
- 1RabbitMQ如何保证消息的顺序性
- 2build 打包报错:TypeError: Cannot read property ‘get‘ of undefined_typeerror: cannot read property 'get' of undefined
- 3XXE(XML外部实体注入)详解_xml external entity injection
- 4数据库索引的类型_数据库索引有哪些
- 5目标检测——道路检测数据集_目标检测道路塌方检测
- 6九月十月百度人搜,阿里巴巴,腾讯华为小米搜狗笔试面试八十题(2012年度笔试面试八十题)_zhutouaabb
- 72024/4/25:Hybrid Policy Optimization from Imperfect Demonstrations_neurips2024
- 8【论文阅读】14-Accurate Multiple View 3D Reconstruction Using Patch-Based Stereo for Large-Scale Scenes
- 9《单片机原理与应用》课程课程实验报告实验三 定时计数+中断综合控制实验_单片机亮灯实验报告
- 10USART HMI串口屏+单片机通讯上手体验
开源关系型数据库架构
赞
踩
前言
我们把主要的开源关系型数据库分为三类,来分别了解一下它们的架构和设计,并了解一下它们各自的优缺点。
- OLTP,在线事务处理,是传统的关系型数据库的主要应用场景
- OLAP,在线分析处理,是当今大数据,数据仓库使用的主要的数据库技术
- SQL Query Engine,随着存算分离技术的发展,SQL查询引擎也占据了开源关系型数据库的重要的位置
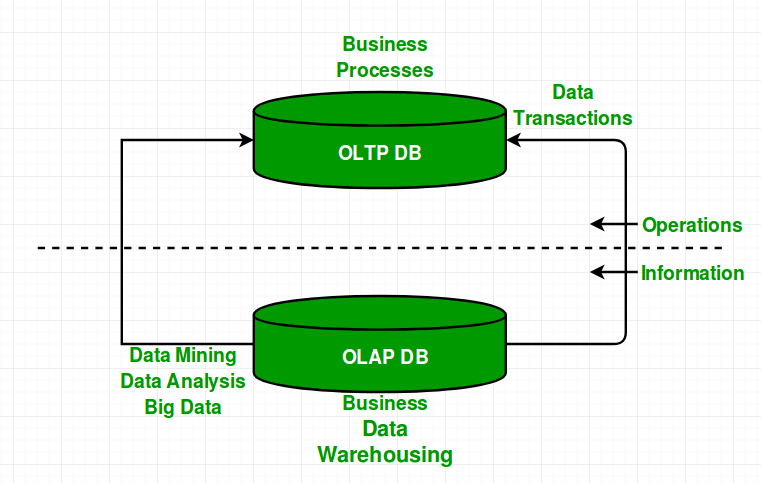
OLTP
OLTP是在线事务处理,在3层体系结构中支持面向事务的应用程序。 OLTP管理组织的日常事务。主要目标是数据处理而不是数据分析。OLTP的主要特点是:
- 大量的短时间交易请求和处理
- 对信息进行增删改查的操作,常常需要查询明细信息。
- 必须保证事务和数据的一致性
- 通常要支持大量的并发用户
下面我们就来看看主要的开源OLTP的数据库架构。
MySQL
MySQL是最为流行的开源关系数据库
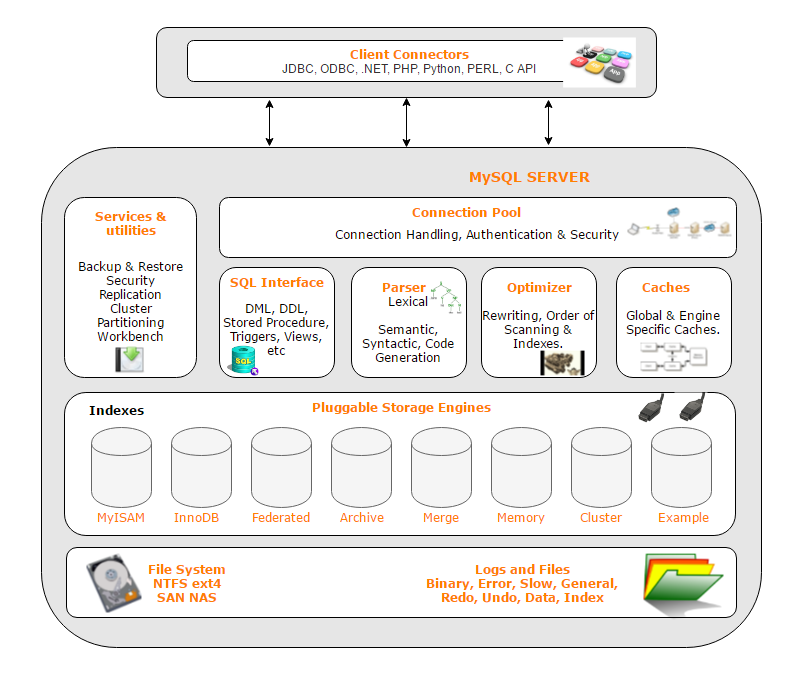
MySQL采用了经典的客户端服务器C/S架构,服务器端的主要组件包含:
- 连接池,处理连接和认证授权
- SQL接口,语法解析,优化器,缓存
- 可插拔的存储引擎,支持InnoDB、MyISAM、Memory等多个存储引擎。
- 物理文件,包含redolog、undolog、binlog、errorlog、querylog、slowlog、data、index等
- 服务工具,备份,安全等
MySQL架构设计中的一些关键技术包括:
- 利用缓存来避免提高热数据的查询性能
- 利用优化器优化查询性能
- 例如redo log/bin log避免频繁写数据库带来的性能压力。同时在出错的时候可以通过日志来恢复
- 通过两阶段提交来保证两份日志的一致性
MySQL支持事务,事务是一组原子性的SQL查询,或者说一个独立的工作单元。事务的ACID:
- 原子性(atomicty):一个不可分割的最小工作单元。
- 一致性(consistency):数据库总是从一个一致性状态转换到另一个一致性的状态。
- 隔离性(isolation):一个事务所做的修改在最终提交以前,对其他事务是不可见的。
- 持久性(durability):事务提交后,其所做的修改会永久保存到数据库中。(没有100%的持久性持久性保证策略)
MySQL的大多数存储引擎通过数据快照的形式支持了多版本的并发控制。
优点:
- 性能卓越服务稳定,很少出现异常宕机
- 开放源代码且无版权制约,自主性强。
- 历史悠久、社区及用户非常活跃,遇到问题,可以很快获取到帮助。
- 支持多种操作系统,提供多种 API 接口,支持多种开发语言。
- 体积小、速度快、易于维护,安装及维护成本低。
- MySql的核心程序采用完全的多线程编程。线程是轻量级的进程,它可以灵活地为用户提供服务,而不过多的系统资源。用多线程和C语言实现的MySql能很容易充分利用CPU。
- 拥有一个非常快速而且稳定的基于线程的内存分配系统,可以持续使用面不必担心其稳定性。
缺点:
- MySQL的设计是用来支持事务的OLTP数据库,本身缺乏支持水平扩展的能力。对于水平扩展更多是通过分库,分表加上客户端的处理来支持的。
- 不支持热备份。
- 安全管理系统比较简单。
- 不允许调试存储过程,开发和维护存储过程很难。
开源的MySQL集群软件比较少,例如Myat。而官方的MySQL Cluster不是开源的,它是将线性可伸缩性和高可用性结合在一起的分布式数据库。它提供了跨分区和分布式数据集的事务内一致性的内存实时访问。
因为MySQL被“邪恶”的Oracle收购,社区另开门户,以MySQL的代码创建分支,开发了MariaDB。MariaDB Server是最受欢迎的开源关系数据库之一。它由MySQL的原始开发人员制作,并保证保持开源。它是大多数云产品的一部分,并且是大多数Linux发行版中的默认产品。书籍推荐:



PostgreSQL
PostgreSQL是一个功能强大的开源对象关系数据库系统,经过30多年的积极开发,在可靠性,功能强大和性能方面赢得了极高的声誉。
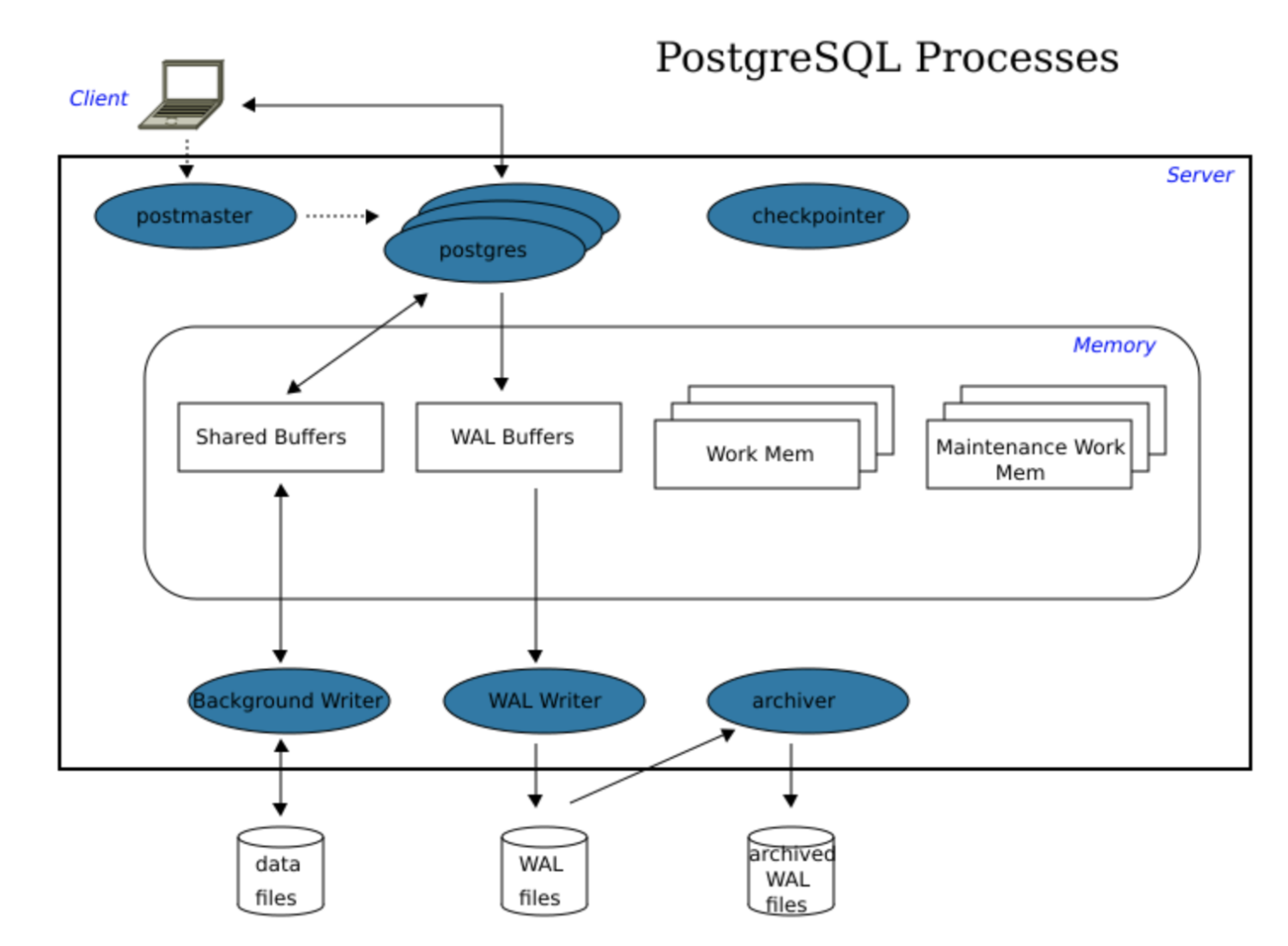
PostgreSQL和MySQL一样使用客户端/服务器模型。PostgreSQL会话由以下协作过程(程序)组成:
- 服务器进程管理数据库文件,接受来自客户端应用程序的数据库连接,并代表客户端执行数据库操作。PostgreSQL服务器可以处理来自客户端的多个并发连接。为此,它为每个连接启动(“分叉”)新过程。从那时起,客户端和新服务器进程进行通信,而无需原始postgres进程进行干预。因此,主服务器进程始终在运行,等待客户端连接,而客户端和关联的服务器进程来来往往。
- 想要执行数据库操作的客户端(前端)应用程序。客户端应用程序的性质可能非常多样:客户端可以是面向文本的工具,图形应用程序,访问数据库以显示网页的Web服务器或专用的数据库维护工具。
PostgreSQL的物理结构非常简单。它由共享内存以及一些后台进程和数据文件组成。
共享内存
共享内存是指为数据库缓存和事务日志缓存保留的内存。共享内存中最重要的元素是共享缓冲区和WAL缓冲区
共享缓冲区
共享缓冲区的目的是使DISK IO最小化。为此,必须满足以下原则
- 需要快速访问非常大的缓冲区(数十,数百GB)。
- 当许多用户同时访问争用时,应将争用最小化。
- 常用块必须在缓冲区中保留尽可能长的时间
WAL缓冲区
-
- WAL缓冲区是一个临时将更改存储到数据库的缓冲区。将WAL缓冲区中存储的内容在预定的时间点写入WAL文件。从备份和恢复的角度来看,WAL缓冲区和WAL文件非常重要。
PostgreSQL有四种进程类型。
- 守护程序进程
