
- 1ChatGPT Plus GPT-4o Claude 3 Opus合租拼车全新方式
- 2ThinkPHP实现用户注册、登录模块_thinkphp6 创建user模块
- 3Baidu Comate智能编码助手:编程效率的未来_comate代码助手
- 4软件测试之测试用例评审流程_软件测试计划评审会
- 5数码管显示
- 6【MySQL】学习和总结使用列子查询查询员工工资信息,2024年最新面试必问知识点总结_5、查有无员工工资一样的,列出他们的编号,姓名,收入(以前用自查询做过,这次用子查
- 7关于MySQL权限介绍
- 82024粤港澳青少年信息学创新大赛C++知识点汇总和真题训练_粤港澳青少年信息学创新大赛真题
- 9关于提交AppStore的总结_appstorecontact 上传完成1个小时了 构件版本还是没有
- 10linux超级root权限,Linux内核超级权限用户root
图像识别——玩转YOLO网络_图像识别yolo是啥
赞
踩
图像识别——玩转YOLO网络
YOLO,全称“You Only Look Once”,意为你只需要看一次,是一种快速、准确的目标检测算法。它由Joseph Redmon等人在2016年提出,其核心思想是将输入图像划分为S×S个网格单元,每个网格预测B个边界框,并给出这些边界框中包含目标的置信度以及类别概率。
YOLO网络的结构特点
- 输入层:YOLO算法的输入图像大小通常为固定尺寸,如416×416或448x448,这是为了方便网络进行卷积和池化操作。
- 网络结构:YOLO采用了一个单独的CNN模型实现end-to-end的目标检测。它首先将输入图像划分为多个网格单元,然后每个网格单元预测多个边界框及其置信度,以及每个边界框中目标物体的类别概率。
- 输出层:YOLO的输出是一个张量,表示了图像中各个目标物体的位置、大小和类别。通过非极大值抑制(NMS)算法去除重叠的边界框,最终输出所有保留下来的边界框及其对应的类别和置信度。
本文我们将结合YOLO官网https://docs.ultralytics.com,对YOLO的使用,训练方法进行较为详细的介绍,让我们开始吧
YOLO快速使用(Ultralytics HUB)
- Ultralytics HUB官网:https://hub.ultralytics.com/home
- Ultralytics HUB介绍:https://docs.ultralytics.com/hub/
- Ultralytics HUB官方教程:https://docs.ultralytics.com/hub/quickstart/
- YouTobe视频介绍:https://youtu.be/lveF9iCMIzc
Ultralytics HUB是一个功能全面且用户友好的视觉人工智能云平台。该平台提供了一站式解决方案,涵盖了数据处理、模型选择与配置、训练以及模型部署等关键环节。用户可以通过简单的操作快速上传和处理数据,选择适合的模型和任务,进行高效的模型训练。
HUB的设计是用户友好和直观的,具有拖放界面,允许用户轻松上传数据并快速训练新模型。它提供了一系列预先训练的模型和模板供选择,使用户可以轻松开始训练自己的模型。一旦模型经过训练,就可以很容易地部署并用于实时对象检测、实例分割和分类任务。
我们首先来体验一下Ultralytics HUB的移动APP吧!首先我们扫描Ultralytics HUB介绍网站的APP二维码,下载并安装Ultralytics HUB移动APP。  下载好之后,我们登录进来即可体验各种YOLO模型的目标检测功能。
下载好之后,我们登录进来即可体验各种YOLO模型的目标检测功能。
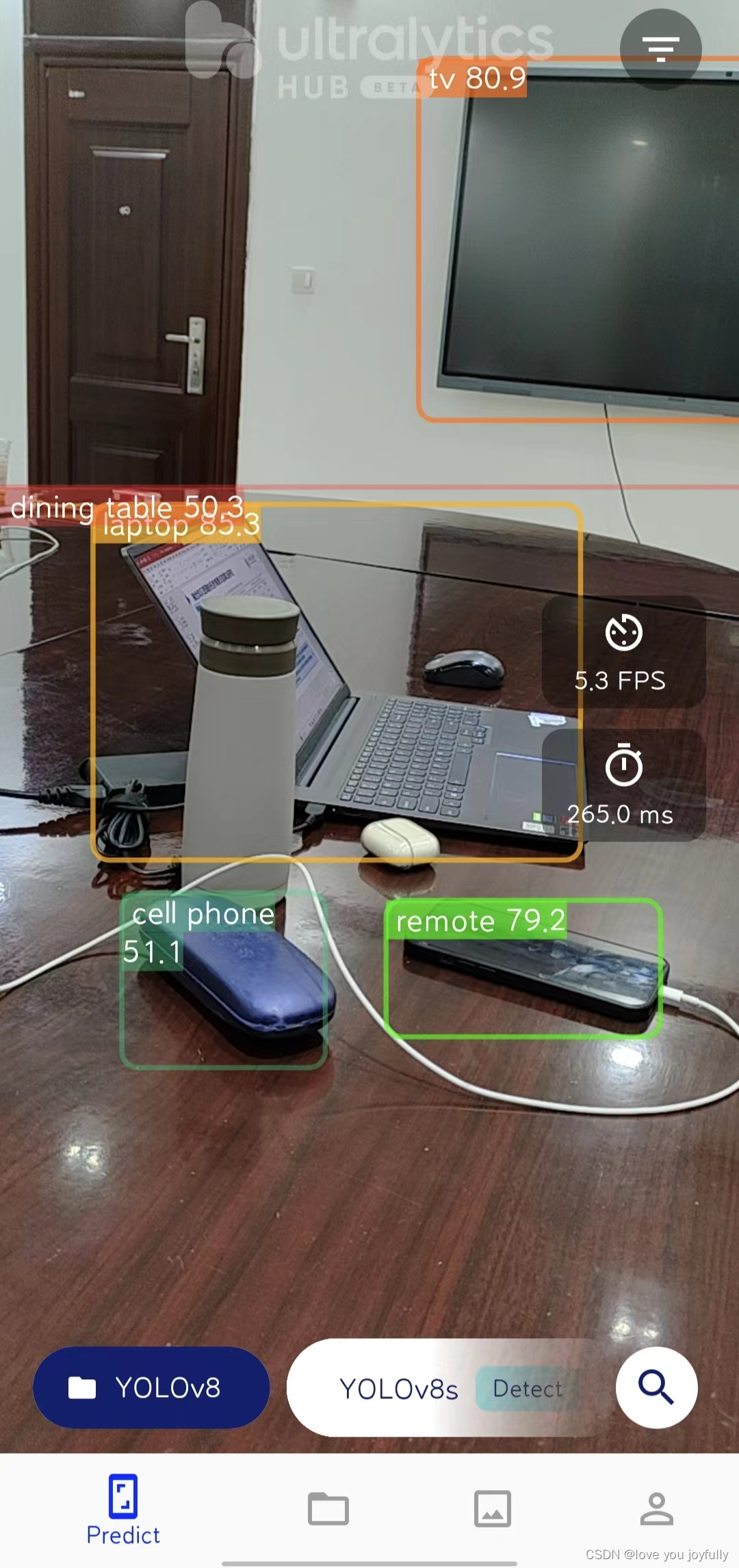
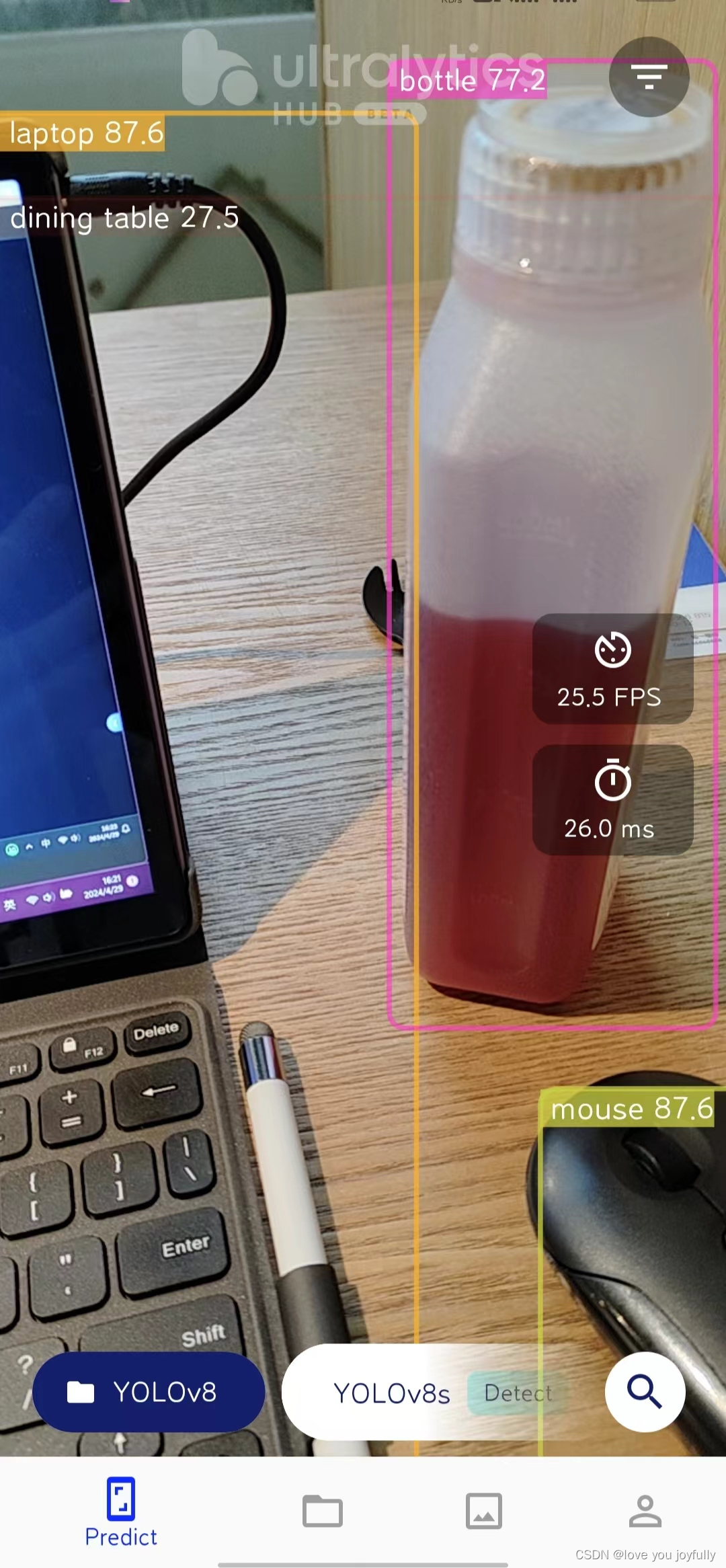
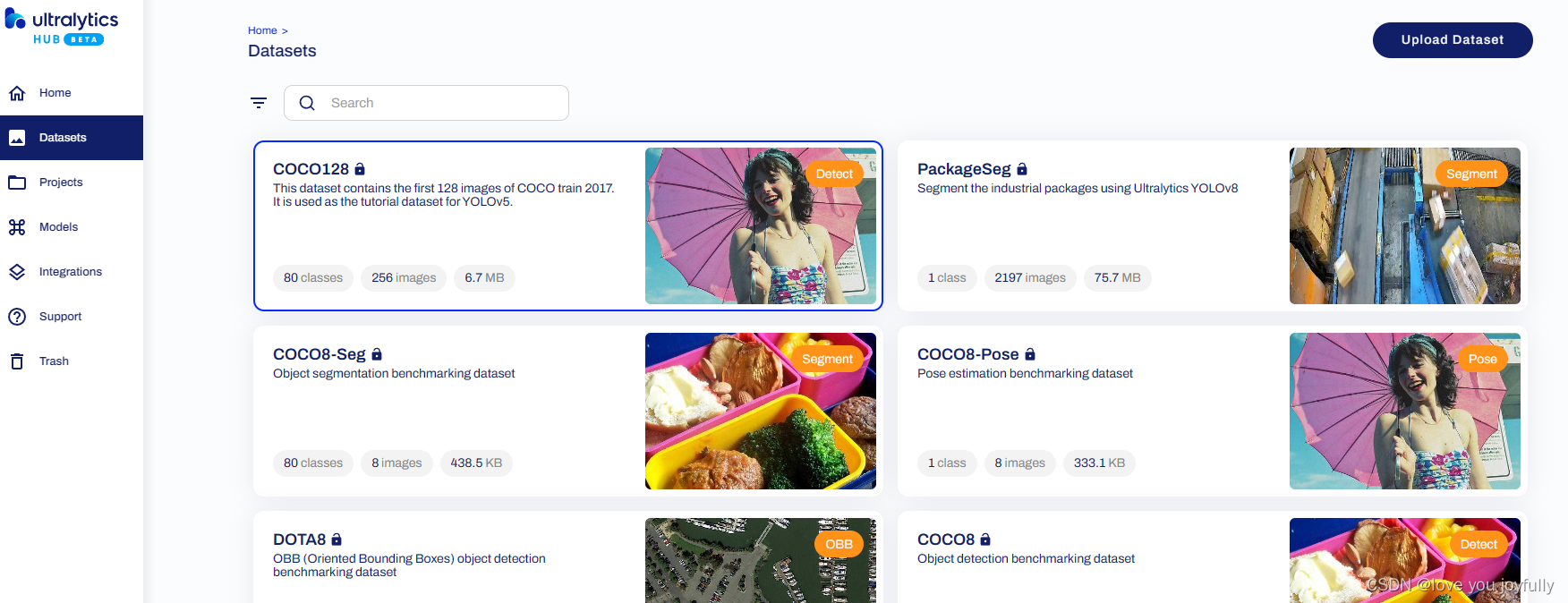
此处我们可以选择公开的数据集,也可以上传自己的数据集,本文我们将介绍上传自定义数据集的方法。我们下载了吸烟数据集,该数据集中有文件夹images原始图像,labels标签,我们通过设计函数,将data数据集中数据进行适当的调整,转化为ultralytics HUB标准的数据集格式。
HUB Datasets制作可查看官网:https://docs.ultralytics.com/hub/datasets/
import os import shutil import random from pathlib import Path def check_names_match(image_files, label_files): ''' 检查图片文件名与标签文件名是否匹配 如果匹配,则返回True,否则返回False ''' for image_file, label_file in zip(image_files, label_files): if image_file.split('.')[0] != label_file.split('.')