- 1提问AI:详细描述使用5v供电,电机驱动芯片制作一个简易的直流有感无刷电机驱动电路方案_5v无刷电机驱动芯片
- 2Spring Boot:SpringBoot 如何优雅地定制JSON响应数据返回_springboot设置响应为json
- 3ECCV 2020 亮点摘要(下)
- 4R语言建立回归分析,并利用VIF查看共线性问题的例子_r语言vif
- 5MySQL安装及配置详细教程(保姆级,超详细!)_mysql的安装与配置步骤
- 6华为OD机试真题 Python 实现【整数对最小和】_给定两个整数数组 array1 array2 数组元素按升序排列 假设从array1 array2中
- 7selenium自动获取cookies用于requests做接口请求爬虫_selenium如何获取cookie并注入request
- 8Linux 三十六章
- 9Chat GPT Plus:适合您企业的终极人工智能聊天机器人_chatgpt plus
- 102023年互联网大厂寒冬已至?Java程序员还能找到工作吗?_it行业寒冬2023
7.数据仓库搭建之数据仓库环境准备_数据存储环境配置
赞
踩
数据仓库搭建之数据仓库环境准备
1.Hive安装部署
(1)我们首先需要将apache-hive-3.1.2-bin.tar.gz上传到linux的**/opt/software**目录下
(2)解压apache-hive-3.1.2-bin.tar.gz到**/opt/module/**目录下面
[root@hadoop102 software]$ tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
- 1
(3)修改apache-hive-3.1.2-bin.tar.gz的名称为hive
[root@hadoop102 software]$ mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
- 1
(4)修改/etc/profile.d/my_env.sh,添加环境变量
[root@hadoop102 software]$ sudo vim /etc/profile.d/my_env.sh
- 1
具体添加的内容如下所示:
#HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin
- 1
- 2
- 3
使用source /etc/profile.d/my_env.sh,使环境变量生效
[root@hadoop102 software]$ source /etc/profile.d/my_env.sh
- 1
(5)解决日志Jar包冲突,进入/opt/module/hive/lib目录
[root@hadoop102 lib]$ mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak
- 1
2.Hive元数据配置到Mysql
2.1为什么使用Mysql作为元数据库而不使用Derby呢?
Hive默认的元数据库使Derby。Apache Derby非常小巧,核心部分derby.jar只有2M,所以既可以做为单独的数据库服务器使用,也可以内嵌在应用程序中使用。所以hive采用了Derby作为一个内嵌的元数据库,可以完成hive安装的简单测试。
hive安装完成之后,就可以在hive shell中执行一些基本的操作,创建表、查询等等。但是会有一个较为明显的问题:
当在某个目录下启动终端,进入hive shell时,hive默认会在当前目录下生成 一个 derby 文件 和 一个 metastore_db 目录 ,这两个文件主要保存刚刚在shell中操作的一些sql的结果,比如新建的表、添加的分区等等
这种存储方式的带来 弊端
1.在同一个目录下同时只能有一个hive客户端能使用数据库
2. 切换目录启动新的shell,无法查看之前创建的表,不能实现表数据的共享
由于使用默认的元数据库有些弊端,所以采用mysql保存hive元数据解决上面的问题。hive所有的元数据都保存在同一个库里,这样不同开发者创建的表可以实现共享。
2.2Hive元数据配置到Mysql
(1)首先,我们需要拷贝Mysql的JDBC驱动到Hive的lib目录下
[root@hadoop102 lib]$ cp /opt/software/mysql-connector-java-5.1.27.jar /opt/module/hive/lib/
- 1
(2)配置MySQL作为元数据存储。我们在/opt/module/hive/conf目录下新建hive-site.xml文件
[root@hadoop102 conf]$ vim hive-site.xml
- 1
我们向hive-site.xml中添加如下内容:
<?xml version="1.0"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>******</value> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property> <property> <name>hive.metastore.schema.verification</name> <value>false</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>hadoop102</value> </property> <property> <name>hive.metastore.event.db.notification.api.auth</name> <value>false</value> </property> <property> <name>hive.cli.print.header</name> <value>true</value> </property> <property> <name>hive.cli.print.current.db</name> <value>true</value> </property> </configuration>