守护进程是启动PostgreSQL时启动的第一个进程。在启动时,执行恢复,初始化共享内存并运行后台进程。当客户端进程发出连接请求时,它还会创建一个后端进程。- 后台进程
Logger将错误消息写入日志文件。
Checkpointer发生检查点时,脏缓冲区将被写入文件。
Writer定期将脏缓冲区写入文件。
WAL writer将WAL缓冲区写入WAL文件。
Autovacuum launcher将分叉自动真空工作程序.autovacuum守护程序负责按需对桌面进行真空操作
Archiver在Archive.log模式下,将WAL文件复制到指定目录。
统计收集器统计数据库使用统计信息。- 后端进程进行数据处理工作。后端进程执行用户进程的查询请求,然后发送结果。执行查询需要一些内存结构,称为本地内存。
- 客户进程
客户端进程是指为每个后端用户连接分配的后台进程。通常,守护进程将派生一个专门为用户连接服务的子进程。
PostgreSQL希望做到单栈全功能数据库,包括:
- OLTP:事务处理是PostgreSQL的本行
- OLAP:citus分布式插件,ANSI SQL兼容,窗口函数,CTE,CUBE等高级分析功能,任意语言写UDF流处理:PipelineDB扩展,Notify-Listen,物化视图,规则系统,灵活的存储过程与函数编写
- 时序数据:timescaledb时序数据库插件,分区表,BRIN索引
- 空间数据:PostGIS扩展(杀手锏),内建的几何类型支持,GiST索引。
- 搜索索引:全文搜索索引足以应对简单场景;丰富的索引类型,支持函数索引,条件索引
- NoSQL:JSON,JSONB,XML,HStore原生支持,至NoSQL数据库的外部数据包装器
- 数据仓库:能平滑迁移至同属Pg生态的GreenPlum,DeepGreen,HAWK等,使用FDW进行ETL
- 图数据:递归查询
优点:
- 支持更丰富的数据类型的存储,包括Array,JSON等。支持R-Tree索引的树状结构。
- 丰富的SQL编程能力,支持递归,有非常丰富的统计函数和统计语法支持
- 外部数据源支持,可以多种外部数据源 (包括 Mysql, Oracle, CSV, hadoop …) 当成自己数据库中的表来查询
- 无限长 TEXT 类型,支持全文搜索和正则搜索
- 支持图数据格式的存储
- 丰富的索引类型支持,支持 B-树、哈希、R-树和 Gist 索引
- 较好的稳定性和平稳的性能
- 可以做到同步,异步,半同步复制,以及基于日志逻辑复制,可以实现表级别的订阅和发布。
- 支持各种分布式集群部署
PostgreSQL有丰富的开源cluster软件支持。plproxy 可以支持语句级的镜像或分片,slony 可以进行字段级的同步设置,standby 可以构建WAL文件级或流式的读写分离集群,同步频率和集群策略调整方便,操作非常简单。Postgres-X2是一个开放源代码项目,可提供水平可伸缩性,包括写可伸缩性,同步多主机和透明PostgreSQL接口。它是紧密耦合的数据库组件的集合,可以安装在多个硬件或虚拟机中。
缺点:
- PostgreSQL的 MVCC 事务语义依赖于能够比较事务 ID(XID)数字:如果一个新版本的插入 XID 大于当前事务的 XID,它就是"属于未来的"并且不应该对当前事务可见。XID的问题可能会导致长时间停机的故障。
- Failover故障可能会丢失数据,如果运行中的主服务器突然出现故障,那么运行中的流复制设置几乎肯定会丢失已提交的数据。
- 物理复制有利有弊,低效率的复制会传播失败。使用物理复制,大型索引构建会创建大量WAL条目,从而很容易成为流复制的瓶颈。
- MVCC垃圾回收频发。与大多数主流数据库一样,PostgreSQL使用多版本并发控制(MVCC)来实现并发事务。但是,其特定的实现通常会给垃圾行的数据版本及其清理(VACUUM)带来操作上的麻烦
- 每次连接处理=规模化痛苦,PostgreSQL为每个连接生成一个进程,而其他大多数数据库都使用更有效的连接并发模型。由于存在一个相对较低的阈值,在该阈值上添加更多的连接会降低性能(约2个内核),最终会导致性能下降
和MySQL相比较,PostgreSQL从底层设计原理不尽相同,在数据量小的时候,数据库更趋于轻量化,MySQL会更适合。但是一旦数据量大的时候,应用场景复杂,或者需要分析的场合,PostgreSQL会是更好的选择。书籍推荐:



CockroachDB
CockroachDB是为现代云应用程序设计的分布式数据库。它与PostgreSQL兼容,并由一个RocksDB或专门创建的派生工具Pebble的键值存储提供支持。CockroachDB 思路源自 Google 的全球性分布式数据库 Spanner。CockroachDB 既具有 NoSQL 对海量数据的存储管理能力,又保持了传统数据库支持的 ACID 和 SQL 等,还支持跨地域、去中心、高并发、多副本强一致和高可用等特性。支持 OLTP 场景,同时支持轻量级 OLAP 场景。CockroachDB主要设计目标是可扩展,强一致和高可用 。CockroachDB旨在无人为干预情况下,以极短的中断时间容忍磁盘、主机、机架甚至整个数据中心的故障 。 CockroachDB采用完全去中心化架构,集群中各个节点的地位完全对等,同时所有功能封装在一个二进制文件中,可以做到尽量不依赖配置文件直接部署
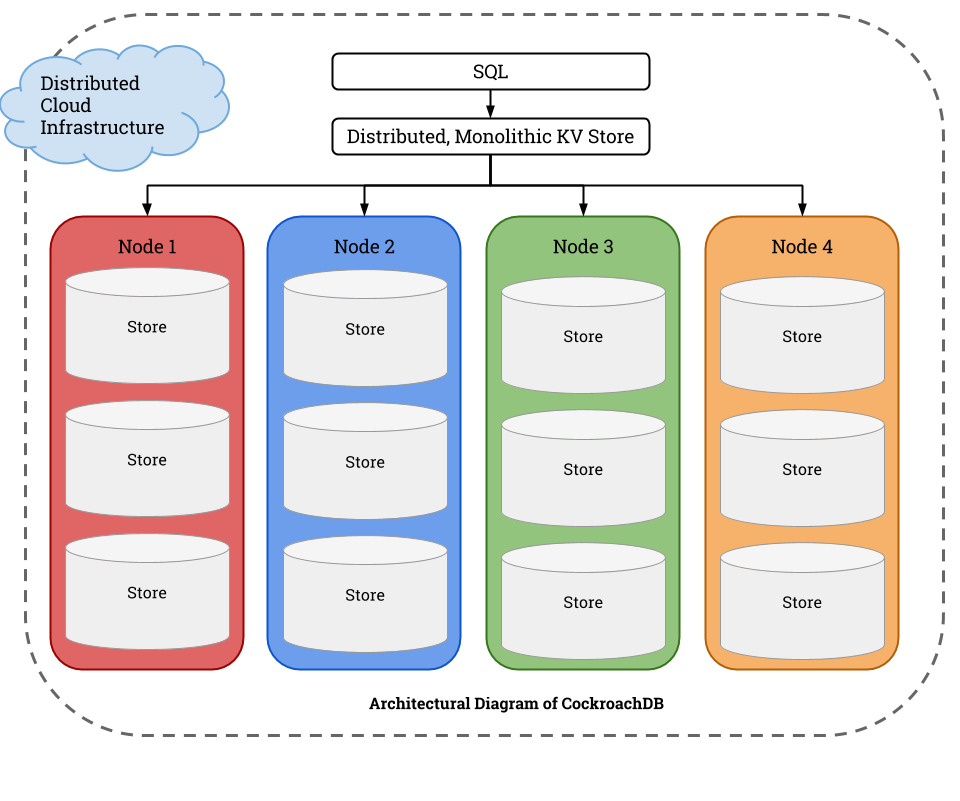
Node代表一个CockroachDB进程实例,一般情况下一台物理机部署一个CockroachDB实例,一个CockroachDB实例可以配置多个Store, 单个Store与RocksDB实例一一对应,一般情况下一个Store对应一块物理磁盘。CockroachDB按照范围进行数据切分,最小数据切分单元是Range。Range默认的配置大小是64M, 以3副本的方式分布在各个节点上,副本间通过Raft协议进行数据同步。CockroachDB底层是RocksDB的KV,在此之上,利用Raft协议来实现分布式的多副本的一致性。节点故障无丢失数据风险。CockroachDB架构上去中心化,没有单点故障:架构不存在集中式模块,单节点故障不影响集群整体的可用性。基于Raft协议,只要半数以上副本存活,则服务可用;当节点异常,数据副本数量少于指定阈值时,自动补齐副本;基于HLC分布式时钟同步算法,任意节点皆可充当事务管理节点,无中心事务管理器。CockroachDB使用Gossip协议实现节点状态管理,理论上单集群支持10K节点规模。CockroachDB兼容PostgreSQL协议,对于报文的封装和解析完全按照PostgreSQL的方式进行,所以用户可以直接使用PostgreSQL的客户端访问CockroachDB。
优点:
- 支持标准SQL,兼容PostgreSQL
- 扩展能力强,高并发,支持弹性扩容和高可用。单集群支持10K节点的规模, 能够存储的数据最大为4EB
- 支持分布式事务,多副本强一致。支持多区域部署
- CRDB所有功能都在一个编译好的二进制中, 不需要依赖其它组件, 运维部署都非常方便.
