- 1Spring Boot整合RabbitMQ详细教程_springboot整合rabbitmq
- 2未来已来!体验AI数字人客服系统带来的便利与智慧
- 3【python】tkinter+pyserial实现串口调试助手_串口调试工具 python
- 4数据库MongoDB启动方式(3种) - 方法总结篇_如何启动mongodb
- 5通过虚拟机安装Ubuntu系统到移动硬盘_vmware虚拟机移动到移动硬盘
- 6基于MATLAB的ZF、MMSE、THP线性预编码误码率仿真_zf预编码matlab代码
- 7自然语言处理(NLP)—— 置信度(Confidence)_感知层的置信度
- 8自然语言处理的实体识别:命名实体识别与关系抽取_使用自然语言处理进行人物关系抽取
- 9Python Tkinter教程之Event篇(1)_python tk event
- 10代码随想录day1 Java版
SAP HANA函数汇总(3)——字符串函数_hana 字符串函数
赞
踩
刚好最近在看官方文档,做个记录。
一、字符串函数汇总
| ABAP_ALPHANUM Function (String) |
| ABAP_LOWER Function (String) |
| ABAP_NUMC Function (String) |
| ABAP_UPPER Function (String) |
| ASCII Function (String) |
| BINTOHEX Function (String) |
| BINTONHEX Function (String) |
| BINTOSTR Function (String) |
| CHAR Function (String) |
| CONCAT Function (String) |
| CONCAT_NAZ Function (String) |
| HAMMING_DISTANCE Function (String) |
| HEXTOBIN Function (String) |
| HEXTONUM Function (String) |
| INITCAP Function (String) |
| LCASE Function (String) |
| LEFT Function (String) |
| LENGTH Function (String) |
| LOCATE Function (String) |
| LOCATE_REGEXPR Function (String) |
| LOWER Function (String) |
| LPAD Function (String) |
| LTRIM Function (String) |
| NCHAR Function (String) |
| NORMALIZE Function (String) |
| NUMTOHEX Function (String) |
| OCCURRENCES_REGEXPR Function (String) |
| REPLACE Function (String) |
| REPLACE_REGEXPR Function (String) |
| RIGHT Function (String) |
| RPAD Function (String) |
| RTRIM Function (String) |
| SOUNDEX Function (String) |
| STRTOBIN Function (String) |
| SUBSTR_AFTER Function (String) |
| SUBSTR_BEFORE Function (String) |
| SUBSTRING Function (String) |
| SUBSTRING_REGEXPR Function (String) |
| TRIM Function (String) |
| UCASE Function (String) |
| UNICODE Function (String) |
| UPPER Function (String) |
| XMLTABLE Function (String) |
二、字符串函数用法
1.字符串截取与拼接
| 操作 | 函数 | 说明 |
|---|---|---|
| 截取 | LEFT | 返回字符串从左侧开始的指定数量的字符或字节。 |
| 截取 | RIGHT | 返回字符串从右侧开始的指定数量的字符/字节。 |