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
3.启动HIve
3.1初始化元数据库
(1)登录Mysql
[atguigu@hadoop102 conf]$ mysql -uroot -p123456
- 1
(2)新建Hive元数据库
mysql> create database metastore;
mysql> quit;
- 1
- 2
(3)初始化Hive元数据库
[root@hadoop102 conf]$ schematool -initSchema -dbType mysql -verbose
- 1
3.2启动Hive客户端测试
(1)使用bin/hive启动Hive客户端测试
[root@hadoop102 hive]$ bin/hive
- 1
(2)查看数据库
hive (default)> show databases;
- 1
4.修改元数据库字符集
Hive元数据库的字符集默认为Latin1,由于其不支持中文字符,故若建表语句中包含中文注释,会出现乱码现象。如需解决乱码问题,须做以下修改。
修改Hive元数据库中存储注释的字段的字符集为utf-8:
(1)字段注释
mysql> alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
- 1
(2)表注释
mysql> alter table TABLE_PARAMS modify column PARAM_VALUE mediumtext character set utf8;
- 1
之后修改hive-site.xml中JDBC URL,如下所示:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false&useUnicode=true&characterEncoding=UTF-8</value>
</property>
- 1
- 2
- 3
- 4
5.Hive on Spark配置
Hive的引擎包括有MR(默认)、tez以及spark。
5.1Hive on Spark和Spark on Hive比较
Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。
Spark on Hive : Hive只作为存储元数据,Spark负责SQL解析优化,语法是Spark SQL语法,Spark负责采用RDD执行。
两者的运行速度相差不大。
5.2Hive on Spark配置
(1)遇到的兼容性问题
在官网下载的Hive3.1.2和Spark3.0.0默认是不兼容的。因为Hive3.1.2支持的Spark版本是2.4.5,所以需要我们重新编译Hive3.1.2版本。
编译的步骤如下所示:
1.官网下载Hive3.1.2源码,修改pom文件中引用的Spark版本为3.0.0。
2.编译通过后,直接打包获取jar包。
(2)在Hive所在节点上部署Spark
上传并解压spark-3.0.0-bin-hadoop3.2.tgz
[root@hadoop102 software]$ tar -zxvf spark-3.0.0-bin-hadoop3.2.tgz -C /opt/module/
- 1
修改spark-3.0.0-bin-hadoop3.2 为spark
[root@hadoop102 module]$ mv /opt/module/spark-3.0.0-bin-hadoop3.2 /opt/module/spark
- 1
(3)配置SPARK_HOME环境变量,在/etc/profile.d/my_env.sh中添加如下内容:
# SPARK_HOME
export SPARK_HOME=/opt/module/spark
export PATH=$PATH:$SPARK_HOME/bin
- 1
- 2
- 3
通过source使该文件生效
[root@hadoop102 module]$ source /etc/profile.d/my_env.sh
- 1
(4)在hive中创建spark配置文件
[root@hadoop102 module]$ vim /opt/module/hive/conf/spark-defaults.conf
- 1
我们在配置文件中添加如下内容,在spark执行任务时,会根据下面的参数执行
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop102:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
- 1
- 2
- 3
- 4
- 5
我们在HDFS创建路径,存储历史日志
[root@hadoop102 /]$ hadoop fs -mkdir /spark-history
- 1
(5)向HDFS上传Spark纯净版jar包
由于Spark3.0.0非纯净版默认支持的是hive2.3.7版本,直接使用会和安装的Hive3.1.2出现兼容性问题。所以采用Spark纯净版jar包,不包含hadoop和hive相关依赖,避免冲突。
为什么要上传到HDFS上呢?
