
- 1Github账号开启账号双重验证_github双重认证
- 2(JavaSE)认识异常
- 3Vue 组件单元测试深度探索:细致解析与实战范例大全_vue 测试用例
- 4plugin zsh-autosuggestions/zsh-syntax-highlighting not found_plugin 'zsh-syntax-highlighting' not found
- 5最全的常用正则表达式大全——包括校验数字、字符、一些特殊的需求等等
- 6Java核心技术第4章(6)_警告: 使用不提供注释的默认构造器
- 7TS学习(六) :TS的模块化使用_object.defineproperty(exports
- 8比特币-系统架构师(十四)_比特币双花
- 9SpringAMQP的配置和使用_springamqp 发送消息
- 10ElasticSearch学习篇13_《检索技术核心20讲》进阶篇之LSM树
YOLOV5总结
赞
踩
目录
3.CSPDarkNet53(Cross Stage Partial Networks)
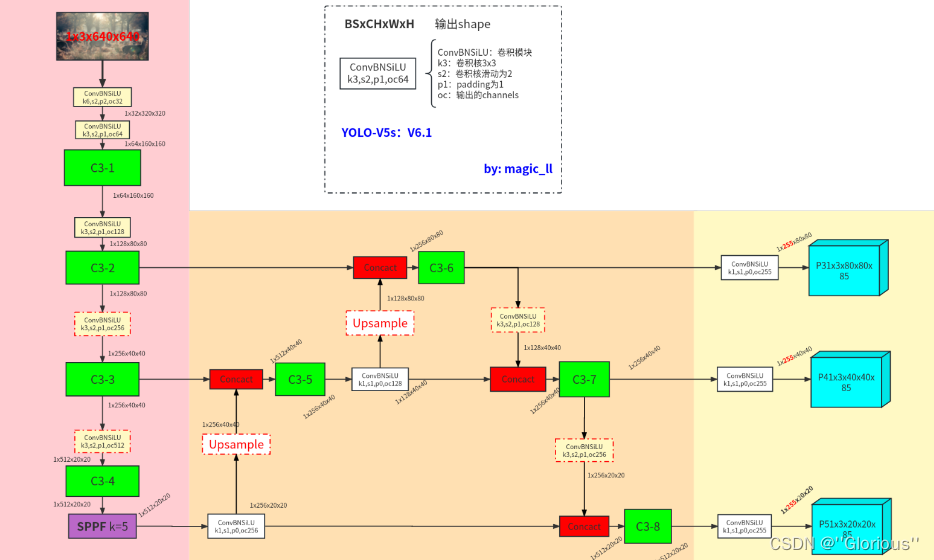
YOLOV5网络结构图:
1.YOLOV5版本:
(1)YOLOV5s
(2)YOLOV5m
(3)YOLOV5l
(4)YOLOV5x四个模型banb
2.模型的三部分:
输入端:
Mosaic数据增强,自适应锚框计算,自适应图片缩放
Moscaic数据增强的优点:
Mosaic数据增强则采用了4张图片,随机缩放、随机裁剪、随机排布的方式进行拼接
- 丰富数据集:随机使用4张图片,随机缩放,再随机分布进行拼接,大大丰富了检测数据集,特别事随机缩放增加了很多小目标,让网络的鲁棒性更好。
- 减少GPU:可能有人会说,随即缩放,普通的数据增强也可以做,但作者考虑到很多人可能只有一个GPU,因此Mosaic增强训练时,可以直接计算4张图片的数据,使得Mini-batch大小并不需要很大,一个GPU就可以达到比较好的效果。
总结:输入端===>
- mosic数据增强--->功能:随机裁剪、随机缩放、随机排布形成一张大图
- 自适应锚框计算
- 自适应缩放
YOLOV5主干网络(backbone):
FOCUS、C3NET、SPPF、Conv_BN_SiLU(strides=2,用于下采样)
- 第一个C3-Net在主干网络中,第二个C3-Net在neck端,主要目的提取特征,融合多尺度
- Focus===>通过高维度特征转达低维度特征,相当于三维数据或者对维度数据为一维的过程
- spp:先卷积后池化(先提取特征后降维的操作)然后多尺度融合拼接==>进行卷积
FOCUS模块:
Focus模块在v5中是图片进入backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
