
- 1java无法验证证书_在java中验证证书会引发异常 – 无法找到所请求目标的有效证书路径...
- 2yolov5,7,8,9 官方模型对比_为啥用yolov5而不用v7v8
- 3《程序员你伤不起》读书总结
- 4ChatGPT vs 文心一言: 两大AI助手的较量_研发助手chatgpt
- 5mysql 去重_mysql去重语句
- 6MAC环境下 搭建Flutter运行环境_flutter mac 刷新终端命令
- 7Wind Python案例_windpy
- 8数据结构之快排算法以及力扣相关例题_力扣快速排序题
- 95年测试岗,自动化测试经验总结(真实)他的测试之路高歌猛进..._写自动化测试脚本,一个功能需要写多久
- 10spark的安装与部署_spark安装
【Darknet】【yolo v2】训练自己数据集的一些心得----VOC格式(经典YOLO训练心得)_darknet yolov2.weight
赞
踩
------【2017.11.2更新】------------SSD传送门----------
http://blog.csdn.net/renhanchi/article/details/78411095
http://blog.csdn.net/renhanchi/article/details/78423343
-------【2017.10.30更新】------------一些要说的-----------
虽然写完这篇博客后我几乎再没使用darknet和yolo,但这半年多我一直在不断更新这篇博客,也在不断为大家解决问题。
如果你想通过这篇博客学习使用darknet和yolo,包括一些detection的知识,我希望你能仔细、认真的读本文的每一句话。
-------------------------------------------------------------------------
最近发现作者代码改动很大,导致很多地方跟我写的博客内容都不一样了。我现在把我当初下载的darknet打包给大家。
新老版本的区别在于代码,算法架构还是一样的,所以放心使用老版本。
解压缩后进入目录,配置好Makefile后直接make all就可以了。
https://pan.baidu.com/s/1jIR2oTo
1. 前言
关于用yolo训练自己VOC格式数据的博文真的不少,但是当我按照他们的方法一步一步走下去的时候发现出了其他作者没有提及的问题。这里就我自己的经验讲讲如何训练自己的数据集。
2.数据集
这里建议大家用VOC和ILSVRC比赛的数据集,因为xml文件都是现成的,省去很多功夫。
想自己标记的可以自己去github搜索 labelImg , 下载好make后直接运行就可以。具体使用方法先不做赘述。
也可以直接去下载现成的数据集
ILSVRC2015比赛的地址是: http://image-net.org/challenges/LSVRC/2015/download-images-3j16.php
VOC 比赛地址是: http://host.robots.ox.ac.uk/pascal/VOC/index.html
我的数据集是把VOC2007,VOC2012,ILSVRC2013和ILSVRC2014所有关于人的数据集单独拿了出来,我只想做单独检测人的训练。注意ILSVRC后缀名是JPEG的,可以自己改成jpg,也可以不改,因为darknet代码里也兼容JPEG格式。但为了以后省事儿,我是都给改成jpg后缀名了。
关于怎么把VOC所有关于人的数据集单独拿出来,大家可以用下面这个shell脚本,稍微改一改就也能用来提取ILSVRC的数据。ILSVRC数据集里面人的类别不是person,是n00007846,这个在xml文件里不影响后面的训练,所以大家也不需要特意把n00007846都改成person。原因是labels.txt文件里面是用数字0,1,2,3等等表示类别的,而不是单词。这些数字是对应data/names.list 里面类别的索引。
-
#!/bin/sh -
year="VOC2012" -
mkdir /your_path/VOCperson/${year}_Anno/ #创建文件夹 -
mkdir /your_path/VOCperson/${year}_Image/ -
cd /your_path/VOCdevkit/$year/Annotations/ -
grep -H -R "<name>person</name>" > /your_path/VOCperson/temp.txt #找到有关键字的行,并把这些行存到临时文档 -
cd /your_path/VOCperson/ -
cat temp.txt | sort | uniq > $year.txt #根据名字排序,并把相邻的内容完全一样的多余行删除。 -
find -name $year.txt | xargs perl -pi -e 's|.xml:\t\t<name>person</name>||g' #把文档中后缀名和其他无用信息删掉,只保留没后缀名的文件名 -
cat $year.txt | xargs -i cp /your_path/VOCdevkit/$year/Annotations/{}.xml /your_path/VOCperson/${year}_Anno/ #根据文件名复制注释文件 -
