
- 1Unity 中 Android Manifest_unity androidmanifest
- 2总结:kafka_kafka总结
- 3云计算——虚拟化中的网络架构与虚拟网络(文末送书)_网络功能虚拟化架构下的虚拟网络功能设计以及评估网络构建
- 4ElementUI - 自定义全局主题颜色及主题颜色切换(最简洁的方式 | 利用 element-variables.scss)_element ui定义全局颜色变量
- 5Maven下载安装的详细教程
- 6封面的最佳设计 _csdn封面图设计
- 7el-tooltip超出文字长度进行显示_el-tooptip设置文本最大长度超过悬浮显示
- 8大数据(078)Spark【Spark 源码分析----划分Stage】_spark源码解析
- 9maven仓库网址
- 10An error occure while resolving packages: Project has invaild dependencies解决办法
R计算系统的快速入门_expression<-data.frame
赞
踩
R简介
基于R体系下的Bioconductor项目为用户提供了整体解决方案。
R的编程比较简单。不像Java、C等那么难学。但灵活性太强了,有时候反而觉得不易掌握。R最强大的地方就是它的统计计算功能,这可以从数据结构和算法两方面来说。
首先,它的许多数据结构都是为数据处理的需要而设计的。例如其中有一个叫做data.frame的数据类型,它本质上就是一张二维表,每一行是一条记录,每一列是一个字段(按统计学的术语来说,每一行是一个观测,每一列是一个变量)。data.frame是一种类矩阵结构,可以对行和列进行一系列的操作,但它又允许每一列的数据是不同的类型,这跟现实中的很多数据是相符的。当然,其它各种流行的语言要实现这些操作都不是难事,只不过R语言是把这些数据结构作为内置的一部分。
此外,R语言的绝大多数操作都是向量化的,这和Matlab很像,因此省去了很多显式的循环。例如,如果x是一个向量,那么我要将它标准化(减去均值,再除以标准差)就只需要 (x - mean(x)) / sd(x) 形式上就像是在写数学公式。
除去基础的数据结构之外,数据处理最重要的一点就是各种统计方法,在这一点上R语言可以不太谦虚地说是无言能及。
R语言的统计方法更新很快,目前已经有3000多个附加软件包,其中大多数都是统计学专业的老师和学生,以及数据分析人员贡献的。当然这有好处也有坏处,好处是你永远可以找到最新的统计方法,因为那些大牛们发paper时基本上都会将程序编好然后挂到网站上。
推荐一个R的IDE工具:RStudio。下载地址:http://www.rstudio.com/. 不管怎么说,肯定比R自带的那个编辑器要强喽。
Nicklaus Wirth——Pascal之父,曾经因为一句话“算法+数据结构=程序”,获得图灵奖。
所以,有必要详细地介绍R的数据结构,特别是那些独特的数据结构,它们给数据处理带来了很大的便利。
数据结构
向量
向量是R内置的 最基本的数据结构, 相当于其它编程语言的数组 .那么如何从头建立一个向量呢?
v <- c(2, 3, 2, 2, 1) v[1] 2 3 2 2 1
从回显中可以看到,c函数将一串以逗号分隔的整数存进了一个名为v的向量里。c函数(英文:concatenate)的目的是将一串数连接起来。其中[1]表示行数,当内容太多的时候,R会自动换行。
w - 1:10; w [1] 1 2 3 4 5 6 7 8 9 10围绕向量这一数据结构,有一些内建的方法特别有用。例如查询一个向量的长度,
length(w); [1] 10再如设置向量的元素的名字,
names(v) <- c("a","b","c","d","e")
> names(v)
[1] "a" "b" "c" "d" "e" 设置名字有什么用呢?