缺点:
- 相对比较新,社区和生态还不成熟
- 修改了代码授权协议,不再是开源友好。CockroachDB 的核心代码授权协议将采用 BSL。用户可以将 CockroachDB 扩展到任意数量的节点,可以随意使用 CockroachDB,也可以将其嵌入到应用程序中(无论是将这些应用程序发送给客户,还是将其作为服务运行),甚至可以在内部将 CockroachDB 作为服务运行。唯一不能做的事情是,在没有购买许可证的情况下,提供商业版 CockroachDB 作为服务。
TiDB
TiDB是支持MySQL语法的开源分布式混合事务/分析处理(HTAP)数据库。TiDB可以提供水平可扩展性、强一致性和高可用性。它主要由PingCAP公司开发和支持,并在Apache 2.0下授权。TiDB从Google的Spanner和F1论文中汲取了最初的设计灵感。TiDB是国产数据库的翘楚,所属公司 PingCAP于11月宣布完成D轮2.7亿美元融资,创造了全球数据库历史新的里程碑。到目前为止,PingCAP 总计已融资 3.416 亿美元,上一次的 5000 万美元 C 轮融资于2018年9月完成。截止到2020年10月,TiDB项目在GitHub上已总计获得超过25000颗星,近1200位开源代码贡献者,参与企业包括美团、知乎、伴鱼、丰巢、小米、微众银行、UCloud、Zoom、Samsung、Square、PayPay 等行业企业。HTAP 是 Hybrid Transactional / Analytical Processing 的缩写。这个词汇在 2014 年由 Gartner 提出。传统意义上,数据库往往专为交易或者分析场景设计,因而数据平台往往需要被切分为 TP 和 AP 两个部分,而数据需要从交易库复制到分析型数据库以便快速响应分析查询。而新型的 HTAP 数据库则可以同时承担交易和分析两种智能,这大大简化了数据平台的建设,也能让用户使用更新鲜的数据进行分析。作为一款优秀的 HTAP 数据数据库,TiDB 除了优异的交易处理能力,也具备了良好的分析能力。TiDB在整体架构基本是参考 Google Spanner 和 F1 的设计,上分两层为 TiDB 和 TiKV 。 TiDB 对应的是 Google F1, 是一层无状态的 SQL Layer ,兼容绝大多数 MySQL 语法,对外暴露 MySQL 网络协议,负责解析用户的 SQL 语句,生成分布式的 Query Plan,翻译成底层 Key Value 操作发送给 TiKV , TiKV 是真正的存储数据的地方,对应的是 Google Spanner ,是一个分布式 Key Value 数据库,支持弹性水平扩展,自动的灾难恢复和故障转移(高可用),以及 ACID 跨行事务。值得一提的是 TiKV 并不像 HBase 或者 BigTable 那样依赖底层的分布式文件系统,在性能和灵活性上能更好,这个对于在线业务来说是非常重要。
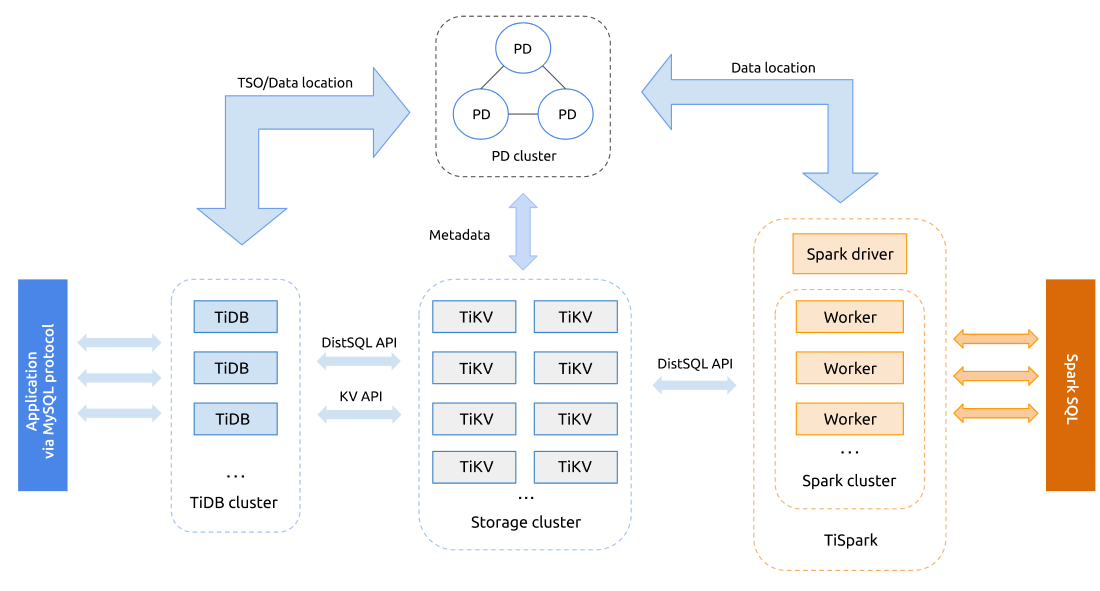
- TiDB Server:SQL 层,对外暴露 MySQL 协议的连接 endpoint,负责接受客户端的连接,执行 SQL 解析和优化,最终生成分布式执行计划。TiDB 层本身是无状态的,实践中可以启动多个 TiDB 实例,通过负载均衡组件(如 LVS、HAProxy 或 F5)对外提供统一的接入地址,客户端的连接可以均匀地分摊在多个 TiDB 实例上以达到负载均衡的效果。TiDB Server 本身并不存储数据,只是解析 SQL,将实际的数据读取请求转发给底层的存储节点 TiKV(或 TiFlash)。
- PD (Placement Driver) Server:整个 TiDB 集群的元信息管理模块,负责存储每个 TiKV 节点实时的数据分布情况和集群的整体拓扑结构,提供 TiDB Dashboard 管控界面,并为分布式事务分配事务 ID。PD 不仅存储元信息,同时还会根据 TiKV 节点实时上报的数据分布状态,下发数据调度命令给具体的 TiKV 节点,可以说是整个集群的“大脑”。此外,PD 本身也是由至少 3 个节点构成,拥有高可用的能力。建议部署奇数个 PD 节点。
- 存储节点
- TiKV Server:负责存储数据,从外部看 TiKV 是一个分布式的提供事务的 Key-Value 存储引擎。存储数据的基本单位是 Region,每个 Region 负责存储一个 Key Range(从 StartKey 到 EndKey 的左闭右开区间)的数据,每个 TiKV 节点会负责多个 Region。TiKV 的 API 在 KV 键值对层面提供对分布式事务的原生支持,默认提供了 SI (Snapshot Isolation) 的隔离级别,这也是 TiDB 在 SQL 层面支持分布式事务的核心。TiDB 的 SQL 层做完 SQL 解析后,会将 SQL 的执行计划转换为对 TiKV API 的实际调用。所以,数据都存储在 TiKV 中。另外,TiKV 中的数据都会自动维护多副本(默认为三副本),天然支持高可用和自动故障转移。
- TiFlash:TiFlash 是一类特殊的存储节点。和普通 TiKV 节点不一样的是,在 TiFlash 内部,数据是以列式的形式进行存储,主要的功能是为分析型的场景加速。
和CockroachDB采用了类似的架构设计,TiKV实际上也是基于RocksDB,同样采用了Raft协议来实现分布式的一致性。值得一提的是TiKV用Rust语言开发,是开源社区的网红明星。
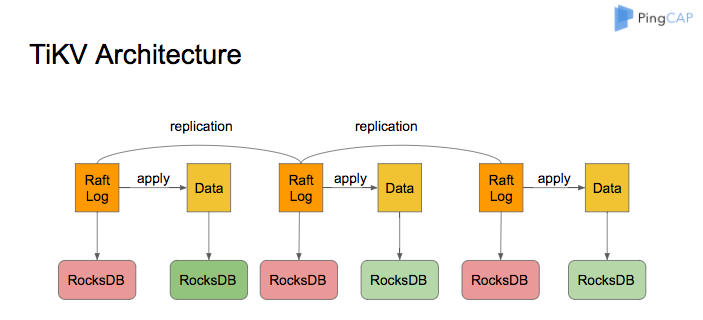
优点:
- 纯分布式架构,拥有良好的扩展性,支持弹性的扩缩容
- 支持 SQL,对外暴露 MySQL 的网络协议,并兼容大多数 MySQL 的语法,在大多数场景下可以直接替换 MySQL
- 默认支持高可用,在少数副本失效的情况下,数据库本身能够自动进行数据修复和故障转移,对业务透明
- 支持 ACID 事务,对于一些有强一致需求的场景友好,例如:银行转账
- 具有丰富的工具链生态,覆盖数据迁移、同步、备份等多种场景
- 智能的行列混合模式,TiDB 可经由优化器自主选择行列。这套选择的逻辑与选择索引类似:优化器根据统计信息估算读取数据的规模,并对比选择列存与行存访问开销,做出最优选择。
缺点:
- 虽然兼容MySQL,但是不支持存储过程,触发器,自定义函数,窗口功能有限。
- 不适用数据量小的场景,专门为大数据量设计。
SQLite
SQLite是一种C语言库,可实现小型,快速,自包含,高可靠性,功能齐全的SQL数据库引擎。 SQLite是世界上最常用的进程内,嵌入式数据库引擎。 SQLite内置在所有手机和大多数计算机中,并捆绑在人们每天使用的无数其他应用程序中。SQLite因为其特点,无法应用与海量数据的场景。
OpenGauss
openGauss 是华为开源关系型数据库管理系统,采用木兰宽松许可证 v2 发行。openGauss 内核源自 PostgreSQL,深度融合华为在数据库领域多年的经验,结合企业级场景需求,持续构建竞争力特性。同时 openGauss 也是一个开源的数据库平台,鼓励社区贡献、合作。OpenGauss因为起步时间短,社区还不成熟,这里就不做详细介绍了。
总结