[0]: # 在这里添加删除不匹配文件的代码 image_files.remove(image_file) label_files.remove(label_file) while len(image_files) != len(label_files): if len(image_files) > len(label_files): # 删除多余的图片文件 image_files.pop() else: # 删除多余的标签文件 label_files.pop() return True def split_data(image_dir, label_dir, output_dir, train_ratio=0.8, val_ratio=0.1, test_ratio=0.1): """ 将数据集中的图片和标签按照指定比例分割成训练、验证和测试集,并创建相应的文件夹结构。 参数: image_dir (str): 原始图片所在的文件夹路径。 label_dir (str): 原始标签所在的文件夹路径。 output_dir (str): 输出文件夹的路径,用于存放分割后的数据。 train_ratio (float): 训练集所占的比例,默认为0.8。 val_ratio (float): 验证集所占的比例,默认为0.1。 test_ratio (float): 测试集所占的比例,默认为0.1。 """ # 确保比例总和为1 assert train_ratio + val_ratio + test_ratio == 1.0, "Ratios must sum up to 1" # 创建输出目录结构 Path(output_dir).mkdir(parents=True, exist_ok=True) output_dir = Path(output_dir) for subset in ['train', 'val', 'test']: # 使用Path对象的joinpath方法来连接路径,并创建目录 (output_dir.joinpath('images', subset)).mkdir(parents=True, exist_ok=True) (output_dir.joinpath('labels', subset)).mkdir(parents=True, exist_ok=True) # 获取所有图片和标签的文件名 image_files = sorted(os.listdir(image_dir)) label_files = sorted(os.listdir(label_dir)) check_names_match(image_files, label_files) # 打乱文件列表 combined = list(zip(image_files, label_files)) random.shuffle(combined) image_files[:], label_files[:] = zip(*combined) # 根据比例分割数据集 num_files = len(image_files) train_end = int(num_files * train_ratio) val_end = train_end + int(num_files * val_ratio) # 复制文件到对应的文件夹 for i, (img_file, lbl_file) in enumerate(zip(image_files, label_files)): if i < train_end: subset = 'train' elif i < val_end: subset = 'val' else: subset = 'test' shutil.copy(os.path.join(image_dir, img_file), os.path.join(output_dir, 'images', subset, img_file)) shutil.copy(os.path.join(label_dir, lbl_file), os.path.join(output_dir, 'labels', subset, lbl_file))

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
import yaml def generate_yaml_file(output_dir, dataset_name): ''' 根据数据集生成yaml文件 ''' data = { "train": f"images/train", "val": f"images/val", "test": f"images/test", "nc": 0, # 类别数量,需要根据实际情况修改 "names": [] # 类别名称列表,需要根据实际情况修改 } # 读取类别名称 label_dir = f"{output_dir}/labels" for subset in ["train", "val", "test"]: try: label_files = os.listdir(os.path.join(label_dir, subset)) for label_file in label_files: with open(os.path.join(label_dir, subset, label_file), "r") as f: lines = f.readlines() for line in lines: class_name = line.split(" ")[0] if class_name not in data["names"]: data["names"].append(class_name) data["nc"] += 1 except FileNotFoundError: data.pop(subset) continue # 写入yaml文件 with open(f"{output_dir}/{dataset_name}.yaml", "w") as f: yaml.dump(data, f)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
