
- 1大数据方向毕业设计:热门选题合集及实践指南_大数据技术毕业设计选题方向
- 2Python OpenCV 入门 这篇就够了_opencv轻松入门 面向python
- 3Python魔法之旅-魔法方法(07)
- 4K8s(Kubernetes)常用命令
- 5AI大模型探索之路-基础篇5:GLM-4解锁国产大模型的全能智慧与创新应用_gml4模型
- 6喜报!多学科领域高分区SCI、EI期刊录用成功!
- 7智慧农田视频监控技术应用:智能监管引领农业新时代
- 8idea version control 找不到_idea2019jar包里面的controller路径搜不到
- 9Windows中 AppdData_window appdata locallow
- 10FPGA入门 关于Quartus 的安装教程_quartus prime 安装教程 csdn
【数据结构】 链表 - 链表的概念及结构_为什么链表的结点可以是同名结构
赞
踩
1、 链表的概念
概念:链表是一种物理存储结构上非连续、非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的
1、链表由一系列结点(链表中每一个元素称为结点)组成。
2、结点可以在运行时动态(malloc)生成。
3、每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域(详见1.2 节点部分)。
4、相比于线性表顺序结构,链表操作复杂。但是由于不需按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比顺序表快得多;但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表只需O(1)
2、 结点
链表由一个个结点构成,每个结点采用结构体的形式。结构体内前面的变量按照需要给予,最后一个变量是这个结构体类型的指针,用来存放下一节点的首地址‘
链表结点分为两个域
数据域 :存放各种实际的数据
指针域 :存放下一结点的地址
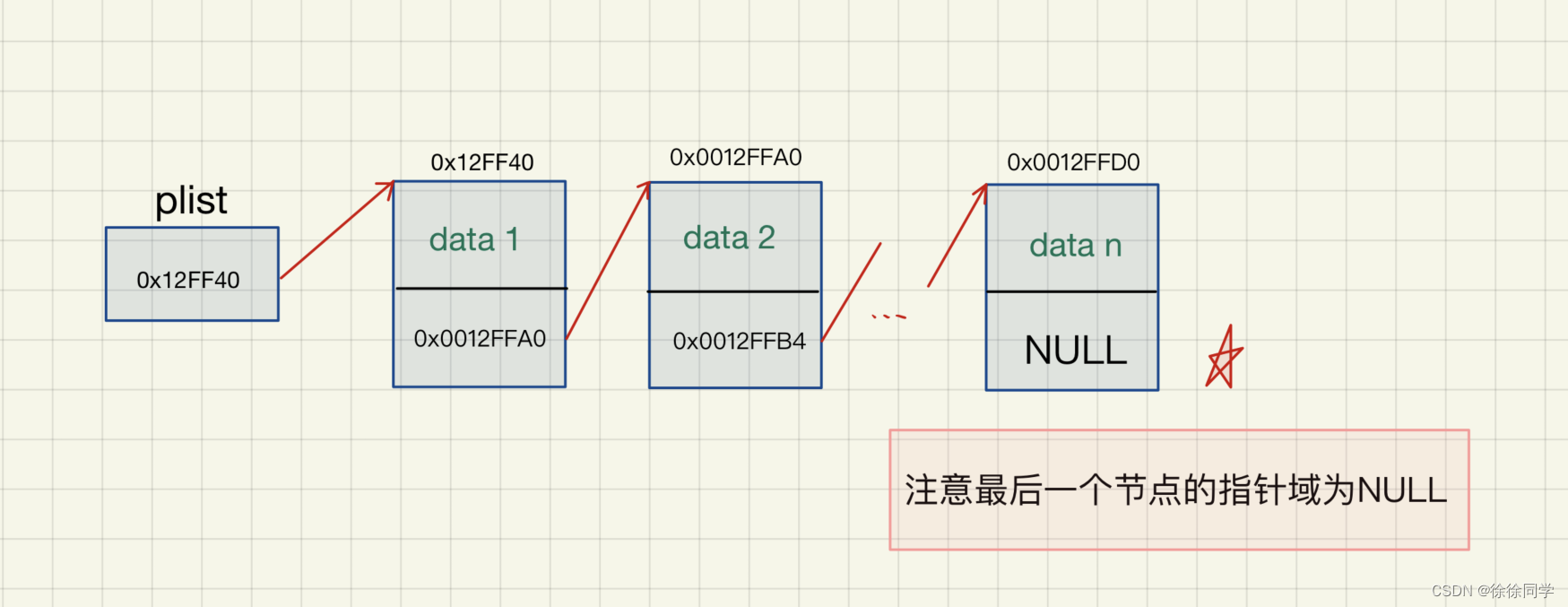 (图为带哨兵位头结点的链表)
(图为带哨兵位头结点的链表)
3、 链表的使用场景
线性表在 需要经常插入或删除数据元素 的情况下适合采用链式存储结构。
因为对于链表来说,插入或删除数据只需要创建一个结点、输入数据、修改指针把该结点连接到链表中的某一位置即可; 而对于顺序表,插入一个数据可能需要搬移其他数据,复杂度高。
4、 链表分类 和 常用的结构
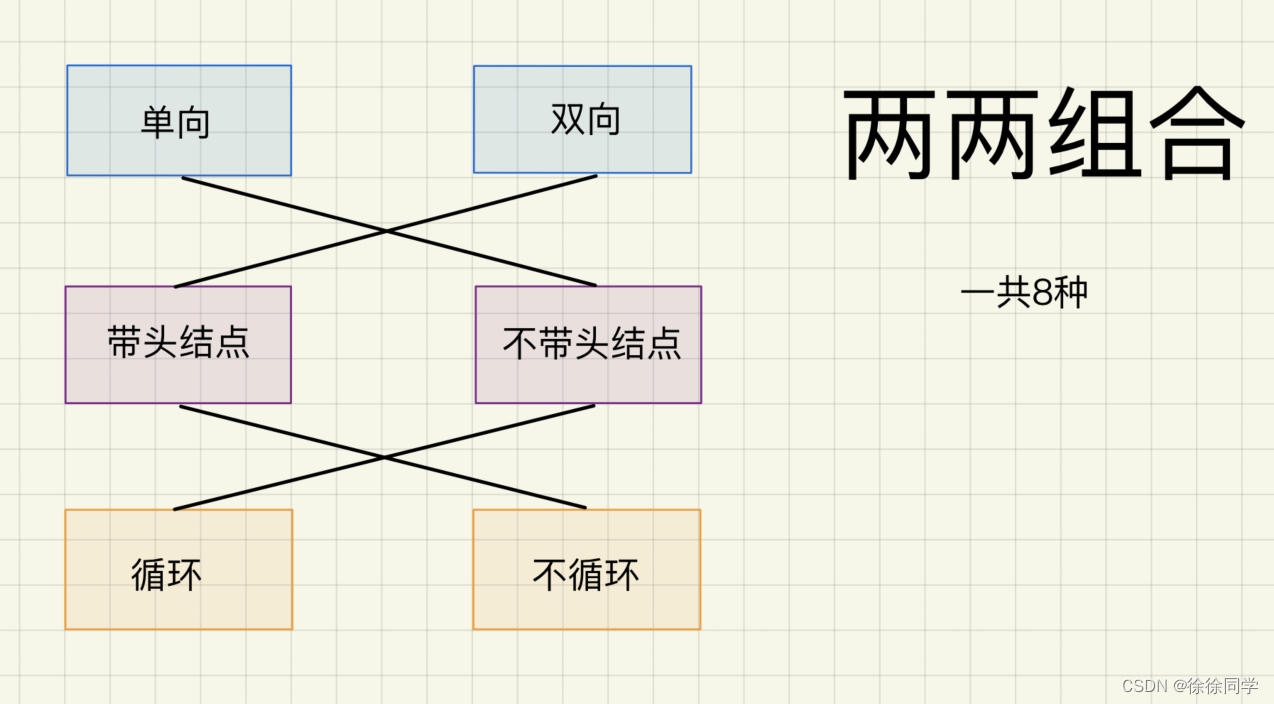 各种链表的结构:
各种链表的结构:
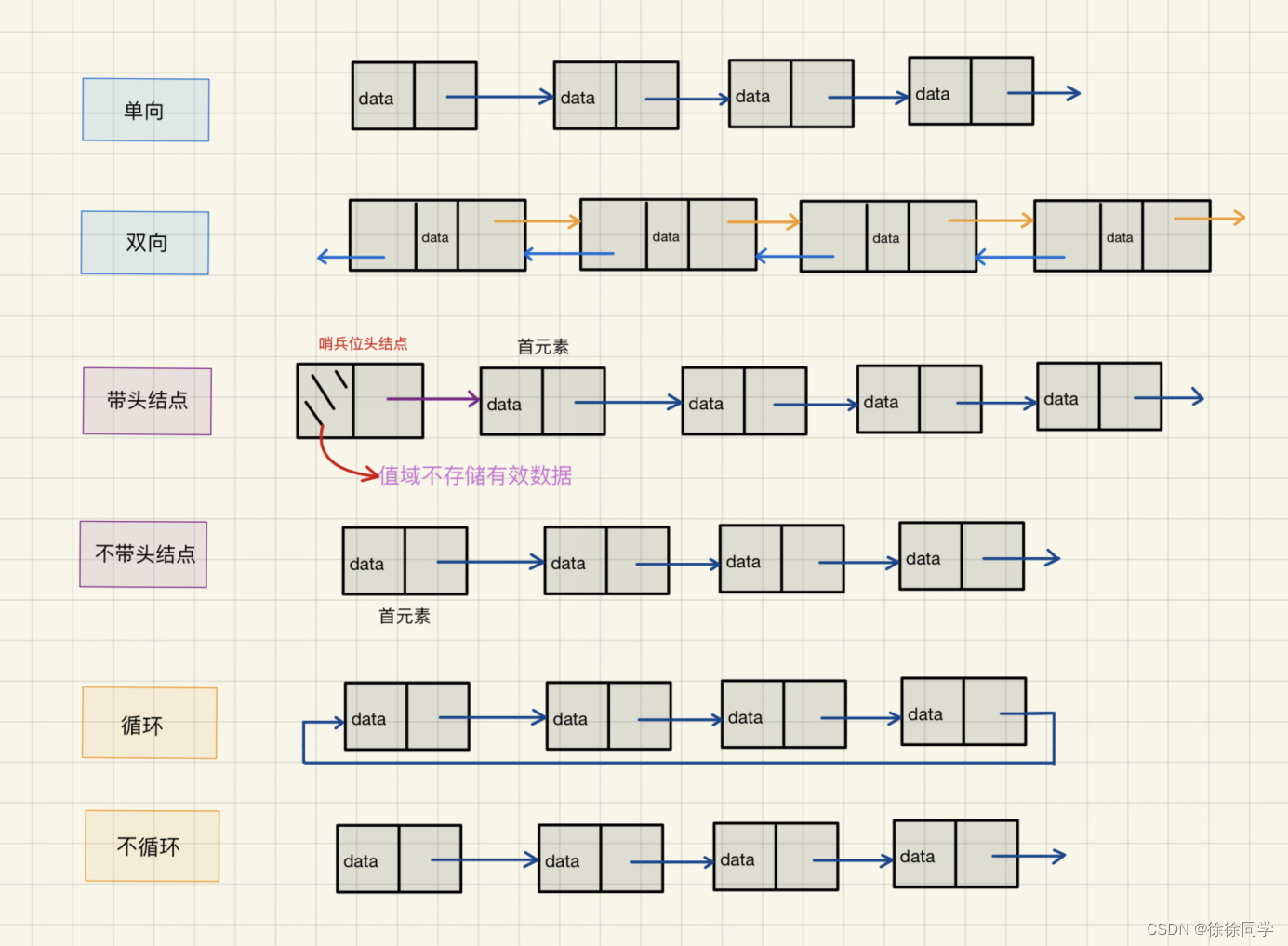
