
- 1安卓系统安全权限相关内容_安卓关于系统安全
- 2Baidu Comate 智能编码助手:编程新伙伴,效率新飞跃_智能编码助手百度comate
- 3千万流量大型分布式系统架构设计实战(干货)
- 4CANape 22.0惊艳亮相,全面升级的新特性引领汽车测试技术飞跃:硬件映射助手 | 工程协作 | 测量数据管理工具 | 函数复合工具 | 多媒体数据记录 | 测量文件的使用 | 测量数据加载_canape打开. dat文件
- 5【C语言进阶:动态内存管理】柔性数组
- 6FastDFS 分布式集群搭建详解_fastdfs集群部署
- 7已解决java.lang.NullPointerException异常的正确解决方法,亲测有效!!!_tinyumbrella安装java.lang.nullpointerexception
- 8https://chat18.aichatos.xyz/#/chat/1702650198606
- 9元素水平垂直居中_元素需要在垂直方向居中,应该怎么编写代码?
- 10Hadoop学习-6-HDFS权限管理_将 node 文件的所有权限赋给 hadoop 用户
Stable Diffusion 训练
赞
踩
前言
简单介绍了Stable diffusion的训练过程。
一、主要训练方式
Stable Diffusion主要有 4 种方式:Dreambooth, LoRA, Textual Inversion, Hypernetworks
1.Textual Inversion (也称为 Embedding),它实际上并没有修改原始的 Diffusion 模型, 而是通过深度学习找到了和你想要的形象一致的角色形象特征参数,通过这个小模型保存下来。这意味着,如果原模型里面这方面的训练缺失的,其实你很难通过嵌入让它“学会”,它并不能教会 Diffusion 模型渲染其没有见过的图像内容。
2.Dreambooth 是对整个神经网络所有层权重进行调整,会将输入的图像训练进 Stable Diffusion 模型,它的本质是先复制了源模型,在源模型的基础上做了微调(fine tunning)并独立形成了一个新模型,在它的基本上可以做任何事情。缺点是,训练它需要大量 VRAM, 目前经过调优后可以在 16GB 显存下完成训练。
