
- 1Single Shot 6D Object Pose Prediction代码复现--测试_gen6d csdn
- 2yolov5 web端部署进行图片和视频检测_yolov5 flask web 部署
- 3qt for android存储文本文件到本地_qt andriod 文件读写
- 4jmeter并发误区及集合点(同步计时器),吞吐量定时器_jmeter设置1秒100并发和定时器有什么区别
- 5树莓派使用 snowboy 安装_树莓派 安装swig
- 6Node.js开发-包管理工具
- 7【java爬虫】selenium+browsermob入门实战_java selenium proxy-pool
- 8Maven 中央仓库地址大全_maven官方仓库地址
- 9HCIA-HarmonyOS设备开发认证V2.0-3.2.轻量系统内核基础-中断管理
- 10UI素材|最全面的移动端 UI KIT 模板_ui界面展开的模板叫什么
【文献翻译】A review of epileptic seizure detection using machine learning classifiers_bern-barcelona数据集
赞
踩
基于机器学习分类器的癫痫发作检测综述
文章目录
摘要
癫痫是一种严重的慢性神经系统疾病,可以通过分析大脑神经元产生的脑信号来检测。神经元以复杂的方式相互连接,与人体器官进行通信并产生信号。这些脑信号的监测通常使用脑电图(EEG)和脑皮层电图(ECoG)媒介完成。这些信号复杂、有噪声、非线性、非平稳,并产生大量数据。因此,癫痫发作的检测和大脑相关知识的发现是一项具有挑战性的任务。机器学习分类器能够对EEG数据进行分类,检测癫痫发作,并在不影响性能的情况下揭示相关的感知模式。因此,许多研究人员已经开发了许多使用机器学习分类器和统计特征的癫痫检测方法。主要的挑战是选择合适的分类器和特征。本文的目的是根据统计特征和机器学习分类器的分类——“黑盒”和“非黑盒”,概述过去几年中这些技术的广泛种类。本文介绍的最新方法和思想将对癫痫检测和分类以及未来的研究方向有详细的了解 .
1 - 引言
Epilepsy(癫痫)一词起源于拉丁语和希腊语单词“epilepsia”,意思是“seizure”或“seize upon”。它是一种严重的神经系统疾病,具有独特的特征,易于反复发作[1]。在巴比伦医学文献中发现的癫痫的背景是3000多年前写的[2,3]。这种疾病不仅限于人类,还扩展到包括狗、猫和老鼠等所有哺乳动物物种。然而,癫痫这个词并不能提供任何关于癫痫病因或严重程度的线索;它在世界范围内分布不明显且均匀[1,4]。
