
- 1数据结构 易错题合集(持续更新)_数据结构易错题
- 2跟着医生学kivy:kivy-garden 究竟怎样安装?_kivy garden安装
- 3在 QML 中,ComboBox 是一种常用的用户界面控件,通常用于提供一个下拉式的选择框,允许用户从预定义的选项列表中选择一个值_qml 下拉框
- 4当35岁中年危机码农遇上GPT.....
- 5基于大语言模型的智能问答系统设计与实践_基于大模型的智能问答技术
- 6c++有趣的代码_C++开源项目:十行代码15个BUG,你入坑了吗?
- 7基于SpringBoot面向智慧教育的实习实践系统
- 8在红帽上搭建dm7的主备的一些问题_dm7主备搭建守护进程报错无法绑定端口
- 9openlayers入门添加百度地图绘制点线面_openlayers 添加百度地图
- 10如何用python进行接口测试(详细教程)_python接口测试
22K star的超强工具:Ollama,一条命令在本地跑 Llama2_ollama 启动
赞
踩
前言
在当今的科技时代,AI 已经成为许多领域的关键技术。AI 的应用范围广泛,从自动驾驶汽车到语音助手,再到智能家居系统,都有着 AI 的身影,而随着Facebook 开源 LLama2 更让越来越多的人接触到了开源大模型。
今天我们推荐的是一条命令快速在本地运行大模型,在GitHub超过22K Star的开源项目:ollama。

ollama是什么?
Ollama 是一个强大的框架,设计用于在 Docker 容器中部署 LLM。Ollama 的主要功能是在 Docker 容器内部署和管理 LLM 的促进者,它使该过程变得非常简单。它帮助用户快速在本地运行大模型,通过简单的安装指令,可以让用户执行一条命令就在本地运行开源大型语言模型,例如 Llama 2。

Ollama 将模型权重、配置和数据捆绑到一个包中,定义成 Modelfile。它优化了设置和配置细节,包括 GPU 使用情况。
安装 ollama
ollama极大的简化了安装的过程,并提供了多种选择。
支持的平台包括:Mac和Linux,并提供了docker 镜像。
Mac:
如果你使用的是Mac,那么你可以直接下载安装包,地址如下:
https://ollama.ai/download
下载完成后,直接安装即可。
Linux:
Linux同样也提供了一键安装命令:
curl https://ollama.ai/install.sh | sh 直接执行命令,可以完成默认安装。
直接执行命令,可以完成默认安装。
使用 ollama
笔者以Mac为例,安装完成后打开ollama的应用,简单的点击确认后,就已经启动了ollama的服务器。
下一步我们启动一个Llama2,只需要执行:
ollama run llama2
之后会自动去pull Llama2的模型,并运行,确实非常的便捷。另外还支持将Ollama作为服务提供到网络环境中,在 macOS 中:
OLLAMA_HOST=0.0.0.0:11434 ollama serve除了Llama2以外 Ollama 还支持其他的开原模型,如下图:
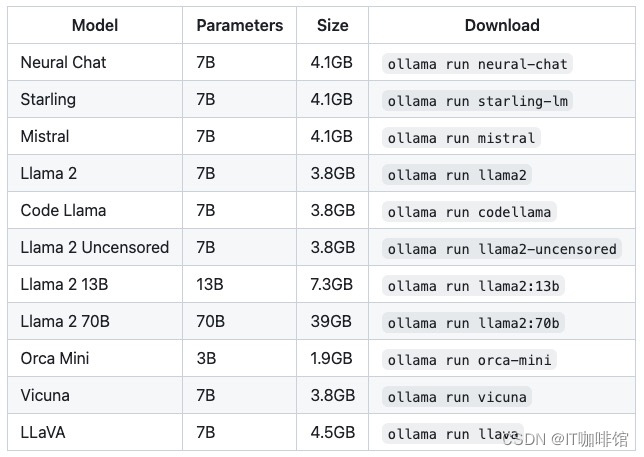
另外还需要注意一下文档中的运行资源说明:
3B模型需要8G内存,7B模型需要16G内存,13B模型需要32G内存。
除了简单的启动模型外,Ollama 可以通过编写 Modelfile 来导入更多的自定义模型,具体的使用方法和配置请自行查阅文档。
Ollama具备灵活的扩展性,它支持和很多工具集成,除了命令行的使用方式,可以通过配合UI界面,简单快速的打造一个类ChatGPT应用。笔者也计划抽空写一期专门的教程,来介绍一个如果快速通过Ollama搭建一个仿ChatGPT。
项目特点
- 开源:很显然这是首要特点,开源推动者项目的持续发展
- 开箱即用:一条命令的方式,简化了大量的工作,降低了门槛。
- 可扩展:可以和很多工具进行集成使用,有更多的玩法
- 轻量化:不需要太多的资源,Mac就能跑
项目信息
- 项目名称:Ollama
- 官方网站:https://ollama.ai/
- GitHub 链接:https://github.com/jmorganca/ollama
- Star 数:22K+