虽然组合起来一共有8种链表可以选择,但是实际中最常用的主要还是 无头单向非循环 链表和 带头双向循环 链表。
1、无头单向非循环链表:俗称 “单链表”。结构简单,一般不会单独用来存储数据。实际上更多是作为其他数据结构的子结构(如哈希桶、图的邻接表、栈的链式结构等)
2、带头双向循环链表:结构最复杂,一般用来单独存储数据。实际使用的链表,大多都是带头双向循环链表。虽然结构最复杂,但是这种结构会带来很多优势。
5、 与顺序表的比较
链表: 链表是通过结点把离散的数据链接成一个表,通过对结点的插入、删除操作从而实现对数据的存取。
顺序表: 顺序表是通过开辟一段连续的内存(直接使用 数组 或者 malloc后realloc扩容)来存储数据。
但是由于 realloc 扩容分为原地扩容和异地扩容,前者代价较低,而后者扩容时不仅需要拷贝数据,还要释放旧空间。再者,扩容时一般会扩到原来容量的2倍,扩容次数多了就容易造成空间的浪费
顺序表的每个成员对应链表的结点;成员和结点的数据类型可以是标准的c类型或者是用户自定义的结构体类型。
| 比较对象 | 顺序表 | 链表 |
|---|---|---|
| 存储空间 | 连续 | 不连续 |
| 插入或删除数据 | 可能要搬移数据,复杂度O(n) | 只需修改指针 |
| push | 动态顺序表:空间不够了需要扩容 | 没有“容量”的概念,push时直接malloc新的结点 |
| 应用 | 需要频繁访问 | 需要频繁插入、删除数据 |