关于原因的几种理论已经存在。主要原因是大脑内部的电活动紊乱[1,5,6],这可能是由多种原因[7]引起的,如畸形、分娩时缺氧和血液中的低糖水平[8,9]。在全球范围内,癫痫影响了大约5000万人,其中1亿人一生中至少受到一次影响[5,10]。总的来说,它占世界疾病负担的1%,据报道患病率为0.5–1%[4,11]。癫痫的主要症状是患者多次发作。它会导致大脑突然崩溃或异常活动,从而促使患者的行为、感觉发生不自觉的改变,并丧失瞬间意识。通常情况下,癫痫发作持续几秒钟到几分钟,可以在任何时候发生,没有任何先兆。这会导致严重的伤害,包括骨折、烧伤,有时甚至死亡[12]。
1.1 - 癫痫类型
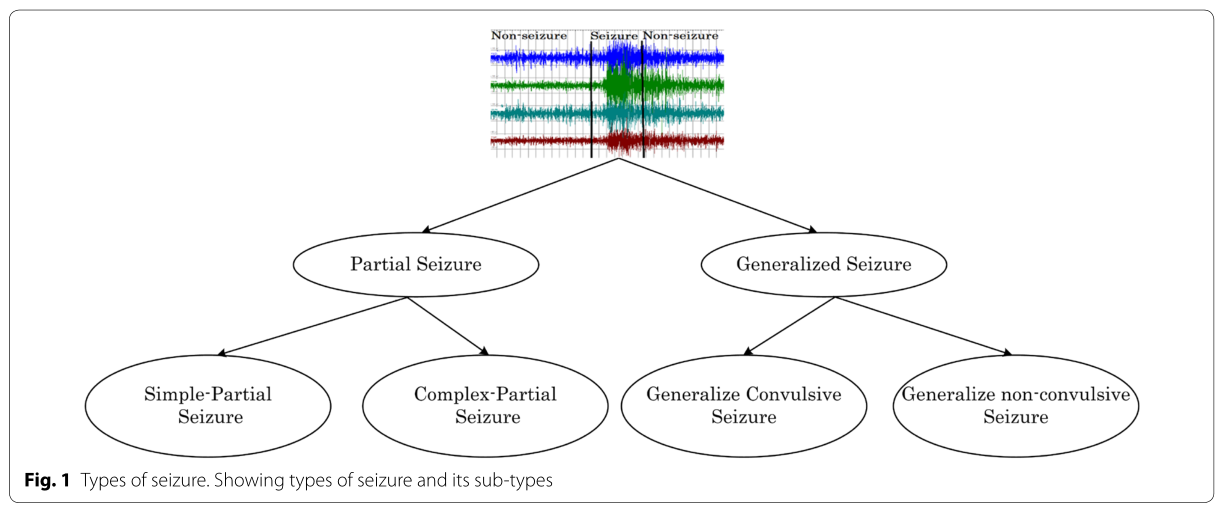
根据症状,神经专家将癫痫分为两大类:部分性发作和全身性发作[7,13]——如图1所示。部分性发作,也称为“局灶性发作”,只会导致大脑半球的一部分受到影响。
- 部分性发作有两种类型:简单部分性发作和复杂部分性发作。简单来说,患者不会失去意识,但无法正常沟通。在复杂的部分,一个人对周围环境感到困惑,开始表现出不正常的行为,比如咀嚼和咕哝;这被称为“局灶性意识障碍发作”。
- 相反,在全身性癫痫发作中,大脑的所有区域都会受到影响,整个大脑网络很快就会受到影响[14]。全身性癫痫有多种类型,但大致分为两类:惊厥性和非惊厥性。
1.2 论文的主要贡献
总之,本文的贡献如下:
- 我们按照五个主要维度进行了审查。首先,研究人员采用EEG、ECoG或两者同时用于癫痫检测;二是显著特征;第三,机器学习分类器;第四,在癫痫发作期间分类器的性能,最后是知识发现(例如,癫痫发作定位)。
- 通过研究,发现决策树集成(即决策森林-随机森林)分类器优于其他分类器(ANN、KNN、SVM、单个决策树)。
- 我们还建议,决策森林算法如何能够更有效地用于除癫痫检测之外的其他知识发现任务。
- 这项研究将帮助研究人员根据他们的数据科学背景,确定哪些统计和机器学习分类器与进一步改进现有癫痫检测方法更相关。
- 该研究还将帮助读者了解公开的癫痫数据集。
- 最后,我们通过当前的回顾提供了我们的观察结果,并对该领域未来的研究提出了建议。
论文的结构安排如下。“数据科学家在癫痫发作检测中的作用”部分概述了EEG数据集中的机器学习专家。初步要求见“癫痫发作检测框架”一节;它提出了癫痫检测的一般模型,并以后续的方式解释了每个步骤。“公开可用数据集”部分提供了基准数据集的详细信息及其描述。“基于统计特征和机器学习分类器的癫痫检测”部分介绍了使用不同机器学习分类器进行癫痫检测的文献综述,并进行了详细比较。“癫痫定位”一节回顾了使用机器学习分类器识别受影响的大脑叶的工作。在“现有文献中发现的问题”部分,我们探讨了之前工作中的问题,并强调了差距。总的来说,“关于有能力的分类器和统计特征的观察”部分报告了我们对合适的分类器和特征的观察。“癫痫发作检测的研究方向”部分强调了该研究领域的未来方向,然后是总结论文的“结论”部分。
2 - 数据科学家在癫痫发作检测中的作用
