
- 1面试时,被要求笔试还得上机编写代码,感觉有点被鄙视了
- 2linux查找hadoop安装路径,Linux安装hadoop
- 3OPENCV的介绍_opencv 免费版和商业版的区别
- 4mysql 优化器提示_mysql查询优化之三:查询优化器提示(hint)
- 5Flutter中网络图片加载和缓存_exactassetimage assetimage resizeimage
- 6Modbus通信从入门到精通_2_Modbus TCP通信详解及仿真(搭建ModbusTCP仿真环境:创建虚拟PLC并进行ModbusTCP通讯;寄存器与PLC中映射关系;适合理解如何编写上位机)
- 7C++ map和multimap使用方法详细介绍_c++ 遍历multimap
- 8入门大数据基础知识了解_大数据相关知识学习
- 9MySql进阶索引篇01——深度讲解索引的数据结构:B+树_mysql b+树存储结构
- 10Day08 备忘录页面设计
flink连接hbase的连接池_进击的 Flink:网易云音乐实时数仓建设实践
赞
踩
 作者 | 汪磊(网易云音乐 / 数据平台开发专家) 整理 | 杨涛(Flink 社区志愿者) 编辑 | 蔡芳芳 如何基于 Flink 的新 API 升级实时数仓架构? 背景介绍
作者 | 汪磊(网易云音乐 / 数据平台开发专家) 整理 | 杨涛(Flink 社区志愿者) 编辑 | 蔡芳芳 如何基于 Flink 的新 API 升级实时数仓架构? 背景介绍
网易云音乐从 2018 年开始搭建实时计算平台,到目前为止已经发展至如下规模:
机器数量:130+
单 Kafka 峰值 QPS:400W+
在线运行任务数:500+
开发者:160+
业务覆盖:在线业务支持,实时报表统计,实时特征处理,实时索引支持
2020 年 Q1 任务数增长 100%,处于高速发展中

这是网易云音乐实时数仓 18 年的版本,基于 Flink 1.7 版本开发,当时 Flink SQL 的整体架构也还不是很完善。我们使用了 Antlr (通用的编程语言解析器,它只需编写名为 G4 的语法文件,即可自动生成解析的代码,并且以统一的格式输出,处理起来非常简单。由于 G4 文件是通过开发者自行定制的,因此由 Antlr 生成的代码也更加简洁和个性化)自定义了一些 DDL 完善了维表 join 的语法。通过 Antlr 完成语法树的解析以后,再通过 CodeGen(根据接口文档生成代码)技术去将整个 SQL 代码生成一个 Jar 包,然后部署到 Flink 集群上去。
此时还没有统一的元数据管理系统。在 JAR 包任务的开发上, 我们也没有任何框架的约束,平台也很难知道 JAR 的任务上下游以及相关业务的重要性和优先级。这套架构我们跑了将近一年的时间,随着任务越来越多,我们发现了以下几个问题:
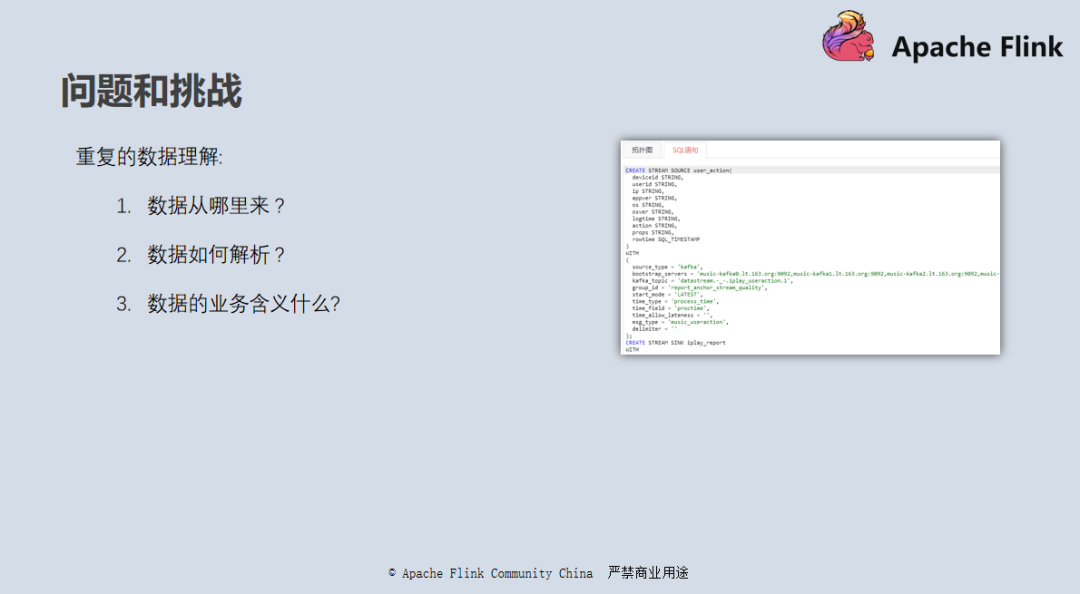
由于没有进行统一的元数据管理,每个任务的代码里面都需要预先定义 DDL 语句,然后再进行 Select 等业务逻辑的开发;消息的元数据不能复用,每个开发都需要进行重复的数据理解,需要了解数据从哪里来、数据如何解析、数据的业务含义是什么;整个过程需要多方沟通,整体还存在理解错误的风险;也缺乏统一的管理系统去查找自己想要的数据。

由于早期版本很多 SQL 的语法都是我们自己自定义的,随着 Flink 本身版本的完善,语法和官方版本差别越来越大,功能完善性上也渐渐跟不上官方的版本,易用性自然也越来越差。如果你本身就是一名熟知 Flink SQL 的开发人员,可能还需要重新学习我们平台自己的语法,整体不是很统一,有些问题也很难在互联网上找到相关的资料,只能靠运维来解决。

org.apache.flink [详细] 赞
踩