# 使用,我们将data中数据整理到data_sorted文件夹中
split_data('data\images', 'data\labels', 'data_sorted')
- 1
- 2
# 生成对应的yaml文件
generate_yaml_file("data_sorted", "my_dataset")
- 1
- 2
接着我们将制作好的数据集进行压缩即可上传,将数据集压缩后,在上传到Ultralytics HUB之前,首先应该对其进行验证。Ultralytics HUB会在数据集上传后进行数据集验证检查,因此提前确保数据集格式正确、无误,就能避免因数据集被拒而造成的任何损失。
# 如果本地没有安装YOLO,需要首先pip一下~
%pip install -U ultralytics
- 1
- 2
from ultralytics.hub import check_dataset
# 利用该代码即可将待上传的压缩文件数据集进行检查
check_dataset('data_sorted.zip')
- 1
- 2
- 3
- 4
检查好数据集之后,我们就可以将数据集进行上传了,在datasets中单击upload Dataset,将数据集命名,上传,待系统上传整理完毕后,就可以开始训练过程了。
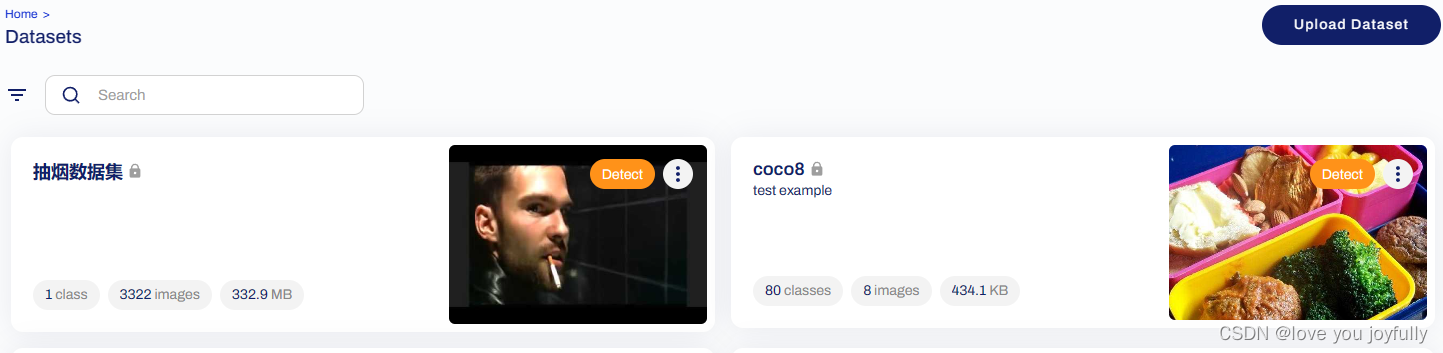
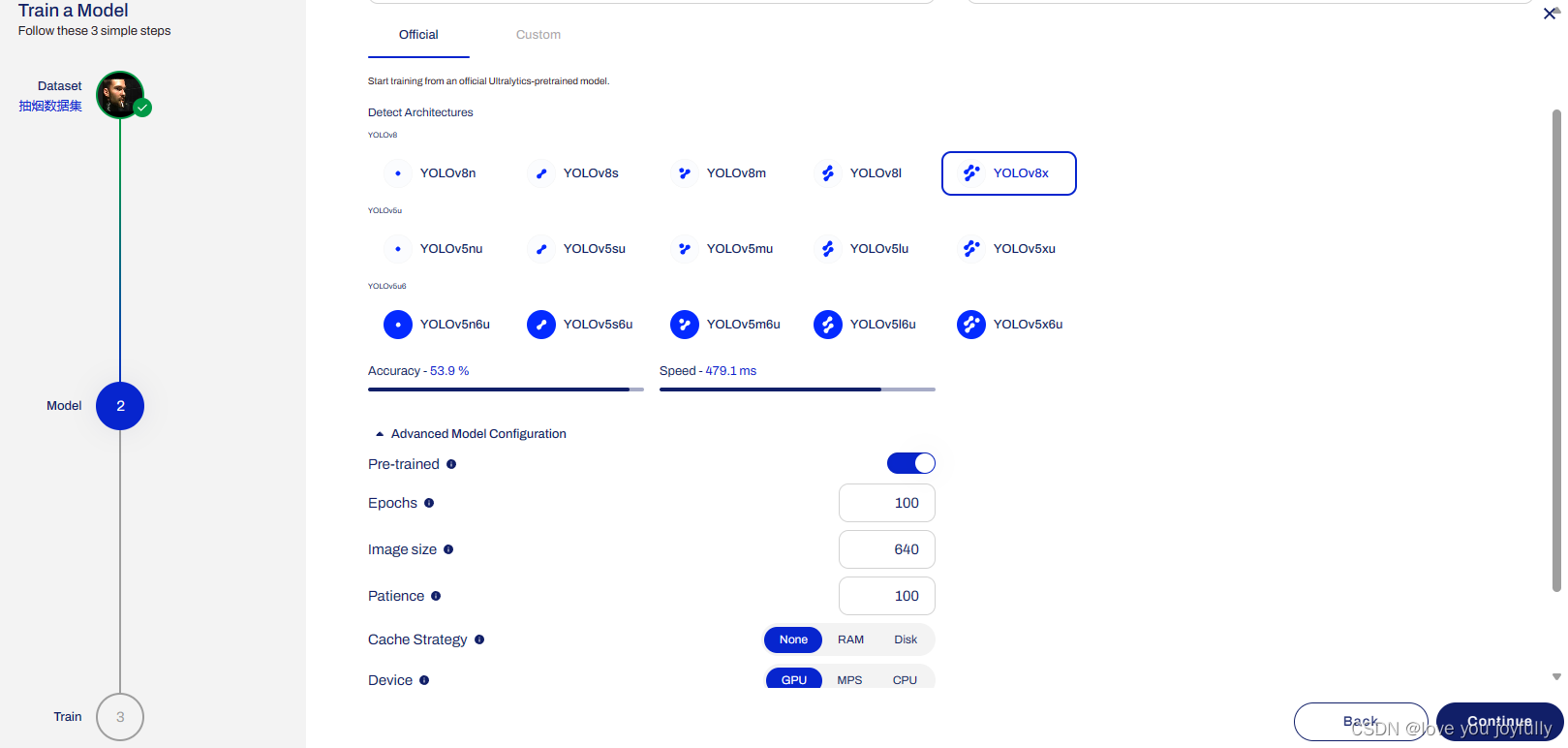

from ultralytics import YOLO, checks, hub
checks()
hub.login('aeXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX')
model = YOLO('https://hub.ultralytics.com/models/XXXXXX')
results = model.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
在运行上述代码的过程中,我们可以在网站界面看到训练过程:
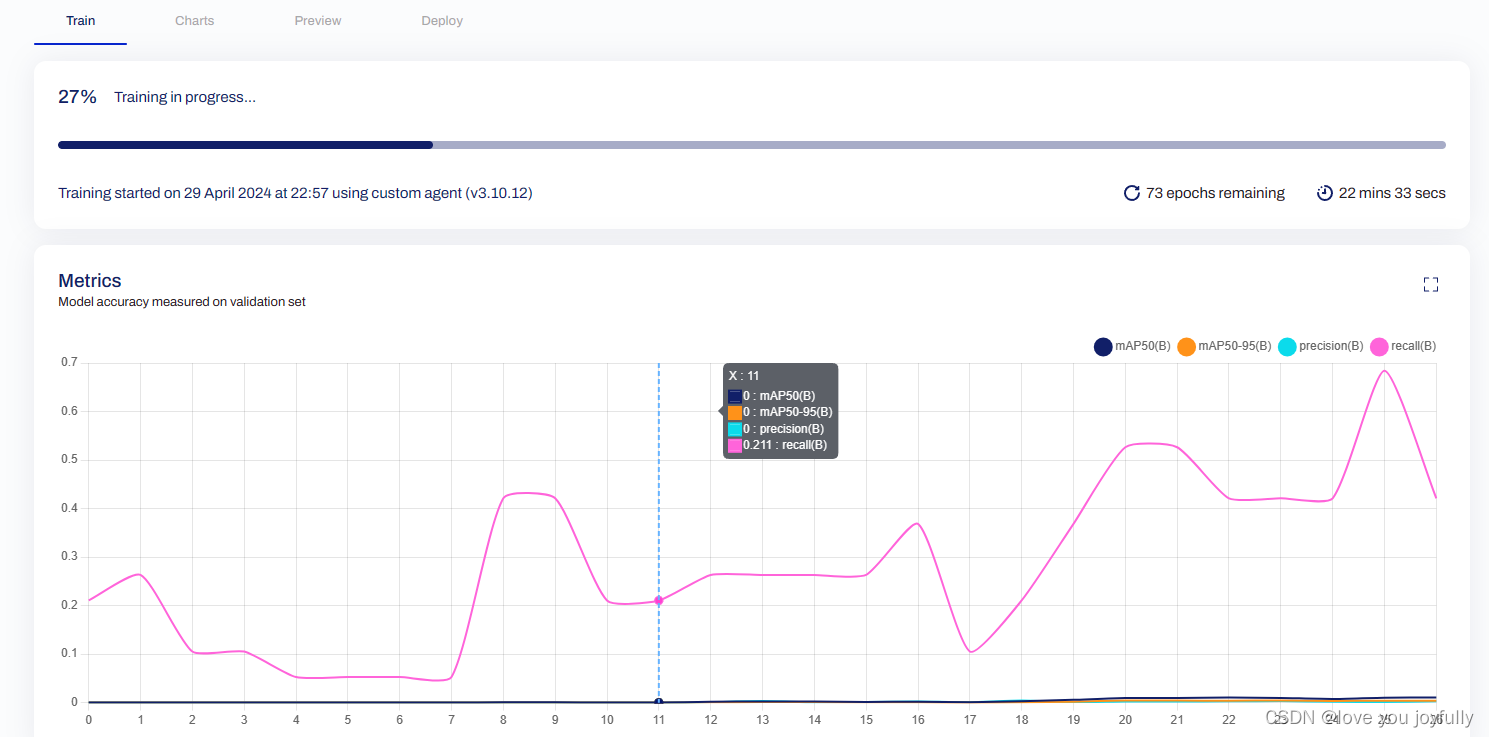
模型训练好之后,模型会自动上传到HUB网站,方便部署,在APP中我们也可以轻松的使用自己训练的模型。
YOLO本地训练
Ultralytics 提供多种安装方法,包括 pip、conda 和 Docker。通过 ultralytics pip 软件包安装最新稳定版本的 YOLO,或通过克隆 Ultralytics GitHub 仓库安装最新版本的 YOLOv8。Docker 可用于在隔离的容器中执行软件包,避免本地安装。在Quickstart对于YOLO的本地安装进行了详细的说明。接下来我们介绍一下python,pytorch框架下的使用训练方法。
首先加载模型,注意,加载一个已经训练过的模型时,若当前文件夹不存在对应的.pt文件,则需要联网进行下载。
from ultralytics import YOLO
# Load a model加载模型,此处如果没有指定路径,将会自动下载对应的参数结构
model1 = YOLO('yolov8n.yaml') # 从yaml文件创建一个新的模型
model2 = YOLO('yolov8n.pt') # 加载一个已经训练过的模型
model3 = YOLO('yolov8n.yaml').load('yolov8n.pt') # 从yaml文件创建一个新的模型,然后改变权重,变为训练过的模型
- 1
- 2
- 3
- 4
- 5
- 6
Transferred 355/355 items from pretrained weights
- 1
让我们使用工具来简要看看YOLO目标检测模型的结构,我们可以使用pytorch可视化工具netron查看YOLO网络模型结构。
在命令行执行:
C:\Users\admin>netron
Serving at http://localhost:8080
即可在网页端打开netron
将网络模型保存为.pt,或者将现有的.pt文件导入网页即可。
# 如果没有安装netron,需要先pip一下~
%pip install netron
- 1
- 2
 下方是抽烟数据集进行训练的代码用法。其他设备,如苹果电脑的使用方法及更详细的训练过程可参考https://docs.ultralytics.com/modes/train/
下方是抽烟数据集进行训练的代码用法。其他设备,如苹果电脑的使用方法及更详细的训练过程可参考https://docs.ultralytics.com/modes/train/