机器学习在健康和生物数据集上的应用显著提高了结果[15,16]。不同领域的研究人员/科学家,特别是数据挖掘和机器学习,积极参与提出更好的癫痫检测解决方案。机器学习已被广泛应用于从不同领域的数据集中发现有意义的模式[17,18]。它在解决医疗保健等多个学科的问题方面发挥着重要和潜在的作用[17,19-25]。机器学习在癫痫检测、癫痫偏侧化、鉴别癫痫状态和定位的大脑数据集上也有应用[26–29]。这是由各种机器学习分类器完成的,如ANN、SVM、决策树、决策森林和随机森林[26,28]。
当然,在过去,人们对癫痫发作检测、应用特征、分类器和声称的准确性[27,30–33]进行了大量审查,但没有关注数据科学家在研究神经疾病数据集时面临的挑战。因此,本文详细研究了机器学习在癫痫发作检测和其他相关知识发现任务中的应用。在这篇综述中,收集的文章来自相关领域的知名期刊。这些参考文献由SCOPUS或科学网(WOS)编制索引。
此外,我们还考虑了一些排名良好的会议论文。大量文献涵盖了对用于癫痫检测的EEG数据集的不同特征和分类器的深入分析[31,34,35]。特征提取和分类技术的应用都是具有挑战性的任务。之前的文献表明,在过去几年中,机器学习分类器在从EEG信号中提取有意义的模式方面的应用越来越受到关注,这有助于检测癫痫发作、癫痫在大脑中的位置以及其他令人印象深刻的相关知识发现[28、36、37]。30年前,Jean Gotman[6,38–40]通过应用不同的计算和统计技术进行自动癫痫检测,分析并提出了有效利用EEG信号的模型。此外,该研究通过不同的信号处理方法和数据科学方法进行,以提供更好的结果[27,34,41–47]。
3 - 癫痫检测框架
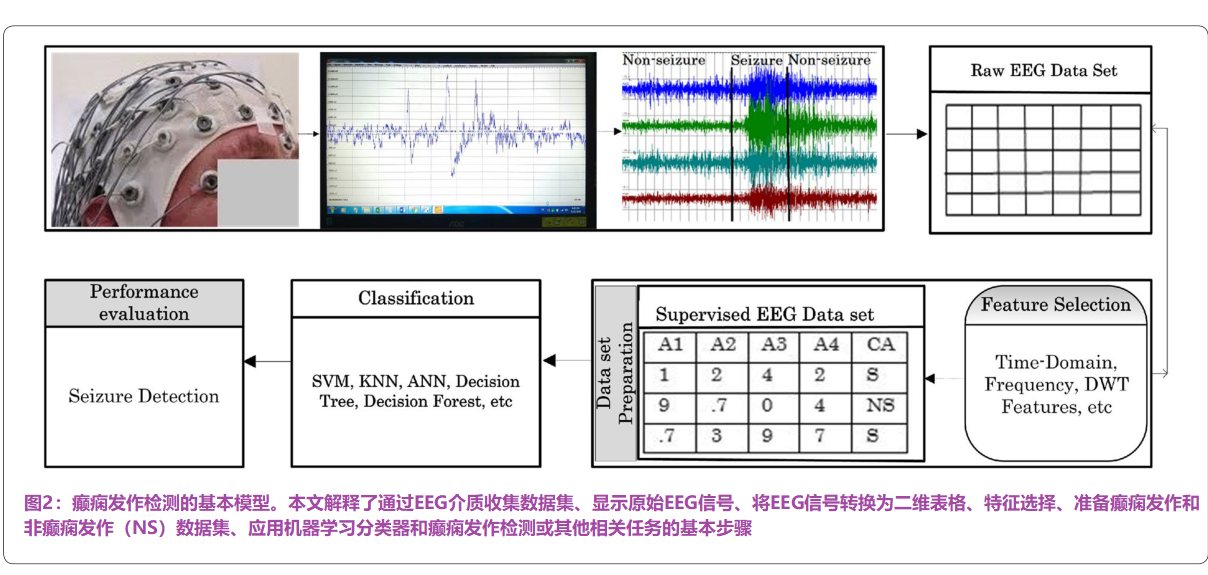
在本节中,我们展示了用于从EEG / ECoG癫痫发作数据集进行癫痫发作检测的模型的图形框架,如图2所示。该过程包括四个步骤:数据收集、数据准备、应用机器学习分类器和性能评估。
3.1 - 数据收集
最初的要求是收集大脑信号的数据集。为此,使用了不同的监控工具。通常,最常用的设备是EEG和ECoG,因为根据10–20国际体系[48],它们的通道或电极通过胶水植入头皮表面的不同叶。它们中的每一个都有一个与脑电图设备的接线,提供关于电压变化的及时信息,以及时间和空间信息[49]。如图2所示,EEG通道放置在受试者的头皮上,EEG监控工具读取电信号,并在屏幕上显示这些原始信号。此外,分析员仔细监控了这些原始信号,并将其分为“癫痫发作”和“非癫痫发作”状态。
3.2 数据转换
数据采集后,下一个关键步骤是将信号数据转换为二维表格格式。这样做的原因是为了便于分析,并提供必要的知识,如癫痫检测。这个数据是原始的,因为它还没有被处理。因此,不适合提供相关信息。为了进行处理,采用了不同的特征选择模式。这一步还将数据集显示为受监督的,这意味着它为class属性提供了可能的class值。
3.3 数据集准备
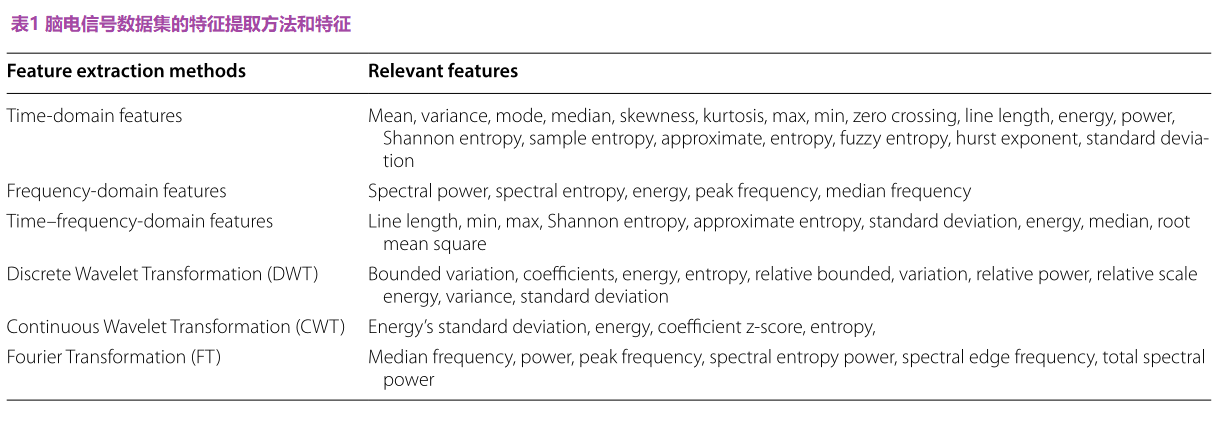