比如想取一个向量的特定的元素,可以这么取
names(v) [1] "a" "b" "c" "d" "e" > v["b"]实际上,对于简单的向量,可以直接根据索引取值。
> v[2] b 3实际上,可以在建立向量的同时设置列名。
> n <- c(a = 1, b = 2, c = 3); > n a b c 1 2 3建立好的向量还可以修改。
> v["a"] <- 100; > v a b c d e 100 3 2 2 1修改的方式并不限于单个值。可以从向量中取出一部分内容构建新的向量。
> v[-1] b c d e 3 2 2 1这里,可以看出使用-1的索引,实际上是把第一列排除了。相似的用法也可以在Perl里找到影子,但是意义完全不同,请注意区分。
更复杂点,去除两个值,结果是b和d两列被去除了。
> v[-c(2, 4)] a c e 100 2 1这里,使用了更高级的技巧,v>2返回相同长度的只包含TRUE或FALSE的向量。
> v[v>2] a b 100 3这等价于下面的用法。
> v[which(v > 2)] a b 100 3
如果向量的长度不够,可以扩充。
> length(v) <- 11 > v a b c d e 100 3 2 2 1 NA NA NA NA NA NA
我们可以看到长度扩大到11,最后面六个值为NA,相当于JAVA里的Null。
因子
虽然初学者很少使用到因子类型,但是适当的了解可以为以后打下基础。因子的特点是用于分类数据,而且不同水平间不重复。
建立一个因子的方法:
> a <- factor(c("low", "low", "low", "high", "high"), levels = c("low", "medium", "high"))
> a
[1] low low low high high
Levels: low medium high
访问一个因子的水平:
> levels(a) [1] "low" "medium" "high"
列表
列表在功能上和JAVA和Perl里的哈希类似。特别是函数的返回值较多时,可以用列表打包,从而返回一个唯一值。列表中的值可以是异质性的,但次序是固定的。
建立一个列表的方法:
l <- list(1,2,3,4,5) > l [[1]] [1] 1 [[2]] [1] 2 [[3]] [1] 3 [[4]] [1] 4 [[5]] [1] 5更进一步,建立一个命名列表的方法:
info <-list(name="jerry",threedimension=c(40,60,90),salary=2000) info $name [1] "jerry" $threedimension [1] 40 60 90 $salary [1] 2000要想从一个列表中取出特定的值,需要使用索引或名称:
l[1] [[1]] [1] 1 > info["name"] $name [1] "jerry" > class(info["name"]) [1] "list"实际上,这种方法得到的还是一个列表,只不过只包含一个值。class函数可以得出类型,这里是list类型。
通过$符号可以得到向量形式的值。
info$salary [1] 2000 > class(info$name) [1] "character"可以从class函数返回的值看出得到的一个字符串向量。
使用unlist函数可以得到将列表转换成向量形式。