3.LoRA (Low-Rank Adaptation of Large Language Models) 也是使用少量图片,但是它是训练单独的特定网络层的权重,是向原有的模型中插入新的网络层,这样就避免了去修改原有的模型参数,从而避免将整个模型进行拷贝的情况,同时其也优化了插入层的参数量,最终实现了一种很轻量化的模型调校方法, LoRA 生成的模型较小,训练速度快, 推理时需要 LoRA 模型+基础模型,LoRA 模型会替换基础模型的特定网络层,所以它的效果会依赖基础模型。
4.Hypernetworks 的训练原理与 LoRA 差不多,与 LoRA 不同的是,Hypernetwork 是一个单独的神经网络模型,该模型用于输出可以插入到原始 Diffusion 模型的中间层。 因此通过训练,我们将得到一个新的神经网络模型,该模型能够向原始 Diffusion 模型中插入合适的中间层及对应的参数,从而使输出图像与输入指令之间产生关联关系。
二、kohya_ss安装(Linux)
安装步骤参考:https://github.com/bmaltais/kohya_ss
1.打开终端并切换到所需的安装目录
2.通过运行以下命令克隆存储库
git clone https://github.com/bmaltais/kohya_ss.git
- 1
3.切换到kohya_ss目录
cd kohya_ss
- 1
4.通过执行命令来运行安装脚本
bash ./setup.sh
- 1
5.安装完成后,在kohya_ss目录下,运行
bash ./gui.sh --listen 0.0.0.0 --server_port 12345 --inbrowser --share
- 1
三、利用koyha_ss GUI训练lora
1.准备训练数据
- 收集20张以上特定风格的图片
- 保证图片的高质量(训练SDXL模型分辨率最好在10241024以上,训练SD1.5分辨率在512512以上)对模型训练结果有很大影响