对于数据转换,数据处理是从收集的原始数据集中提取有意义信息的决定性步骤。因此,使用了不同的特征提取技术;如表1所示。这些方法通常适用于提取的EEG信号数据集[31,34]。原始数据集在不同的统计度量值方面变得丰富。
经过特征提取处理后,数据集的信息量变得更大,最终有助于分类器检索更好的知识。
3.4 应用机器学习分类器和性能评估
为了获得高准确率的癫痫检测率,并从EEG处理的数据集中探索相关知识,使用了不同的有监督和无监督机器学习。
3.4.1 分类
在分类中,数据集 D D D有一组“非类属性”和一组“类属性”。它们是主成分,它们的相关知识非常重要,因为两者都与潜在分类密切相关。目标属性被定义为“类属性”C,它包含多个类值,例如,扣押和非扣押。相反,属性 A = { A 1 , A 2 , A 3 … A n } A=\left\{A_1, A_2, A_3…A_n \right\} A={A1,A2,A3…An}被称为“非类属性”或预测器[50,51]。以下分类器,如SVM[52]、决策树[53]和决策森林[54]被应用于处理后的EEG数据集,用于癫痫检测。
3.4.2 表现评估
所得结果的准确性用于评估不同的方法。最流行的训练方法是十倍交叉验证[55],其中每个折叠,即数据集的一个水平段被视为测试数据集,其余九个段被用作训练数据集[56,57]。除了准确度,分类器的性能通常通过以下指标来衡量,例如精度、召回率和f-score[58]。这是基于表2所示的四种可能的分类结果:真阳性(TP)、真阴性(TN)、假阳性(FP)和假阴性(FN)。

Precision是真阳性与检测为阳性(TP+FP)病例总数的比率。 它是正确的选定样本的百分比,如等式1所示。高精度意味着低假阳性率。

Recall是真实阳性病例与实际阳性病例的比率。方程式2显示了已选择的正确样本的百分比。
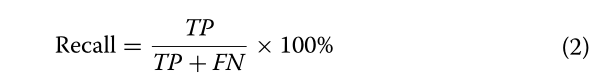
尽管获得了高召回率的分类器结果,但这并不表明分类器在精度方面表现良好。因此,必须计算精度和召回率的加权调和平均值:这种测量被称为F-Measure Score,如等式3所示。考虑了假阳性和假阴性。一般来说,它比准确性更有用,尤其是当数据集不平衡时。

4 - 公开可用的数据集
对于数据科学家和研究人员来说,使用的数据集对于评估他们提出的模型的性能非常重要。同样,在癫痫发作检测中,我们需要捕捉大脑信号。脑电图记录是监测大脑活动最常用的方法。这些记录在机器学习分类器中起着至关重要的作用,机器学习分类器以不同的方式探索癫痫发作检测的新方法,如发作癫痫检测、快速癫痫检测、患者癫痫检测和癫痫定位。公开可用数据集的意义在于,它们提供了一个基准,用于分析和比较结果。在下一节中,我们将描述广泛用于癫痫的流行数据集。
4.1 - 波士顿儿童医院麻省理工学院脑电图数据集 (CHB-MIT)