unlist(info) name threedimension1 threedimension2 threedimension3 salary "jerry" "40" "60" "90" "2000"
矩阵
可以想象的出,矩阵是用来存储数据的。可以将矩阵看成特殊的向量。
从头建立一个矩阵的方法:
m <- matrix(data=1:12,nrow=4,ncol=3, dimnames=list(c("r1","r2","r3","r4"), c("c1","c2","c3")))
> m
c1 c2 c3
r1 1 5 9
r2 2 6 10
r3 3 7 11
r4 4 8 12
data后面的数值向量会以此填充进4行3列的矩阵中,而且默认的填充方向是纵向的。同时,dimnames指定了行和列的名字。
比较令人感兴趣的是从矩阵中提取感兴趣的数值块,这个过程叫做切片。
m[1,] #抽取矩阵的第一行,学过Mathlab的童鞋应该不陌生 c1 c2 c3 1 5 9 > m[,1] #抽取矩阵的第一列 r1 r2 r3 r4 1 2 3 4 > m[1:2,1:2] #同时抽取行和列 c1 c2 r1 1 5 r2 2 6抽取矩阵的行或列的名称:
rownames(m) [1] "r1" "r2" "r3" "r4" > colnames(m) [1] "c1" "c2" "c3" > colnames(m)[2] #只抽取第二列的名称 [1] "c2"
数据框
数据框差不多是最有用的数据结构了。从外部输入的数据都是以数据框的形式存储的。数据框类似于矩阵,但是能用于存储异质性的数据。
从头建立一个数据框的方法:
Expression<-data.frame(sample1=c(.8,.4,.2), sample2=c(.2,.1,.2),sample3=c(.2,.3,.1)); > Expression sample1 sample2 sample3 1 0.8 0.2 0.2 2 0.4 0.1 0.3 3 0.2 0.2 0.1这里,直接对数据框的列进行了命名。Expression好似一个矩阵,因为没有字符数据,所以它可以很容易地转换为矩阵,这样可以使用矩阵特异的方法对其进行深入的操作了。
> exp<-as.matrix(Expression) > exp sample1 sample2 sample2.1 [1,] 0.8 0.2 0.2 [2,] 0.4 0.1 0.3 [3,] 0.2 0.2 0.1 > class(exp) [1] "matrix"as.matrix是将任何可转换为matrix的对象转换为matrix的方法。实际上,还有其它方法可用于类型转换,例如is.character可以将其它对象转换为字符串。
> class(v) [1] "numeric" > class(as.character(v)) [1] "character"童鞋们可以自己试试其它类型转换的方法,如as.numeric, as.logical, as.data.frame等等。
同样可以对数据框通过索引或列名读取部分数据。
> Expression[1:2] sample1 sample2 1 0.8 0.2 2 0.4 0.1 3 0.2 0.2 > class(Expression[1:2]) [1] "data.frame" > Expression$sample1 [1] 0.8 0.4 0.2 > class(Expression$sample1) [1] "numeric"可以看出,切片操作得到的是数据框,但如果得到的是一维数据的话,会自动转成向量。