MySQL是最为流行的开源OLTP数据库,有非常强大的生态。PostgeSQL支持丰富的功能和扩展性,能应用与各种不同的场景中。CockroachDB和TiDB同样借鉴了google spanner的架构,底层使用RocksDB作为KV存储,使用raft协议保证分布式的一致性来实现高可用和高扩展,是新一代开源OLTP的代表。虽然PostgreSQL和TiDB都号称能兼顾OLTP和OLAP的场景,但是我还是把它们都归于OLTP的分类。他们的核心设计都更适合TP的场景。SQLite是小型的关系型数据库,可用于进程内的部署。
OLAP
OLAP(Online Analytical Processing)联机分析处理,是指一类软件工具,可为业务决策提供数据分析。 OLAP系统允许用户一次分析来自多个数据库系统的数据库信息。主要目标是数据分析而不是数据处理。OLAP的主要特点是:
- 数据量通常比较大
- 大部分操作是Select
- 数据一致性不是非常的关键
- 以读操作为主,很少更新
- 并发查询的量通常不会很大
下面我们就来看看主要的开源OLAP的数据库架构。
Apache Hive
Hive是基于Hadoop的用于查询和管理大型分布式数据集的数据仓库软件。Apache Hive数据仓库软件有助于使用SQL读取,写入和管理驻留在分布式存储中的大型数据集。可以将结构投影到已经存储的数据上。提供了命令行工具和JDBC驱动程序以将用户连接到Hive。Hadoop的出现,通过HDFS和Map/Reduce解决了海量数据的存储和计算问题,然而Map/Reduce并不是一个开发者友好的计算和编程接口。Hive的出现解决了这个问题,基于Hadoop,Hive提供一个用户友好的SQL接口,对海量数据进行操作。
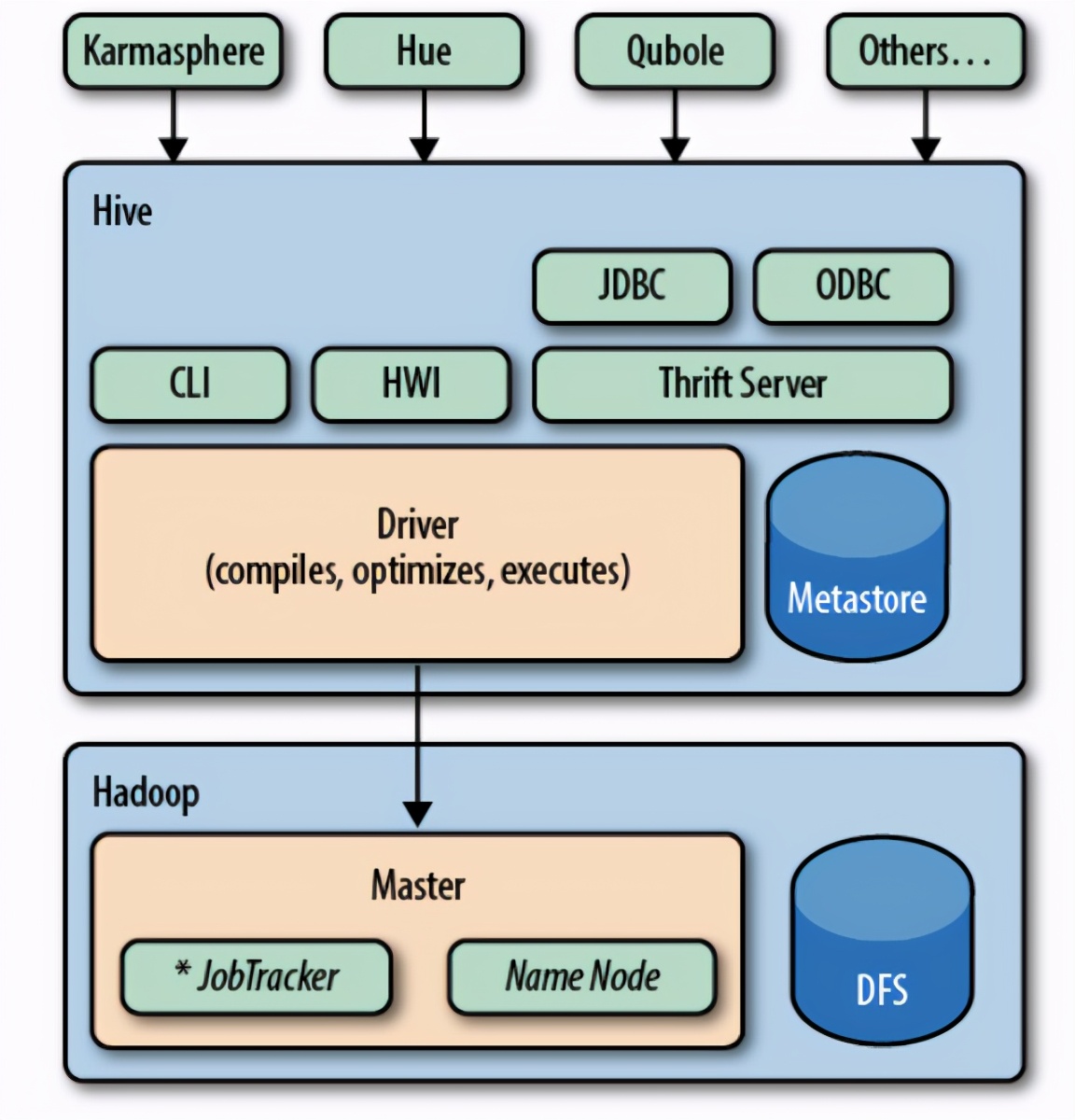
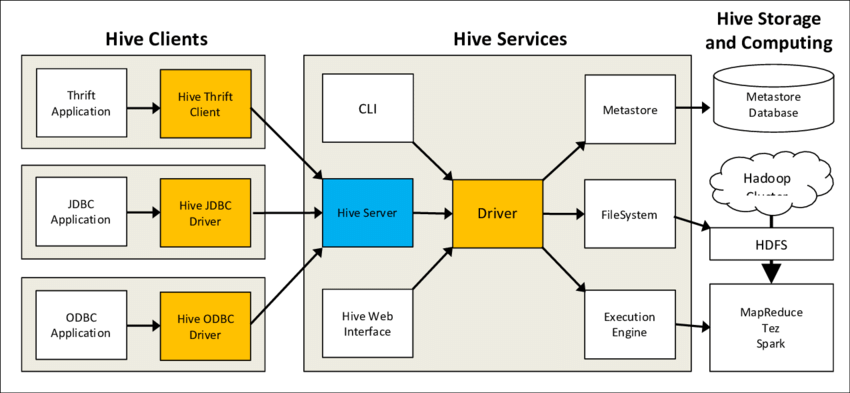
从架构上来看,Hive包含:
- 客户端,Hue,Qubole,CLI等
- 通过Thrift Server,提供JDBC/ODBC连接
- Driver,所有命令和查询都转到驱动程序,该驱动程序通常使用MapReduce作业来编译输入,优化所需的计算并执行所需的步骤。
- Metastore是一个单独的关系数据库(通常是一个MySQL实例),保存Hive的表模式和其他系统元数据
- 底层是Hadoop的文件系统和计算节点
Hive不提供的某系数据库功能,例如行级更新,快速的查询响应时间和事务,这时候你可能会需要HBase,HBase是一种分布式且可扩展的数据存储,它支持行级更新,快速查询和行级事务(但不支持多行事务)。 HBase是一个开源的非关系型分布式数据库,它参考了谷歌的BigTable建模,实现的编程语言为Java。它是Apache软件基金会的Hadoop项目的一部分,运行于HDFS文件系统之上,为 Hadoop 提供类似于BigTable 规模的服务。因此,它可以对稀疏文件提供极高的容错率。Hive是查询引擎,而HBase是专门用于非结构化数据的数据存储。Apache Hive主要用于批处理(即OLAP),但HBase广泛用于事务处理,其中查询的响应时间不是高度交互的,即OLTP。与Hive不同,HBase中的操作在数据库上实时运行,而不是转换为mapreduce作业。HBase用于实时查询,Hive用于分析查询。Hive采用了Schema On Read的模式,当通过加载外部数据,写入查询的输出,执行UPDATE语句等将数据写入传统数据库时,数据库可以完全控制存储。该数据库是“守门人”。数据库可以在写入数据时强制执行模式。这被称为Schema on write。Hive无法控制基础存储。有多种方法可以创建,修改甚至破坏Hive将要查询的数据。因此,Hive只能在读取时强制执行查询。这称为读取模式Schema on read。如果模式与文件内容不匹配怎么办? Hive尽其所能读取数据。如果记录中没有足够的字段来匹配模式,那么将获得很多空值。如果某些字段是数字,并且Hive遇到非数字字符串,它将为这些字段返回null。最重要的是,Hive会尽力从所有错误中恢复。Hive除了支持Map/Reduce作为计算引擎,也可以使用SparkSQL作为计算引擎。当然SparkSQL也可以脱离Hive,使用其它数据存储来支持SQL查询。这是一种典型的存算分离的数据处理技术。
优点:
- Hive在海量数据上支持了OLAP场景下的分析查询
- Hive支持水平扩展,高可靠,高容错
- Hive支持Map/Recude或者Spark作为计算引擎
缺点
- 效率不高,延迟较高,默认的M/R执行引擎启动有延迟
- 不支持物理化视图,不能在视图上更新、插入、删除
- 不适用OLTP,暂不支持列级别添加、更新、删除
- 暂不支持存储过程,当前版本不支持存储过程
- HiveQL的表达能力有限
书籍推荐:

Greenplum
建立在PostgreSQL上的分析数据库平台。全名是Pivotal Greenplum数据库。一个用于分析,机器学习和AI的开源大规模并行数据平台
- MPP体系结构,PB级加载,Greenplum的所有主要贡献都是Greenplum数据库项目的一部分,并且共享相同的数据库核心,包括MPP体系结构,分析接口和安全功能。
- 联合数据访问,使用Greenplum优化器和查询处理引擎查询外部数据源。包括Hadoop,云存储,ORC,AVRO,Parquet和其他Polyglot数据存储。
- 多态数据存储,完全控制表和分区存储,执行和压缩的配置。根据访问数据的方式设计表。用户可以选择任何表或分区的行或列导向存储和处理。
- 集成的数据库内分析,使用Apache MADlib处理数据科学,从实验到大规模部署,Apache MADlib是Postgres系列数据库的集群内机器学习功能的开源库。具有Greenplum的MADlib提供了多节点,多GPU和深度学习功能。
- 查询优化方面的创新,Greenplum数据库中提供的查询优化器是业界第一个针对大数据工作负载而设计的基于开源成本的查询优化器。它可以将交互式和批处理模式分析扩展到PB级的大型数据集,而不会降低查询性能和吞吐量。
Greenplum数据库是基于PostgreSQL开源技术的。它本质上是多个PostgreSQL面向磁盘的数据库实例一起工作形成的一个紧密结合的数据库管理系统(DBMS)。Greenplum数据库和PostgreSQL的主要区别在于:
- 在基于Postgres查询规划器的常规查询规划器之外,可以利用GPORCA进行查询规划。
- Greenplum数据库可以使用追加优化的存储。
- Greenplum数据库可以选用列式存储,数据在逻辑上还是组织成一个表,但其中的行和列在物理上是存储在一种面向列的格式中,而不是存储成行。列式存储只能和追加优化表一起使用。列式存储是可压缩的。当用户只需要返回感兴趣的列时,列式存储可以提供更好的性能。所有的压缩算法都可以用在行式或者列式存储的表上,但是行程编码(RLE)压缩只能用于列式存储的表。Greenplum数据库在所有使用列式存储的追加优化表上都提供了压缩。
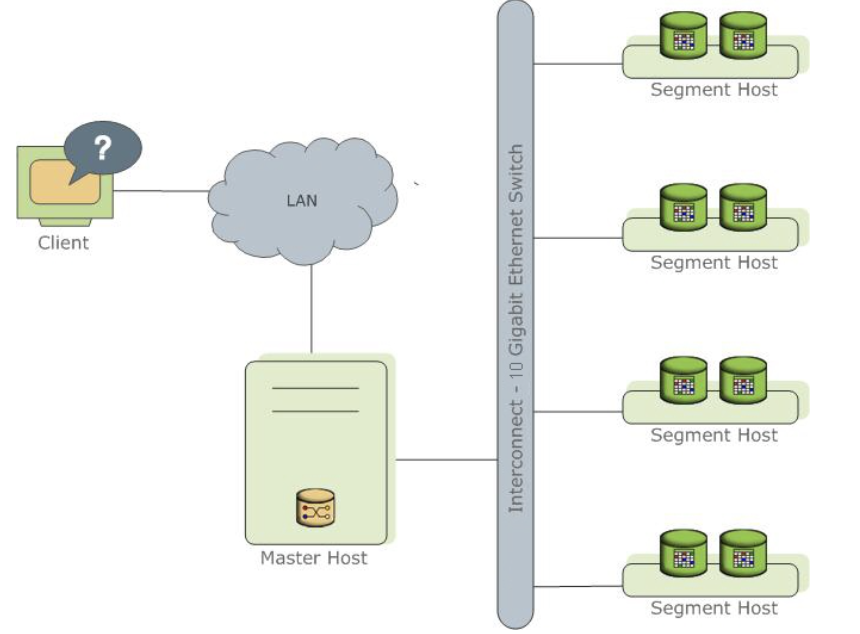