其实就是yolov2里面的ReOrg+Conv操作,也就是亚像素卷积的反向操作版本,简单来说就是把数据切分成4份,每份数据都是相当于2倍下采样得到的,然后再channel维度进行拼接,最后进行卷积操作。可以最大程度的减少信息损失而进行下采样操作。
以yolov5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。切片操作如下

先了解两个概念:
- 参数数量(params):关系到模型大小,单位通常是M,通常参数用float32表示,所以模型大小是参数数量的4倍。
- 计算量(FLOPs):即浮点运算数,可以用来衡量算法/模型的复杂度,这关系到算法速度,大模型的单位通常为G,小模型单位通常为M;通常只考虑乘加操作的数量,而且只考虑Conv和FC等参数层的计算量,忽略BN和PReLU等,一般情况下,Conv和FC层也会忽略仅纯加操作的计算量,如bias偏置加和shoutcut残差加等,目前技术有BN和CNN可以不加bias。
- params计算公式:Kh × Kw × Cin × Cout
- FLOPs计算公式:Kh × Kw × Cin × Cout × H × W = 即(当前层filter × 输出的feature map)= params × H × W
neck端:
------>使用混合和组合图像特征的网络层,并且将提取特征传递给预测端
FPN、PAN
neck模块部分, 包含 FPN (Feature Pyramid Network)、PAN (Path Aggregation Network)。两者都是在解决目标检测中 多尺度检测任务上的不足,都是将高层的语义信息与低层的空间信息结合,然后再进行信息提取。换句话说就是 自上而下或自下而上地融合不同尺度信息的特征。
FPN和PAN都有对应的论文和完整的网络结构,但在后来的使用中,很少指原论文中的网络结构,而是来强调 不同特征进行融合的模块。FPN是unsample+merge,PAN是downsample+merge,其中merge有add、concat,具体为哪种形式看每个工程自己的使用情况。在yolov5中,使用的是concat。
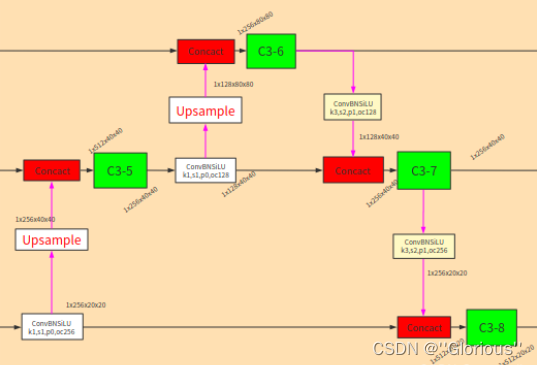
FPN
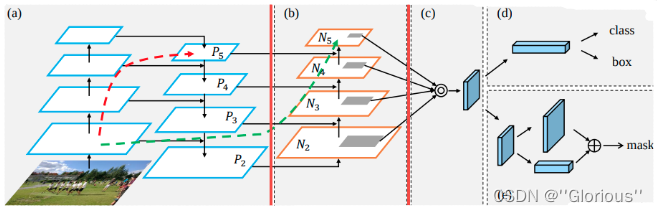
Feature Pyramid Network是由FAIR在2017年提出的一种处理多尺度问题的方法。
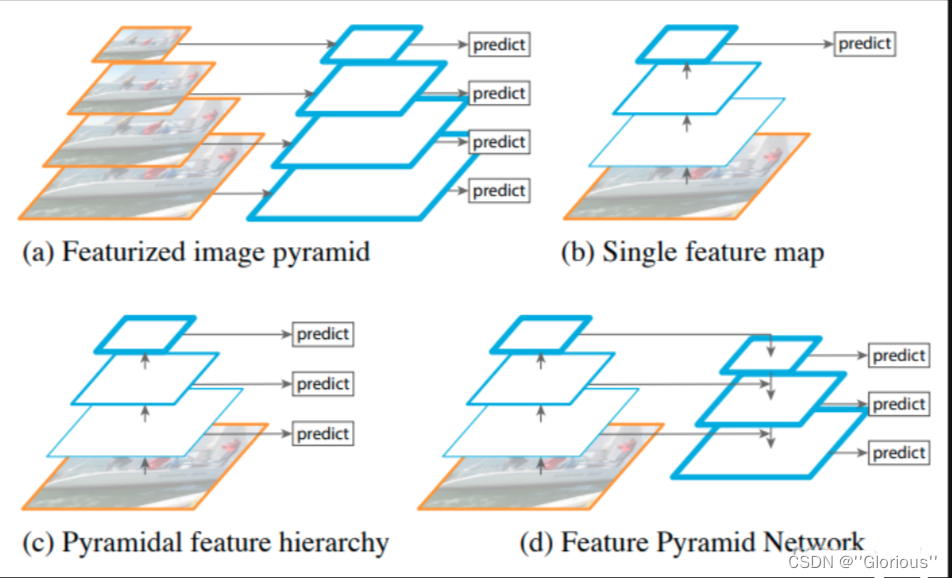
上图是多尺度问题,其中(d)为FPN。具体的细节如下,主打一个upsample + concat,将不同尺度的特征图融合,然后再特征提取:
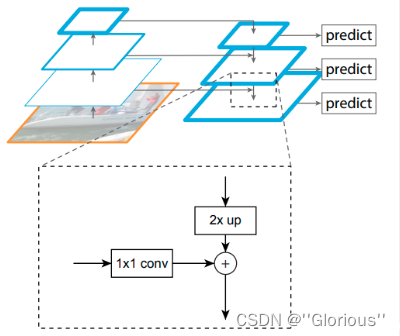
PAN
Path Aggregation Network是由Megvii在2018年提出的一种处理多尺度问题的方法。与FPN类似,PAN也是一种金字塔式的特征提取网络,但是它采用的是自下而上的特征传播方式。
head端:
Conv_BN_SiLU、输出
对于检测头,就是一个ConvBNSiLU,然后得到神经网络的输出。
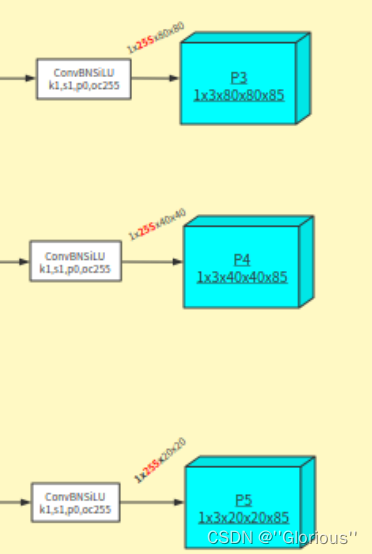
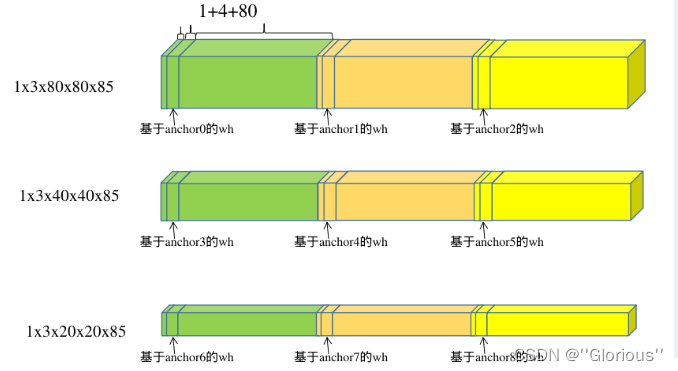
共有三个尺度的输出分别为 1x255x20x20、1x255x40x40、1x255x80x80。其中
【1】 为batch
【255】 为 (80+1+4)*3:
【80:class】 为coco数据集中目标检测的类别数,将其转换成one-hot形式;
【1:confidence】 为是否为目标;
【4:box】 为检测框对应的xywh,具体的为:xy检测框的中心下采样到某层输出上,距离grid ceil 左上角的偏移,wh为检测框的长宽与当前anchor的长宽的比值。
【3】 为在每个grid cell 上预测3个检出信息,分别对应3个anchor。
【80x80/40x40/20x20】不同降采样层的输出尺寸,80x80对应有80x80个grid cell。
conv模块

CONV模块(CBL模块)中封装了三个功能:包括卷积(Conv2d)、BN以及Activate函数(在新版yolov5中,作者采用了SiLU函数作为激活函数),同时autopad(k, p)实现了padding的效果。总的说来Conv实现了将输入特征经过卷积层,激活函数,归一化层,得到输出层。
Prediction端:
------>对图像进行特征预测,并且通过IOU和NMS提取并生成边界框与预测类别
3.CSPDarkNet53(Cross Stage Partial Networks)
Yolov4和v5都使用CSPDarknet作为Backbone,从输入图像中提取丰富的信息特征。
CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。
CSPNet实际上是基于Densnet的思想,复制基础层的特征映射图,通过dense block 发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号) ,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。

CSPDarknet53
