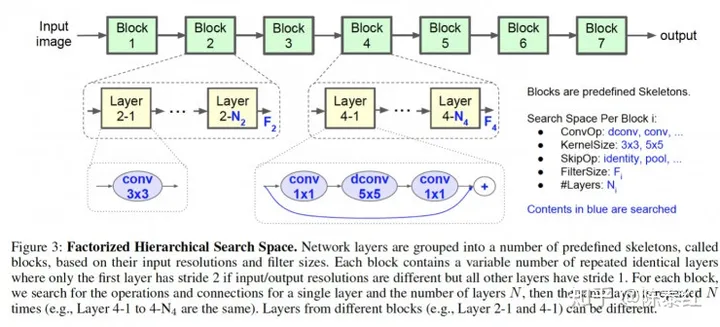
搜索空间
搜索算法:强化学习
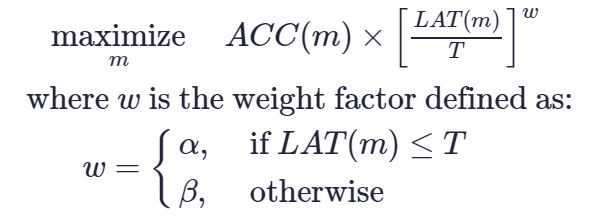
NetAdapt
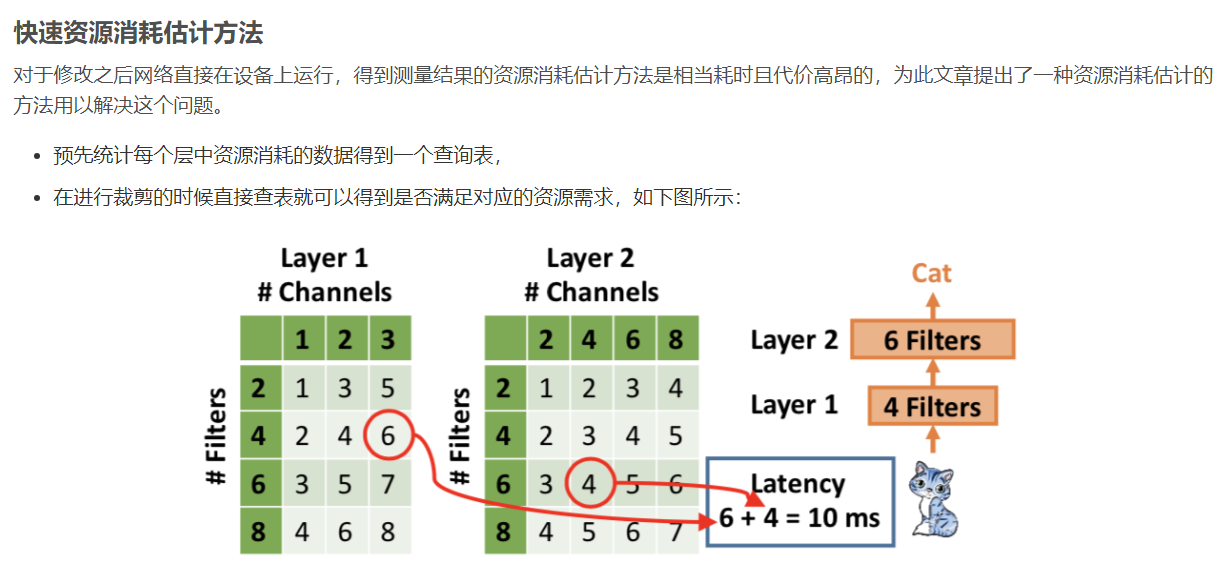
1、按照给定的资源约束选择当前层需要剪掉的filter数量
2、在确定好需要剪裁掉的filter数量之后就需要确定哪些不重要的filter需要被剪裁掉。文章使用的重要性选择方式是使用上一轮迭代产生的梯度信息,将其L2-norm。
3、对当前裁剪的层进行short-term的finetune使其恢复精度。
4、判断当前迭代论述的模型是否满足算法预先设计的资源需求限制,若满足则对模型进行long-term的finetune
MobileNetV3中还做了手工修改:
1、MobileNet v1和v2都从具有32个滤波器的常规3×3卷积层开始,然而实验表明,这是一个相对耗时的层,只要16个滤波器就足够完成对224 x 224特征图的滤波。
2、使用h-wish而不是ReLU6;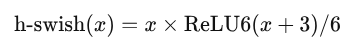
3、使用了Squeeze-and-excitation模块(SE),并进一步缩减了通道数
4、对于SE模块,不再使用sigmoid,而是采用ReLU6(x + 3) / 6作为近似
ShuffleNet V2
作者分析了ShuffleNet v1 和 MobileNet v2的运行时间,数据输入输出、通道打乱和逐元素的一些操作消耗了很多运行时间。
因此作者提出了几点高效网络设计的思想
1、同样大小的通道数可以最小化 MAC,即卷积前后的特征通道数变化应尽可能小
2、分组数太多的卷积会增加 MAC
3、网络碎片化会降低并行度

4、逐元素的操作(relu,add)不能忽视。它们的 FLOPs 相对较小,但是 MAC 较大。
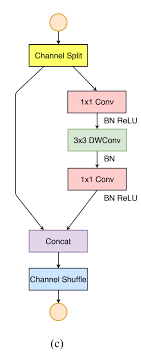