该数据集在physionet服务器上公开,由麻省理工学院波士顿儿童医院(CHB-MIT)准备[59,60]。它可以通过Cygwin工具轻松收集,Cygwin工具与physionet服务器交互。它包含每个CHB患者发作和非发作脑电图记录的数量[61]。数据集包括23名患者;5名男性,年龄3-22岁,17名女性,年龄1.5-19岁。每个患者都包含多个**欧洲数据格式(.edf)**的癫痫发作和非癫痫发作记录文件,代表癫痫发作开始和结束时间的峰值,在名为“EDFbrowser”的浏览器上很容易看到。主要数据集为1-D格式,包含EEG信号,这些信号通过根据10-20国际系统放置在大脑表面的不同类型通道获得。数据集的所有这些信号均以256Hz的频率采样。
4.2 - 加利福尼亚大学癫痫中心ECoG数据集
这是一个公开的来自癫痫患者的皮层电图(ECOG)信号的数据集,该信号来自旧金山加利福尼亚大学癫痫中心(UCSF)〔62〕。它最初是通过在头皮上植入76个电极(12个电极)和非侵入性(64个电极)来收集的。它总共包括16个文件。在这些文件中,有八份(F1、F2和··F8)被归类为“发作前”,即癫痫发作前的阶段。其余的文件(F9、F10、F11、·F16)代表“发作期”阶段的数据。采集的数据以400 Hz(即400个周期/s)的频率采样,总持续时间为10 s。因此,每个文件中有(400个周期/s×10 s)4000个周期[63]。
4.3 - The Freiburg—EEG dataset
该数据集收集自21名患有难治性局灶性癫痫的患者(8名男性,年龄13-47岁,13名女性,年龄10-50岁)的侵入性脑电图记录。这是在德国弗莱堡大学医院癫痫中心进行的侵袭性术前癫痫监测期间记录的[64]。在21名患者中,13名患者有24小时的记录,8名患者的记录时间少于24小时。这些记录是发作间期的,总共提供了88次癫痫发作。
4.4 - 波恩大学脑电图数据集
该数据集由五个子集组成,其中每一个子集(A–E)包含100个单通道记录,每个子集的持续时间为23.6秒,由国际10–20电极放置方案捕获。所有信号都用相同的128通道放大器系统通道记录[65]。
4.5 - 伯尔尼-巴塞罗那-脑电图数据集(BERN-BARCELONA)
该数据集包括来自五名药物耐受性颞叶癫痫患者的脑电图记录,其中3750份为局灶性和3750份为非局灶性双变量脑电图文件。三名患者无癫痫发作,两名患者术后仅有先兆,但无其他癫痫发作。用颅内条和深度电极记录多通道EEG信号。电极植入采用10-20位。EEG信号的采样频率为512或1024 Hz,这取决于它们记录的通道是否多于或少于64个。根据颅内脑电图记录,他们能够定位所有五名患者开始癫痫发作的大脑区域[66]。该数据集适用于癫痫定位。
5 基于统计特征和机器学习分类器的癫痫发作检测
本节详细介绍了使用统计特征、分类器——“黑盒”和“非黑盒”进行癫痫检测的工作。如表3所示。简言之,“黑匣子”分类器是那些提供准确度而不提及结果背后原因的分类器,如ANN和SVM[67]。他们无法解释自己的分类步骤。然而,“非黑盒”分类器,如决策森林和随机森林,能够解释处理的每个步骤,这是人类可以理解的。因此,它有助于提高人类可解释知识的准确性[68]。
