
- 1w3wp.exe 发生.net framework异常_一文看懂 .NET 的异常处理机制、原则以及最佳实践...
- 2vue项目里使用scss全局变量_vue scss 全局变量
- 3利用flask将yolov5算法封装成在线推理服务
- 4使用UnityWebRequest发送Post请求深度解析_unitywebrequest post
- 5Python代码实现用户循环输入成绩,输出显示成绩所对应的等级_python输入一个成绩,输出对应的登记(a:100-85, b:84-70, c:69-60, d
- 6开发实战教学视频|快速实现微信小程序视频弹幕功能_微信弹幕游戏开发
- 7实现授权码模式登录和密码模式登录的spring oauth2服务_oauth2 怎么兼容密码模式和授权码模式
- 8书生·浦语大模型实战营-学习笔记4
- 9Pytorch实现鸟类识别(含训练代码和鸟类数据集)_鸟的数据集
- 10配置TensorFlow的cuda环境教程_tensorflow cuda
从零开始配深度学习服务器2023.04.01_从零开始配一个深度学习服务器
赞
踩
这是一篇比较详细的新从零开始配深度学习服务器教程,大家可以根据小标题直接跳转到需要参考的部分。
1.制作可启动 Ubuntu U盘
需要将下载的 ISO 写入 U 盘以创建安装介质,这里推荐使用Rufus,Ubuntu官网上推荐的balenaEtcher烧录时会报错。
- 插入U盘
- 启动 Rufus
- “设备”处选择您插入的U盘
- 点击“选择”插入ubuntu-22.04.2-desktop-amd64映像文件
- 点击“开始”,开始烧录
- 若有警告弹窗,阅读一下,没有问题点击确定
- 烧录完成,点击”关闭“
bootable U盘安装介质制作完成。

2.安装Ubuntu
将 U 盘插入要用于安装 Ubuntu 的笔记本电脑或 PC,然后启动或重启设备。它应该会自动识别安装媒体,选择”Install Ubuntu"(一般是第一行)。这里用的是有两块硬盘,512G SSD,1T机械硬盘的 PC。如果没有自动识别,尝试在启动期间按住F1/ F2/F12进入BIOS,修改开机启动顺序。
然后应该就能看见欢迎页面。(下图皆以官网英文界面举例)
可以下拉到最后选择“中文”,点击"Install Ubuntu"

选择键盘布局,应该是下拉到最后选择中文,右边选择“Chinese Hanyupinyin”类似(方便以后在Ubuntu中可以中文输入),点击“继续”

一般选择“正常化安装”,点击“继续”

如果有两块硬盘想自己分区的话,选择"Something else",否则选"Erase disk and install Ubuntu",一般不会选择新旧Ubuntu系统共存的那个选项。这里以选"Something else"为例,点击“Install Now”。

看到的界面类似上图(图片来源教程,您可以参考着看这份教程,比较详细),建议先点击“还原”找到自己的两个硬盘,选中"/dev/sda1"等非空闲分区,点击“—”,清空所有内容,这样磁盘就都变成空闲了。其中名为nvme0n1的磁盘是固态硬盘,大小为512G,名为sda的磁盘为机械硬盘,大小为1T。
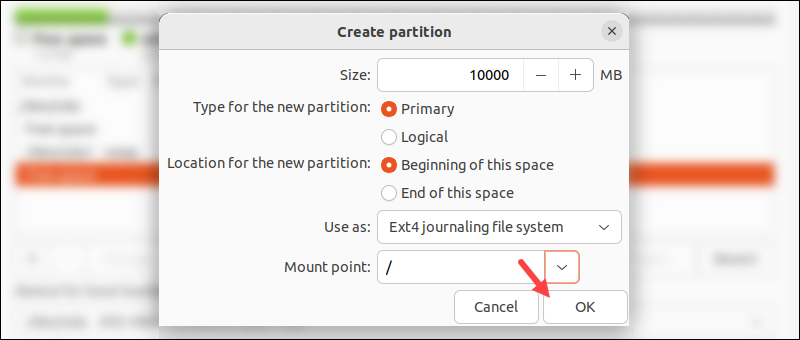
删除完所有分区后点击"+",新建以下四个分区:(注意“主分区”还是“逻辑分区”不要选错了,下图只是找的示例,错勾成了“Primary")
硬盘 大小 类型 位置 分区(Use as) 挂载点 SSD 500M 主分区 空间起始位置 efi系统分区 无 SSD 与电脑内存一样大(比如我这里32G=32768M) 逻辑分区 空间起始位置 swap分区 交换空间 SSD SSD剩余所有空间 主分区 空间起始位置 Ext4分区 / 机械硬盘 机械硬盘所有空间 主分区 空间起始位置 Ext4分区 /home 其中efi系统分区是启动引导相关的,swap分区是交换分区,一般设置为与电脑内存一样大就行,/是系统根目录,将SSD的剩余所有空间都给它,/home用于存放用户数据等,整个机械硬盘都分给它。整个安装完成后可以打开Terminal,输入 df -hl 查看。
创建完四个分区后,点击“Install Now”