CSPDarknet53是在yolov3主干网络Darknet53的基础上,借鉴2019年的CSPNet的经验,产生的Backbone结构,其中包含了5个CSP模块。
每个CSP模块前面的卷积核大小都是3*3,stride=2,因此可以起到下采样的作用。
因为Backbone有5个CSP模块,输入图象是608*608,所以特征图变化的规律是:608-->304-->152-->76-->38-->19。经过5次CSP模块后得到19*19大小的特征图。只在Backbone中采用了Mish激活函数,网络后面仍然采用了Leaky_relu激活函数。
为啥要采用CSP模块?CSPNet全称是Cross Stage Paritial Network,主要从网络结构设计的角度解决推理中从计算量很大的问题。CSPNet的作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。因此采用CSP模块先将基础层的特征映射划分为两部分,然后通过跨阶段层次结构将它们合并,在减少了计算量的同时可以保证准确率。因此Yolov4在主干网络Backbone采用CSPDarknet53网络结构,主要有三个方面的优点:
- 优点一:增强CNN的学习能力,使得在轻量化的同时保持准确性。
- 优点二:降低计算瓶颈
- 优点三:降低内存成本
CSP结构的优点:
- 加强CNN的学习能力
- 减少计算瓶颈,现在的网络大多计算代价昂贵,不利于工业的落地
- 减少内存消耗
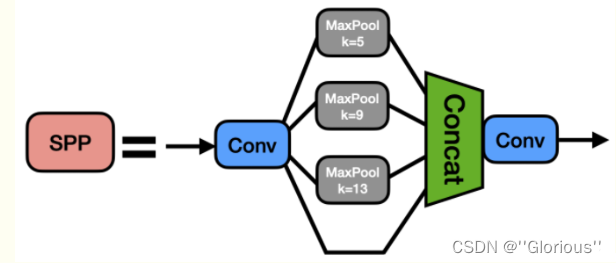
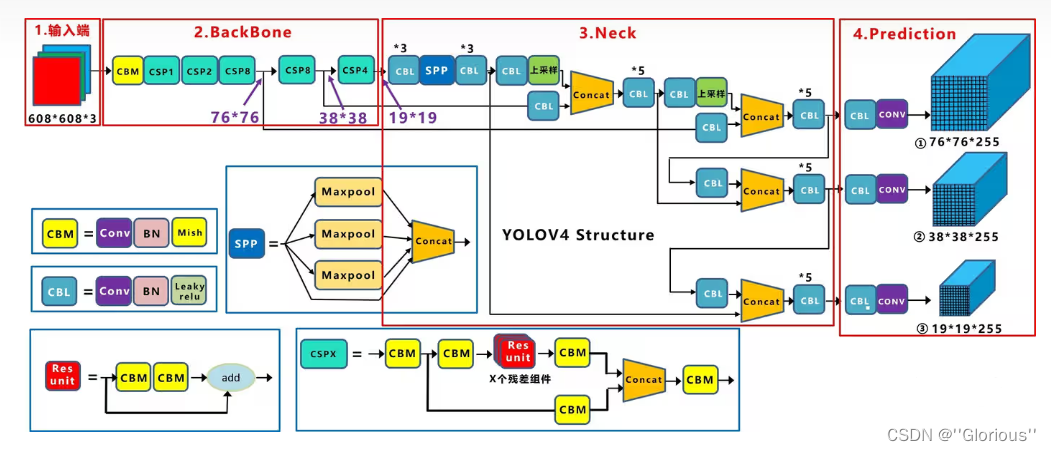
4.SPP vs SPPF
先摆出SPP和SPPF的对比图
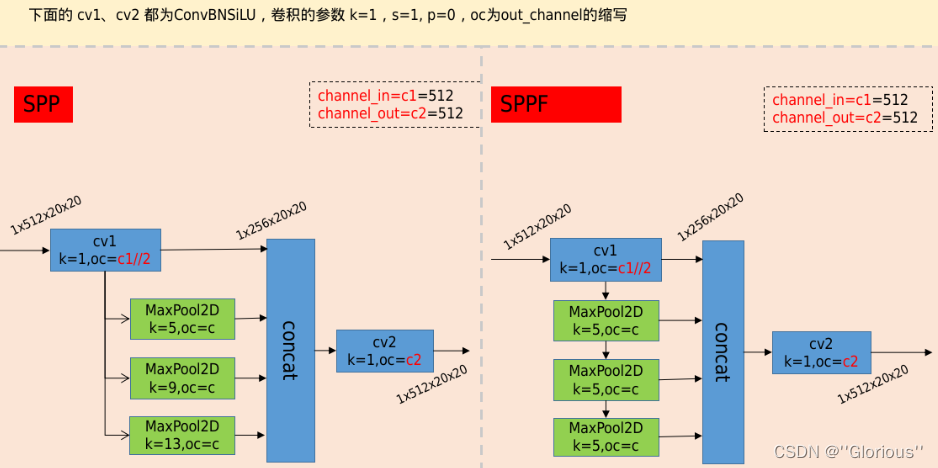
分析一下两者区别
SPP(空间金字塔池化):
原论文解读在 SPPNet,这里的SPP是借鉴了SPPNet中的模块,使用不同kernel的池化层对featuremap进行信息提取然后concat。具体的如下:
1)先在通过一个ConvBNSiLU。
2)然后分别通过三个MaxPool2D,默认stride=1,且进行padding,如此整个过程不会改变featuremap的尺寸;
对应的kernel分别为5,9,13,对应的感受野分别为5*5,9*9,13*13。
3)然后进行concat,再通过ConvBNSiLU得到模块最后的输出。
SPPF:
与SPP不同的是MaxPool2D的堆叠方式
分析:
对于9*9的MaxPool2D 等价与 两个5*5的MaxPoolD2D的堆叠;13*13的MaxPoolD等价于三个5*5的MaxPoolD2D的堆叠,可将SPP的结构修改成下图左图;然后对左图是对右图的pool进行了合并连接。其中左图是完全等价SPP的,右图是则SPPF,与上图右图完全一致。