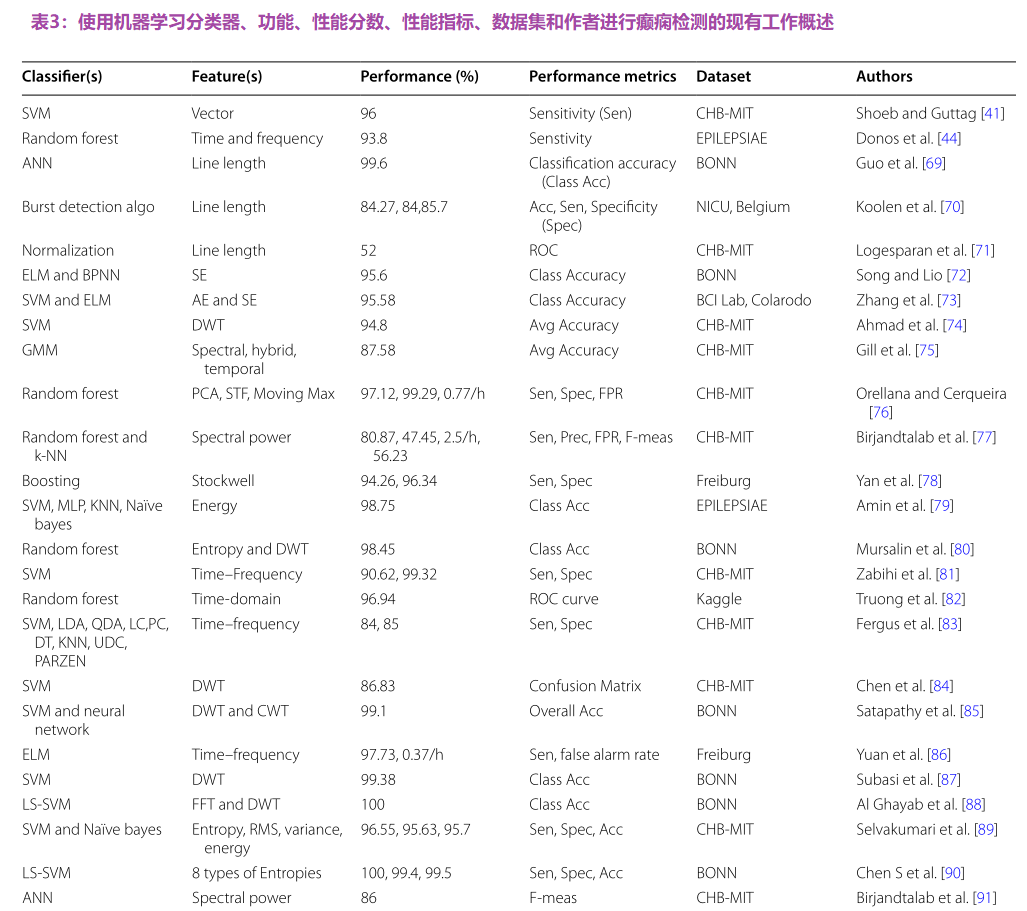
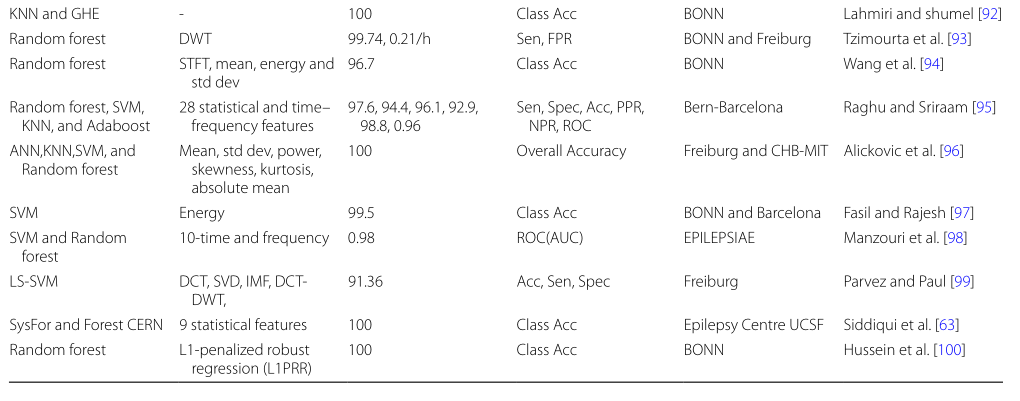
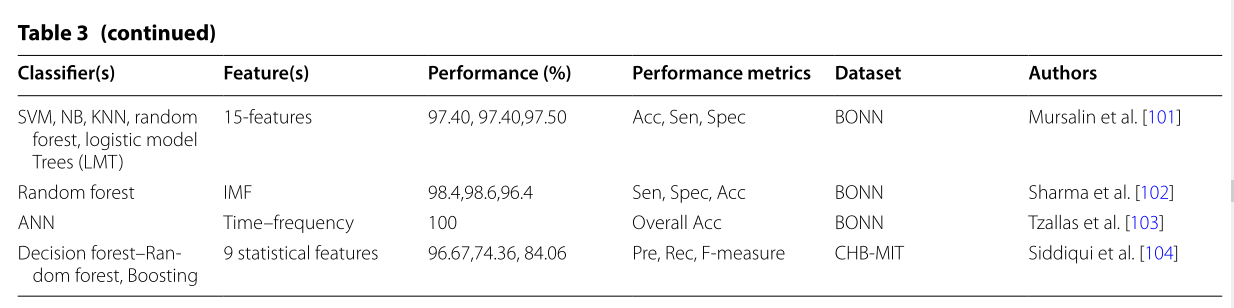
5.1 基于统计特征的癫痫发作检测
如果我们将机器学习分类器直接应用于原始EEG\ECoG数据集,它可能不会产生足够的sensible patterns。因此,从EEG和ECoG原始数据集中选择重要且有能力的统计特征是一项挑战和关键任务。EEG和ECoG信号的性质非常复杂、非平稳且具有时间依赖性[105–107]。因此,我们可以将机器学习分类器应用于处理后的数据集,这将最终帮助解决各种神经问题;例如,确定癫痫发作的阶段、准确的癫痫发作检测、快速检测等。在表3中,我们总结了几项研究的回顾。
通过不同类型的转换技术提取显著的统计特征;来自EEG数据集的离散小波变换(DWT)、连续小波变换(CWT)、傅立叶变换(FT)、离散余弦变换(DCT)、奇异值分解(SVD)、固有模式函数(IMF)和时频域[34、71、79、108]。
- Logesparan等人[34]使用了不同类型的特征提取方法进行癫痫检测,但他们报告说,两种特征——“line length”和“relative power”是癫痫检测的良好表现。
- GuerreroMosquera[109]在原始EEG数据集上应用了三种时域特征线长度、频率和能量。这些功能声称适用于癫痫检测和其他与大脑相关的应用,如脑机接口(BCI)。使用以下指标评估声称的性能,如敏感性、特异性、F评分、受试者操作特征(ROC)曲线和百分位引导测量。
- Duo Chen[84]在CHB-MIT和波恩大学的两个基准数据集上使用DWT和SVM分类器,分别实现了92.30%和99.33%的癫痫检测准确率。
- Ramy Hussein等人[100]提出了一种新的特征L1-penalized robust
regression(L1PRR)用于癫痫检测,其方法的问题是计算复杂性。 - Zavid和Paul[99]专注于对‘ictal’和‘inter-ictal’状态进行分类,他们使用了四个特征DCT、DCT-DWT、SVD和IMF;由于计算量较小,LS-SVM进一步对得到的信号进行分类。
几位研究人员利用单一特征对癫痫检测做出了贡献[108110]。将特征“line length”[108110]应用于EEG数据集;以0.051 Fp/h的虚警率记录了大约4.1 s的平均检测延迟。此外,郭等人[69]也使用了“line length”,但使用ANN对EEG信号获得的记录进行分类。他们的自动癫痫检测准确率为99.6%。Koolen等人[70]提出了一种系统,用于从脑电图记录中检测癫痫发作。该检测系统使用单一特征——“line length”。该系统的性能显示出84.27%的准确率、84.00%的灵敏度和85.70%的特异性,这相对低于郭等人[69]的结果。