cat $year.txt | xargs -i cp /your_path/VOCdevkit/$year/JPEGImages/{}.jpg /your_path/VOCperson/${year}_Image/ #根据文件名复制数据集 -
rm temp.txt
3.训练文件
3.1 文件夹设置
Annotations ---- 这个文件夹是放所有xml描述文件的。
JPEGImages ---- 这个文件夹是放所有jpg图片文件的。
ImageSets -> Main ---- 这个文件里放一个names.txt文档(我的这个文档的名字是:train.txt,注意这个名字要跟下面python代码中列表sets的第二个元素内容一致),文档内容是所有训练集图片的名字,没有后缀名。
PS: 官网自带的训练VOC方法里面图片是分别放在2007和2012两个不同路径的,我觉得麻烦,就一股脑把所有文件都放在一个文件里面了。
3.2 txt文档
一共需要准备三种txt文档:
先是上面提到的在ImageSets文件下所有训练数据名的names.txt文档。
然后是所有图片一一对应的labels.txt。这些文档是通过scripts/voc_label.py 这个文件生成的,里面路径是要改一改的。我把所有图片文件和xml文件都分别放到一个文件夹下了,而且训练类别只有person。所以开头的sets和classes,也是需要改的。这里值得注意的是如果你是用的ILSVRC数据集,并且你也和我一样懒懒的没有把xml文件里面的n00007846改成人的话,那么你需要把classes改成n00007846这样才能找到关于这一类别的bbox信息。还有一点需要注意,就是ILSVRC数据集的xml文件里面没有difficult这个信息,所以.py文件里关于这一点的东西注释掉就好了。
最后是保存有所有训练图片绝对路径的paths.txt文档。注意这个文档里面图片文件名是带jpg后缀名的。生成上面labels.txt文档的时候最后会自动生成paths.txt。
下面是我的.py文件
-
import xml.etree.ElementTree as ET -
import pickle -
import os -
from os import listdir, getcwd -
from os.path import join -
sets=[('person','train')] -
classes = ["n00007846"] -
def convert(size, box): -
dw = 1./(size[0]) -
dh = 1./(size[1]) -
x = (box[0] + box[1])/2.0 - 1 -
y = (box[2] + box[3])/2.0 - 1 -
w = box[1] - box[0] -
h = box[3] - box[2] -
x = x*dw -
w = w*dw -
y = y*dh -
h = h*dh -
return (x,y,w,h) -
def convert_annotation(year, image_id): -
in_file = open('/home/hans/darknet/person/VOC%s/Annotations/%s.xml'%(year, image_id)) -
out_file = open('/home/hans/darknet/person/VOC%s/labels/%s.txt'%(year, image_id), 'w') -
tree=ET.parse(in_file) -
root = tree.getroot() -
size = root.find('size') -
w = int(size.find('width').text) -
h = int(size.find('height').text) -
for obj in root.iter('object'): -
# difficult = obj.find('difficult').text -
cls = obj.find('name').text -
if cls not in classes: # or int(difficult)==1: -
continue -
cls_id = classes.index(cls) -
xmlbox = obj.find('bndbox') -
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), -
float(xmlbox.find('ymax').text)) -
bb = convert((w,h), b) -
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n') -
wd = getcwd() -
for year, image_set in sets: -
if not os.path.exists('/home/hans/darknet/person/VOC%s/labels/'%(year)): -