| 截取 | SUBSTR_AFTER | 返回从指定字符串中跟随指定模式的第一次出现的子字符串。 |
| 截取 | SUBSTR_BEFORE | 返回指定模式第一次出现之前的指定字符串的子字符串。 |
| 截取 | SUBSTRING | 从输入值中的指定位置开始,返回输入值的子字符串。 |
| 截取 | LTRIM | 返回一个去掉所有前导空格的字符串。 |
| 截取 | RTRIM | 返回一个去掉所有尾随空格的字符串。 |
| 截取 | TRIM | 返回删除前导和尾随空格后的字符串。 |
| 填充 | LPAD | 使用空格或指定的模式向左填充字符串,以使字符串达到指定的字符长度。 |
| 填充 | RPAD | 使用空格或指定的模式向右填充字符串,以使字符串达到指定的字符长度。 |
| 拼接 | CONCAT | 返回由两个指定字符串组成的组合字符串。 |
| 拼接 | CONCAT_NAZ | 返回由两个指定字符串组成的非空值组合字符串。 |
| 拼接 | || | 当有多个字符串拼接的时候,可以用||来作拼接 |
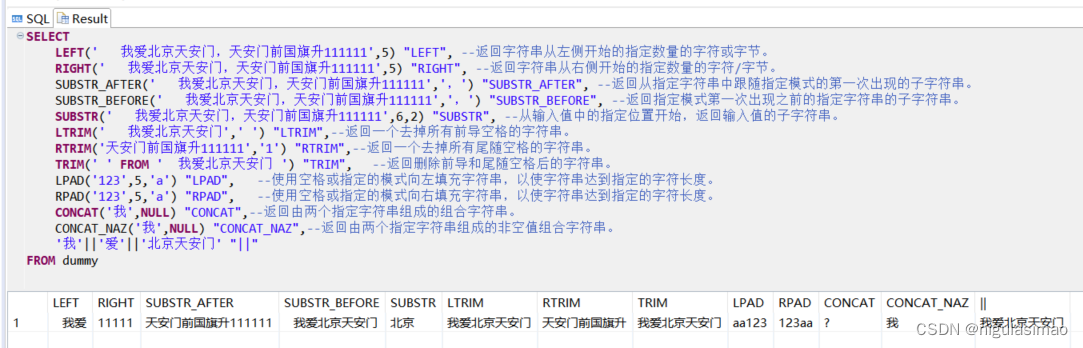
SELECT
LEFT(' 我爱北京天安门,天安门前国旗升111111',5) "LEFT", --返回字符串从左侧开始的指定数量的字符或字节。
RIGHT(' 我爱北京天安门,天安门前国旗升111111',5) "RIGHT", --返回字符串从右侧开始的指定数量的字符/字节。
SUBSTR_AFTER(' 我爱北京天安门,天安门前国旗升111111',',') "SUBSTR_AFTER", --返回从指定字符串中跟随指定模式的第一次出现的子字符串。
SUBSTR_BEFORE(' 我爱北京天安门,天安门前国旗升111111',',') "SUBSTR_BEFORE", --返回指定模式第一次出现之前的指定字符串的子字符串。
SUBSTR(' 我爱北京天安门,天安门前国旗升111111',6,2) "SUBSTR", --从输入值中的指定位置开始,返回输入值的子字符串。
LTRIM(' 我爱北京天安门',' ') "LTRIM",--返回一个去掉所有前导空格的字符串。
RTRIM('天安门前国旗升111111','1') "RTRIM",--返回一个去掉所有尾随空格的字符串。
TRIM(' ' FROM ' 我爱北京天安门 ') "TRIM", --返回删除前导和尾随空格后的字符串。
LPAD('123',5,'a') "LPAD", --使用空格或指定的模式向左填充字符串,以使字符串达到指定的字符长度。
RPAD('123',5,'a') "RPAD", --使用空格或指定的模式向右填充字符串,以使字符串达到指定的字符长度。
CONCAT('我',NULL) "CONCAT",--返回由两个指定字符串组成的组合字符串。
CONCAT_NAZ('我',NULL) "CONCAT_NAZ",--返回由两个指定字符串组成的非空值组合字符串。
'我'||'爱'||'北京天安门' "||"
FROM dummy
2.字符串其他常用函数
| 函数 | 说明 |
|---|---|
| LENGTH | 返回字符串中的字符数量。 |
| LOCATE | 返回子串在字符串中的位置。 |
| REPLACE | 在字符串中搜索指定字符串的所有出现,并将它们替换为另一个指定的字符串。 |
这些函数往往会配合字符串的截取一起在实际开发场景中灵活使用。
SELECT
LENGTH('我爱北京天安门') "LENGTH", --返回字符串中的字符数量。
REPLACE ('我爱北京天安门','天安门', '故宫') "REPLACE", --在字符串中搜索指定字符串的所有出现,并将它们替换为另一个指定的字符串。
LOCATE ('我爱北京天安门','天安门') "LOCATE" --返回子串在字符串中的位置,如果未找到则返回0
FROM DUMMY

3.字符串大小写转换
| 函数 | 说明 |
|---|---|
| ABAP_LOWER | 将指定字符串中的所有字符转换为小写。 |
| LCASE | 将字符串中的所有字符转换为小写。 |
| LOWER | 将字符串中的所有字符转换为小写。 |
| ABAP_UPPER | 将指定字符串中的所有字符转换为大写。 |
| UCASE | 将指定字符串中的所有字符转换为大写。 |
| UPPER | 将字符串中的所有字符转换为大写。 |