和Matlab类似,R也提供了查询矩阵或数据框的维度的方法。
> nrow(exp)#查询矩阵的行数 [1] 3 > nrow(Expression)#查询数据框的行数 [1] 3 > ncol(exp)#查询矩阵的列数 [1] 3 > ncol(Expression)#查询数据框的列数 [1] 3
接下来,会介绍数据的外部导入,之所以在这里介绍,是因为导入的数据会以数据框的形式存储。
df1 <- read.table(header=T, text=' K value K2 0.766 K3 0.857 K4 0.811 K5 0.711 K6 0.614 ') > class(df1) [1] "data.frame"
再如,我们导入一个数值数据,最后将它转换为矩阵。
df2 <- read.table(header=T, text='
Sample1 Sample2
0.453 0.766
0.370 0.857
0.199 0.811
0.888 0.711
0.341 0.614
')rownames(df2)<-c("probe1","probe2","probe3","probe4","probe5")#指定其行名 df2
Sample1 Sample2
probe1 0.453 0.766
probe2 0.370 0.857
probe3 0.199 0.811
probe4 0.888 0.711
probe5 0.341 0.614
class(df2) [1] "data.frame"
df3<-as.matrix(df2)
> df3<-as.matrix(df2)
> df3
Sample1 Sample2
probe1 0.453 0.766
probe2 0.370 0.857
probe3 0.199 0.811
probe4 0.888 0.711
probe5 0.341 0.614
> class(df3) #[1] "matrix"
虽然,直接在命令中输入少量数据看起来很优雅,然而,真实的生物数据的维度普遍较大,使用文件导入的方式较合适。
dat <- read.csv("class_exp1.csv",header= T, row.name= 1)
如果目标文件不在当前目录,可以通过设置当前绝对路径指定。
setwd("E:/R讲解基本/2-练习数据")
dat <- read.csv("class_exp1.csv",header= T, row.name= 1)
#或者直接指定绝对路径
dat <- read.csv("E:/R讲解基本/2-练习数据/class_exp1.csv",header= T, row.name= 1)
小结:在介绍完这些关于常见数据结构的最最基本的内容之后,或许你已经可以磕磕绊绊地进行一些数据分析。然而,更深入的数据分析或许需要更多的练习和技巧,希望大家进一步学习和不断提高。推荐一本参考书《R Cookbook》。它其实就是一本参考手册,从中可找到你感兴趣的内容。很显然,你不需要将此书从头读到尾,只需要找你需要的内容,copy并修改加入到自己的script里。然而,你还是需要大致浏览此书,以帮助你快速找到想要找到的知识。