os.makedirs('/home/hans/darknet/person/VOC%s/labels/'%(year)) -
image_ids = open('/home/hans/darknet/person/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split() -
list_file = open('%s_%s.txt'%(year, image_set), 'w') -
for image_id in image_ids: -
list_file.write('%s/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id)) -
convert_annotation(year, image_id) -
list_file.close()
3.3 训练配置文件
先是在data文件夹下创建一个person.names文件,内容只有person。
然后是修改cfg文件夹下voc.data文件,classes改成1。 train对应的路径是上文的paths.txt。 names对应路径是person.names文件的。backup对应路径是备份训练权重文件的。
最后是选取.cfg网络,在darknet官网还有很多博文里面都是用的yolo-voc.cfg,我用这个网络训练一直失败。体现在训练好久后test,没有bbox和predict结果。出现这种问题有两种情况,一是训练发散了。二是训练不充分,predict结果置信概率太低。对于训练发散,其实很容易发现的,就是在训练的时候观察迭代次数后边的两个loss值,如果这两个值不断变大到几百就说明训练发散啦。可以通过降低learning rate 和 提高batch数量解决这个问题。关于参数修改和训练输出分别表示什么意思我会在后文提及。 对于训练不充分的时候如何显示出predict结果,可以在test的时候设置threshold,darknet默认是.25,你可以尝试逐渐降低这个值看效果。
./darknet detector test cfg/voc.data cfg/yolo_voc.cfg -thresh 0.25
当时对darknet理解还不够深,出现上面问题当时我解决不了的时候,我换成了现在用的yolo-voc.2.0.cfg 这个网络。关于里面的参数我简单说说:
batch: 每一次迭代送到网络的图片数量,也叫批数量。增大这个可以让网络在较少的迭代次数内完成一个epoch。在固定最大迭代次数的前提下,增加batch会延长训练时间,但会更好的寻找到梯度下降的方向。如果你显存够大,可以适当增大这个值来提高内存利用率。这个值是需要大家不断尝试选取的,过小的话会让训练不够收敛,过大会陷入局部最优。
subdivision:这个参数很有意思的,它会让你的每一个batch不是一下子都丢到网络里。而是分成subdivision对应数字的份数,一份一份的跑完后,在一起打包算作完成一次iteration。这样会降低对显存的占用情况。如果设置这个参数为1的话就是一次性把所有batch的图片都丢到网络里,如果为2的话就是一次丢一半。
angle:图片旋转角度,这个用来增强训练效果的。从本质上来说,就是通过旋转图片来变相的增加训练样本集。
saturation,exposure,hue:饱和度,曝光度,色调,这些都是为了增强训练效果用的。
learning_rate:学习率,训练发散的话可以降低学习率。学习遇到瓶颈,loss不变的话也减低学习率。
max_batches: 最大迭代次数。
policy:学习策略,一般都是step这种步进式。
step,scales:这两个是组合一起的,举个例子:learn_rate: 0.001, step:100,25000,35000 scales: 10, .1, .1 这组数据的意思就是在0-100次iteration期间learning rate为原始0.001,在100-25000次iteration期间learning rate为原始的10倍0.01,在25000-35000次iteration期间learning rate为当前值的0.1倍,就是0.001, 在35000到最大iteration期间使用learning rate为当前值的0.1倍,就是0.0001。随着iteration增加,降低学习率可以是模型更有效的学习,也就是更好的降低train loss。
最后一层卷积层中filters数值是 5×(类别数 + 5)。具体原因就不多说了,知道就好哈。
region里需要把classes改成你的类别数。
最后一行的random,是一个开关。如果设置为1的话,就是在训练的时候每一batch图片会随便改成320-640(32整倍数)大小的图片。目的和上面的色度,曝光度等一样。如果设置为0的话,所有图片就只修改成默认的大小 416*416。(2018.04.08更新,评论给里有朋友说这里如果设置为1的话,训练的时候obj和noobj会出现全为0的情况,设置为0后一切正常。)
3.4 开始训练
可以自己去下载pre_trained文件来提高自己的训练效率。
以上所有准备工作做好后就可以训练自己的模型了。
terminal 运行:
./darknet detector train cfg/voc.data cfg/yolo_voc.cfg darknet19_448.conv.23