Greenplum的最小并行单元不是节点层级,而是在实例层级,每个实例都有自己的postgresql目录结构,都有各自的一套Postgresql数据库守护进程(甚至可以通过UT模式进行单个实例的访问)。正因为如此,甚至一个运行在单节点上的GreenplumDB也是一个小型的并行计算架构,一般一个节点配置6~8个实例,相当于在一个节点上有6~8个Postgresql数据库同时并行工作,优势在于可以充分利用到每个节点的所有CPU和IO 能力。
优点:
- 采用无共享(no shareing)的MPP架构;具有良好的线性扩展能力,具有高效的并行运算、并行存储特性。
- 拥有独特的高效的ORCA优化器。
- 兼容SQL语法。适合用于高效PB数据量级的存储、处理和实时分析能力。
- 由于内核是基于PostgreSQL数据库;也支持涵盖OLTP型业务混合负载。
- 同时数据节点和主节点都有自己备份节点。提供数据库的高可用性。
缺点:
- 并发能力很有限(受物理Master限制),性能随并发量增加而快速下降。Master主控节点性能瓶颈,并发性能低,实际应用中无法支持超过30个并发。
- 主从双层架构,并非真正的扁平架构,存在性能瓶颈和SPOF单点故障。集群规模受物理Master限制,实际应用中很难超过20个物理节点。
- 无法支持数据压缩态下的DML操作,不易于数据的维护和更新。
- 主备双Master节点容灾方案,在切换事物日志到备用master时,如有数据操作,容易导致数据损坏、insert数据丢失、delete未删除成功等。
- 单个节点上的数据库没有并行和大内存使用能力,必须通过部署多个实列(segment servers)来充分利用系统资源,造成使用和部署很复杂。
Clickhouse
俄罗斯搜索巨头Yandex开发的面向列存的关系型数据库。ClickHouse是过去两年中OLAP领域中最热门的,并于2016年开源。典型的用户包括著名的公司,例如字节,新浪和腾讯。ClickHouse是基于MPP架构的分布式ROLAP(关系OLAP)分析引擎。每个节点都有同等的责任,并负责部分数据处理(不共享任何内容)。ClickHouse 是一个真正的列式数据库管理系统(DBMS)。在 ClickHouse 中,数据始终是按列存储的,包括矢量(向量或列块)执行的过程。只要有可能,操作都是基于矢量进行分派的,而不是单个的值它开发了矢量化执行引擎,该引擎使用日志合并树,稀疏索引和CPU功能(如SIMD单指令多数据)充分发挥了硬件优势,可实现高效的计算。因此,当ClickHouse面临大数据量计算方案时,通常可以达到CPU性能的极限。通常有两种不同的加速查询处理的方法:矢量化查询执行和运行时代码生成。在后者中,动态地为每一类查询生成代码,消除了间接分派和动态分派。这两种方法中,并没有哪一种严格地比另一种好。运行时代码生成可以更好地将多个操作融合在一起,从而充分利用 CPU 执行单元和流水线。矢量化查询执行不是特别实用,因为它涉及必须写到缓存并读回的临时向量。如果 L2 缓存容纳不下临时数据,那么这将成为一个问题。但矢量化查询执行更容易利用 CPU 的 SIMD 功能。将两种方法结合起来是更好的选择。ClickHouse 使用了矢量化查询执行,同时初步提供了有限的运行时动态代码生成。列式存储和数据压缩,对于一款高性能数据库来说是必不可少的特性。如果你想让查询变得更快,最简单且有效的方法是减少数据扫描范围和数据传输时的大小,而列式存储和数据压缩就可以帮助实现上述两点。列式存储和数据压缩通常是伴生的,因为一般来说列式存储是数据压缩的前提。ClickHouse数据按列进行组织,属于同一列的数据会被保存在一起,列与列之间也会由不同的文件分别保存 。数据默认使用LZ4算法压缩,在Yandex.Metrica的生产环境中,数据总体的压缩比可以达到8:1 ( 未压缩前17PB,压缩后2PB )。列式存储除了降低IO和存储的压力之外,还为向量化执行做好了铺垫。ClickHouse用C ++编写,具有一个独立的系统,几乎不依赖第三方工具。支持相对完整的DDL和DML。大多数操作可以通过结合SQL的命令行来完成;分布式集群依赖Zookeper管理,并且单个节点不需要依赖Zookeper。大多数配置都需要通过修改配置文件来完成。
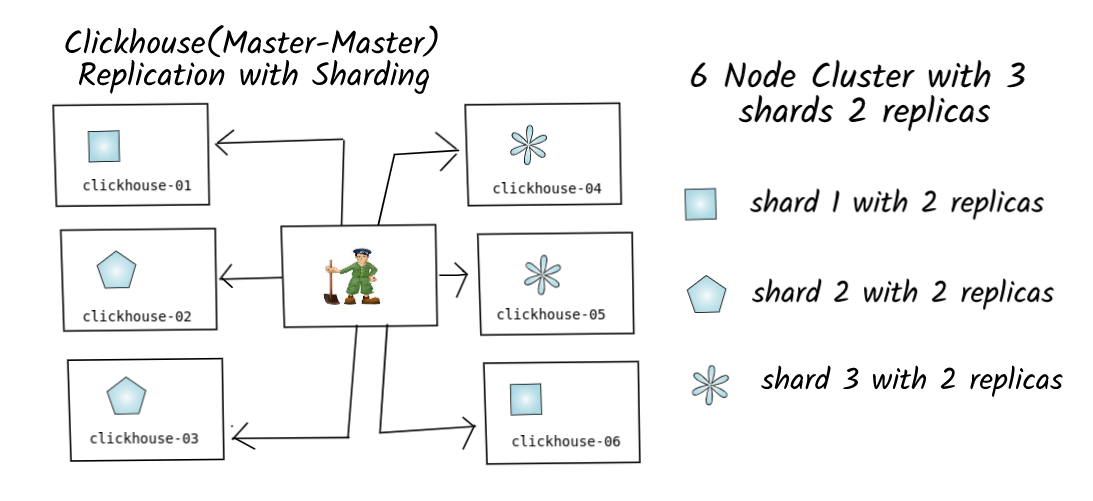
ClickHouse通常要求用户在创建表结构时指定分区列。采用数据压缩和纯列存储技术,使用Mergetree分别存储每列并压缩块,同时,数据将始终以碎片的形式写入磁盘。当满足某些条件时,ClickHouse将通过后台线程定期合并这些数据片段。当数据量继续增加时,ClickHouse将合并分区目录中的数据,以提高数据扫描的效率。同时,ClickHouse为每个数据块提供了一个稀疏索引。处理查询请求时,稀疏索引可用于减少数据扫描并加快速度。
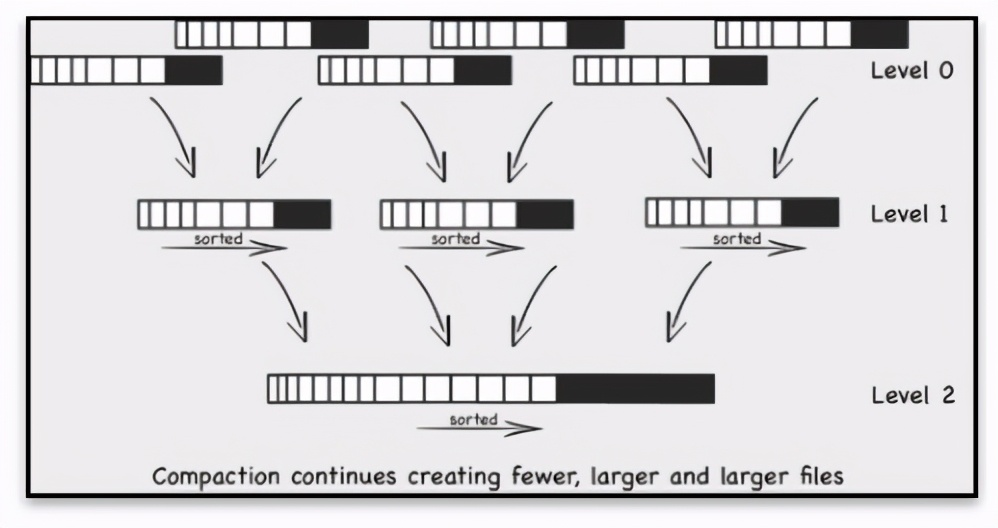
Clickhouse最初架构是基于MySQL实现的,所以在ClickHouse的设计中,能够察觉到一些MySQL的影子,表引擎的设计就是其中之一。与MySQL类似,ClickHouse也将存储部分进行了抽象,把存储引擎作为一层独立的接口。ClickHouse共拥有合并树、内存、文件、接口和其他6大类20多种表引擎。其中每一种表引擎都有着各自的特点,用户可以根据实际业务场景的要求,选择合适的表引擎使用。
优点:
- 性能卓越。在成本与性能之间做到了良好平衡,即快又开源。即便是在复杂查询的场景下,它也能够做到极快响应,且无须对数据进行任何预处理加工。
- 数据压缩比高,存储成本低。
- 支持常用的SQL语法,写入速度非常快,适用于大量的数据更新。
缺点:
- 不适合高并发的场景。在ClickHouse官方网站文档中,建议ClickHouse的并发数量不超过100。当并发要求较高时,为了减少ClickHouse的资源消耗,可以结合ClickHouse的某些特殊引擎对其进行优化。
- 分布式管理较为薄弱,使得运营、使用成本偏高。
- ClickHouse 集群自身虽然可以方便的水平增加节点,但并不支持自动的数据均衡。在节点故障的情况下,ClickHouse 并不会利用其它机器补齐缺失的副本数据。需要用户先补齐节点后,然后系统再自动在副本间进行数据同步。
- ClickHouse 在单表性能方面表现非常出色,但是在复杂场景仍有不足,缺乏成熟的 MPP 计算引擎和执行优化器。例如:多表关联查询、复杂嵌套子查询等场景下查询性能一般,需要人工优化; 缺乏 UDF 等能力,在复杂需求下扩展能力较弱等。
- ClickHouse 并不适合实时写入,原因在于 ClickHouse 并非典型的 LSM Tree 架构,它没有实现 Memory Table 结构,每批次写入直接落盘作为一棵 Tree(如果单批次过大,会拆分为多棵 Tree),每条记录实时写入会导致底层大量的小文件,影响查询性能。这使得 ClickHouse 不适合有实时写入需求的业务,通常需要在业务和 ClickHouse 之间引入一层数据缓存层,实现批量写入。
Apache Druid
https://druid.apache.org/。Apache Druid是开源分析数据库,专为对高维度和高基数数据进行亚秒级OLAP查询而设计,它由广告分析公司Metamarkets创建,到目前为止,已被许多公司使用,包括Airbnb,Netflix,Nielsen,eBay,Paypal和Yahoo。它结合了OLAP数据库,时间序列数据库和搜索系统的思想,以创建适用于广泛使用案例的统一系统。最初,Apache Druid在2012年获得GPL许可,成为开源软件,此后在2015年更改为Apache 2许可,并于2018年加入Apache Software Foundation作为孵化项目。