在对几种统计特征[34]进行了3年的研究后,Logesparan等人[71]提出了“line length”特征,用于规范化和区分EEG数据集中的类别值。值得注意的是,“line length”可以被视为最强大的功能,并提供可观的输出。基于之前的研究,“line length”可以与其他特征一起使用,结果将更有希望,特别是在机器学习中。这是因为数据集维度也会随着属性中有意义的统计信息而增加。
基于单一特征(即熵及其子类型,如近似熵(AE)和样本熵(SE))的癫痫发作检测的其他一些研究也已经完成[45,72,73,111]。熵特征有助于发现EEG信号的随机行为,并在测量信号的杂质时具有深度优势[112113]。当数据以信号形式存在时,例如ECG、[114]、EEG和ECoG[36],熵特征已被广泛使用。这有助于检测模型的后续步骤。
- Acharya等人[111]使用了四种不同类型的基于熵的特征:EEG数据集的样本熵、近似熵、相位熵(S1)和相位熵(S2)。这些熵特征处理后的数据集用于癫痫检测。
- 在另一项研究中,Chen等人[90]在原始EEG数据集上使用了八种不同的熵特征:近似、样本、谱、模糊、置换、香农、条件和校正条件;此外,处理后的数据分为三类值:“发作期”、“发作间期”和“正常期”,准确率为99.50%。
- Selvakumari等人[89]提出了一种工具,使用了熵、均方根(RMS)、方差和能量四个特征。基于这些特征,使用SVM和朴素贝叶斯分类器进行检测,报告准确率为95.63%。该工具还能够找到大脑中的癫痫发作区域;然而,他们没有提到具体的发作地点百分比。
- Song和Li[72]使用两种分类器——极限学习机(ELM)和反向传播神经网络(BPNN)建立了分类模型。总体而言,他们的研究结果显示,在执行时间更短的情况下,分类准确率达到95.6%。
- 张勇等人[73]在两个不同的分类器ELM和SVM上应用了两个熵特征AE和SE来处理EEG数据集。与检测癫痫发作时的AE特征相比,ELM的SE特征提供了良好的分类精度。
能量特征在癫痫检测中有着重要的应用[115]。它起着至关重要的作用,尤其是当癫痫发作被基于epoch或窗口的方法检测到时。这意味着EEG信号被分为不同的部分[79,94]。Fasil和Rajesh[97]引入了指数能量特征,这有助于识别振幅EEG信号中的不规则性。