-------- 【2017.06.29更新】---------新版本源代码被作者做了很大改动,老版本的可以看看下面内容--------------------------------------
这里有一点我还是要说一下, 其他博文有让我们修改.c源文件。其实这个对于我等懒人是真的不用修改的。原因是这样的,在官网里有一段执行test的代码是:
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg
这是一段简写的执行语句。它的完整形式是这样的:
./darknet detector test cfg/coco.data cfg/yolo.cfg yolo.weights data/dog.jpg
其实修改.c文件的作用就是让我们可以使用简写的test执行语句,程序会自动调用.c里面设置好的路径内容。我个人觉得这个很没有必要。还有就是最新的版本中已经没有yolo.cu这个文件了。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------
4.训练输出
这里我讲一讲关于输出的东西都是些什么东西,有些我也不太懂,只挑些有用的,我懂得讲讲。
Region Avg IOU: 这个是预测出的bbox和实际标注的bbox的交集 除以 他们的并集。显然,这个数值越大,说明预测的结果越好。
Avg Recall: 这个表示平均召回率, 意思是 检测出物体的个数 除以 标注的所有物体个数。
count: 标注的所有物体的个数。 如果 count = 6, recall = 0.66667, 就是表示一共有6个物体(可能包含不同类别,这个不管类别),然后我预测出来了4个,所以Recall 就是 4 除以 6 = 0.66667 。
有一行跟上面不一样的,最开始的是iteration次数,然后是train loss,然后是avg train loss, 然后是学习率, 然后是一batch的处理时间, 然后是已经一共处理了多少张图片。 重点关注 train loss 和avg train loss,这两个值应该是随着iteration增加而逐渐降低的。如果loss增大到几百那就是训练发散了,如果loss在一段时间不变,就需要降低learning rate或者改变batch来加强学习效果。当然也可能是训练已经充分。这个需要自己判断。
5.可视化
这里我给大家分享一个关于loss可视化的matlab代码。可以很直观的看到你的loss的变化曲线。
首先在训练的时候,可以通过script命令把terminal的输出都录像到一个txt文档中。
script -a log.txt./darknet detector train cfg/voc.data cfg/yolo_voc.cfg darknet19_448.conv.23训练完成后记得使用ctrl+D或者输入exit结束屏幕录像。
下面是matlab代码:
-
clear; -
clc; -
close all; -
train_log_file = 'log.txt'; -
[~, string_output] = dos(['cat ', train_log_file, ' | grep "avg," | awk ''{print $3}''']); -
train_loss = str2num(string_output); -
n = 1:length(train_loss); -
idx_train = (n-1); -
figure;plot(idx_train, train_loss); -
grid on; -
legend('Train Loss'); -
xlabel('iterations'); -
ylabel('avg loss'); -
title(' Train Loss Curve');
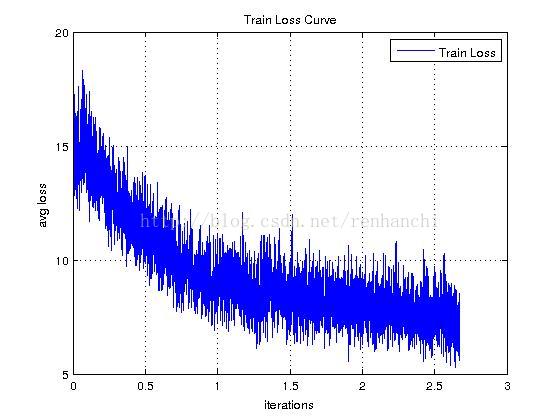
我画的是avg train loss的曲线图。我这里batch为8,曲线震荡幅度很大。学习率是0.0001,25000次迭代后降到0.00001,。大家注意看后面loss趋于稳定在7-8左右降低就不明显,并且趋于不变了。我的理解是可能遇到两种情况,一是陷入局部最优,二是学习遇到瓶颈。但没有解决这个问题。降低batch,提高学习效果,loss不变。提高batch,让网络更顾全全局,loss降低一点点,继续不变。降低学习率提高学习效果,降低一点点,继续不变。希望有大神看到此文请予以指教。25000次迭代后有一点下降是因为我降低了learning rate,但降低不明显,而且很快就又趋于平稳了。训练集4.3W+,是从ILSVRC2015训练集和VOC2012训练集中挑出来的所有关于人的数据。
-----------【2017.09.26更新】-----------------
一直犯懒没有写这个补充说明, 上面我说可能陷入局部最优. 做了很多工作并没有提升. 我当时一直用caffe的loss标准来对待darknet, 其实这个有很大问题. 因为两种框架输出loss并不一定是相同单位的. 其实我上面训练好的模型的实际使用效果是非常非常好的, 远远的一颗小小人头都能检测的到.