如此,SPPF相较于SPP的效果精度并未改变的同时,节省了三个k=5的MaxPool2D的计算,较大的提升了运行时间
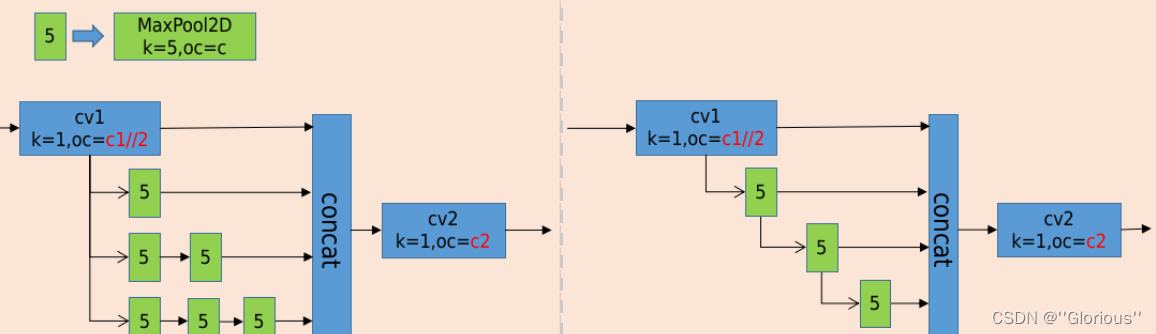
注意:
特征图的输入尽量保证尺寸 大于等于13、且靠近13,此时网络的状态将会相对更优。
1)若SPPF的输入尺寸为13,神经网络此时输入尺寸为13*32=418。此时效果和运行时间达到最佳
2)若SPPF的输入尺寸为8(小于13较多),MaxPool2D提供13的感受野 将会有冗余的操作以及冗余的时间消耗。此时对于SPPF可去掉一个MaxPool2D,节省时间的同时获取相近的效果。
3)若SPPF的输入尺寸为25 (大于13较多),MaxPool2D提供的13的感受野 无法获取到图像的全局特征,此时效果将会降低一些,自己在训练时可留意这里的处理
5.YOLOv5 相较于 YOLOv4 的进行的改进
改进点:
-
网络结构:使用了新的CSPDarknet53模型替换了Darknet53,并引入了新的Neck网络结构(YOLOv5s使用FPN,而YOLOv5使用PAN)。
-
数据预处理:引入Mosaic数据增强方法,并对模型训练进行了改进。
-
损失函数:使用CIOU_Loss替换了YOLOv4中的GIOU_Loss。
-
激活函数:使用Mish替换了Leaky_Relu。
-
优化器和学习率调整:使用Adaptive Detection Range (ADR)策略,并引入了自适应学习率调整。
-
运行效率:优化模型架构,以提高推理速度。
以下是YOLOv5中一些关键组件的示例代码片段:
代码展示
CSPDarknet53模型结构:
- class CSPDarknet(nn.Module):
- # CSPDarknet53 model structure
- def __init__(self):
- super(CSPDarknet, self).__init__()
- self.conv1 = Conv(3, 32, 3, 2)
- self.conv2 = DarknetConv2d(32, 64)
- self.conv3 = DarknetConv2d(64, 128, downsample=True)
- # ... (other layers)
FPN结构:
- class FPN(nn.Module):
- # YOLOv5s PAN structure
- def __init__(self, in_ch):
- super(FPN, self).__init__()
- self.in_ch = in_ch
- self.up1 = UpSample(in_ch[2], in_ch[1])
- self.up2 = UpSample(in_ch[1], in_ch[0])