results = model2.train(data='data_sorted\my_dataset.yaml', epochs=50) # 使用数据data训练,轮次为50
# 下方代码可以使用多个GPU设备进行训练
results = model2.train(data='data_sorted\my_dataset.yaml', epochs=100, device=[0, 1])
- 1
- 2
- 3
在结束训练后,模型会将训练好的参数以及结果放在文件夹runs中,我们可以加载runs中的参数进行验证。其实在训练的过程中会自动进行验证,结果将保存在runs\detect\val中
model2 = YOLO("runs\detect/train\weights/best.pt")
model2.val(data='data_sorted\my_dataset.yaml')
- 1
- 2
在预测时,Ultralytics YOLO 模型会返回一个 Python 结果对象列表,或者在推理过程中向模型传递数据流=True 时,返回一个具有内存效率的 Python 结果对象生成器
# 对一系列图片进行批量推理 # '000012.jpg'和'000016.jpg'是要进行目标检测的图片文件名 # stream=True表示以流的方式返回结果,即返回一个生成器(generator),这样可以逐个处理结果,节省内存 results = model2(['data_sorted/images/test/000012.jpg', 'data_sorted/images/test/000016.jpg'], stream=True) # 处理生成器中的结果 for result in results: # 获取边界框的输出结果,Boxes对象包含了检测到的目标物体的位置信息 boxes = result.boxes # 获取分割掩码的输出结果,如果模型支持分割任务,则Masks对象会包含分割掩码信息 masks = result.masks # 获取姿态关键点的输出结果,如果模型支持姿态估计任务,则Keypoints对象会包含关键点的位置信息 keypoints = result.keypoints # 获取分类概率的输出结果,Probs对象包含了目标物体的分类概率信息 probs = result.probs # 获取有方向边界框(Oriented Bounding Box, OBB)的输出结果,如果模型支持此类输出,则Obb对象会包含相关信息 obb = result.obb # 在屏幕上显示检测结果图片 result.show() # 将检测结果图片保存到磁盘,文件名为'result.jpg' # 注意:如果有多张图片,后面的图片会覆盖前面的图片,因为文件名相同 # 如果需要保存不同的图片,应该为每个结果指定不同的文件名 result.save(filename='result.jpg')
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
对于目标检测,我们可以使用以下代码获得简要的结果信息。
# 模型预测
outputs = model2.predict(source='data_sorted\images/test/000025.jpg') # treat predict as a Python generator
# 检查输出结果,对于目标检测问题,这里我们检查boxes中数据,只需提取boxes中data即可获得全部数据:outputs[0].boxes
out1 = outputs[0].boxes.data
# data每一行数据为目标的xmin,ymin,xmax,ymax,prob,classes
out2 = outputs[0].names
# 标记了各种类对应的数字
- 1
- 2
- 3
- 4
- 5
- 6
- 7
YOLOv8模型结构简析
YOLOv8是一种先进的目标检测算法,它在YOLO系列的基础上进行了多项改进和优化,从而在精度和速度方面都实现了显著的提升。以下是对YOLOv8的详细介绍:
一、算法特点:
- 新的骨干网络:YOLOv8采用了一种新的骨干网络架构,这种架构有望提高特征提取和处理能力,从而有助于更准确的目标检测和分割。
- Anchor-Free检测头:与之前的YOLO版本相比,YOLOv8引入了Anchor-Free检测头,这意味着它不再依赖锚框,而是提供了更大的灵活性,可以更好地适应各种目标形状和大小。
- 全新的损失函数:为了进一步提升模型的收敛速度和性能表现,YOLOv8还采用了一种全新的损失函数。
- 多平台支持:YOLOv8具备在多平台运行的能力,包括CPU和GPU,这使得它可以在不同的硬件环境中都能表现出色。
二、性能表现:
- 实时性能:YOLOv8继续保持了YOLO系列的实时检测特性。即使在较低的硬件配置上,它也能达到很高的帧率(FPS),确保实时响应。
- 高准确度:通过更深更复杂的网络结构和改进的训练技巧,YOLOv8在保持高速度的同时,也大幅提高了检测的准确度。这使得它在各种应用场景中都能表现出色。
- 多尺度预测:YOLOv8引入了改进的多尺度预测技术,这使得它可以更好地检测不同大小的对象,提高了检测的灵活性和准确性。
三、应用领域:
YOLOv8在工业视觉识别领域有着广泛的应用。例如,在生产线上的物体进行准确检测和定位方面,它可以快速而准确地识别出物体,并给出其精确的位置信息,为后续的自动化操作提供有力支持。此外,它还可以应用于质量检测与控制、安全生产监控等多个方面,为工业生产提供全面的视觉识别解决方案。
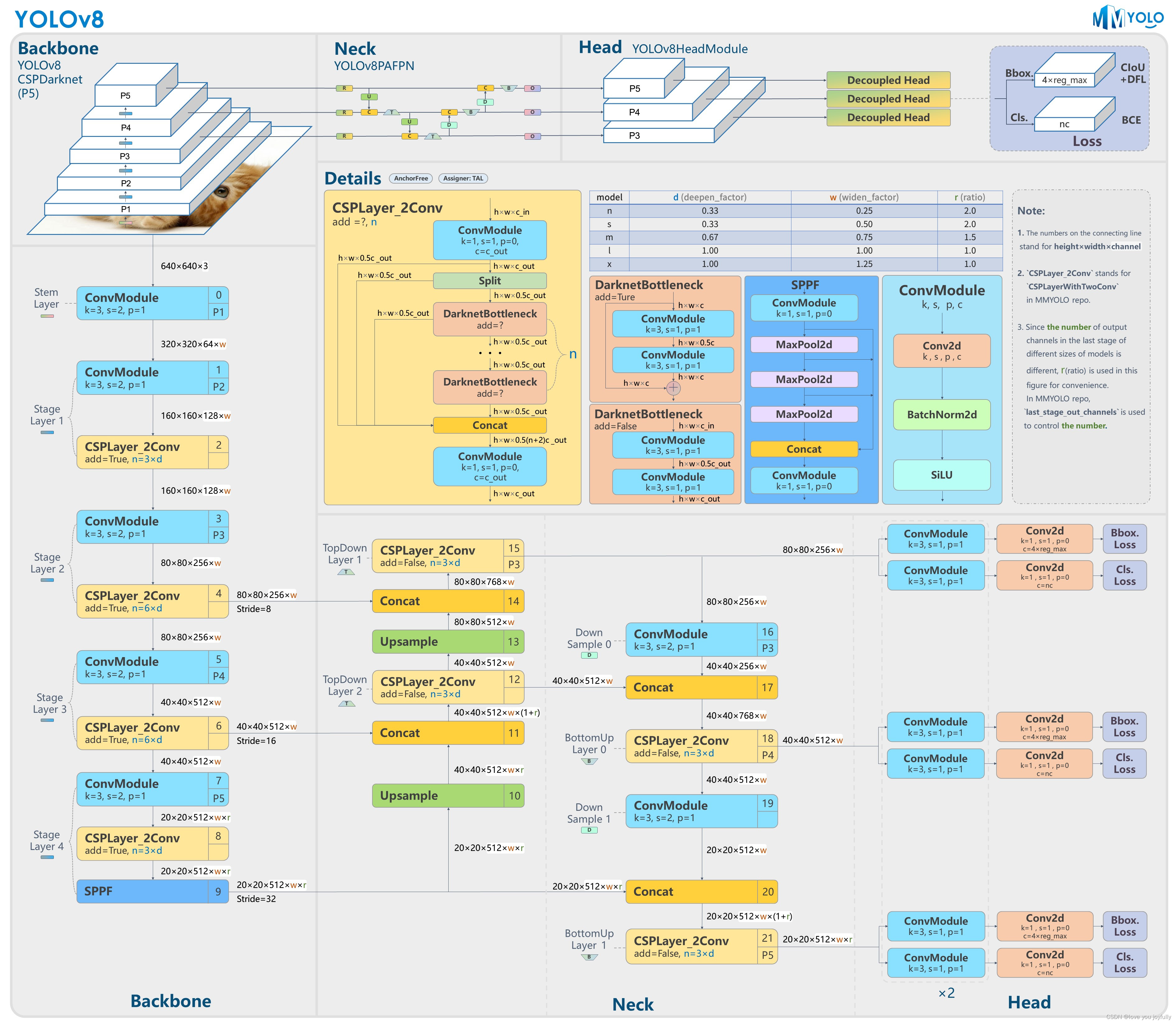
首先让我们总览一下模型整体结构

下方YOLOv8代码中使用到了这些库
# 需要有以下包:
import numpy as np
import torch
import torchvision
from PIL import Image
from torch import nn
from torch.nn import functional as F
from torch.utils import data
from torchvision import transforms
import math
from ultralytics import YOLO
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
1.Backbone部分
ultralytics.nn.modules.conv.Conv
Conv层代码如下所示:
这段代码定义了一个名为Conv的卷积层类,它继承自nn.Module。这个类主要用于初始化卷积层,包括卷积、批归一化和激活等操作。
首先,看到函数autopad(k, p=None, d=1),这个函数用于自动计算填充大小。如果p为None,则自动填充为k的一半(对于对称填充)。如果d大于1,那么会考虑膨胀卷积的情况,对k进行相应调整。
然后,在Conv类的__init__方法中,初始化了一个卷积层,其中的卷积核大小、步长、填充、组数、膨胀系数等参数由函数参数给出。这里使用了autopad(k, p, d)函数来自动计算填充大小。然后,初始化了一个批归一化层和一个激活函数。默认激活函数为SiLU,也可以通过参数传入其他激活函数。
在Conv类的forward方法中,对输入x执行卷积、批归一化和激活操作,然后返回结果。
另外,类中还有一个forward_fuse方法,它执行的是转置卷积操作,不过这个方法似乎没有在实际中使用。
需要注意的是,这个代码在PyTorch框架下使用,其中nn.Module是PyTorch中所有神经网络模块的基类,nn.Conv2d是二维卷积层,nn.BatchNorm2d是二维批归一化层,nn.SiLU是Sigmoid Linear Unit激活函数,nn.Identity是一个恒等映射,将输入直接输出。

def autopad(k, p=None, d=1): # kernel, padding, dilation """Pad to 'same' shape outputs.""" if d > 1: k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-size if p is None: p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad return p class Conv(nn.Module): """Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation).""" default_act = nn.SiLU() # default activation def __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True): """Initialize Conv layer with given arguments including activation.""" super().__init__() self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False) self.bn = nn.BatchNorm2d(c2) self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity() def forward(self, x): """Apply convolution, batch normalization and activation to input tensor.""" return self.act(self.bn(self.conv(x))) def forward_fuse(self, x): """Perform transposed convolution of 2D data.""" return self.act(self.conv(x))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
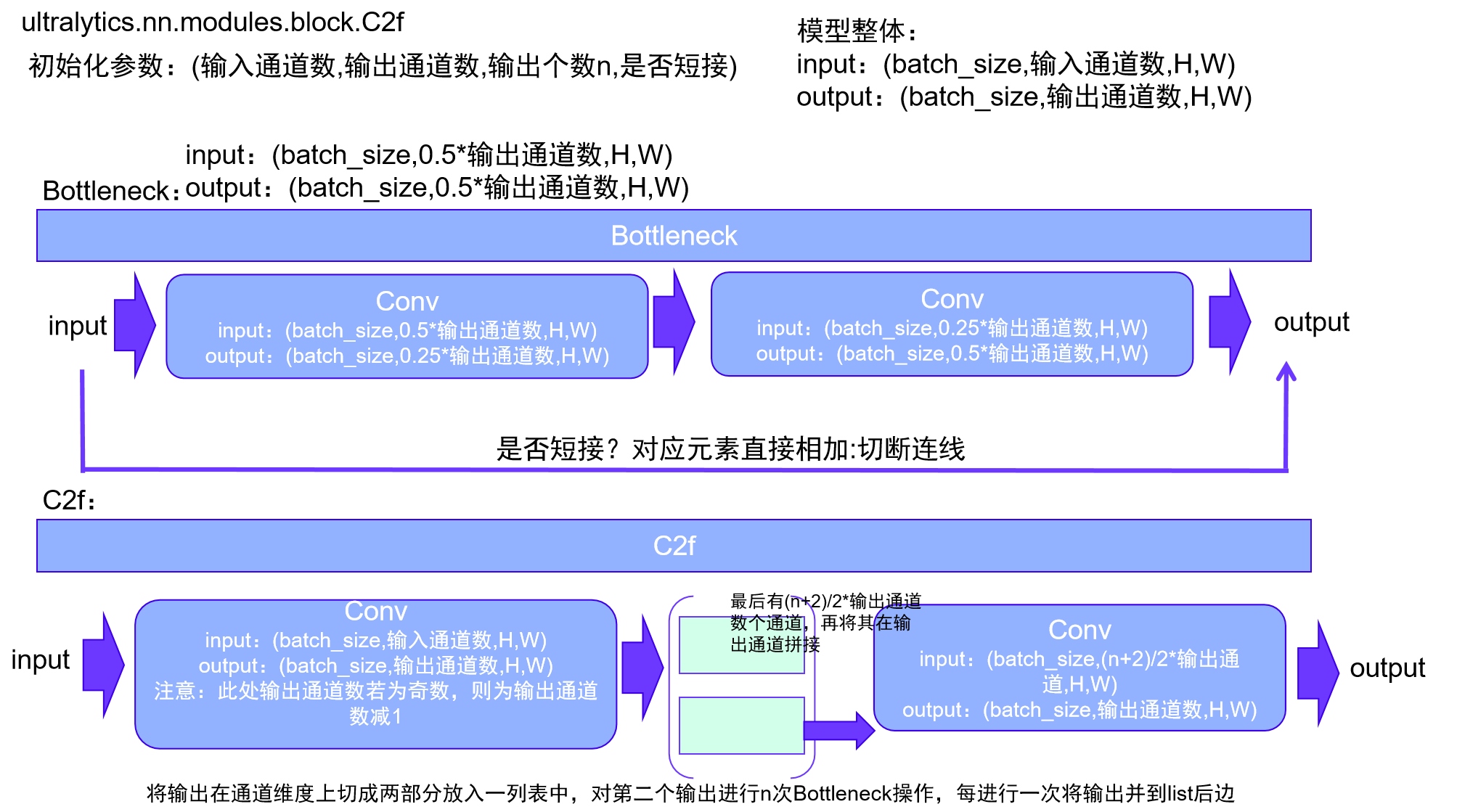
ultralytics.nn.modules.block.C2f
这段代码定义了两个PyTorch模块:Bottleneck和C2f。
1. Bottleneck类
这个类表示一个标准的bottleneck模块。