Druid提供OLAP查询的主要功能包括:
- 为了提高存储效率和在数据范围内进行快速过滤,Druid以面向列的压缩格式存储数据。因此,它可以处理数据冗余,同时使用高效的格式对多维聚合和分组执行查询。要回答查询,它仅加载所需的确切列。每列都针对其特定数据类型进行了优化存储。为了在多个列之间提供快速过滤和搜索,Druid使用了最新的压缩位图索引(。
- 任何数据源(即Druid中的表)的架构都非常灵活,可以轻松地进行开发。
- 数据是根据时间进行分区的,因此时间序列查询的速度明显快于传统数据库。
- Druid提供了开箱即用的算法,用于近似计数差异,近似排名以及近似直方图和分位数的计算。
- 它具有高度的可扩展性,已用于每秒每秒数百万个事件和多年数据存储的生产环境中。
- 查询的平均响应时间以秒为单位。
- 容错架构。
- 与最新的大数据技术集成,包括Apache Kafka,Apache Flink,Apache Spark和Apache Hive。
- 提供基于本机JSON的语言,以及基于HTTP或JDBC的SQL(实验性)。
- 提供高级商业智能和分析数据探索和可视化工具(如Metabase和Apache Superset)支持。
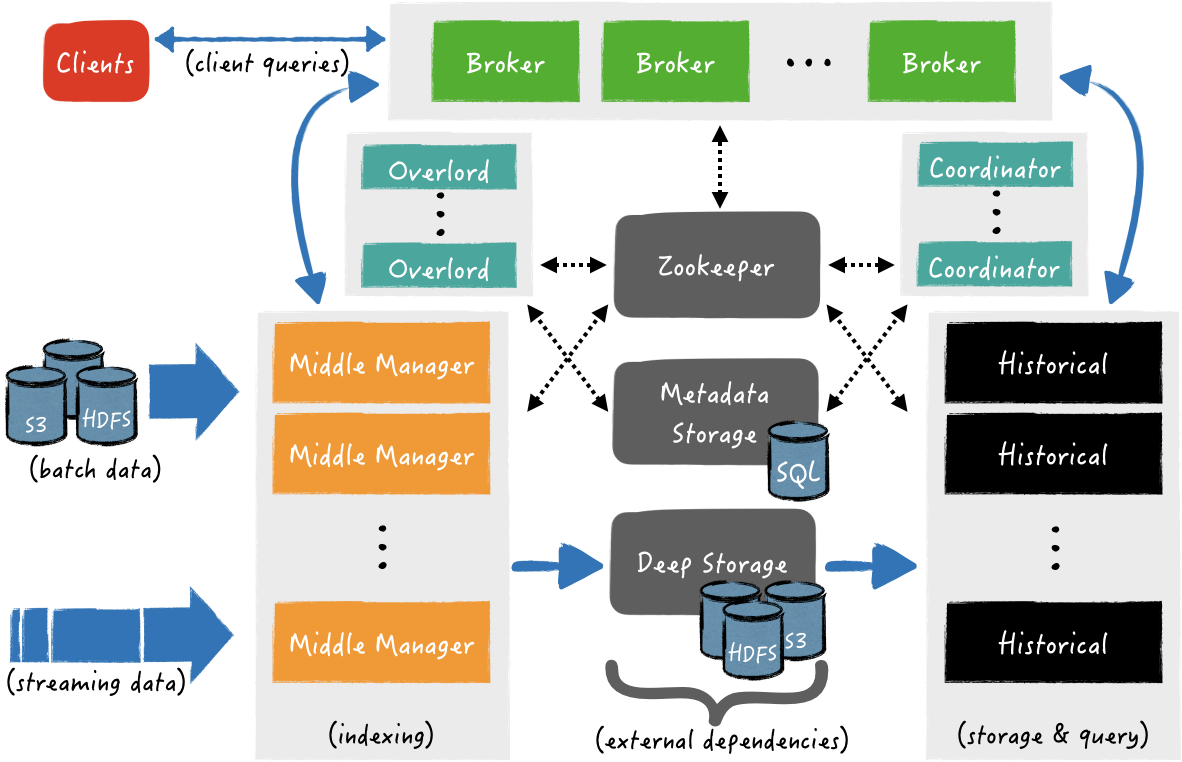
Druid平台依赖于以下三个外部依赖项:
- 深度存储:它可以是任何分布式文件系统或对象存储,例如Amazon S3,Azure Blob存储,Apache HDFS(或任何HDFS兼容系统)或网络安装的文件系统。深度存储的目的是持久保存Druid吸收的所有数据,作为备份解决方案,并在需要时同时可供所有Druid组件和群集使用。
- 元数据存储:由传统的关系数据库系统(例如PostgreSQL或MySQL)支持。所有元数据都可用于任何Druid组件。 Druid中有多种类型的元数据,有些与深度存储中的持久段有关,例如段文件的路径,它们的时间戳,它们的版本等,其他可能与外部系统有关,例如从Apache提取分区偏移量Kafka主题以及其余主题与各种内部流程的元数据有关(例如,现在正在其中创建段)。
- ZooKeeper:用于内部服务发现,协调和领导者选举。
Druid的体系结构由以下处理类型的组件组成:
- 中间管理器进程(Middle Manager)处理将数据提取到群集中的过程。例如,他们负责从Apache Kafka摄取实时流数据或从其他来源加载一批数据(例如,来自HDFS的文件)。
- 历史进程(Historical)处理“历史”数据的存储和查询。运行历史进程的节点将从深度存储中获取分段到其本地磁盘,并响应有关这些分段的查询。
- 代理进程(Broker)从外部客户端接收查询。它们确定哪个历史记录和中间管理器节点正在服务那些段,并将重写的子查询发送到这些流程中的每个流程。此后,他们收集并合并结果并响应呼叫者。在内部,历史记录进程会响应与已保留到深度存储中的数据段相对应的子查询,而中级代理将响应与最近提取的数据。
- 为了在历史和中间管理器流程之间平衡数据,Druid分别具有协调器流程和Overload流程。具体地说,协调器进程负责将段分配给正在运行历史记录进程的特定节点。同样,Overlord流程负责将提取任务分配给中间管理器进程,并负责协调细分发布。
- 最后,路由器进程在Brokers,Overlords和Coordinator的前面提供了一个统一的API网关。它们的使用是可选的,因为还可以直接联系Brokers,Overlords和Coordinator。
如前所述,Druid由用于摄取,查询和协调的独立组件组成。每个Druid流程组件都可以独立配置和扩展,从而提供最大的灵活性,并具有强大的容错能力(因为一个组件的故障不会立即影响其他组件)。此外,将深度存储和元数据存储与Druid系统的其余部分分开,可以从一直保留在深度和元数据存储中的数据中重新启动组件或整个集群。
优点:
- 亚秒级的OLAP查询分析,Druid采用了列式存储/倒排索引/位图索引等关键技术,能够在亚秒级别内完成海量数据的过滤/聚合以及多位分析等操作
- 高可用性和高扩展性,Druid采用分布式,SN(share-nothing)架构,管理类节点课配置HA,工作节点功能单一,不互相依赖,耦合性低,各种节点挂掉都不会使Druid停止工作
- 实时流数据分析。区别于传统分析型数据库采用的批量导入数据进行分析的方式,Druid提供了实时流数据分析,采用LSM(Long structure merge)-Tree结构使Druid拥有极高的实时写入性能
缺点:
- 数据不可修改,数据没有 update 更新操作,只对 segment 粒度进行覆盖:由于时序化数据的特点,Druid 不支持数据的更新。
- 能接受的数据的格式相对简单,比如不能处理嵌套结构的数据
- Druid 查询并发有限,不适合 OLTP 查询。
- 不支持Join 操作:Druid 适合处理星型模型的数据,不支持关联操作。
Apache Kylin
Apache Kylin是用于大数据的分布式分析引擎,提供SQL接口和多维分析(OLAP)并可用于用Hadoop栈。它最初由eBay中国研发中心开发,于2014年开源并为Apache Software Foundation贡献力量,具有亚秒级的查询功能和超高的并发查询功能,被美团,滴滴,携程,壳牌,腾讯,58.com等许多主要制造商采用。Kylin是基于Hadoop的MOLAP(多维OLAP)技术。核心技术是OLAP Cube;与传统的MOLAP技术不同,Kylin在Hadoop上运行,Hadoop是一个功能强大且可扩展的平台,可以支持大量(TB到PB)数据。它将预先计算(由MapReduce或Spark执行)的多维多维数据集导入到低延迟分布式数据库HBase中,以实现亚秒级的查询响应。最近的Kylin 4开始使用Spark + Parquet代替HBase来进一步简化架构。由于在脱机任务(多维数据集构造)过程中已完成大量聚合计算,因此在执行SQL查询时,它不需要访问原始数据,而是直接使用索引来组合聚合结果并再次进行计算。性能高于原始数据。一百甚至数千次;由于CPU使用率低,它可以支持更高的并发性,特别适合于自助服务分析,固定报告和其他多用户交互式分析方案。Kylin用Java编写,完全集成到Hadoop生态系统中,并使用HDFS进行分布式存储。计算引擎可以是MapReduce,Spark和Flink。存储引擎可以是HBase,Parquet(与Spark结合使用)。源数据访问支持Hive,Kafka,RDBMS等,多节点协调依赖Zookeeper;与Hive元数据兼容,Kylin仅支持SELECT查询,Schema修改需要在Hive中完成,然后同步到Kylin;传递建模和其他操作Web UI完成,通过Rest API执行任务调度,并且可以在Web UI上查看任务进度。Kylin使用Hadoop生态系统HBase或Parquet作为存储结构,依靠HBase的行键索引或Parquet的行组稀疏索引来提高查询速度,并使用HBase Region Server或Spark执行器进行分布式并行计算。Kylin通过预聚合计算多维Cube数据,并在查询时根据查询条件动态选择最佳Cuboid(类似于实例化视图),这将大大减少CPU计算和IO读取的数量。在多维数据集构建过程中,Kylin对维值进行某些编码和压缩,例如字典编码,以最大程度地减少数据存储;由于Kylin的存储引擎和架构引擎是可插拔的,因此也存在用于不同存储引擎的存储结构。Kylin的核心原则是预先计算,利用空间换时间来加速查询:Kylin的计算引擎使用Apache Spark和MapReduce;存储使用HBase和Parquet;SQL分析和后计算使用Apache Calcite。Kylin的核心技术是开发一系列优化方法,以帮助解决尺寸爆炸和扫描数据过多的问题。这些方法包括:设置聚合组,设置维度尺寸,设置派生维度,设置维度表快照,设置行键顺序,按列设置分片等。