此外,R FOR DUMMIES也是为新手推荐的一本参考书。虽然,该书还没有中文版出版,但是具备大学英语4级以上的水平的读者相信阅读此书都不会有太大障碍。况且,你学习的是此书涉及的代码,在一定的语境的条件下,对文字的理解会有所帮助。这本书并不追求技巧,而是将读者的水平置于很低的层次,逐渐地提高,是推荐给新手的可选读物。
R绘图快速入门
这里要介绍的是基于ggplot2包快速绘制高品质图像。
什么是ggplot2
ggplot2是用于绘图的R语言扩展包。它将绘图视为一种映射,即从数学空间映射到图形元素空间。例如将不同的数值映射到不同的色彩或透明度。该绘图包的特点在于并不去定义具体的图形(如直方图,散点图),而是定义各种底层组件(如线条、方块)来合成复杂的图形,这使它能以非常简洁的函数构建各类图形,而且默认条件下的绘图品质就能达到出版要求。
与lattice包的比较
ggplot2和lattice都属于高级的格点绘图包,初学R语言的朋友可能会在二者选择上有所疑惑。从各自特点上来看,lattice入门较容易,作图速度较快,图形函数种类较多,比如它可以进行三维绘图,而ggplot2就不能。ggplot2需要一段时间的学习,但当你跨过这个门槛之后,就能体会到它的简洁和优雅,而且ggplot2可以通过底层组件构造前所未有的图形,你所受到的限制只是你的想象力。虽然总体感受是入门慢,但是功能确实强大。这里我推荐学习ggplot2。基本上,你只需要掌握一个命令即可学会画图。画图的画图命令跟搭积木很类似,大大加快了绘图效率。特别推荐《R Graphics Cookbook》。其实你完全不懂ggplot2,将它上面的代码改动一下,完全可以应付大部分的生物信息毕业论文了。
基本概念
图层(Layer):如果你用过photoshop,那么对于图层一定不会陌生。一个图层好比是一张玻璃纸,包含有各种图形元素,你可以分别建立图层然后叠放在一起,组合成图形的最终效果。图层可以允许用户一步步的构建图形,方便单独对图层进行修改、增加统计量、甚至改动数据。
标度(Scale):标度是一种函数,它控制了数学空间到图形元素空间的映射。一组连续数据可以映射到X轴坐标,也可以映射到一组连续的渐变色彩。一组分类数据可以映射成为不同的形状,也可以映射成为不同的大小。
坐标系统(Coordinate):坐标系统控制了图形的坐标轴并影响所有图形元素,最常用的是直角坐标轴,坐标轴可以进行变换以满足不同的需要,如对数坐标。其它可选的还有极坐标轴。
位面(Facet):很多时候需要将数据按某种方法分组,分别进行绘图。位面就是控制分组绘图的方法和排列形式。
ggplot2的安装
在第一次使用ggplot2之前,你需要安装它。
install.packages("ggplot2")
在每次使用ggplot2之前,你需要将它导入到R环境。
library(ggplot2)
ggplot2的例子
接下来,我们将使用R内置的一个数据,演示ggplot2的强大能力,开始发挥你的创造力吧。
data(mtcars)mtcars这套数据是记录汽车性能和部件的关系。这里,我们先看看Drat: Rear axle ratio(后轴比) 和wt: Weight(容量)之间的关系。由于该数据较大,我们先显示前两行,相信你没忘了这些基本的切片操作的命令(O(∩_∩)O~~)。