Hive任务最终由Spark来执行,Spark任务资源分配由Yarn来调度,该任务有可能被分配到集群的任何一个节点。所以需要将Spark的依赖上传到HDFS集群路径,这样集群中任何一个节点都能获取到。
1.上传并解压spark-3.0.0-bin-without-hadoop.tgz
[root@hadoop102 software]$ tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
- 1
2.上传Spark纯净版jar包到HDFS
[root@hadoop102 software]$ hadoop fs -mkdir /spark-jars
[root@hadoop102 software]$ hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
- 1
- 2
(6)修改hive-site.xml文件,在/opt/module/hive/conf/hive-site.xml中添加如下内容
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop102:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
6.Hive on Spark测试
(1)启动hive客户端
[root@hadoop102 hive]$ bin/hive
- 1

(2)创建一张测试表
hive (default)> create table student(id int, name string);
- 1
(3)通过insert测试效果
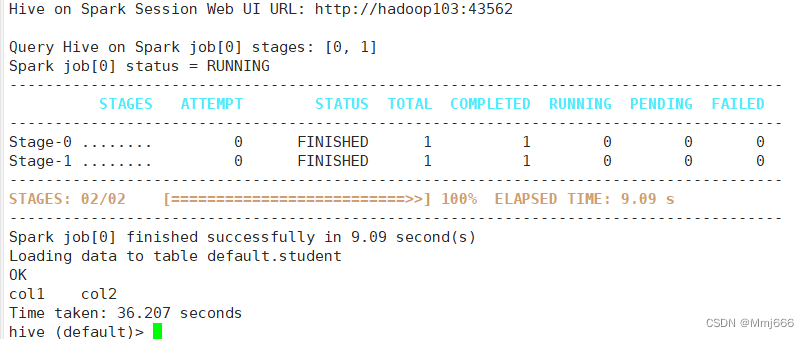
hive (default)> insert into table student values(1,'abc');
- 1
8.数据仓库开发环境DataGrip配置
数仓开发工具我们本次项目选用的是DataGrip,由于是在校大学生,所以具有免费的使用权:D。
我们只需要使用DataGrip连接上我们的hive即可
(1)在hadoop102上启动hiveserver2服务
[root@hadoop102 hive]# hiveserver2
- 1
(2)创建连接
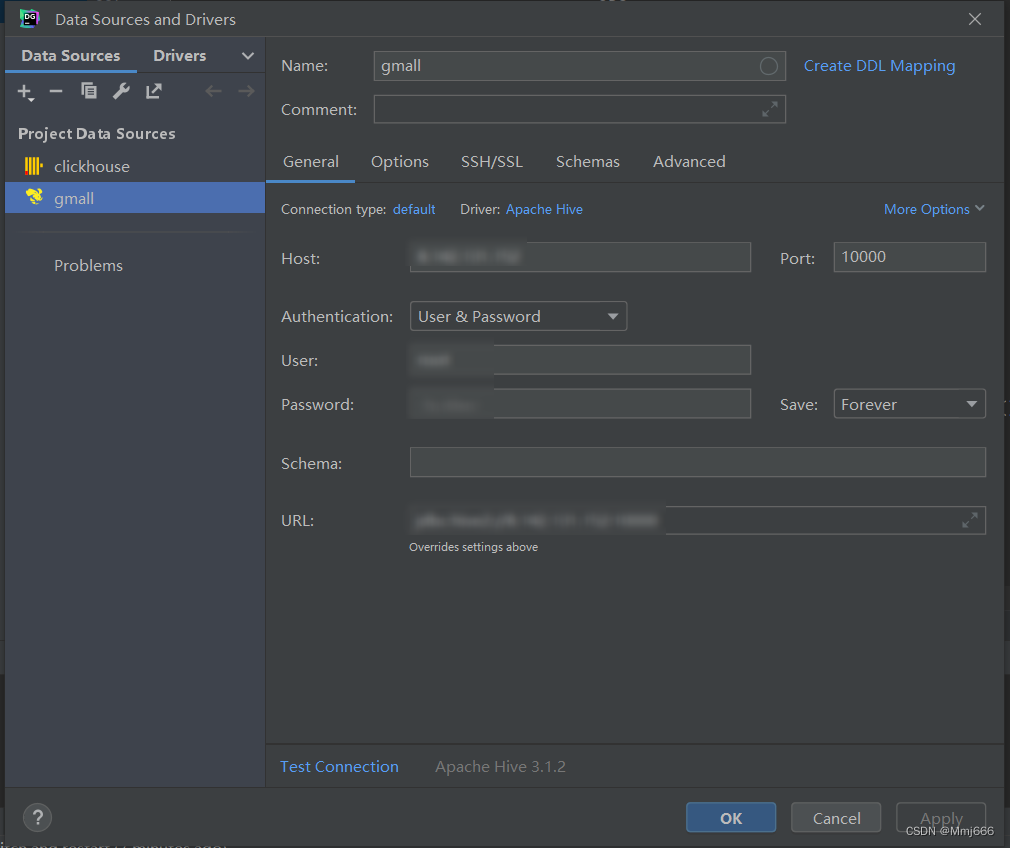
(3)配置连接属性
(4)连接成功
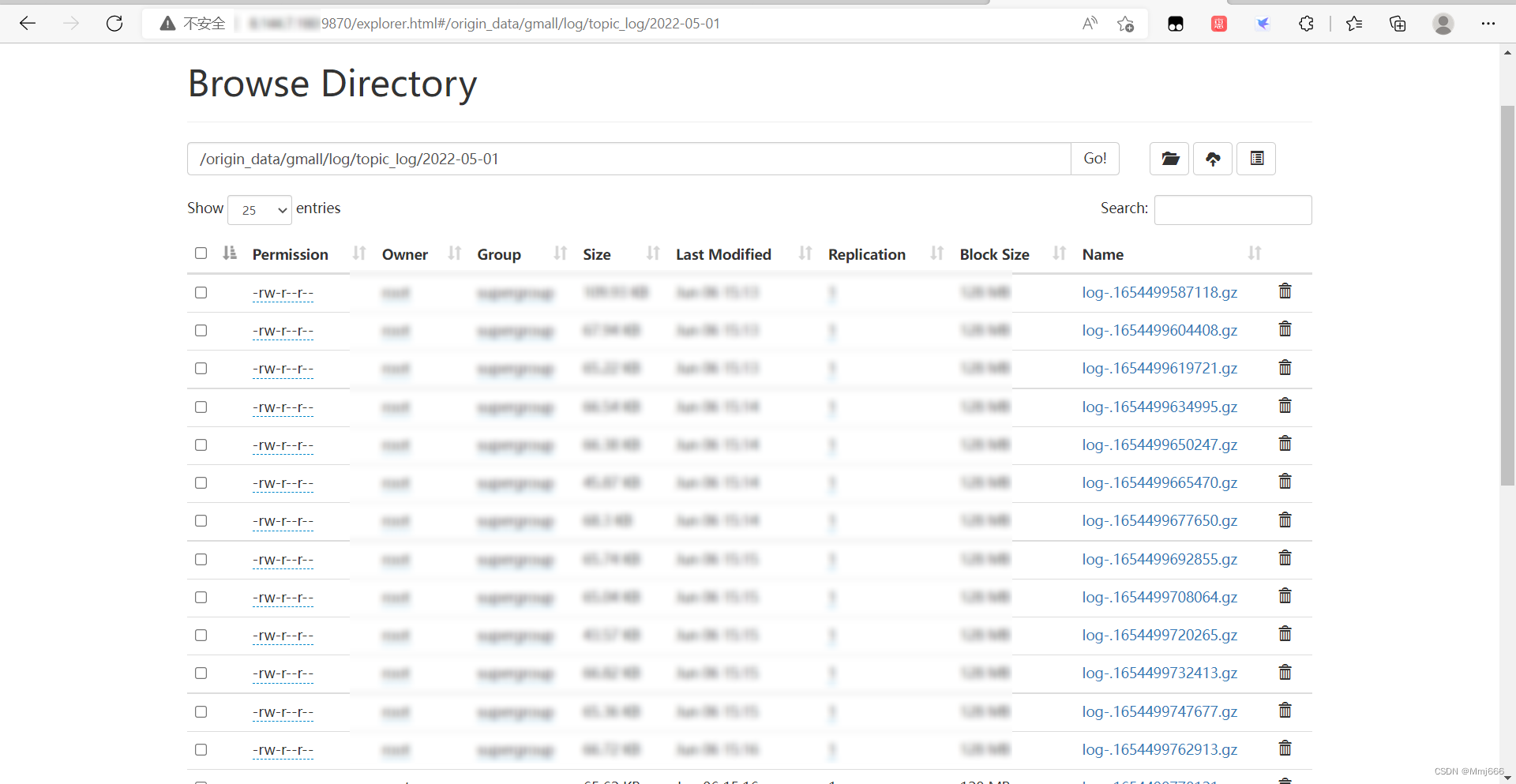
9.2022-05-01模拟数据准备
模拟用户行为数据,用户行为日志,一般是没有历史数据的,故日志只需要准备2022-05-01一天的数据。我们使用先前搭建的数据采集通道采集到HDFS上。
模拟业务数据,业务数据一般存在历史数据,此处需准备2022-04-28至2022-05-01的数据。我们使用先前搭建的数据采集通道采集到HDFS上。