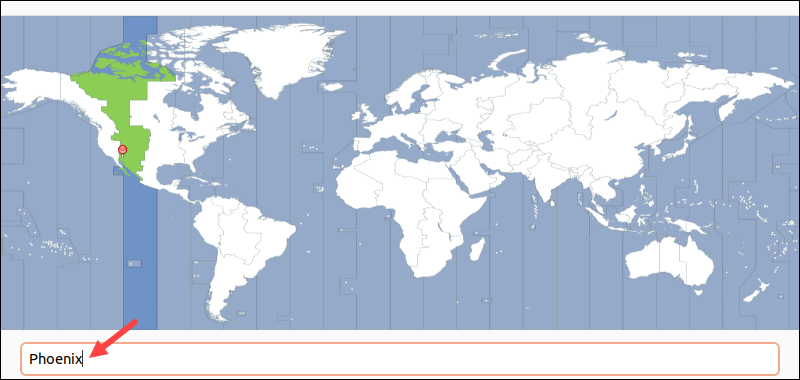
接下来选择时区,点击地图上的中国处,Shanghai
创建用户帐户,然后点击”继续“

完成并重启,移除安装介质并单击“Enter"键。系统重新启动时,会出现登录屏幕。单击用户名并输入安装过程中设置的密码,就安装成功了。



3.安装完Ubuntu后的初始化配置
打开终端(快捷键”Ctrl" +"Alt"+"T"新建窗口,”Ctrl" +"Shift"+"T"新建标签页)
在安装好系统后,如果直接打开一个终端执行su的话,会得到报错
su: 认证失败。因为root用户默认是锁定状态,不允许登录,因此需要进行配置。终端执行:sudo passwd root会先要求你输入用户密码,然后会要你输入新的密码以及确认,这里新的密码就是root的密码,可以设置的和用户密码不一样,也可以一样。设置后,再次执行:
su输入刚刚设置的root密码后,就可以进入root了。按”Ctrl" +"D"可退出root。
更新系统软件
禁止内核更新,不然后边很容易出现驱动版本错误等各种问题,导致系统崩溃。执行:
dpkg --get-selections |grep linux可以查看电脑已安装的内核版本,比如输出如下:
然后再执行:
uname -a可以查看当前正在使用的内核版本。比如:
表明我在用的是5.11.0-41-generic这个版本(注意不是5.8.0-43-generic)。一般只禁止和上述输出版本一致的image和headers即可,如果想保守起见,也可以将所有与该版本一致的内容都禁止掉。比如我这里禁止的有:(注意版本号检查与uname -a输出一致)