__init__方法用于初始化模块。输入参数有输入/输出通道数(c1,c2)、是否有shortcut连接、卷积的组数、卷积核大小和扩展因子等。c_计算了隐藏通道的数量。- 然后,初始化了两个Conv层(
self.cv1和self.cv2)。 self.add是一个布尔值,用于决定是否添加shortcut连接。
forward方法定义了数据的前向传播。如果self.add为True(即满足shortcut条件并且输入/输出通道数相同),则添加一个residual连接。
2. C2f类
这个类表示一个具有两个卷积的CSP(Cross Stage Partial,跨阶段局部)bottleneck模块。
__init__方法初始化了模块,参数类似于Bottleneck类,但增加了一个n参数,用于指定Bottleneck模块的数量。self.c计算了隐藏通道的数量。self.cv1和self.cv2是两个Conv层。self.m是一个包含多个Bottleneck模块的列表。
forward方法定义了数据的前向传播,通过使用chunk方法来分割张量。forward_split方法是一个备用的前向传播方法,使用split方法来代替chunk方法。
|
class Bottleneck(nn.Module): """Standard bottleneck.""" def __init__(self, c1, c2, shortcut=True, g=1, k=(3, 3), e=0.5): """Initializes a bottleneck module with given input/output channels, shortcut option, group, kernels, and expansion. """ super().__init__() c_ = int(c2 * e) # hidden channels # 隐藏层通道数 self.cv1 = Conv(c1, c_, k[0], 1) self.cv2 = Conv(c_, c2, k[1], 1, g=g) self.add = shortcut and c1 == c2 def forward(self, x): """'forward()' applies the YOLO FPN to input data.""" return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x)) class C2f(nn.Module): """Faster Implementation of CSP Bottleneck with 2 convolutions.""" def __init__(self, c1, c2, n=1, shortcut=False, g=1, e=0.5): """Initialize CSP bottleneck layer with two convolutions with arguments ch_in, ch_out, number, shortcut, groups, expansion. """ super().__init__() self.c = int(c2 * e) # hidden channels self.cv1 = Conv(c1, 2 * self.c, 1, 1) self.cv2 = Conv((2 + n) * self.c, c2, 1) # optional act=FReLU(c2) self.m = nn.ModuleList(Bottleneck(self.c, self.c, shortcut, g, k=((3, 3), (3, 3)), e=1.0) for _ in range(n)) def forward(self, x): """Forward pass through C2f layer.""" y = list(self.cv1(x).chunk(2, 1)) y.extend(m(y[-1]) for m in self.m) return self.cv2(torch.cat(y, 1)) def forward_split(self, x): """Forward pass using split() instead of chunk().""" y = list(self.cv1(x).split((self.c, self.c), 1)) y.extend(m(y[-1]) for m in self.m) return self.cv2(torch.cat(y, 1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
ultralytics.nn.modules.block.SPPF
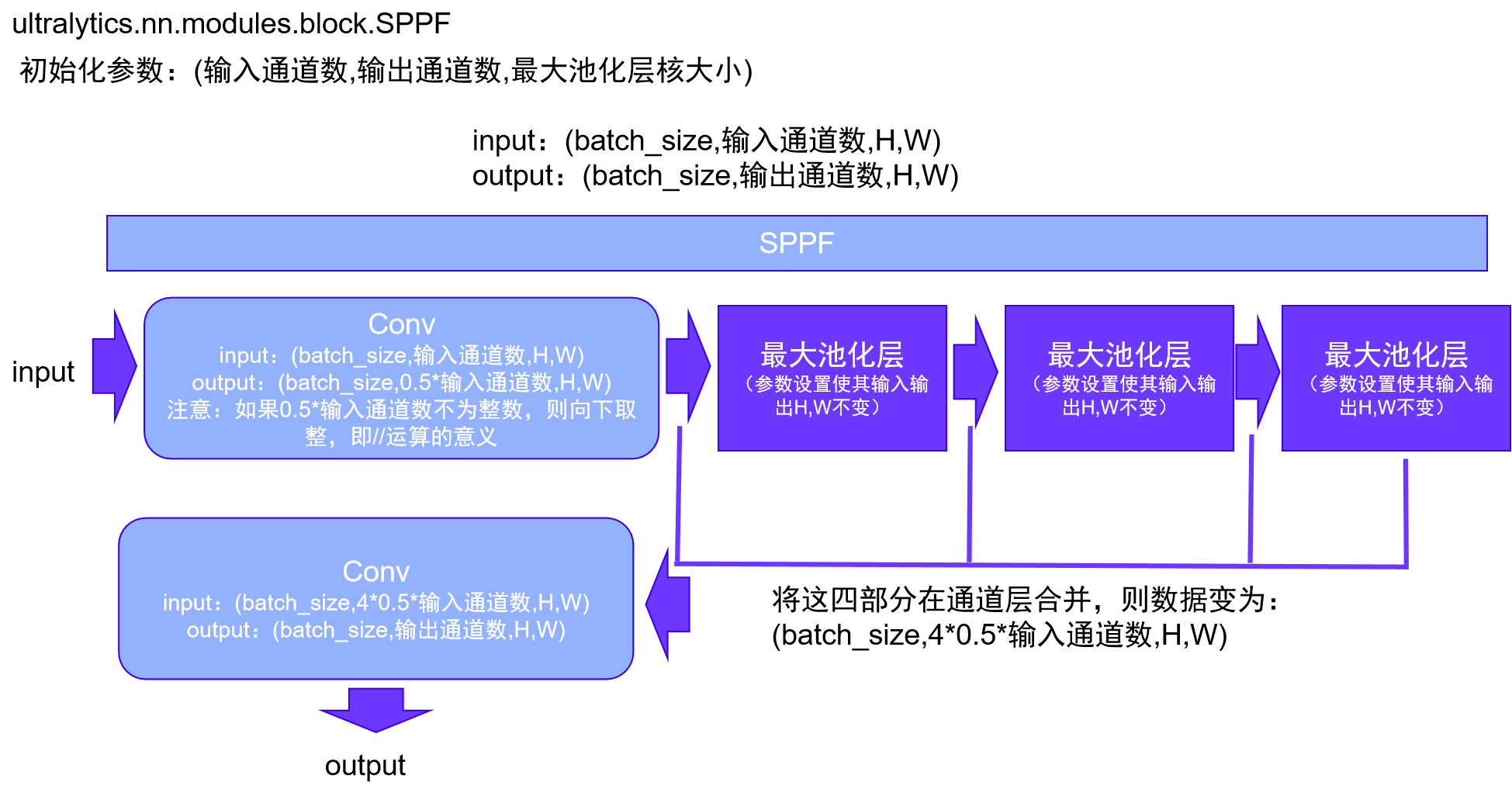
这段代码定义了一个名为SPPF的PyTorch模块,表示空间金字塔池化-快速(Spatial Pyramid Pooling - Fast)层,这个层是为YOLOv5设计的,由Glenn Jocher提出。
初始化方法 __init__
c1和c2是输入和输出通道数。k是池化核的大小,默认为5。c_计算了隐藏通道的数量,它是c1的一半。self.cv1和self.cv2是两个卷积层,其中self.cv1的输入通道数为c1,输出通道数为c_;self.cv2的输入通道数为c_ * 4,输出通道数为c2。self.m是一个最大池化层,其池化核大小为k,步长为1,填充为k // 2。