> mtcars[1:2,] mpg cyl disp hp drat wt qsec vs am gear carb Mazda RX4 21 6 160 110 3.9 2.620 16.46 0 1 4 4 Mazda RX4 Wag 21 6 160 110 3.9 2.875 17.02 0 1 4 4先使用一个最基本的命令,直观地看看效果。
ggplot(mtcars,aes(x=drat,y=wt))+geom_point()
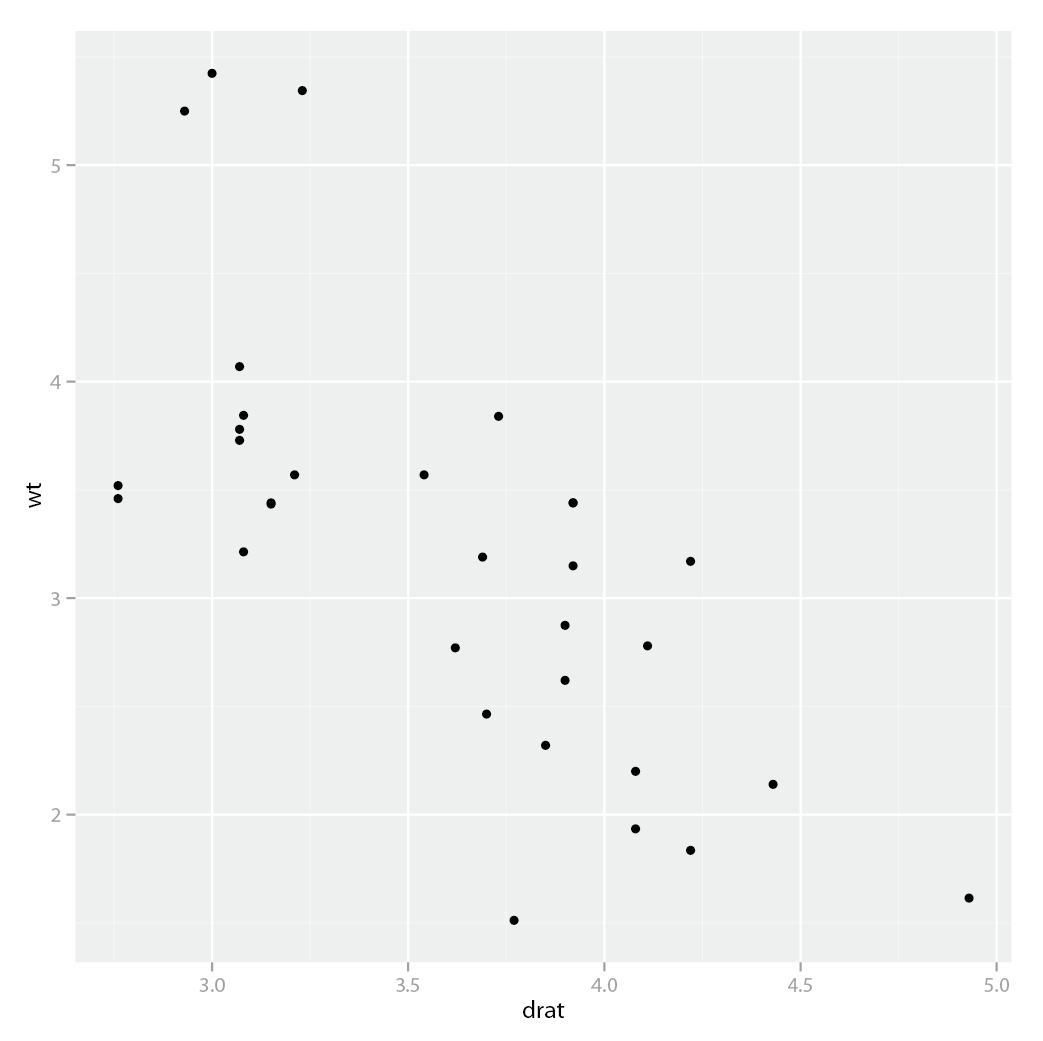
接着,我们仔细审视这条唯一你需要掌握的命令。
ggplot(mtcars,aes(x=drat,y=wt))+geom_point()
| | |
数据框(必需)aes中的每一项将 几何元件
geom被映射到特定的
可视化元件
给ggplot喂的数据需要是一个数据框。
aes项每个点都有自己图像上的属性,比如x坐标,y坐标,点的大小、颜色和形状,这些都叫做aesthetics,即图像上可观测到的属性,通过aes函数来赋值
geom决定了图像的“type”,即几何特征,是用点来描述图像,还是用柱,或者用条形.因此,通过修改geom项,可以修改图的类型。
我们接着改变一下几何元件,看看效果。
ggplot(mtcars,aes(x=drat,y=wt,color=as.character(gear)))+geom_smooth()
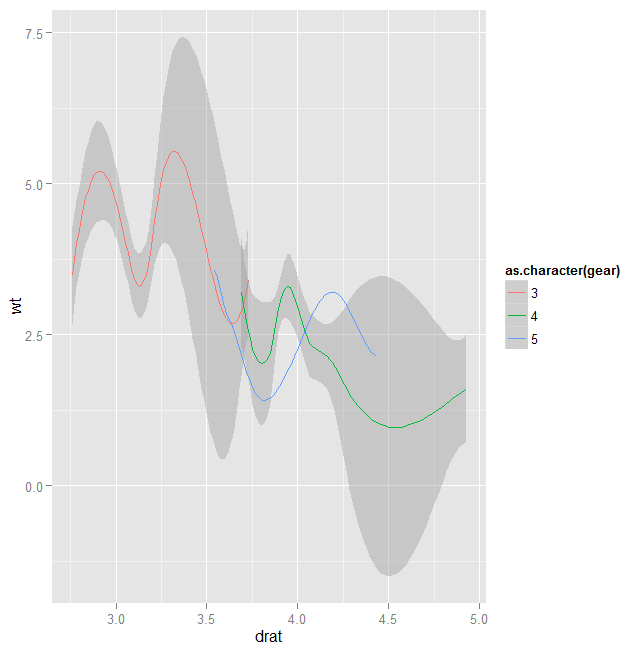
我们看看将gear作为数值的情况的效果(这条命令有些古怪,有的时候不能运行,可以考虑最后运行它)。
ggplot(mtcars,aes(x=drat,y=wt,color=gear))+geom_point()
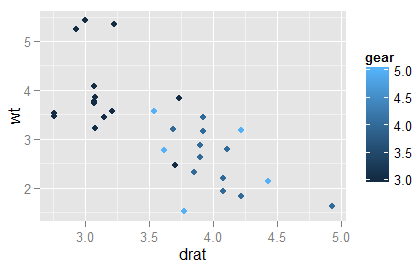
这里,可以看到点的研究随着gear的值得变化而变化,你可以试着把gear强制变为character,再运行一次,比较一下。可以清楚看出这里还是比较适宜用字符型的gear,因为gear只有三个值。如果一个变量是连续范围的,不用强制变为字符串的类型。
我们再做一些变动,比较一下效果。
ggplot(mtcars,aes(x=drat,y=wt))+geom_point()+geom_smooth()
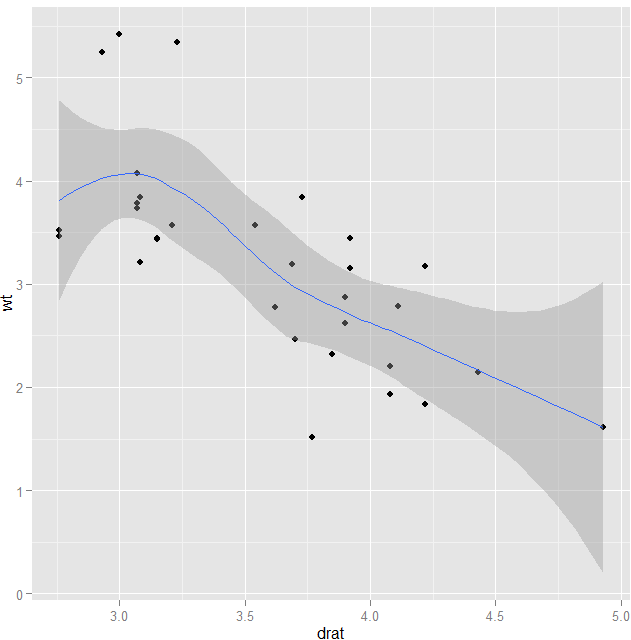
我们发现几何元件其实是可以叠加的。这样不仅可以同时显示散点,也可以显示平滑的曲线图,这种图被用来显示置信区间。
接下来,我们只对一个变量进行绘图。
ggplot(mtcars,aes(x=drat))+geom_density()
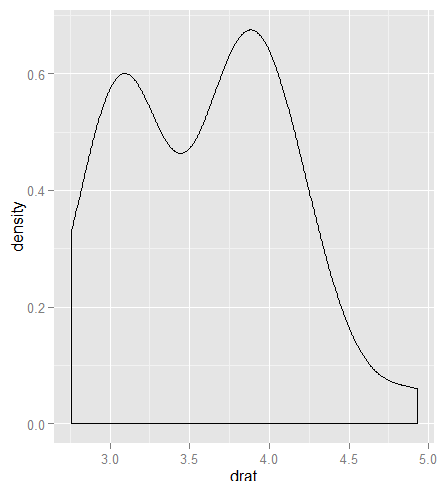
我们发现显示的是drat这个变量的值的分布。
为了考察在另一个变量gear不同(3,4,5)的情况下,drat的分布,我们进一步加了点东西。
ggplot(mtcars,aes(x=drat))+geom_density()+facet_grid(~gear)
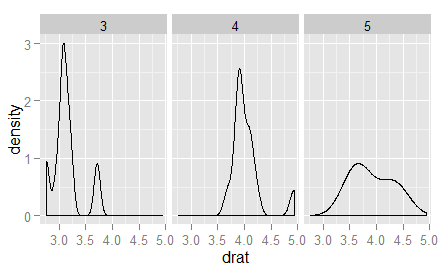
facet_grid方法的确很神奇,可以按照传递给它的变量的值分成不同的情况。需要注意的是gear前面的~。
最后,照例给大家推荐一本ggplots的工具书:R Graphics Cookbook。这本书大部分的例子都是用ggplot2实现的,可见ggplot2的强大功能。
要想学好任何编程语言,都离不开这几个字:多练,兴趣,折腾,交流。