并且现在看上面训练参数应该可以有所改进, 我在这里记一下如果以后再次用到darknet的话方便查阅. 因为做的finetune, 学习率很低这个没毛病, 但是相应momentum可以考虑适当增加, 从0.9调整到0.99. 还可以考虑将学习策略改成poly.
-------------------------------------------------------------
-----------【2017.10.30更新】------------------------
最近开始着手做一些detection 的东西,回过头来看darknet,再纠正一点。对于detection而言,应该不要盲目用loss来评判一个模型的好坏。loss应该用作在训练当中判断训练是否正常进行。比如训练一开始loss一直升高,最后NAN,说明学习率大了。那我们要用哪个数值来评判模型的好坏呢?应该是mAP,这个应该是当前主流标准,其实就是平均的precision。在darknet训练过程中并不输出precision的结果,所以我们也可以通过recall来判断。recall越接近1.0,就说明模型检测到实际的物体数量越准确。如果用老版本的darknet,并通过修改源代码,可以在测试阶段输出precision,具体内容我已经在本文中写出来了。
----------------------------------------------------------------
-----------【2017.11.30更新】添加IOU --------------
IOU这个输出我之前是忽略了,这个输出其实也可以在训练阶段判断模型是否在正确训练,以及最后效果如何。
----------------------------------------------------------------
----------------- 【2017.09.19 更新】 python 可视化代码 --------------------------------------------
我一开始是写给caffe的, 不过道理都一样, 就顺便把这个也更新了.
-
#!/usr/bin/env python2 -
# -*- coding: utf-8 -*- -
""" -
Created on Tue Aug 29 10:05:13 2017 -
@author: hans -
http://blog.csdn.net/renhanchi -
""" -
import matplotlib.pyplot as plt -
import numpy as np -
import commands -
train_log_file = "vegetable_squeezenet.log" -
display = 10 #solver -
test_interval = 100 #solver -
train_output = commands.getoutput("cat " + train_log_file + " | grep 'avg,' | awk '{print $3}'") #train loss -
train_loss = train_output.split("\n") -
_,ax1 = plt.subplots() -
l1, = ax1.plot(display*np.arange(len(train_loss)), train_loss) -
ax1.set_xlabel('Iteration') -
ax1.set_ylabel('Train Loss') -
plt.legend([l1], ['Train Loss'], loc='upper right') -
plt.show()
如果觉得波动太大,不好看变化趋势。可以参考http://blog.csdn.net/renhanchi/article/details/78411095里可视化代码,改一改就好了。
-------------------------------------------------------------------------------------------------------------------------------------------------------
6.评价模型
--------【2017.07.03更新】-------------------------------------------------------------------------
下面命令不适用于新版本darknet(如果你下载了最上面百度云盘中老版本的darknet,下面命令是适用的)
首先使用下面的命令:
./darknet detector recall cfg/xxx.data cfg/xxx.cfg backup/xxx.weights--------------------------------------------------------------------------------------------------------------------------------
下面命令在新版本上是适用
在xxxx.data文件中train下面加上一句话: valid=path/to/valid/images.txt
./darknet detector valid cfg/.....data cfg/.....cfg backup/....weights然后输出一连串的数字数字数字,什么鬼??
