
- 1设计模式之单例模式_new random()有必要单列吗
- 2消息中间件RabbitMQ
- 3ArcGIS镶嵌影像数据集 掩膜显示_arcgis图像掩膜镶嵌
- 4YOLO系列算法精讲:从yolov1至yolov8的进阶之路(2万字超全整理)_yolov9
- 5快速上手!LLaMa-Factory最新微调实践,轻松实现专属大模型_demo.launch(server_name="0.0.0.0", share=false, in
- 6OS总结!_在处理器调度中,决定处理器执行哪个可运行程序
- 7chatgpt不好使?那是你不会问,github上收集的100多种问法,让你快速玩转chatgpt_awesome chatgpt 截图和屏幕录制正在共享您的屏幕。
- 8Arch/Manjaro换源+安装常用的软件+安装显卡驱动
- 9Qt开发笔记——动画_qanimationtimer
- 10uniapp实战仿写网易云音乐(二)—promise接口请求的封装和主页功能的实现,组件封装,配置下拉刷新_uniapp仿网易云音乐播放页面代码
让照片人物开口说话,SadTalker 安装及使用(避坑指南)_sadtaker
赞
踩
AI技术突飞猛进,不断的改变着人们的工作和生活。数字人直播作为新兴形式,必将成为未来趋势,具有巨大的、广阔的、惊人的市场前景。它将不断融合创新技术和跨界合作,提供更具个性化和多样化的互动体验,成为未来的一种趋势。
SadTalker介绍
西安交通大学开源了人工智能SadTaker模型,通过从音频中学习生成3D运动系数,使用全新的3D面部渲染器来生成头部运动,可以实现图片+音频就能生成高质量的视频。内含多个踩坑的解决办法,值得玩一玩。
可以根据一张图片、一段音频,合成面部说这段语音的视频。图片需要真人或者接近真人。目前项目已经支持stable diffusion webui,可以SD出图后,结合一段音频合成面部说话的视频(抖音常见的数字人)

环境准备
Anaconda介绍
Anaconda,中文大蟒蛇,是一个开源的Anaconda是专注于数据分析的Python发行版本,包含了conda、Python等190多个科学包及其依赖项。
Anaconda就是可以便捷获取包且对包能够进行管理,包括了python和很多常见的软件库和一个包管理器conda。常见的科学计算类的库都包含在里面了,使得安装比常规python安装要容易,同时对环境可以统一管理的发行版本。
下载地址:https://repo.anaconda.com/archive/
Index of /anaconda/archive/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
为什么要安装Anaconda?
Anaconda对于python初学者而言及其友好,相比单独安装python主程序,选择Anaconda可以帮助省去很多麻烦,Anaconda里添加了许多常用的功能包,如果单独安装python,这些功能包则需要一条一条自行安装,在Anaconda中则不需要考虑这些,同时Anaconda还附带捆绑了两个非常好用的交互式代码编辑器(Spyder、Jupyter notebook)。
总的来说,在Anaconda中conda可以理解为一个工具,也是一个可执行命令,其核心功能是包管理与环境管理。所以对虚拟环境进行创建、删除等操作需要使用conda命令。
annoconda环境安装
annoconda环境安装与使用详见:环境安装
配置镜像源
- conda config --add channels https://pypi.tuna.tsinghua.edu.cn/simple
- #豆瓣源
- conda config --add channels http://pypi.douban.com/simple/
-
- # 阿里源
- conda config --add channels https://mirrors.aliyun.com/pypi/simple/
-
- #中科大源
- conda config --add channels https://pypi.mirrors.ustc.edu.cn/simple/
-
- conda config --remove channels https://pypi.mirrors.ustc.edu.cn/simple/
- conda config --remove-key channels
-
- conda install numpy=1.19.2
-
- conda create --name myenv python=3.8
- conda env list
- conda activate myenv
- conda deactivate
- conda env remove --name myenv
注:给pip添加镜像和给conda添加镜像源是不同的,上述conda config添加的源实测不能用的(上述的是pip的镜像源,不能在conda下用),正确应该是:
给pip添加清华通道:
pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple给conda添加清华通道:
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