ShuffleNet V2v2版本引入了一种新的运算:channel split,在开始时先将输入特征图在通道维度分成两个分支。左边分支做同等映射,右边的分支包含3个连续的卷积,并且输入和输出通道相同,符合G1。
而且两个1x1卷积不再是组卷积,这符合G2,另外两个分支相当于已经分成两组。两个分支的输出不再是Add元素,而是concat在一起,紧接着是对两个分支concat结果进行channle shuffle,以保证两个分支信息交流。其实concat和channel shuffle可以和下一个模块单元的channel split合成一个元素级运算,这符合原则G4。
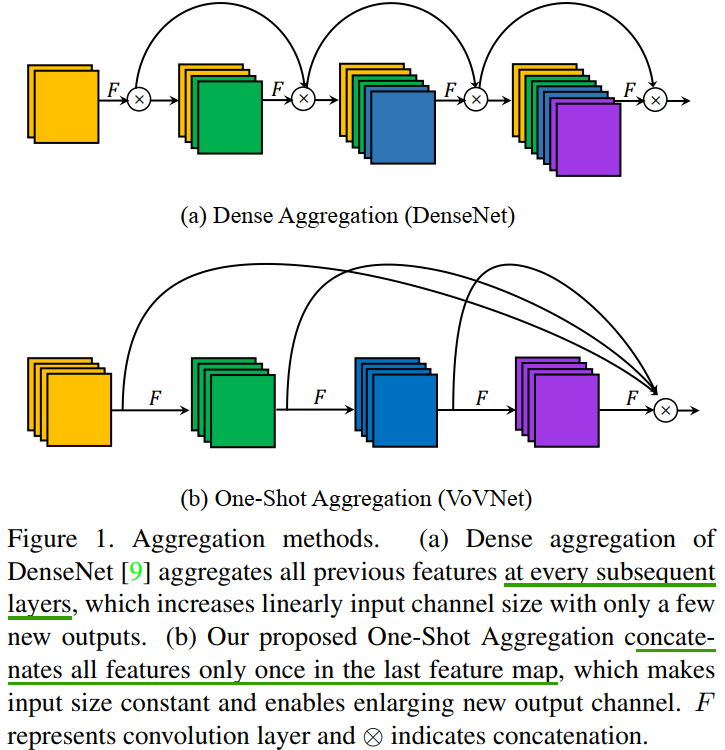
CSPNet
文中认为深度可分离卷积技术并不适用于 NPU 芯片。(内存访问代价与计算量的冲突)
这篇论文从增强CNN的学习能力出发,降低20%计算量的情况下保持甚至提高CNN的能力。
通过将基础层的特征图划分为两部分,然后通过提出的跨阶段层次结构将它们合并,通过对梯度流进行分裂,使梯度流通过不同的网络路径传播。这样就能增加CNN学习能力吗,没啥道理
主流的CNN架构,如ResNet、DenseNet,它们的输出通常是中间层输出的线性或非线性组合。
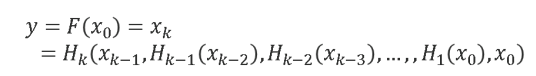
无论是ResNet层还是Dense层,组成它们的每个卷积层的输入都接收到前面所有层的输出。这种架构设计会使第k层将梯度传递给所有 k − 1 , k − 2 , . . . , 1层并使用它来更新权重,这会导致重复学习冗余信息。
CSPNet将x0沿通道分为两部分,x0’和x0’',T用于截断 H1、H2、…Hk的梯度流的转换函数,M 是用于混合两个分段部分的转换函数。
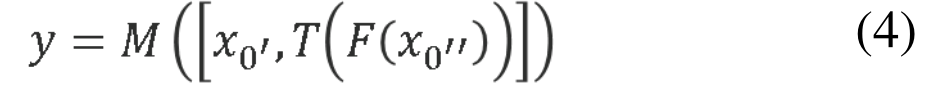
c 将两部分生成的特征图拼接起来,然后进行transition操作。如果采用这种策略,将会重用大量的梯度信息。
