
- 1laravel引入element-ui后,blade模板中使用elementui时,事件未生效问题(下载element-ui到本地直接引入项目)_elementui下载到本地引入项目
- 2Hive on Spark安装配置详解(都是坑啊)
- 3100行python实现摄像机偏移、抖动告警_摄像头偏移检测算法 python_python 判断摄像头位置是否移动
- 4Hadoop三大组件之HDFS_hdfscontain
- 5PTA甲级——树的同构 (25分)_pta go语言 树的同构 (25 分)
- 6win10安装tensorflow并配置到pycharm_wrokflow路径配置到pycharm
- 7Git之工作中经常使用的命令(git merge/git revert/git rebase)_git repeat
- 8Spark streaming直连Kafka分区问题_sparkstreaming kafka 6个分区,executor设定4
- 9[Android Studio]Android 数据存储--SQLite数据库存储_androidstudio的sqlite数据库存储
- 10软件开发必看书籍_非专业人士了解软件研发的书籍推荐
Java基本数据类型解析及转换。(面试必问)_二进制转化为short
赞
踩
Java基本数据类型解析及转换。(面试必问)
很多高级程序员在工作中都会遇到数据类型转换等问题。这种问题不能死记硬背,这里总结一下。工作中有需要可以打开博客看看。
总览:
总览图:


位数:
看了上面的列表我们看到有一列叫做”位数“。那么什么他妈是位数呢?
我们知道,计算机不认识我们的代码,代码最后都会被编译为计算机认识的二进制数据(0和1)。
那么这里的位数,就是代表这个数据类型占了多少二进制位数。
例如Byte类型,我们通过包装类中的SIZE属性,可以得到其占用二进制的位数为:8
System.out.println(Byte.SIZE);
- 1
- 2
字节:
字节这个概念在上面的列表中并没有展示。但我们在面试的时候经常会被问到:“你知道int类型占用多少个字节吗?” 。 那什么是他妈的字节呢?
有基础的同学就应该知道,字节的就是Byte。我们打开百度翻译,输入Byte:

好!原来字节就是我们的一种基本数据类型Byte。
一个字节就是一个Byte。而且我们知道一个Byte所占位数是8位!
所以我们知道:一个字节占8个位数
所以我们就能知道其他所有的数据类型所占用的位数了。如:
例如int类型,我们先通过包装类获取到它的位数:32.再除以8(8个位数=一个字节)得到:int类型占4个字节
System.out.println(Integer.SIZE/8);
- 1
- 2
取值范围:
取值返回标定的当前数据类型可以承载的数据的最小值和最大值。其取值范围再数据类型的包装内的属性中可以得到:

那么取值范围是怎么计算出来的呢? 我们用int类型来举例:
4个字节
一个字节占8位
所以4个字节就是4*8=32位 因为在计算机的二进制中有一个符号位,32-1=31,剩下31个位置存放数字
计算:每个位置只能是0,1这两个数字中的任意一个,有两种情况
31个2相乘:2的31次方
范围:-2^31到 2^31-1 。
数据类型解析:
byte:
byte是所有数据类型的基础,也是最重要的一个数据类型。例如文件传输,硬件数据传输等等。。都是一个字节一个字节进行的传输。所以弄懂byte是非常重要的。
byte是做为最小的数字来处理的,因此它的值域被定义为-128~127,也就是signed byte。
接下来,我们用一段代码来更深刻地理解byte:
int a = 456;
byte res= (byte) a;
System.out.println(res);
- 1
- 2
- 3
上述代码,最后会输出-56。原因如下:
456的二进制表示是111001000,由于int是32位的二进制,所以在计算机中,实际上是00000000000……111001000。int转成byte的时候,那么计算机会只保留最后8位,即11001000。
然后11001000的最高位是1,那么表示是一个负数,而负数在计算机中都是以补码的形式保存的,所以我们计算11001000的原码为00111000,即56,所以11001000表示的是-56,所以最后res的值为-56。
使用场景:
- 字节流传输(输入和输出)。 比如现在有一个需求,使用Socket将本地的一个String字符串以字节流的方式发送给第三方服务。这个时候我们不能直接将数据以String明文直接传输。这个时候就需要用到btye。
String aaa = "消息";
byte[] bytes = aaa.getBytes(); 获取到String对应的byte数组
socketChannel.write(ByteBuffer.wrap(bytes); 伪代码,通过Socket发送字节流
- 1
- 2
- 3
- 4
- 5
- 文件的读取。 这个很常用。
File file = new File("C:\\Users\\Administrator\\Desktop\\oldSamping.txt");
InputStream inputStream = new FileInputStream(file);
int len = 0;
byte[] b2 = new byte[1024]; 一次读取1024个字节
while ((len = inputStream.read(b2)) != -1){ 读到文件被读完为止
String value = new String(b2,0,len); 将byte数组解密成String字符串
System.out.println(value);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 字符串编码转换
String name="sunCK";
String newName=new String(name.getBytes(),"UTF-8");
newName为将编码转为utf-8后的字符串。
- 1
- 2
- 3
- 4
- 5
short:
short是开发中使用较少的一种(整数)数据类型。 我们用的比较多的是byte、int、long。那short到底有什么特别的呢? 什么时候会用到short?
我们先看看short的取值范围:
System.out.println(Short.MAX_VALUE);
System.out.println(Short.MIN_VALUE);
- 1
- 2
得到的结果是-32768 到 32767之间。也就是short类型的变量不能大于32767或小于-32768。
现在看一个例子:
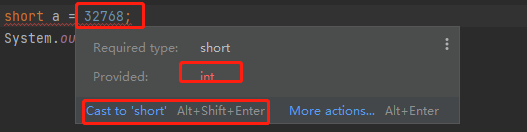
我们给short变量赋予了超出了它取值范围的值。我们的idea编译器报错了,提示我们32768这个变量已经不能赋予给short类型了。32768已经是一个int类型的整数了,因为32768已经超过了short的最大取值范围,已经属于int的取值范围了。这个时候编译器要求我们进行数据类型强转。
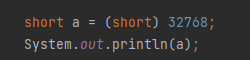
答应出来看,发现结果是-32768。这里的原因和上面的Byte原因一样。由于short是16为二进制,而int是32为二进制。这里强转会出现这样的问题。
使用场景:
为社么short用得很少呢?short所占用的空间很少,再取值范围内应该多用才对啊?
所有的short参与运算时都会自动转化成int,并且这一个short在Java虚拟机里面仍然占用四个字节的空间。
相反的,short和int赋值时还要经常进行类型转换。
所以很少使用short(byte也是一样),一般情况下都int.
int:
int是开发中用得最多得数据类型了。这里就跳过
long:
long也是一种整数数据类型。我们先来看看它的取值范围:
System.out.println(Long.MIN_VALUE);
System.out.println(Long.MAX_VALUE);
- 1
- 2
结果: -9223372036854775808 —— 9223372036854775807
首先你肯定在想,如果我赋值一个long比9223372036854775807更大的数会发生什么? 这里我们就不试了。没有比long更大的基本数据类型了。如果超出的long的取值范围,那么我们可以用BigInteger或BigDecimal这两个类来存放。
而且,这里要强调一下,取值范围小的数据类型可以转为取值范围大的数据类型,如int可以转为long。而反过来则会出现问题。int类型可能装不下long类型的数据。
关于long和Long:
关于long和Long,还有一个坑。就是两个long数据的==对比。我们来看一个例子。

首先我们要知道,Long是long的包装类,Long声明的是一个对象,而由Long声明的变量在进行对比的时候,值在-128和128区间[-128,127] 内可以直接使用等号返回正常。如果在这个区间之外的数据就只能使用Long的对象比较equals或者Long.valueOf取值后比较。
而用long声明的数据就可以直接用等号去判断相等否。
String转Long:
-
Long.ValueOf(“String”) 返回Long包装类型
-
Long.parseLong(“String”) 返回long基本数据类型
使用场景:
- 数据的id。 由于long可以存64位字节的数字。我们可以用随机算法生成long类型的数据作为业务数据的id。id重复的概率就很小很小,可以说基本没有。
float和double:
System.out.println(2.00-1.10);
- 1
输出的结果是:0.8999999999999999,很奇怪,并不是我们想要的值0.9。
System.out.println(2.00f-1.10f);
- 1
输出的结果是:0.9。又正确了,为什么会导致这种问题?程序中为什么要尽量避免浮点数比较?
在java中浮点型默认是double的,及2.00和1.10都要在计算机里转换进行二进制存储,这就涉及到数据精度,出现这个现象的原因正是浮点型数据的精度问题。先了解下float、double的基本知识:
在java中float占4个字节32位,double占8个字节64位,其在内存里的存储结构如下:

System.out.println(2.00-1.10);中的1.10不能被计算机精确存储,这里的2.00和1.10都是默认为double类型。我们以1.10来举例看看计算机如何将浮点型数据转换成二进制存储:
1.10整数部分就是1,转换成二进制1(这里整数转二进制不再赘述)
小数部分:0.1
0.12=0.2取整数部分0,基数=0.2
0.22=0.4取整数部分0,基数=0.4
0.42=0.8取整数部分0,基数=0.8
0.82=1.6取整数部分1,基数=1.6-1=0.6
0.62=1.2取整数部分1,基数=1.2-1=0.2
0.22=0.4取整数部分0,基数=0.4
。。。
直至基数为0。1.1用二进制表示为:1.000110…xxxx…(后面表示省略)
而double类型表示小数部分只有52位,当向后计算 52位后基数还不为0,那后面的部分只能舍弃,从这里可以看出float、double并不能准确表示每一位小数,对于有的小数只能无限趋向它。在计算机 中加减成除运算实际上最后都要在计算机中转换成二进制的加运算,由此,当计算机运行System.out.println(2.00-1.10);
时会拿他们在计算机内存中的二进制表示计算,而1.10的二进制表示本身就不准确,所以会出现0.8999999999999999的结果。
但为什么System.out.println(2.00f-1.10f);得出的结果是0.9呢。因为float精度没有double精度那么大,小数部分0.1二进制表示被舍去的比较多。
解决方法:
使用BigDecimal提供的方法进行比较或运算,但要注意在构造BigDecimal的时候使用float、double的字符串形式构建,BigDecimal(String val);
相互装换:
我们现在知道,float占用空间比double小,所以float得精度会比double小。
double d = 3.14;
float f = (float)d;
System.out.println(f);
输出结果是:3.14;
float f = 127.1f;
double d = f;
System.out.println(d);
输出结果是:127.0999984741211
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
因此,double可以转成float,而float不能转成double。因为double精度高(小数位更多)!
如果float非要转成double怎么办呢?
将float型转换为字符串型,再转换为精度更高的BigDecimal型,再将其转换为double型。
char:
和前面得不同。Char存储的不是整数或小数了。它存储的是字符!一个Char是16为,2个字节。
char a='a'; 任意单个字符,加单引号。
char a='中';任意单个中文字,加单引号。
char a=111;整数。0~65535。十进制、八进制、十六进制均可。输出字符编码表中对应的字符。
注:只能放单个字符。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
运算:
char类型是可以运算的因为char在ASCII等字符编码表中有对应的数值。
在JAVA中,对char类型字符运行时,直接当做ASCII表对应的整数来对待。
char m='a'; ——a。 char m='a'+'b'; ——Ã。 char类型相加,提升为int类型,输出对应的字符。注,在CMD.exe用输出结果是问题?,不同的编码输出显示不一样。Eclipse中须改成UTF-8。 int m='a'+'b'; ——195。195没有超出int范围,直接输出195。 char m='a'+b; ——报错。因为b是一个赋值的变量。 char m=197; ——Ã。 输出字符编码表中对应的字符。 char m='197; ——报错。因为有单引号,表示是字符,只允许放单个字符。 char m='a'+1; ——b。提升为int,计算结果98对应的字符是b。 char m='中'+'国'; ——42282。 char m='中'+'国'+'国'+'国'; ——报错。int转char有损失。因为结果已经超出char类型的范围。 int m='中'+'国'+'国'+'国'; ——86820 char m='中'+1; ——丮。1是int,结果提升为int,输出对应的字符。 char m='中'+"国"; ——报错。String无法转换为char。 System.out.println('中'+"国"); ——中国。没有变量附值的过程。String与任何字符用“+”相连,转换为String。

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
总结:
用单引号’'标识,只能放单个字符。
char+char,char+int——类型均提升为int,附值char变量后,输出字符编码表中对应的字符。.
boolean:
boolean 数据类型 boolean 变量存储为 8位(1 个字节)的数值形式,但只能是 True 或是 False。
这里不多做解析了
好了 基本已经讲完,欢迎大家评论区指出不足,一起学习进步!
大家看完了点个赞,码字不容易啊。。。