4. 安装Nvidia驱动,Cuda,Cudnn
安装Cuda,Cudnn往往需要先安装Nvidia驱动,所以这里把它们放在一个标题下。
进行这一步之前一定要进入BIOS把secure boot关掉,
否则安装新驱动后,会报错:
NVIDIA-SMI has failed because it couldn't communicate with the NVIDIA driver. Make sure that the latest NVIDIA driver is installed and running.
如果报了这个错还重启Ubuntu,会导致无法启动系统,左上角光标一闪一闪,黑屏。
挽救办法:
- 进入BIOS把secure boot关掉,重新启动,看是否恢复正常
- 仍然黑屏就要,开机进入 tty命令行界面,重装显卡驱动,教程
实在不行,返回第二步重装系统吧,下次记得先进入BIOS把secure boot关掉
要安装nvidia驱动,首先删除旧驱动:
sudo apt-get purge nvidia*禁止自带的nouveau nvidia驱动:
sudo gedit /etc/modprobe.d/blacklist-nouveau.conf在打开的空白文件内,填入如下两行内容,然后保存关闭。(打开时有问题不要紧,把这两句话填进去就行,如果不放心可以用su -进入root,然后用nano命令编辑)
更新配置文件:
sudo update-initramfs -u!!!!!然后不要重启系统,
直接装新的驱动
添加Graphic Drivers PPA:
sudo add-apt-repository ppa:graphics-drivers/ppa如果一直加载不出来, 用-E绕过代理(教程):sudo -E add-apt-repository ppa:graphics-drivers/ppa
更新:
sudo apt-get update查看合适的驱动版本:
ubuntu-drivers devices输出如下:
可以根据推荐版本进行安装,但我还是建议安装nvidia-driver-470,因为装这个的时候成功了,装其他的时候没成功。
sudo apt-get install nvidia-driver-470安装完成后,重启系统:
sudo reboot执行命令sudo nvidia-smi,可以判断是否成功安装驱动:


安装CUDA
首先从官网下载自己需要的cuda版本,下载链接。可以选择cuda11.7(下面涉及到版本号的记得替换成自己的版本),配置选项如下所示:
选好之后,会自动给出安装的命令,如下图所示:
依次执行官网给出的两行命令,在下载run文件的过程中,可以先安装一下依赖库(不安装的话安装cuda的过程会报错),执行如下命令:
sudo apt-get install freeglut3-dev build-essential libx11-dev libxmu-dev libxi-dev libgl1-mesa-glx libglu1-mesa libglu1-mesa-dev下面是安装时的选项:
!!!!!接下来会选择是否安装驱动等,这一步比较重要。驱动的话我们在前面已经安装好了,这里需要把它的选项给去掉(像法语一样,”X"意味着选中)。界面操作的方式在底部有说明,设置好的选项如下图所示,然后选择install。
配置环境
sudo gedit ~/.bashrc最后面加入
保存关闭,然后在终端执行:
source ~/.bashrc使修改立即生效。接下来,给cuda创建软链接:
sudo ln -s /usr/local/cuda-11.7 /usr/local/cuda检查 CUDA是否顺利安装:
nvcc -V如果有出现类似下图,表示CUDA Toolkit已经安装成功





安装cudnn
安装好cuda后,需要下载cudnn对相应文件进行替换。cudnn的下载链接。如下图所示:
下载cudnn需要登陆nvidia的账号,没有的话就用邮箱去注册一个,免费。
下载 cuDNN Library for Linux [x86_64]
下载完成后,打开一个终端,依次执行如下命令:
配置好后即可。下面测试cudnn
虽然前面我们默认选择安装了cuda的示例,但是仍然找不到/usr/local/cuda-11.7/samples文件夹,自己去github上搜索cudnn samples v8测试,link
如果遇到 fatal error: FreeImage.h: No such file or directory
sudo apt install libfreeimage3 libfreeimage-dev再编译一下
如果没有问题则会返回如下:

5.结语
如果您比较顺利的话,到这里就已经完成“配深度学习服务器”中最难的部分了。接下来您可以继续安装Anaconda,创建虚拟环境,在虚拟环境中安装Pytorch训练深度学习模型。希望能帮助到大家