- 避免相似度高或者重复的图片
2.图像数据打标签(CLIP词表)
使用Stable-diffusion-webui中的Dataset Tag Editor
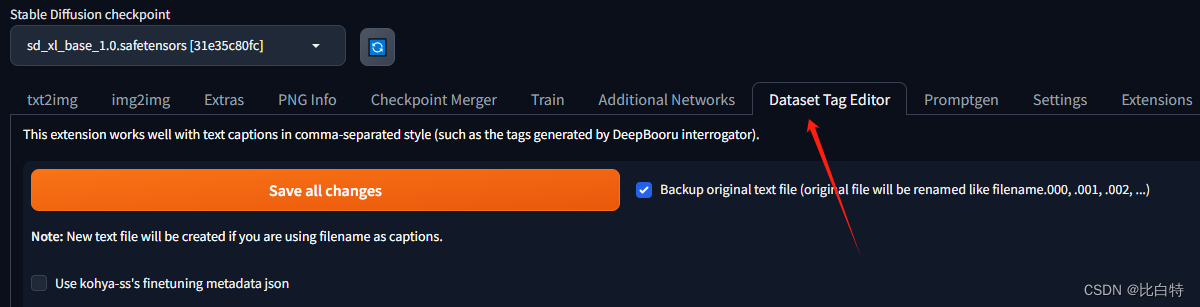
3.标签优化
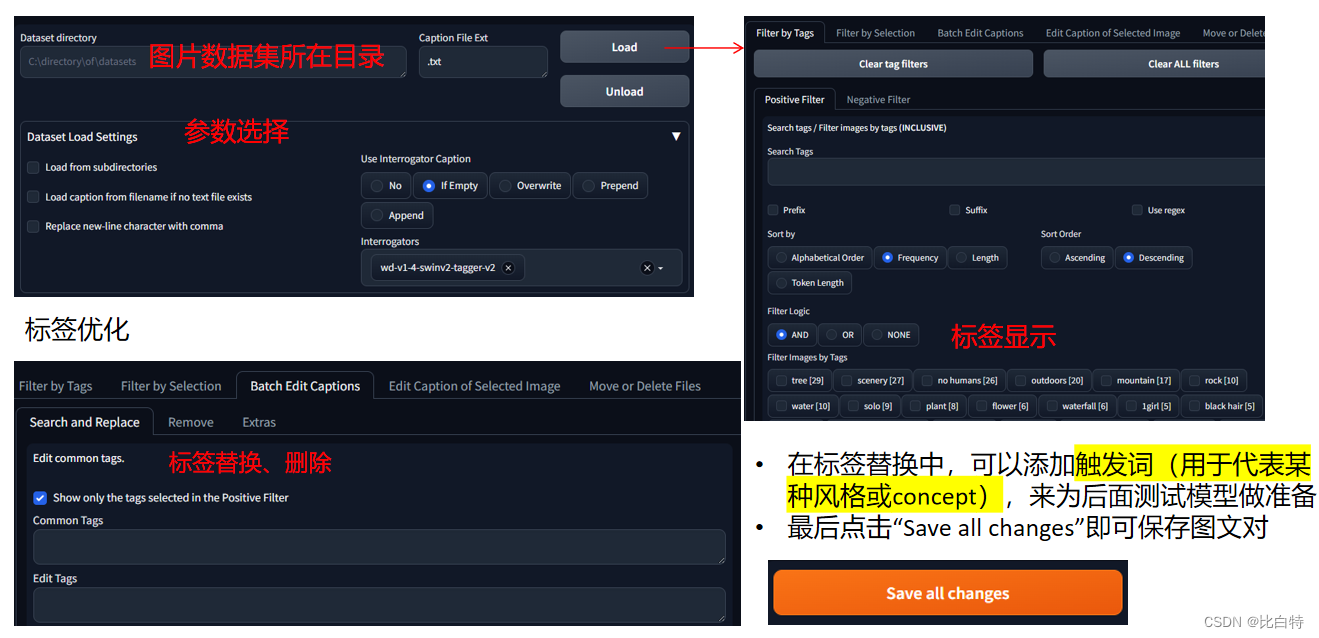
4.训练配置
- 保存好的图文对文件夹命名规范:”repeat_stylename”
- repeat代表重复次数,越精细的图,值越高
- batch_size:训练批量大小,根据显卡类型选择,一般为1,也可以增加
- epoch:迭代次数
- 总训练步数:一般在4000以上比较稳定,其计算公式如下 steps=Image数量×repeat×epocℎ/batcℎ_size
5.kohya_ss GUI训练lora
- 切换到kohya_ss目录下
- 运行bash ./run.sh打开kohya_ss训练界面
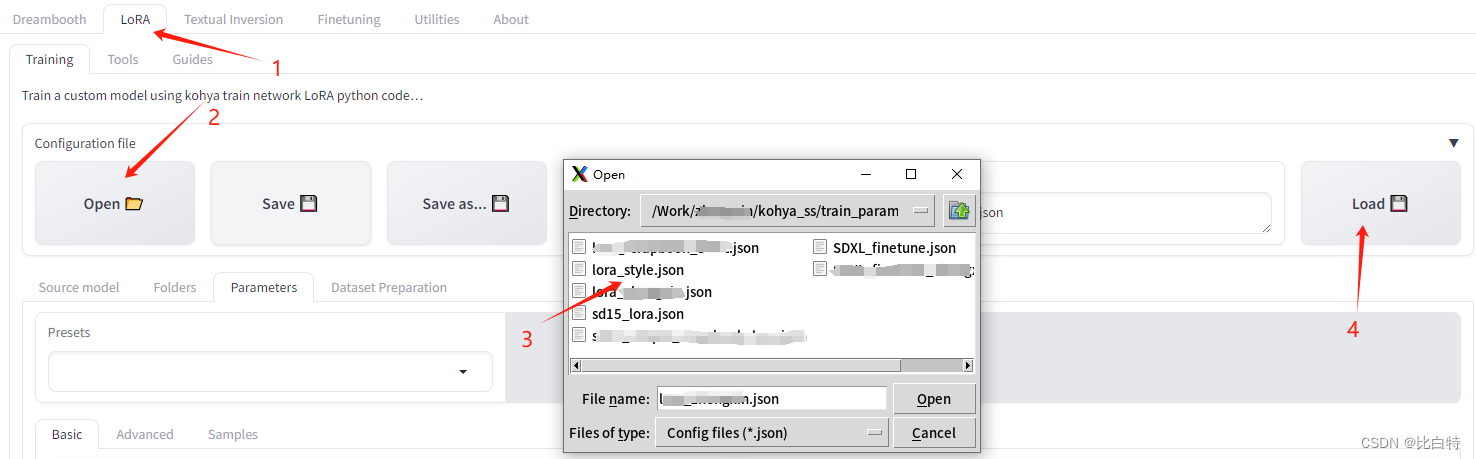
Configuration file 可以打开已有配置文件,自动配置训练参数,也可以保存之前选择好的参数以便下次使用。 - 路径: LoRA – Training – source model
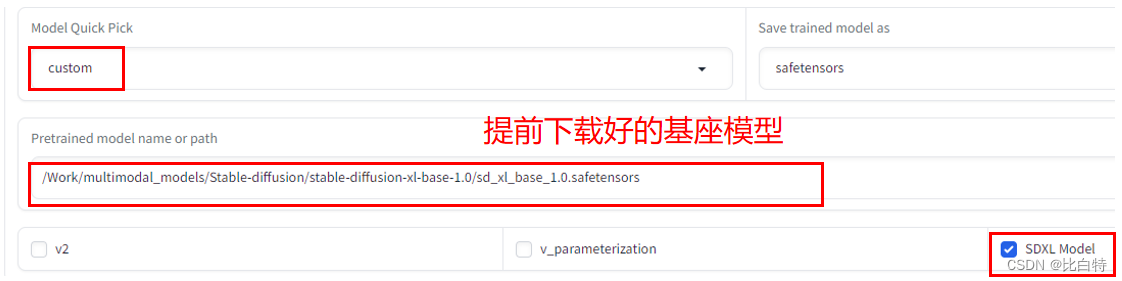
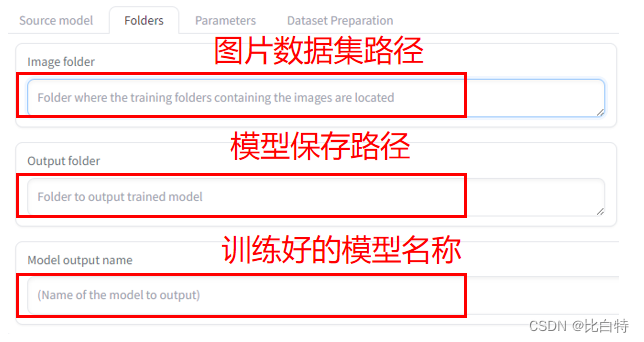
- 路径: LoRA – Training – Folders
- 路径: LoRA – Training – parameters – Basic
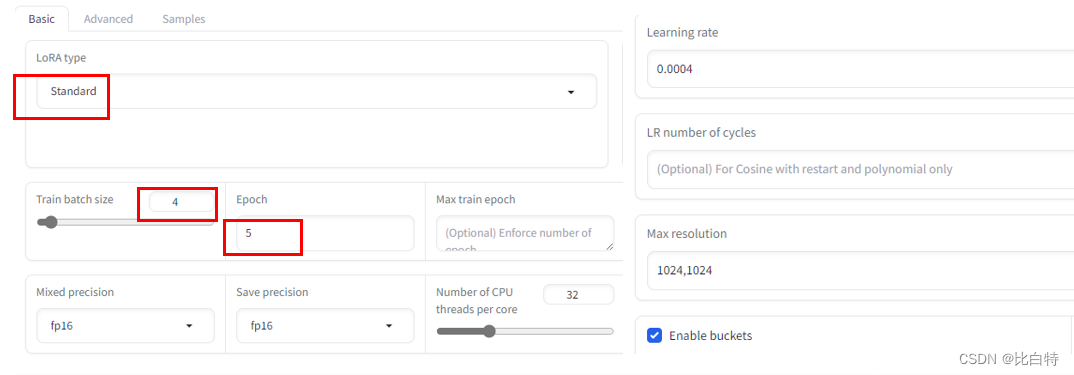
训练参数根据自己的需求设置,比如train batch size一般设为1,如果你的GPU算力充足则可以设置大一些,会加快训练速度。 - 配置完成,开始训练

总结
简单介绍了利用koyha_ss训练lora模型的过程,后面会继续补充更多相关知识!