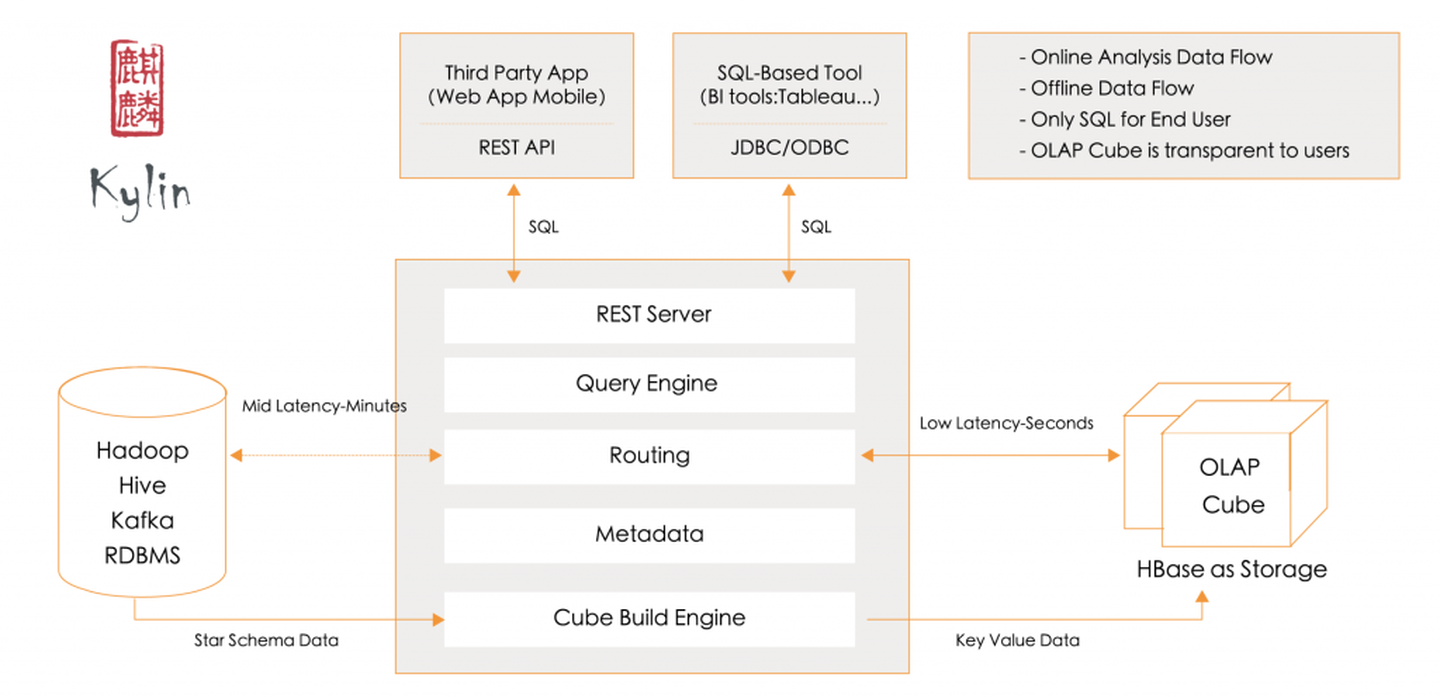
Kylin 利用 MapReduce/Spark 将原始数据进行聚合计算,转成了 OLAP Cube 并加载到 HBase 中,以 Key-Value 的形式存储。Cube 按照时间范围划分为多个 segment,每个 segment 是一张 HBase 表,每张表会根据数据大小切分成多个 region。Kylin 选择 HBase 作为存储引擎,是因为 HBase 具有延迟低,容量大,使用广泛,API完备等特性,此外它的 Hadoop 接口完善,用户社区也十分活跃。
优点:
- 基于预计算,数据量愈大,优势越大。
- SQL接口,Kylin主要的对外接口就是以SQL的形式提供的。SQL简单易用的特性极大地降低了Kylin的学习成本,不论是数据分析师还是Web开发程序员都能从中收益。
- 支持海量数据集。不论是Hive、SparkSQL,还是Impala、Presto,都改变不了这样一个事实:查询时间随着数据量的增长而线性增长。而Apache Kylin使用预计算技术打破了这一点。Kylin在数据集规模上的局限性主要取决于维度的个数和基数,而不是数据集的大小,所以Kylin能更好地支持海量数据集的查询。
- 亚秒级响应,同样受益于预计算技术,Kylin的查询速度非常快,因为复杂的连接、聚合等操作都在Cube的构建过程中已经完成了。
- 水平扩展,Apache Kylin同样可以使用集群部署方式进行水平扩展。但部署多个节点只能提高Kylin处理查询的能力,而不能提升它的预计算能力。
- 可视化集成,Apache Kylin提供了ODBC/JDBC接口和RESTful API,可以很方便地与Tableau等数据可视化工具集成。数据团队也可以在开放的API上进行二次开发。
缺点:
- 不支持明细查询
- 预计算会占用大量空间,也存在维度爆炸的问题
- 灵活性差
Apache Doris
Doris是用于报告和分析的基于MPP的交互式SQL数据仓库。它的原始名称是在百度开发时的Palo。捐赠给Apache Software Foundation之后,它更名为Doris。Doris是一个MPP的ROLAP系统,主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩) 的技术。Doris定位为:
- MPP 架构的关系型分析数据库
- PB 级别大数据集,秒级/毫秒级查询
- 主要用于多维分析和报表查询
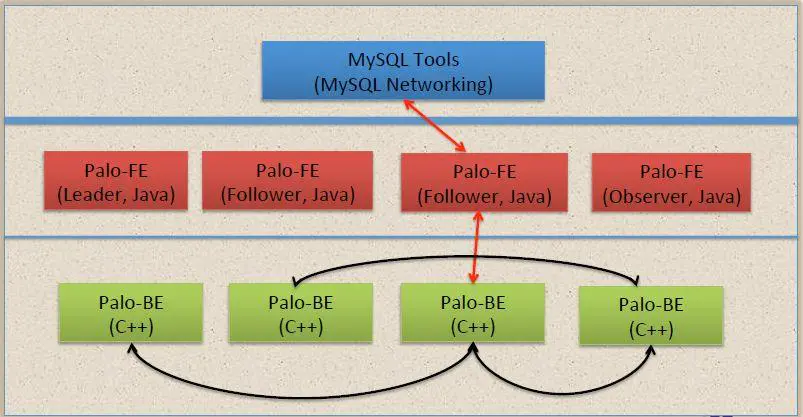
Doris 的整体架构和 TiDB 类似,借助 MySQL 协议,用户使用任意 MySQL 的 ODBC/JDBC以及MySQL 的客户端,都可以直接访问 Doris。Doris 中的模块包括 FE 和 BE 两类:FE 主要负责元数据的管理、存储,以及查询的解析等;一个用户请求经过 FE 解析、规划后,具体的执行计划会发送给 BE,BE 则会完成查询的具体执行。BE 节点主要负责数据的存储、以及查询计划的执行。目前平台的 FE 部分主要使用 Java,BE 部分主要使用 C++。Doris的主要设计思路有:
- 按列存储,支持数据压缩,减少磁盘IO
- 向量化执行,是列存数据库特有的一个优化技巧,可以减少CPU消耗,提升CPU利用率。
- Doris 没有一个强索引,它只有一个稀疏索引,当稀疏索引满足不了用户的场景通过支持物化视图来加速。
- 元数据层面,Doris 采用 Paxos 协议以及 Memory + Checkpoint + Journal 的机制来确保元数据的高性能及高可靠。
优点:
- 数据高可靠,在服务器宕机的情况下,服务依然可用,数据也不会丢失
- 易运维,Doris 部署无外部依赖,只需要部署 BE 和 IBE 即可搭建起一个集群。
- 支持 Online Schema Change
- 类似TiDB,兼容MySQL
缺点:
- 社区刚刚起步,生态还不成熟
总结
Apache Hive是基于Hadoop的数据仓库解决方案,但是查询性能一般。
Greenplum是基于PostgreSQL开发的MPP架构的开源OLAP解决方案。
Clickhouse是最近最为流行的OLAP开源工具,主要采用了列存,向量化,Mergetree等技术,性能不是一般的强。
Apache Kylin是基于Hadoop的MOLAP,主要采用了预汇聚来实现海量数据的查询性能。
Apache Druid是开源时序OLAP工具,支持高可用可高扩展。Druid也采用了预汇聚的技术。
Apache Doris是百度开源的基于MPP的交互式SQL数据仓库,同样利用了列存和向量化技术,使用Paxos协议实现分布式的一致性。
SQL Query Engine
存算分离是现代数据库区别于传统数据库的主要特点之一,主要是为了
- 提升资源利用效率,用户用多少资源就给多少资源;
- 计算节点无状态更有利于数据库服务的高可用性和集群管理(故障恢复、实例迁移)的便利性。
存算分离的架构特别适合云上的部署,能够分别扩展存储和计算资源,做到资源和成本的最大利用和收益。存算分离后,计算侧就需要一个与存储分离的SQL 查询引擎,常见的开源SQL查询引擎有Facebook的Presto,Apache Drill和SparkSQL。
Presto
Presto是一个适用于大数据的分布式SQL查询引擎,使SQL可以访问任何数据源。可以使用Presto通过水平缩放查询处理来查询非常大的数据集。Presto用于对大小从GB到PB的各种数据源运行交互式分析查询。Presto是专为交互式分析而设计和编写的,可在扩展到Facebook之类的组织规模的同时,实现商业数据仓库的速度。虽然Presto理解并可以有效执行SQL,但是Presto不是数据库,因为它不包括自己的数据存储系统。它并不是要成为通用的关系数据库。Presto并非设计为处理OLTP的场景。
Presto利用众所周知的技术和新颖的技术来进行分布式查询处理。这些技术包括
- 内存中并行处理,集群中跨节点的流水线执行,
- 使所有CPU核心保持繁忙的多线程执行模型,
- 有效的平面内存数据结构
- 最小化Java垃圾收集
- Java字节码生成
Presto可以应用在许多的场景下。
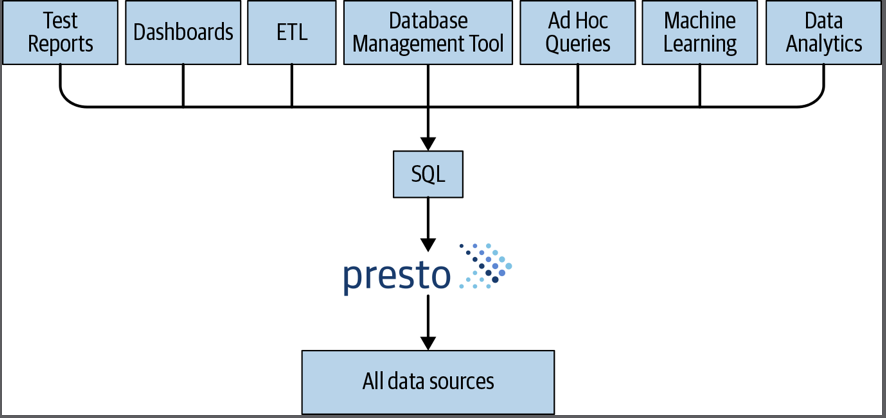