- self.conv = DarknetConv2d(in_ch[0], in_ch[0], 1)
-
- def forward(self, l, n):
- # l - layers, n - num layers
- m = self.up1(l[self.in_ch.index(n[1])])
- m = torch.cat([m, self.up2(l[self.in_ch.index(n[2])])], 1)
- return self.conv(m)
CIOU_Loss
- class CIOU_Loss(nn.Module):
- # CIOU loss function
- def __init__(self):
- super(CIOU_Loss, self).__init__()
-
- def forward(self, pred, true):
- # pred - prediction tensor, true - target tensor
- ciou = torch.diag(generalized_box_iou(box_ciou_encode(pred, true)))
- # ... (calculate loss)
- return loss
Mish激活函数
- class Mish(nn.Module):
- # Mish activation function
- def __init__(self):
- super(Mish, self).__init__()
-
- def forward(self, x):
- return x * torch.tanh(F.softplus(x))
这些代码片段仅展示了YOLOv5中一部分关键的改进和创新,具体实现可能需要结合YOLOv5的完整代码来理解
YOLOV5项目总结:
- GitHub下载业务需求相关的工程-->用什么网络
- 下载-->第一个事情就是看readme文件-->关键字:python版本需求
- Dataset(数据)---> 数据一般跟着是数据下载路径,model(模型)---> 与训练模型 ---> 有网址
- 操作工程 --->1、先跑通 ---> 要用公开的数据集进行支撑网络运行。公开的数据集(voc,coco)voc数据集。前两个Annotation和JPEGImages文件是用来做目标检测,SegmentationClass和SegmentationObject这个文件是用来做语义分割(提取像素)
- 调优 ---> 过拟合,欠拟合,如何解决此类问题
调优问题:
过拟合问题
方面考虑:
(1)数据--->数据质量问题
(2)数据清洗
(3)数据采集
(4)数据拆分
(5)数据增强
(6)数据类别不均衡问题(工程代码上)
仅供参考!