给conda添加社区通道:
conda config --add channels conda-forgeconda的镜像源也可以直接修改.condarc 的文件,conda 应用程序的配置文件。
Windows 用户无法直接创建名为 .condarc 的文件,可先执行 conda config --set show_channel_urls yes 生成该文件之后再修改。文件的一个示例:
- channels:
- - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main/
- - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free/
- - https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge/
- ssl_verify: true
- show_channel_urls: true
另附几个常用的镜像源:
- # 清华源
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/conda-forge
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/msys2
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main
- conda config --add channels https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/free
-
- # 中科大源
- conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
- conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
- conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/conda-forge/
- conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/msys2/
- conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/bioconda/
- conda config --add channels https://mirrors.ustc.edu.cn/anaconda/cloud/menpo/
SadTalker安装
SadTalker安装倒不复杂,但是安装成功非常的不容易。所以这里给出了避坑指南。主要是依赖和需要下载的东西太多太大了,光pytouch都需要2.1G,模型文件又是几个G。
这里有个坑是:最好使用conda来安装需要的包,且指定python的版本为3.8才行。如果指定版本为3.10,最后老半天来个个别pytouch的包找不到安装失败的尴尬,又得重来一遍,很耗时。
还有需要注意的是,一定要提前设置好镜像源啊,否则几天都别想安装成功,需要下载好几个G的东西。
- conda create -n sadtalker python=3.8
-
- conda activate sadtalker
网上给出的安装步骤如下:
- conda create -n sadtalker python=3.8
-
- conda activate sadtalker
-
- pip install torch==1.12.1+cu113 torchvision==0.13.1+cu113 torchaudio==0.12.1 --extra-index-url https://download.pytorch.org/whl/cu113
-
- conda install ffmpeg
-
- pip install -r requirements.txt
其实也可以直接执行webui.bat脚本即可,会自动的下载所有的依赖包(注:这种方式pytouch和下载的包都在venv的目录里,不支持指定下载pytorch的版本,默认的下载内容在launcher.py文件种能查看到)。
E:\test\python\SadTalker> .\webui.bat如果以上成功,仅代表环境安装ok,但是仍然是无法使用的,需要下载模型。在 sadtalker项目根目录下新建两个目录checkpoints 和gfpgan,下载好的模型分别放在这两个文件夹。模型比较大,checkpoints内的文件就有3.3G大小,gfpgan下的文件大小600M左右。不建议从github上下载,那样下载太慢了。
这里给出百度云盘地址:
另外下载github上的资源,推荐使用镜像站点的方式下载。
这里推荐一个:GitHub Proxy 代理加速
再推荐几个快速访问和下载github资源的站点:
- #通过代理网站下载
- #Release、Code(ZIP) 文件加速:
- https://gh.api.99988866.xyz
- https://github.rc1844.workers...
- https://ghgo.feizhuqwq.worker...