d dense block的输出将通过transition层,然后与来自第 1 部分的特征图进行concat。由于梯度流被截断,梯度信息将不会被重用。这里说的梯度截断,指的是有了transition,来自上一层的梯度会发生变化,不会完全重复。
b将两者结合
简述:本文认为同样计算量的深度分离卷积耗时在GPU/NPU比普通卷积更长,想继续利用普通卷积,从增强网络学习能力出发减少计算量,本文认为resnet、densenet这些网络前后层之间的梯度存在冗余,导致学习能力降低,因此在前后层的复用中加入梯度截断(1*1卷积),以防止出现梯度重复
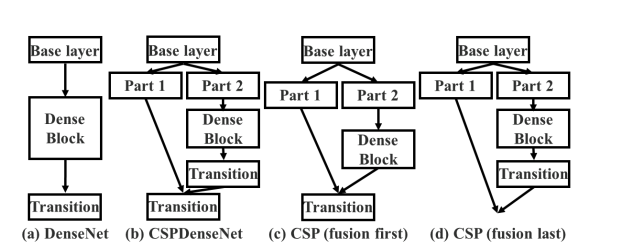
DenseNet和VoVNet
检测任务比分类更加需要多样化尺度去识别对象,因此保留来自各个层的信息对于检测尤为重要,因为网络每一层都有不同的感受野。因此,在目标检测任务上,DenseNet 比 ResNet 有更好更多样化的特征表示。
DenseNet 中的所有特征图都被密集连接用作后续层的输入,因此内存访问成本与网络深度成二次方增加,从而导致计算开销和更多的能耗。
VoVNet的一次聚合的方式,内存访问成本与网络深度成线性增加,比DenseNet小得多。但也能访问前面的特征。
RepVGG
概念结构重参数化(structural re-parameterization)指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。
VGGNet的优势:
1、仅用了33卷积,在GPU 上,3x3 卷积的计算密度(理论运算量除以所用时间)可达 1x1 和 5x5 卷积的四倍,而且在芯片上可集成海量33卷积-relu单元。
2、单路架构,计算快,节约内存,更容易剪枝。
RepVGG的思路是训练一个多分支模型,推理时将多分支模型等价转换为单路模型。
重参数化过程:
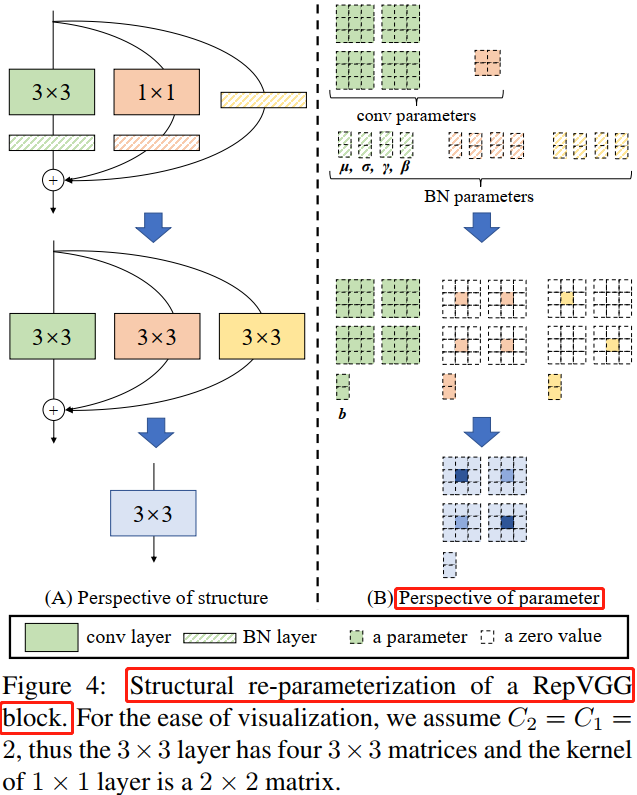
但现在的模型都很复杂,这种方法很难适用。