----------------------------------------------------------------------------------------------------------------------------------------------------------------------
------ 【2017.06.29更新】---源代码被作者做了很大改动,新版本已经不适用下面内容了------------
如果你下载了最上面百度云盘中老版本的darknet,下面命令还是适用的
输出是累积的,结果只有recall,没有precision。因为第一代yolo有一定缺陷,precision跟其他方法相比很低,所以作者干脆把threshold设置的特别低,这样就只看recall,放弃precision了。第二代yolo已经修复了这个缺陷,所以可以自己修改代码把precision调出来。大家打开src/detector.c ,找到validate_detector_recall函数,其中float thresh = .25; 就是用来设置threshold的,我这里改成了0.25,原作者的值是0.0001。所以我一开始的precision只有1%多点 -0-。 继续往下看,找到这句话
-
fprintf(stderr, "%5d\t%5d\t%5d\tRPs/Img: %.2f\tIOU: %.2f%%\tRecall:%.2f%%\t", i, correct, total, (float)proposals/(i+1), -
avg_iou*100/total, 100.*correct/total);
把它改成下面这句话
-
fprintf(stderr, "Number: %5d\tCorrect: %5d\tTotal: %5d\tRPs/Img: %.2f\tIOU: %.2f%%\tRecall:%.2f%%\tProposals: %5d\t -
Precision: %.2f%%\n", i, correct, total, (float)proposals/(i+1), avg_iou*100/total, 100.*correct/total, proposals, -
100.*correct/(float)proposals);
重新make后,再次执行recall命令,就有precision啦。
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------
------ 【2017.12.22更新】---重新表述一下correct-----------------------------------------
Correct表示正确的识别出了多少bbox。这个值算出来的步骤是这样的,丢进网络一张图片,网络会对每一类物体都预测出很多bbox,每个bbox都有其置信概率,概率大于threshold的某一类物体的bbox与其实际的bbox(也就是labels中txt的内容)计算IOU,找出当前类物体IOU最大的bbox,如果这个最大值大于预设的IOU的threshold,说明当前类物体分类正确,那么correct加一。
我再多说两句,对于bbox的threshold,我们可以在命令行通过-thres调整的,同时也是上面修改源代码输出precision所提及的threshold。 而IOU的threshold只能通过源代码调整。
---------------------------------------------------------------------------------------------------------------
关于输出的参数,我的理解如下
Number表示处理到第几张图片。
Correct表示正确的识别除了多少bbox。这个值算出来的步骤是这样的,丢进网络一张图片,网络会预测出很多bbox,每个bbox都有其置信概率,概率大于threshold的bbox与实际的bbox(也就是labels中txt的内容)计算IOU,找出IOU最大的bbox,如果这个最大值大于预设的IOU的threshold,那么correct加一。
Total表示实际有多少个bbox。
Rps/img表示平均每个图片会预测出来多少个bbox。
IOU我上面解释过哈。
Recall我上面也解释过。通过代码我们也能看出来就是Correct除以Total的值。
Proposal表示所有预测出来的bbox中,大于threshold的bbox的数量。
Precision表示精确度,就是Correct除以Proposal的值。
关于预测的框和recall,precision一些逻辑上面的东西,我再多说点,给大家捋一捋顺序。
例如识别 人 这一类
1. 图片中实际有n个人,对应n个bbox信息。这个n的值就是Total的值
2. 图片丢进网络,预测出N个bbox,这N个bbox中置信概率大于threshold的bbox的数量就是Proposal的值,记为Npro。
3. n个实际bbox分别和Npro个bbox计算IOU,得到n个IOU最大的bbox,这n个IOU最大的bbox再与IOU threshold比较,得到nCor个大于IOU threshold的bbox。nCor就是Correct的值。nCor小于等于n。
4. 有了Total,Proposal和Correct,就能算出Recall和Precision了。
总结一下就是图片丢网络里,预测出了Npro个物体,但有的预测对了,有的预测的不对。nCor就是预测对了的物体数量。Recall就是表示预测对的物体数量(nCor)和实际有多少个物体数量(Total)的比值。Precision就是预测对的物体数量(nCor)和一共预测出所有物体数量(Proposal)的比值。联系上面提到的作者一开始把threshold设置为0.0001,这将导致Proposal的值(Npro)非常大,所以Correct的值(nCor)也会随之相应大一点。导致计算出的Recall值很大,但Precision值特别低。
注明:以上内容部分参考自http://blog.csdn.net/hysteric314/article/details/54097845