- https://git.yumenaka.net
- https://github.com.cnpmjs.org
- https://mirror.ghproxy.com/
- https://ghproxy.com/
- https://toolwa.com/github/
-
- #Git Clone 加速:
- https://github.do
- https://gitclone.com
- https://hub.fastgit.xyz
- https://ghproxy.com
- https://hub.0z.gs
具体哪个速度快,请自行找一些大文件来测速。我常使用的是ghproxy.com下载github上的文件,因为名字好记,速度也不错,比百度网盘快很多。
如何使用
启动UI的方式生成
E:\test\python\SadTalker> .\webui.bat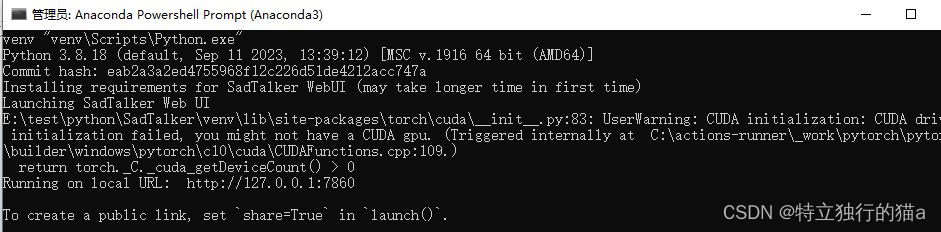
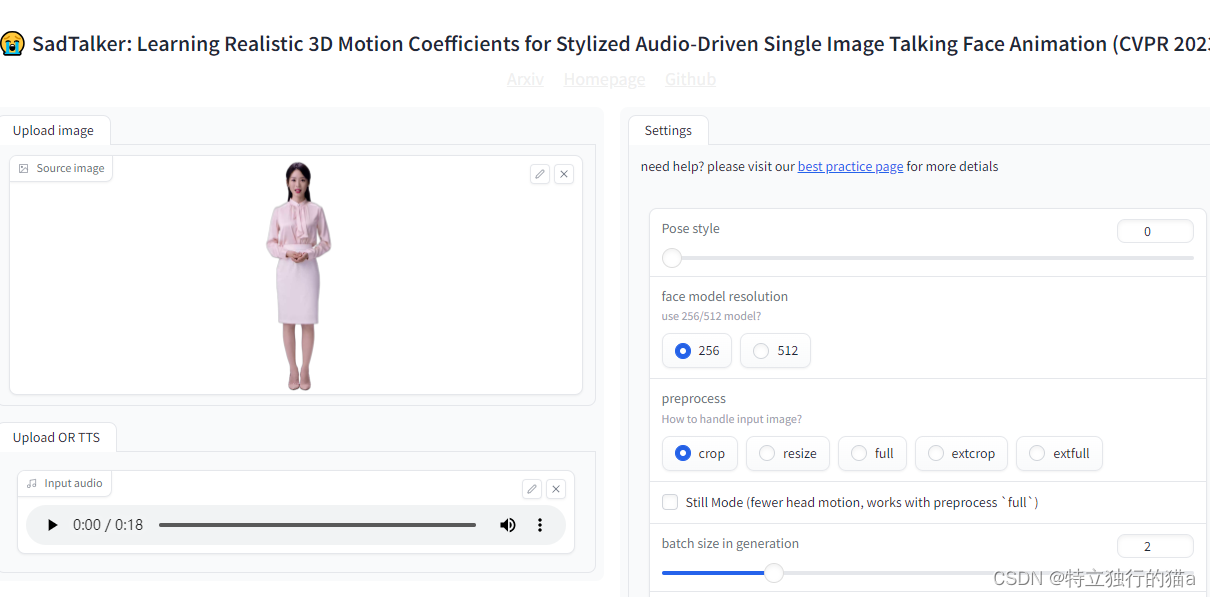
命令行方式视频生成
通过图片+语音生成视频:
python inference.py --driven_audio data/sample.wav --source_image data/sample.png通过视频片段+语音生成视频:
python inference.py --driven_audio data/sample.wav --source_image data/sample.mp4通过参数对生成的视频进行控制:
- --preprocess full 表示完整图片
-
- --still 可以减少头部运动
-
- --enhancer gfpgan
参数1是保留全身,如果不加这个参数,则视频中只剩头部
参数2是减少头部晃动,头部晃动是会和脖子的连接部位脱节
参数3是基于gfpgan对视频进行增强
查看webui.bat文件内容可知,如果是直接执行webui.bat,默认会把pytorch下载到SadTalker项目的venv目录下,这样如果直接执行上述命令行方式的话是不行的,会提示pytorch和其它一些未安装。如果确实需命令行下执行,可参考webui.bat文件内容,临时更改环境变量。
- call .\venv\Scripts\activate.bat
-
- set PYTHON="venv\Scripts\Python.exe"
-
- $PYTHON inference.py --driven_audio data/sample.wav --source_image data/sample.png
webui.bat文件内容如下:
- @echo off
-
- IF NOT EXIST venv (
- python -m venv venv
- ) ELSE (
- echo venv folder already exists, skipping creation...