| INITCAP | 将指定字符串中每个单词的第一个字符转换为大写,并将其余字符转换为小写。 |
大小写转换方法很多,选择合适的一个即可。
SELECT
ABAP_LOWER('OH my gOD') "ABAP_LOWER",--将指定字符串中的所有字符转换为小写。
LCASE('OH my gOD') "LCASE",--将字符串中的所有字符转换为小写。
LOWER('OH my gOD') "LOWER",--将字符串中的所有字符转换为小写。
ABAP_UPPER('OH my gOD') "ABAP_UPPER",--将指定字符串中的所有字符转换为大写。
UCASE('OH my gOD') "UCASE",--将指定字符串中的所有字符转换为大写。
UPPER('OH my gOD') "UPPER",--将字符串中的所有字符转换为大写。
INITCAP('OH my gOD') "INITCAP"--将指定字符串中每个单词的第一个字符转换为大写,并将其余字符转换为小写。
FROM DUMMY

4.正则表达式
| 函数 | 说明 |
|---|---|
| LOCATE_REGEXPR | 在字符串中搜索正则表达式模式,并返回一个整数,表示一个匹配子串的开始位置,或者结束位置加1。 |
| REPLACE_REGEXPR | 在字符串中搜索正则表达式模式,并返回使用替换字符串替换正则表达式模式的一个或每个出现的字符串。 |
| OCCURRENCES_REGEXPR | 返回字符串中正则表达式搜索的匹配次数。 |
| SUBSTRING_REGEXPR | 在字符串中搜索正则表达式模式,并返回匹配子串的一个出现。 可以写成SUBSTR_REGEXPR |
正则表达式有复杂的匹配规则,能够灵活地提取或者找到个性化的字符串。这里举了一些例子供参考,当然实际使用的时候要要根据需求灵活使用。
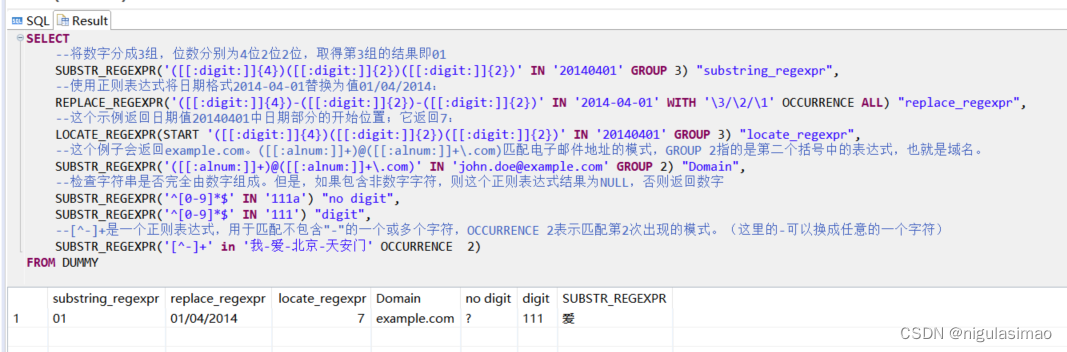
SELECT
--将数字分成3组,位数分别为4位2位2位,取得第3组的结果即01
SUBSTR_REGEXPR('([[:digit:]]{4})([[:digit:]]{2})([[:digit:]]{2})' IN '20140401' GROUP 3) "substring_regexpr",
--使用正则表达式将日期格式2014-04-01替换为值01/04/2014:
REPLACE_REGEXPR('([[:digit:]]{4})-([[:digit:]]{2})-([[:digit:]]{2})' IN '2014-04-01' WITH '\3/\2/\1' OCCURRENCE ALL) "replace_regexpr",
--这个示例返回日期值20140401中日期部分的开始位置;它返回7:
LOCATE_REGEXPR(START '([[:digit:]]{4})([[:digit:]]{2})([[:digit:]]{2})' IN '20140401' GROUP 3) "locate_regexpr",
--以下示例返回指定字符串'a1b2'中数字的出现次数,并返回值2:
OCCURRENCES_REGEXPR('([[:digit:]])' IN 'a1b2') "occurrences_regexpr",
--这个例子会返回example.com。([[:alnum:]]+)@([[:alnum:]]+\.com)匹配电子邮件地址的模式,GROUP 2指的是第二个括号中的表达式,也就是域名。
SUBSTR_REGEXPR('([[:alnum:]]+)@([[:alnum:]]+\.com)' IN 'john.doe@example.com' GROUP 2) "Domain",
--检查字符串是否完全由数字组成。但是,如果包含非数字字符,则这个正则表达式结果为NULL,否则返回数字
SUBSTR_REGEXPR('^[0-9]*$' IN '111a') "no digit",
SUBSTR_REGEXPR('^[0-9]*$' IN '111') "digit",
--[^-]+是一个正则表达式,用于匹配不包含"-"的一个或多个字符,OCCURRENCE 2表示匹配第2次出现的模式。(这里的-可以换成任意的一个字符)
SUBSTR_REGEXPR('[^-]+' in '我-爱-北京-天安门' OCCURRENCE 2)
FROM DUMMY
;
5.不太常用的函数
这些函数平时用得少,以官方文档为准,可以了解其使用方法。