前向传播方法 forward
- 输入
x首先经过self.cv1卷积层。 y1是x经过最大池化层self.m后的结果。y2是y1再次经过最大池化层self.m后的结果。- 最后,将
x,y1,y2, 和self.m(y2)在通道维度上拼接(concatenation),并经过self.cv2卷积层,然后返回结果。
这个模块的目的是通过多个不同大小的最大池化操作来捕获不同尺度的特征。这些特征被拼接在一起并通过一个卷积层进行融合,从而得到最终的输出。
需要注意的是,这里使用的是一种特殊的设计,即空间金字塔池化(Spatial Pyramid Pooling, SPP),这是一种经典的计算机视觉技术,用于在不同尺度上提取特征。这种设计可以提高神经网络对输入尺度变化的鲁棒性。
|
class SPPF(nn.Module): """Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher.""" def __init__(self, c1, c2, k=5): """ Initializes the SPPF layer with given input/output channels and kernel size. This module is equivalent to SPP(k=(5, 9, 13)). """ super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * 4, c2, 1, 1) self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x): """Forward pass through Ghost Convolution block.""" x = self.cv1(x) y1 = self.m(x) y2 = self.m(y1) return self.cv2(torch.cat((x, y1, y2, self.m(y2)), 1))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
2.Neck部分
torch.nn.modules.upsampling.Upsample
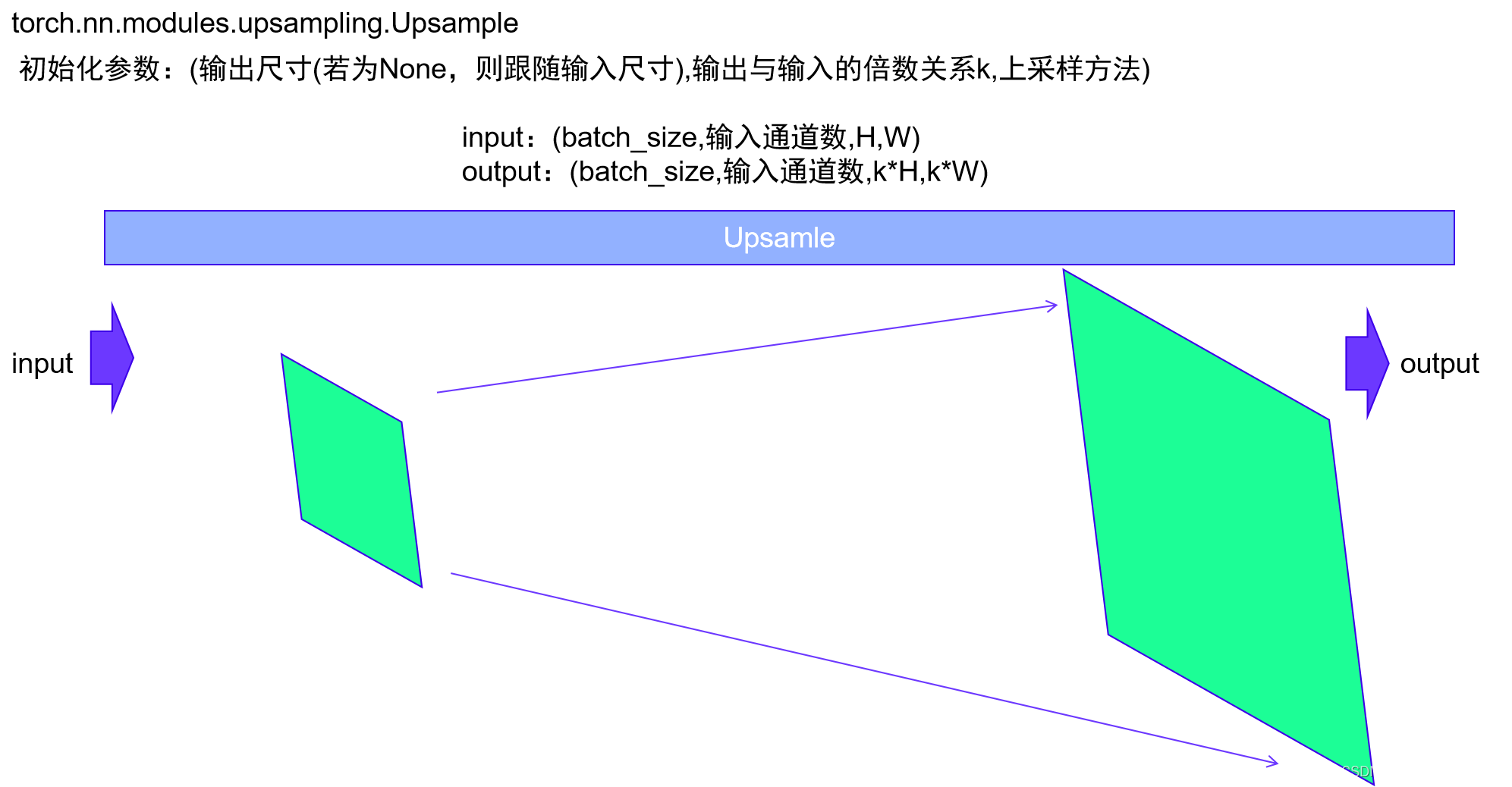
torch.nn.Upsample是PyTorch中的一个模块,用于上采样(或增加)输入张量的分辨率。这在许多计算机视觉任务中是非常有用的,例如在语义分割或生成模型中。
该模块的主要参数包括:
size:输出大小。它可以是一个整数或者一个整数元组,取决于输入张量的维度。例如,对于二维输入,它可以是一个二元组(H,W)。scale_factor:输出与输入的倍数关系。同样,它可以是一个浮点数或者一个浮点数元组,取决于输入张量的维度。只有当使用的算法为“linear”,“bilinear”或“trilinear”时,才可以使用这个参数。mode:上采样算法,可选的有“nearest”,“linear”,“bilinear”,“bicubic”和“trilinear”。默认是“nearest”。align_corners:如果设为True,输入的角像素将与输出张量对齐,这样就可以保留这些像素的值。默认是False。
在实际应用中,你可以根据需要选择合适的参数进行上采样。需要注意的是,上采样通常会增加计算复杂度,因此在使用时需要考虑计算资源的平衡。
|
# 调用torch.nn库Upsample模型即可,详细模型结构可见torch包或models\modules_torch\upsampling.py
# yolov8n中应用该层参数均为:[None, 2, 'nearest']
layer_upsample = nn.Upsample(size=None, scale_factor=2, mode="nearest")
# 让我们设计一个张量看看该层的输入输出尺寸吧
x_test = torch.rand(1, 3, 10, 10)
x_testout = layer_upsample(x_test)
x_testout.shape
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
torch.Size([1, 3, 20, 20])
- 1
ultralytics.nn.modules.conv.Concat
该层很简单,对应yolov8n来说,就是将输入张量列表在通道维度上拼接在一起。
class Concat(nn.Module):
"""Concatenate a list of tensors along dimension."""
def __init__(self, dimension=1):
"""Concatenates a list of tensors along a specified dimension."""
super().__init__()
self.d = dimension
def forward(self, x):
"""Forward pass for the YOLOv8 mask Proto module."""
