
热门标签
热门文章
- 1CDH集群6(1),2024年最新字节跳动厂内部超高质量Flutter+Kotlin笔记_noatime挂载选项来禁用atime选项
- 2Anaconda 环境中安装OpenCV (cv2)_conda安装cv2,2024年最新一线互联网架构师360°全方面性能调优_conda cv2安装
- 3谈谈如何进阶Java高级工程师_从java高级工程师 java工程师
- 4渗透实战-JSP上传webshell报错500_渗透报版本错误
- 5muduo 网络库 编译安装_muduo armlinux
- 6Obsidian Publish的开源替代品Perlite_obsidian publish 替代
- 7如何使用 GPT 4o API 实现视觉、文本、图像等功能?_使用gpt4o api
- 8【RabbitMQ】之持久化机制_rabbitmq持久化
- 9【使用 Python 进行 NLP】 第 2 部分 NLTK_nltk语料库
- 10Android Studio 期末大作业_android studio期末大作业
当前位置: article > 正文
Pandas读取excel数据——pearson相关性分析_一列与多列相关性分析 python
作者:Monodyee | 2024-06-05 06:49:45
赞
踩
一列与多列相关性分析 python
利用Pandas和tushare进行一个简单的数据读取和分析
一丶Pandas的DataFrame操作方法
一个表格型数据,提供列名和不同的值,以及索引值
通过下面代码记录一些DataFrame的方法
from pandas import Series,DataFrame
#一个字典数据
data={'nike':['hello','world','baby','love'],
'year':[2000,1526,11616,123],
'name':['bob','lucy','amy','andy']}
#将字典/列表 数据转化为DataFrame
d=DataFrame(data)
print(d)
#改变数据的输出顺序,按列的形式
print(DataFame(data),columns=['name','year','nike'])
#改变其输出的索引名(按abcd索引而不是0123)
print(DataFrame(data),columns=['name','year','nike'],index=['a','b','c','d'])
#添加一列则该列全部值为21
d['number']=21
#添加一列用Series赋值
d1=Series([1,2,3,4])
d['number']=d1
d2=d.T#数据转置

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
二丶数据抽取和保存分析
这里用到了一个库tushare,里面有很多的数据,链接地址为:
http://tushare.org/trading.html
我们从这里面抽取了浦发银行和广大银行的数据,然后保存和分析其相关性
import matplotlib.pyplot as plt
import numpy as np
import tushare as ts
from pandas import DataFrame,Series
s_pf='600000'#浦发银行股票代码
s_gd='601818'#光大银行股票代码
sdate='2017-01-01'#数据获取开始日期
edate='2017-12-31'#数据获取结束日期
df_pf=ts.get_h_data(s_pf,start=sdate,end=edate).sort_index(axis=0,ascending=True)#竖着排序
df_gd=ts.get_h_data(s_gd,start=sdate,end=edate).sort_index(axis=0,ascending=True)#竖着排序
#将两个数据整合到一起
df=pd.concat([df_pf.close,df_gd.close],axis=1,keys=['pf_close','gd_close'])
#填充数据
df.ffill(axis=0,inplace=True)
#保存数据
df.to_csv('pf_gd.csv')
#然后对数据进行分析
corre=df.corr(method='pearson',periods=1)#方法选择person相关性
print(corre)
plt.plot(figsize=(20,12))
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
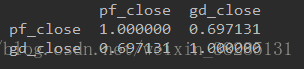
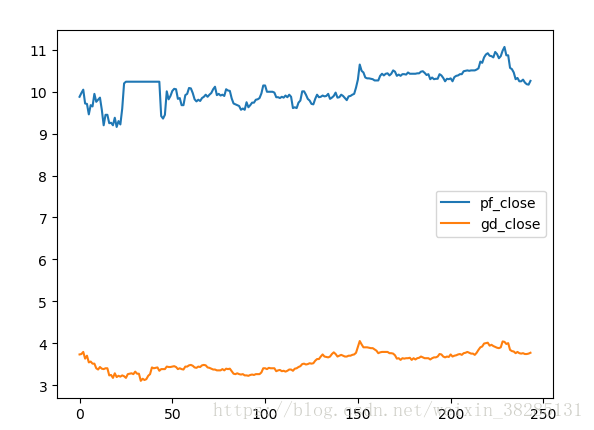
输出结果:
相关性接近0.7
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/Monodyee/article/detail/675281
推荐阅读
相关标签