- )
- call .\venv\Scripts\activate.bat
-
- set PYTHON="venv\Scripts\Python.exe"
- echo venv %PYTHON%
-
- %PYTHON% Launcher.py
-
- echo.
- echo Launch unsuccessful. Exiting.
- pause
最终测试效果:
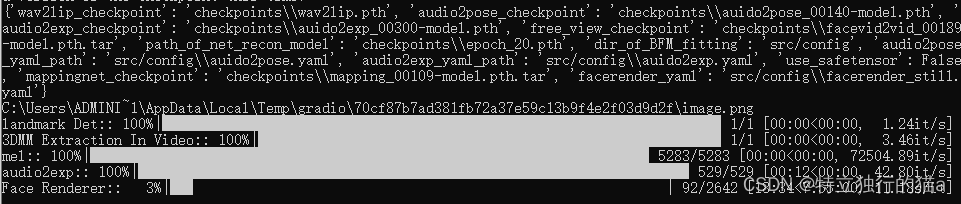
成功生成视频:

可以完美跑起来,就是生成视频的速度太慢太慢啦,要等一会儿才完成。这也跟语音文件大小有关系,平均十多秒才处理一张图片。另外一个原因,cmd窗口提示:
- Launching SadTalker Web UI
- E:\test\python\SadTalker\venv\lib\site-packages\torch\cuda\__init__.py:83: UserWarning: CUDA initialization: CUDA driver initialization failed, you might not have a CUDA gpu. (Triggered internally at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\cuda\CUDAFunctions.cpp:109.)
- return torch._C._cuda_getDeviceCount() > 0
电脑没有安装cuda,没利用GPU的运算能力。
关于cuda
2006年,NVIDIA公司发布了CUDA(Compute Unified Device Architecture),是一种新的操作GPU计算的硬件和软件架构,是建立在NVIDIA的GPUs上的一个通用并行计算平台和编程模型,它提供了GPU编程的简易接口,基于CUDA编程可以构建基于GPU计算的应用程序,利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。它将GPU视作一个数据并行计算设备,而且无需把这些计算映射到图形API。操作系统的多任务机制可以同时管理CUDA访问GPU和图形程序的运行库,其计算特性支持利用CUDA直观地编写GPU核心程序。
CUDA提供了对其它编程语言的支持,如C/C++,Python,Fortran等语言。只有安装CUDA才能够进行复杂的并行计算。主流的深度学习框架也都是基于CUDA进行GPU并行加速的,几乎无一例外。还有一个叫做cudnn,是针对深度卷积神经网络的加速库。
CUDA在软件方面组成有:一个CUDA库、一个应用程序编程接口(API)及其运行库(Runtime)、两个较高级别的通用数学库,即CUFFT和CUBLAS。CUDA改进了DRAM的读写灵活性,使得GPU与CPU的机制相吻合。另一方面,CUDA提供了片上(on-chip)共享内存,使得线程之间可以共享数据。应用程序可以利用共享内存来减少DRAM的数据传送,更少的依赖DRAM的内存带宽。
cuda解决办法