return torch.cat(x, self.d)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.Head部分
ultralytics.nn.modules.head.Detect
本文只简要介绍目标检测部分的头:Detect。该头负责将检测结果转换为预测框和类别。训练详细流程见:
https://zhuanlan.zhihu.com/p/633094573
Detect层详细介绍可见:
https://blog.csdn.net/yjcccccc/article/details/130261153
3.1.DFL解释
这段代码定义了一个名为DFL的PyTorch模块,表示分布焦点损失(Distribution Focal Loss)的积分模块。该模块是基于广义焦点损失(Generalized Focal Loss)论文中提出的概念。论文地址:https://ieeexplore.ieee.org/document/9792391
初始化方法 __init__
c1是输入通道数,默认为16。- 使用
nn.Conv2d初始化一个卷积层self.conv,其中输入通道数为c1,输出通道数为1,卷积核大小为1,且不使用偏置(bias)。并设置该层不需要进行梯度更新。 - 创建一个从0到
c1-1的浮点数张量x,并将其形状调整为(1, c1, 1, 1)以满足卷积层的权重形状要求。 - 使用
nn.Parameter将张量x转换为模型参数,并将其赋值给self.conv.weight.data。这使得该张量成为模型的一部分,并在训练过程中保持不变。 - 保存输入通道数
c1到实例变量中。
前向传播方法 forward
- 输入
x的预期形状是(batch, channels, anchors),分别表示批次大小、通道数和锚点(anchors)数。 - 对输入张量
x进行形状变换和转置操作,使其在通道维度上分成4等分,并且每个部分包含self.c1个通道。这对应于将输入锚点(anchors)的预测分布转换为4个部分。 - 对变换后的张量在第二个维度(索引为1)上应用softmax函数,以得到每个部分的概率分布。
- 最后,通过卷积层
self.conv进行卷积操作,然后恢复到形状(batch, 4, anchors)。
注:这里有两个返回语句,其中一个是被注释掉的。在真实场景中,应该只有一个有效的返回语句。
这个模块的目的是将输入的锚点(anchors)预测分布进行变换,并通过卷积操作得到最终的输出。由于卷积层的权重是一个固定的递增序列,因此输出的每一部分都对应于输入的一个特定范围。通过softmax操作,输出表示了输入锚点属于每个范围的概率分布。这样的设计有助于更精细地预测目标的位置和形状信息。
3.2.make_anchors方法
初始化:函数首先初始化两个空的列表,一个用于存储所有的锚点,另一个用于存储与每个特征图相关的步长。
遍历每个特征图:对于传入的每一个特征图,函数会进行以下操作:
* 获取特征图的高度和宽度。
* 创建x和y轴的偏移量,这可以理解为在每个网格单元上的中心点偏移。
* 利用meshgrid生成二维网格,每个网格点对应一个潜在的锚点。
* 将这些点添加到`anchor_points`列表中,并将与特征图相关的步长添加到另一个列表中。
- 1
- 2
- 3
- 4
返回结果:函数最后会拼接所有的锚点以及步长,并返回这两个张量。
3.3.dist2bbox方法
dist2bbox函数执行了一个核心任务:将相对于锚点的距离转换为实际的边界框坐标。
在目标检测中,我们经常会知道某个框相对于锚点的距离,而不是绝对的坐标位置。这个函数就是用来进行这种转换的。它取这些距离值,结合锚点的位置,然后计算出边界框的实际坐标。
函数还提供了一个xywh参数,允许用户选择返回的边界框的格式。如果xywh为True(默认),则返回的框坐标为中心点加上宽和高;如果为False,则返回的是左上角的坐标和右下角的坐标。
总之,该函数是一个实用工具,用于在目标检测任务中根据相对距离得到实际的边界框坐标。
# 该头部分的实现相对较为复杂,本文结合yolov8n使用源代码定义介绍一下头的用法。 # yolov8n初始化头参数为:[80, [64, 128, 256]] # 即:图片中包含的需要检测的类别有80种,输入Detect层的数据的通道数分别为62,28,56 class Detect(nn.Module): """YOLOv8 Detect head for detection models.""" dynamic = False # force grid reconstruction export = False # export mode shape = None anchors = torch.empty(0) # init strides = torch.empty(0) # init def __init__(self, nc=80, ch=()): """Initializes the YOLOv8 detection layer with specified number of classes and channels.""" super().__init__() self.nc = nc # number of classes种类个数 self.nl = len(ch) # number of detection layers有多少个检测层,即输入的ch通道数为一列表,列表中有多少个数据意味着有多少个 # Detect层需要做 self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x) self.no = nc + self.reg_max * 4 # number of outputs per anchor self.stride = torch.zeros(self.nl) # strides computed during build c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels参数:设定的通道数 self.cv2 = nn.ModuleList( nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch) # 做一个模型列表,列表中内容数量为检测层数量,对于每一个输入,结合该输入的通道数x,将其通过 # Conv,Conv,nn.Conv2d三层,最后输出通道数为4 * self.reg_max=64. self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch) # 做一个模型列表,列表中内容数量为检测层数量,对于每一个输入,结合该输入的通道数x,将其通过 # Conv,Conv,nn.Conv2d三层,最后输出通道数为self.nc种类数. self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity() def forward(self, x): """Concatenates and returns predicted bounding boxes and class probabilities.""" shape = x[0].shape # BCHW:batch_size,通道数,H,W,此时,shape为(batch_size,通道数,H,W) for i in range(self.nl): x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1) # 对于每一项输入,将其通过cv2,cv3层后将结果在通道层连接起来,最后输出后 # x的每一项的尺寸最后均为(batch_size,4*self.reg_max+self.nc(64+80=144),H,W) if self.training: # 处于训练的时候,直接返回此时的x return x elif self.dynamic or self.shape != shape: # 对于之前x的每一项,我们视该项为一个特征图,对于yolov8来说,此处有3个特征图 # 对于每个特征图,我们结合特征图的长宽,生成锚点,将其放到anchors中, # stride为步长 self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5)) self.shape = shape x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2) if self.export and self.format in ('saved_model', 'pb', 'tflite', 'edgetpu', 'tfjs'): # avoid TF FlexSplitV ops box = x_cat[:, :self.reg_max * 4] cls = x_cat[:, self.reg_max * 4:] else: box, cls = x_cat.split((self.reg_max * 4, self.nc), 1) dbox = dist2bbox(self.dfl(box), self.anchors.unsqueeze(0), xywh=True, dim=1) * self.strides if self.export and self.format in ('tflite', 'edgetpu'): # Normalize xywh with image size to mitigate quantization error of TFLite integer models as done in YOLOv5: # https://github.com/ultralytics/yolov5/blob/0c8de3fca4a702f8ff5c435e67f378d1fce70243/models/tf.py#L307-L309 # See this PR for details: https://github.com/ultralytics/ultralytics/pull/1695 img_h = shape[2] * self.stride[0] img_w = shape[3] * self.stride[0] img_size = torch.tensor([img_w, img_h, img_w, img_h], device=dbox.device).reshape(1, 4, 1) dbox /= img_size y = torch.cat((dbox, cls.sigmoid()), 1) return y if self.export else (y, x) def bias_init(self): """Initialize Detect() biases, WARNING: requires stride availability.""" m = self # self.model[-1] # Detect() module # cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1 # ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency for a, b, s in zip(m.cv2, m.cv3, m.stride): # from a[-1].bias.data[:] = 1.0 # box b[-1].bias.data[:m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img) class DFL(nn.Module): """ Integral module of Distribution Focal Loss (DFL). Proposed in Generalized Focal Loss https://ieeexplore.ieee.org/document/9792391 """ def __init__(self, c1=16): """Initialize a convolutional layer with a given number of input channels.""" super().__init__() self.conv = nn.Conv2d(c1, 1, 1, bias=False).requires_grad_(False) x = torch.arange(c1, dtype=torch.float) self.conv.weight.data[:] = nn.Parameter(x.view(1, c1, 1, 1)) self.c1 = c1 def forward(self, x): """Applies a transformer layer on input tensor 'x' and returns a tensor.""" b, c, a = x.shape # batch, channels, anchors return self.conv(x.view(b, 4, self.c1, a).transpose(2, 1).softmax(1)).view(b, 4, a) # return self.conv(x.view(b, self.c1, 4, a).softmax(1)).view(b, 4, a) def dist2bbox(distance, anchor_points, xywh=True, dim=-1): """Transform distance(ltrb) to box(xywh or xyxy).""" lt, rb = distance.chunk(2, dim) x1y1 = anchor_points - lt x2y2 = anchor_points + rb if xywh: c_xy = (x1y1 + x2y2) / 2 wh = x2y2 - x1y1 return torch.cat((c_xy, wh), dim) # xywh bbox return torch.cat((x1y1, x2y2), dim) # xyxy bbox def make_anchors(feats, strides, grid_cell_offset=0.5): """Generate anchors from features."""# 从特征产生锚点 anchor_points, stride_tensor = [], [] assert feats is not None dtype, device = feats[0].dtype, feats[0].device for i, stride in enumerate(strides): _, _, h, w = feats[i].shape sx = torch.arange(end=w, device=device, dtype=dtype) + grid_cell_offset # shift x sy = torch.arange(end=h, device=device, dtype=dtype) + grid_cell_offset # shift y sy, sx = torch.meshgrid(sy, sx) anchor_points.append(torch.stack((sx, sy), -1).view(-1, 2)) stride_tensor.append(torch.full((h * w, 1), stride, dtype=dtype, device=device)) return torch.cat(anchor_points), torch.cat(stride_tensor)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
Paddle平台YOLO模型
飞桨PaddlePaddle是百度推出的深度学习平台,提供动静统一的框架设计,支持高效的深度学习应用开发和大规模分布式训练,拥有丰富的模型库和工具组件。在paddle模型库中,提供了一些YOLO模型,方便训练与部署。https://aistudio.baidu.com/modelsoverview?sortBy=weight&q=yolo