| 函数 | 说明 |
|---|---|
| ABAP_ALPHANUM | 将字符串转换为ALPHANUM类型然后再转换回字符串的结果。 |
| ABAP_NUMC | 将输入字符串转换为只包含数字的指定长度的字符串。 |
什么是ALPHANUM,在HANA中,字符串数据类型有三种。
| 数据类型 | 描述 |
|---|---|
| VARCHAR | VARCHAR(<n>)数据类型指定长度可变字符串,其中 <n> 表示按字节计算的最大长度,为 1 到 5000 之间的整数。如果未指定长度,则缺省值为 1。 如果在 DML 查询中使用 VARCHAR(<n>)数据类型,例如 CAST (A as VARCHAR(n)),则 <n> 表示字符串的最大长度。使用仅具有基于 7 位 ASCII 字符的字符串的 VARCHAR。对于包含其他字符的数据,使用 NVARCHAR 数据类型代替。 |
| NVARCHAR | NVARCHAR(<n>)数据类型指定可变长度的 Unicode 字符集字符串,其中 <n> 表示按字符计算的最大长度,为 1 到 5000 之间的整数。如果未指定长度,则缺省值为 1。 |
| ALPHANUM | ALPHANUM(<n>) 数据类型指定包含字母数字字符的可变长度字符串,其中 <n> 表示最大长度,为 1 到 127 之间的整数。 在字母表示中执行 ALPHANUM 类型的值之间的排序。如果出现纯数字值,则表示可将该值视为具有前导零的字母值。 |
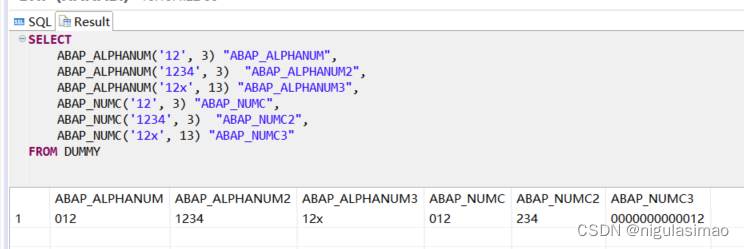
SELECT
ABAP_ALPHANUM('12', 3) "ABAP_ALPHANUM",
ABAP_ALPHANUM('1234', 3) "ABAP_ALPHANUM2",
ABAP_ALPHANUM('12x', 13) "ABAP_ALPHANUM3",
ABAP_NUMC('12', 3) "ABAP_NUMC",
ABAP_NUMC('1234', 3) "ABAP_NUMC2",
ABAP_NUMC('12x', 13) "ABAP_NUMC3"
FROM DUMMY
| 函数 | 说明 |
|---|---|
| ASCII | 返回指定字符串中第一个字符的整数ASCII值。 |
| HAMMING_DISTANCE | 在两个参数之间执行位逐位或字节逐字节的比较,并返回汉明距离。 |
| HEXTOBIN | 将十六进制字符的字符串转换为VARBINARY值。 |
| HEXTONUM | 将十六进制值转换为BIGINT字符串值。 |
| NCHAR | 返回具有指定代码编号的Unicode字符。 |
| NORMALIZE | 对字符值表达式应用标准化格式并返回标准化字符串。 |
| NUMTOHEX | 将数值转换为十六进制值。 |
| STRTOBIN | 使用指定的代码页将字符串中的所有字符转换为二进制编码。 |
| UNICODE | 返回一个整数,包含指定字符串中第一个字符的Unicode代码点。 |
| XMLTABLE | 从XML字符串创建关系表。 |
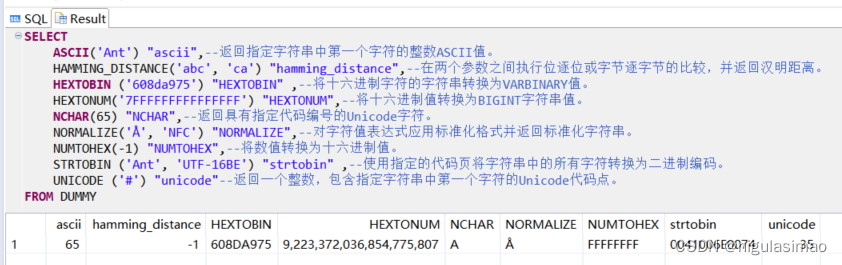
SELECT
ASCII('Ant') "ascii",--返回指定字符串中第一个字符的整数ASCII值。
HAMMING_DISTANCE('abc', 'ca') "hamming_distance",--在两个参数之间执行位逐位或字节逐字节的比较,并返回汉明距离。
HEXTOBIN ('608da975') "HEXTOBIN" ,--将十六进制字符的字符串转换为VARBINARY值。
HEXTONUM('7FFFFFFFFFFFFFFF') "HEXTONUM",--将十六进制值转换为BIGINT字符串值。
NCHAR(65) "NCHAR",--返回具有指定代码编号的Unicode字符。
NORMALIZE('Å', 'NFC') "NORMALIZE",--对字符值表达式应用标准化格式并返回标准化字符串。
NUMTOHEX(-1) "NUMTOHEX",--将数值转换为十六进制值。
STRTOBIN ('Ant', 'UTF-16BE') "strtobin" ,--使用指定的代码页将字符串中的所有字符转换为二进制编码。
UNICODE ('#') "unicode"--返回一个整数,包含指定字符串中第一个字符的Unicode代码点。
FROM DUMMY