首先检查显卡驱动,CUDA,cudnn,以及pytorch的版本是否匹配,如果不匹配,需要卸载之后重装对应的版本。
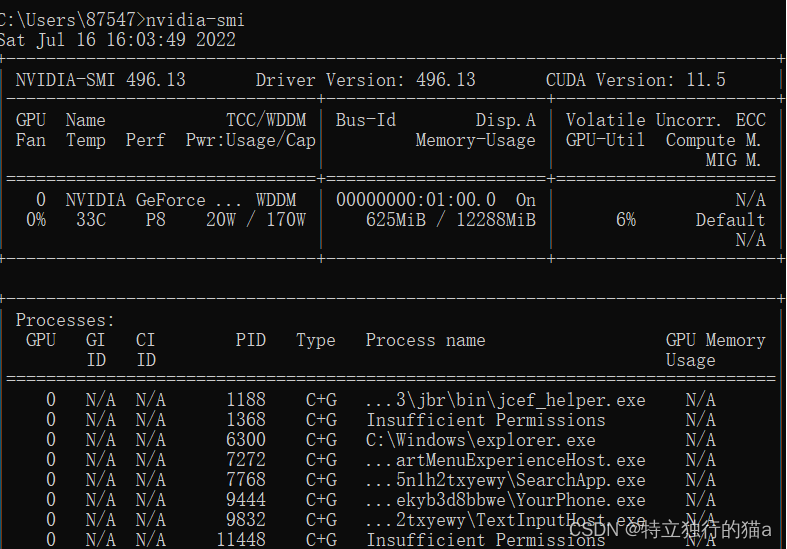
如何查看CUDA版本?
1.搜索栏输入cmd回车(进入cmd)
2.输入下面语句
nvidia-smi或者:
PS C:\Program Files\NVIDIA Corporation\NVSMI> .\nvidia-smi.exe能看到类似以下内容,其中就有CUDA版本信息:
如果C盘的Program Files目录下就没有NVIDIA GPU Computing Toolkit文件夹,nvdia没有安装成功,需要安装CUDA Toolkit。
在设备管理器(此电脑–右键–属性)的显示适配器中可以查看自己的显卡型号,去官网下载对应的CUDA Toolkit 。
其他资源
还是搞不懂Anaconda是什么?读这一篇文章就够了-CSDN博客
annoconda安装使用及镜像源的添加,提高软件下载速度_conda镜像安装-CSDN博客
Anaconda安装教程(带图文)及使用、配置指南含编辑器对比 - 知乎
conda常用命令详解_conda显示所有环境-CSDN博客
annoconda安装使用及镜像源的添加,提高软件下载速度_conda镜像安装-CSDN博客
Anaconda 中使用 conda 配置虚拟环境与管理安装包 - 知乎
如何判断自己的电脑里有没有cuda以及查看cuda版本_CheCacao的博客-CSDN博客
八、让照片说话之SadTalk_vandh的博客-CSDN博客
手把手教安装SadTalker教程_think_张大彪的博客-CSDN博客
彻底搞懂“旋转矩阵/欧拉角/四元数”,让你体会三维旋转之美_欧拉角判断动作-CSDN博客
SadTalker项目上手教程_Alphathur的博客-CSDN博客
SadTalker(CVPR2023)-音频驱动视频生成_‘Atlas’的博客-CSDN博客
SadTalker:Stylized Audio-Driven Single Image Talking Face Animation(CVPR2023)_c2a2o2的博客-CSDN博客
MakeItTalk:让你的人物图片或者动画动起来(学习笔记)_一名不想学习的学渣的博客-CSDN博客
MakeItTalk用一段语音让一张照片动起来-CSDN博客
AI数字人:换脸模型Faceswap_智慧医疗探索者的博客-CSDN博客
AI数字人:最强声音驱动面部表情模型VideoReTalking_智慧医疗探索者的博客-CSDN博客
AI换脸软件DeepFaceLab本地安装使用教程,AI视频换脸详细步骤 - 知乎
最强的AI视频去码&图片修复模型:CodeFormer-CSDN博客
Pytorch 最全入门介绍,Pytorch入门看这一篇就够了 - 知乎
【深度学习】PyTorch基础入门(爆肝2万字)_柒筱暮的博客-CSDN博客
https://download.csdn.net/download/qq_30920479/88059273?spm=1001.2014.3001.5506