Presto是一个分布式SQL查询引擎,类似于大规模并行处理(MPP)样式的数据库和查询引擎。除了依赖于运行Presto的服务器的垂直扩展,它还能够以水平方式在服务器集群中分布所有处理能力。这意味着可以通过添加更多节点来获得更多处理能力。
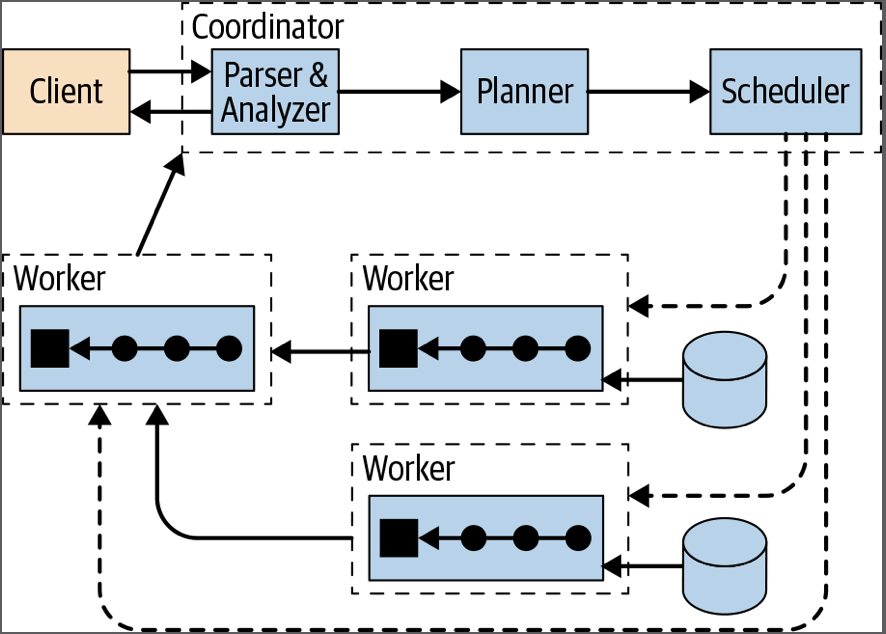
Presto的架构主要包含:
- 客户端
- 协调器是Presto服务器,它处理传入的查询并管理工作程序以执行查询。包含解析分析器,计划器,调度器
- Worker是Presto服务器,负责执行任务和处理数据。
- Discovery Service发现服务通常在协调器上运行,并允许工作人员进行注册以加入集群。
Presto存储与计算分离的核心是基于连接器的体系结构。连接器为Presto提供了访问任意数据源的接口。连接器的API称为SPI(service provider interface )。

优点:
- 类似SparkSQL的SQL计算引擎,全部计算在内存内完成,性能有优势
- 支持的数据源的种类非常多
- 支持联邦查询
缺点:
- 虽然能够处理PB级别的海量数据分析,但不是代表Presto把PB级别都放在内存中计算的。而是根据场景,如count,avg等聚合运算,是边读数据边计算,再清内存,再读数据再计算,这种耗的内存并不高。但是连表查,就可能产生大量的临时数据,因此速度会变慢,反而Hive此时会更擅长。
- 为了达到实时查询,可能会想到用它直连MySql来操作查询,这效率并不会提升,瓶颈依然在MySql,此时还引入网络瓶颈,所以会比原本直接操作数据库要慢。
- 没有容错设计,当某个任务失败时,整个查询都会失败
- 因为查询都在内存中,内存不够会导致查询失败
书籍推荐:

Apache Drill
适用于Hadoop,NoSQL和云存储的无模式SQL查询引擎。
Apache Drill类似SparkSQL和Presto,Apache Drill可以在不同的数据源上执行SQL查询, 它是一个低延迟的大型数据集的分布式查询引擎,包括结构化和半结构化数据/嵌套。其灵感来自于谷歌的 Dremel,Drill 的设计规模为上千台节点并且能与 BI 或分析环境互动查询。在大型数据集上,Drill 还可以用于短,交互式的临时查询。Drill 能够用于嵌套查询,像 JSON 格式,Parquet 格式以及动态的执行查询。Drill 不需要一个集中的元数据仓库。Apache Drill 的核心服务是 “Drillbit”,她负责接受来自客户端的请求,处理请求,并返回结果给客户端。Drillbit 服务能够安装在并运行在 Hadoop 集群上。当 Drillbit 运行在集群的每个数据节点上时,能够最大化去执行查询而不需要网络或是节点之间移动数据。Drill 使用 ZooKeeper 来维护集群的健康状态。虽然 Drill 工作于 Hadoop 集群环境下,但是 Drill 不依赖 Hadoop,并且可以运行在任何分布式集群环境下。唯一的先决条件就是需要 ZooKeeper。
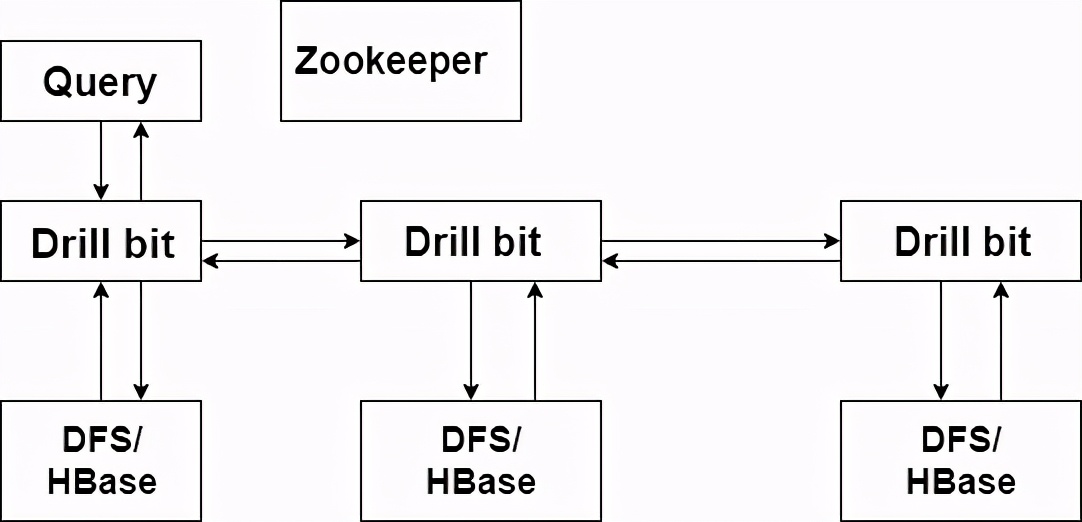
Drill的查询性能主要靠以下几点设计来支持:
- Drill基于列式存储数据,类似Spark和Presto,计算在内存内进行,避免了磁盘IO
- 使用代码生成,把SQL转化为物理执行计划,Drillbit的operator再将其生成为Java代码,本地代码生成避免了代码分发(Spark)的问题
- 长久存活的Drillbit。基于YARN的资源分配模式需要创建和销毁Java进程,Spark可以一定程度上利用Executor的重用来减少JVM的开销。Drill的Drillbit是一直存活的,避免了创建和销毁带来的开销。
优点:
- 动态Schema发现,在开始执行查询处理的时候,Drill 不需要为规范数据的 Schema 和类型。Drill 开始处理数据是在记录批处理的时候,在处理过程中去发现 Schema。
- 灵活的数据模型,Drill 允许数据属性嵌套。从架构的角度来看,Drill 提供了灵活的柱状数据模型,她能够呈现复杂的,高动态的和不断变化的数据模型。关系型数据在 Drill 中能够被转化为特殊的或是复杂/半结构化的数据。
- Drill 没有集中式的元数据要求。你不需要创建和管理表和视图
- 扩展性好,Drill 提供了一个可扩展的体系结构,包括存储插件,查询,查询优化/执行,以及客户端接口层
缺点:
- 长久存活的Drillbit导致缺乏资源的隔离,如果一个Query占用过多资源,会导致其它Query无法获得资源。
- 安装和部署比较麻烦
- 垃圾回收是个问题
书籍推荐:

SparkSQL
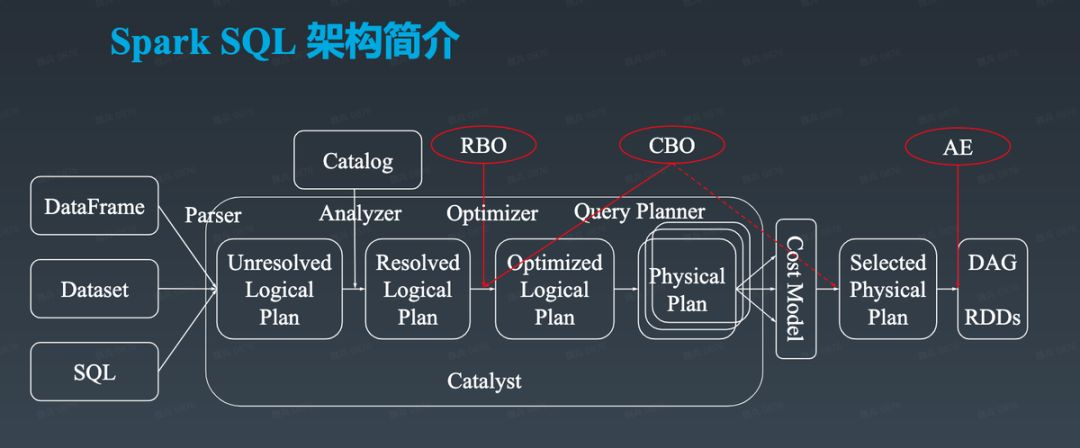
Spark SQL是Apache Spark的用于处理结构化数据的模块。
- 将SQL查询与Spark程序无缝混合。Spark SQL可以使用SQL或熟悉的DataFrame API在Spark程序中查询结构化数据。可在Java,Scala,Python和R中使用。
- 统一数据访问,以相同的方式连接到任何数据源。DataFrame和SQL提供了一种访问各种数据源的通用方法,包括Hive,Avro,Parquet,ORC,JSON和JDBC。甚至可以跨这些源连接数据。
- Hive整合,在现有仓库上运行SQL或HiveQL查询。Spark SQL支持HiveQL语法以及UDF,从而可以访问现有的Hive仓库。
- 标准连接,通过JDBC或ODBC连接。服务器模式为商业智能工具提供了行业标准的JDBC和ODBC连接。
- 性能与可扩展性,Spark SQL包括基于成本的优化器,列存储和代码生成,以加快查询速度。同时,使用Spark引擎可扩展到数千个节点和数小时的查询,该引擎可提供完整的中查询容错能力。不必担心为历史数据使用其他引擎。
优点:
- 灵活,Spark SQL将SQL查询与Spark程序混合使用,借助Spark SQL,我们可以查询结构化数据作为分布式数据集(RDD),我们可以使用Spark SQL运行SQL查询以及复杂的分析算法。
- 高兼容性,在Spark SQL中,我们可以在现有数据仓库上运行未经修改的Hive查询。Spark SQL完全兼容现有的Hive数据、查询和UDF。
- 统一数据访问,使用Spark SQL,我们可以加载和查询来自不同来源的数据。Schema-RDD允许使用单一接口高效地处理结构化数据,例如Apache Hive表、parquet文件和JSON文件。
- 性能优化,Spark SQL中的查询优化引擎将每个SQL查询转换为逻辑计划,然后转换为许多物理执行计划,最后它选择最优化的物理执行计划。
缺点:
- 不支持的union类型,使用Spark SQL,不能创建或读取包含联合字段的表。
- 不支持事务
书籍推荐:


总结
作为SQL查询引擎,SparkSQL是最为流行的,Spark是分布式内存内计算引擎,常被用来取代Map/Reduce做大数据的计算平台,SparkSQL可以用于对结构化数据进行SQL的运算,非常方便。而Presto利用其插件的设计,除了用于SQL计算,还经常被用于SQL的联邦查询,不需要把数据移动到本地存储。Apache Drill的应用不如前两者广泛。

