
- 1ARTIX-7 XC7A35T实验项目之流水灯
- 2数据结构之链表---单向链表_树状结构和链式结构和网状结构的区别
- 3ubuntu20.04编译安装qt5.14.2和qtcreator4.12.0_qt5.14.2源码编译 找不到charts模块
- 4it项目经理带一个项目的完整_IT项目经理是干嘛的?
- 5FastAPI从入门到实战(16)——开发基于JSON Web Tokens的认证
- 6机器学习需要的大量数据集从哪里找?_机器学习数据集
- 7swift笔记_weak' must not be applied to non-class-bound 'any
- 8NLP之BM25:BM25算法的简介、相关库、案例应用之详细攻略_bm25 库
- 9人工智能安全综述_ai技术自身安全特性
- 10第二部分 Python提高—GUI图形用户界面编程(一)_python gui编程
如何理解NLP中的图像?一文知悉TextCNN文本分类_nlp可以图像处理吗
赞
踩
关注微信公众号:NLP分享汇。【喜欢的扫波关注,每天都在更新自己之前的积累】

文章链接:https://mp.weixin.qq.com/s/h_ezSv94ixC0oQQk2Ek9PA
什么是深度神经网络?
深度神经网络被大多数较优模型所青睐。「深」实际上就是「多层」,通过堆叠前馈层(feed-forward layers)抽取特征。前馈层被定义为:y = σ(Wx + b),σ是激活函数,W和b都是可训练参数。前馈层由于激活功能而功能强大,从而使原本为线性的操作变为非线性。然而,在使用前馈层时存在一些问题:首先,前馈层或多层神经网络的操作仅是模板匹配,而没有考虑数据的特定结构。此外,传统多层神经网络的完全连接机制导致参数数量激增,从而导致泛化问题。
卷积神经网络
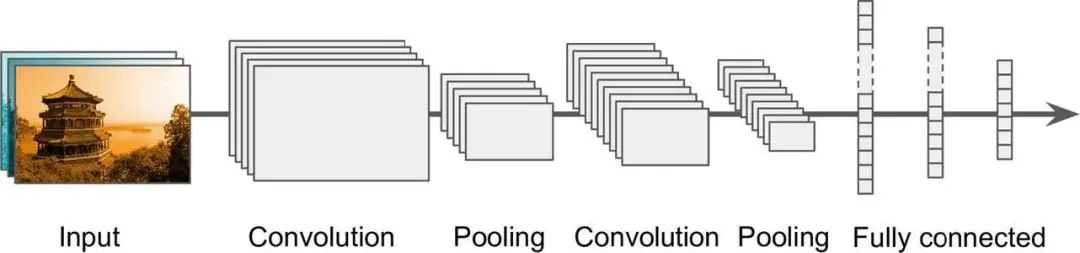
上图所示CNNs通常包含卷积层(convolutional layers)、池化层(pooling layers)和前馈层(feed-forward layers)。卷基层应用卷积核去执行卷积操作,如公式1所示:
![]()
m和n分别为结果矩阵的行和列、f表示输入矩阵、h表示卷积核。池化层对卷积层的结果执行下采样(down-sampling)以获得更高级别的特征,而前馈层将它们映射到概率分布中以预测类分数。滑动窗口(sliding window)特征使卷积层能够捕获局部特征,而池化层可以产生分层特征。这两种机制使CNN具有本地感知能力和全局感知能力,从而有助于捕获数据的某些特定内部结构。参数共享机制减轻了参数爆炸问题和过拟合问题,因为可训练参数的减少导致模型复杂度降低,从而提高了泛化能力。
自然语言处理中的卷积神经网络:TextCNN
下图即为TextCNN的模型结构图:

如何理解NLP中的“图像”?
NLP面对的常常是一个被表达为矩阵的文档或句子。常常每一行表达一个特征或句子,即每一行是一个单词所代表的向量。通常会使用词嵌入(word-embeddings)的方法,例如Word2vec或GloVe。也可以使用one-hot的方法,该方法是标注了单词在词典中的位置。如果一个文本中有10单词,每个单词用100维向量表示,利用上述方法会生成10X100的向量。这就是在NLP中的“图像”。
在机器视觉上,我们的卷积核会在图像的局部区域上滑动,但是在NLP中,我们通常使用的过滤器会滑过整个矩阵(单词)。因此,过滤器的“宽度(width)”通常与输入矩阵的宽度相同。高度,或区域大小(region size),可能会有所不同,但是滑动窗口一次在2-5个字是典型的。
上图展示了CNN在文本分类的使用,使用了2种过滤器(卷积核),每个过滤器有3种高度(区域大小),即有6种卷积结构(左起第2列),所以会产生6种卷积后的结果(左起第3列),经过最大池化层(后面还会提到池化层),每个卷积的结果将变为1个值(左起第4列),最终生成一个向量(左起第5列),最终经过分类器得到一个二分类结果(最后一列)。
-
Embedding:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点。
-
Convolution:然后经过 kernel_sizes=(2,3,4) 的一维卷积层,每个kernel_size 有两个输出 channel。
-
MaxPolling:第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示。
-
FullConnection and Softmax:最后接一层全连接的 softmax 层,输出每个类别的概率。
卷积神经网络另一个突出的特征就是池化层,它经常被放在卷积层之后,池化层是对上一层卷积层的子采样,例如采集池化层过滤器覆盖区域下最大的值——称为最大池化。不必对整个矩阵进行池化,也可以通过窗口进行滑动。NLP中经典的做法是将池化层应用于整个卷积输出的结果,最终就直接得到一个数字——即这个尺寸下此句子的特征,如上面的例子。
我们为什么要用池化层呢?
-
池化层可以保证输出矩阵大小是固定的。而分类任务常常要求输出维度固定,例如,如果池化层应用到1000个过滤器(卷积核)上,那么不管你的过滤器尺寸和你输入矩阵的大小,你都将得到一个1000维的输出。这就使得你可以选择可变的输入向量和过滤器尺寸,但得到的输出维度一致。
-
池化层可以降维,但又能保证重要的信息。
卷积神经网络中的通道(Channels)
通道就是从不同“角度”看待你的输入,在图像里面,RGB格式的图像就有3个通道(红,绿,蓝)。同样的,NLP中也有不同的通道,例如可以把通道分为不同的词嵌入方法(word2vec,GloVe等),不同语种的表达,或者同一个意思不同方式的表达。
为什么是一维卷积?
-
图像是二维数据;
-
文本是一维数据,因此在TextCNN卷积用的是一维卷积(在word-level上是一维卷积;虽然文本经过词向量表达后是二维数据,但是在embedding-level上的二维卷积没有意义)。一维卷积带来的问题是需要通过设计不同 kernel_size 的 filter 获取不同宽度的视野。