**观察:**本节概述了统计特征对癫痫检测的贡献及其重要性。一些研究人员使用多组特征检测癫痫发作,而另一些研究人员则选择单一特征,如“线长”。我们建议将“线长”特征列入癫痫检测的一组合适特征中,因为它有助于测量EEG信号的复杂性。它对信号的频率和振幅的变化起着敏感的作用。因此,它有助于区分“seizure”和“non seizure”。然而,从数据科学的角度来看,通过观察其他统计特征来观察每个大脑信号的不同角度是非常重要的。此外,我们还建议不要使用不相关的功能,因为它们会不必要地增加数据集的大小,这会导致计算时间的增加,并给出不敏感的模式。因此,机器学习分类器和用户很麻烦,而不是提供好处。一些研究人员[95、98、101]使用了大量特征,这增加了属性大小,导致计算时间更长,精确度更低。因此,如果我们像以前的研究人员那样采用较少的特征[71,73,79],这将产生低维数据集,这对知识发现过程来说将不会有成效。下一节说明了“黑盒”分类器对癫痫发作的检测。就分类目的而言,最好采用更相关的统计特征,这些特征可以集成到知识发现中,并具有良好的性能。
5.2 基于黑盒分类器的癫痫发作检测
SVM、ANN和KNN等分类器因其在不同领域的卓越性能而被认为是突出的分类器[67116]。每种技术都有其优缺点,“黑匣子”方法也不例外[104]。尽管这些分类器对大脑数据集有很好的贡献,本文报告了使用这些分类器进行癫痫检测的一些相关工作。
- Satapathy等人[85]的研究基于两种“黑匣子”方法——支持向量机和神经网络,使用不同的核方法对大型EEG数据集进行癫痫检测。每个分类器的性能由多数投票系统独立测量,发现支持向量机比其他神经网络的性能更好。
- Subasi等人[87]提出了使用SVM、遗传算法(GA)和粒子群优化(PSO)的混合方法检测癫痫发作的解决方案。该方法获得了令人印象深刻的准确率,即99.38%,但问题是分类器对数据集进行了两次训练,一次用于SVM-GA,另一次用于SVM-PSO。这可能很耗时。
- Shoeb和Guttag[41]使用带有向量特征的支持向量机(SVM)在他们安排的麻省理工博斯坦儿童医院(CHB-MIT)[60]数据集上进行癫痫检测,估计准确率达到96%。
- Dorai和Ponnambalam[42]提出了epoch的概念,这意味着将数据集划分为更小的时间框架。此外,他们在这些epoch EEG数据集上应用了四种“黑盒”方法LDA、KNN、CVE和SVM。这种方法可以提前65秒预测癫痫发作。
- Birjandtalab等人[117]将EEG数据分为两类“癫痫发作”和“非癫痫发作”,在检测癫痫发作之前使用了高斯混合模型(GMM),并通过85.1%的F-测量获得了90%的准确率。他们还提出了数据集中阶级不平衡的问题。
- Tzallas等人[103]将时间-频率域特征与人工神经网络一起用于EEG数据集,并获得了“癫痫”和“非癫痫”分类问题的100%准确率;对于epochs的数据集,“非癫痫”类的准确率为97.7%(A、B、C和D),而“癫痫”类的准确率为E。
- Amin等人[79]从DWT方法中提取了相对能量特征,并将四种分类器SVM、MLP、KNN和Naïve Bayes用于分类,结果显示SVM的准确率为98%,优于其他分类器。
- K.Abualsaud等人[118]提出了一个框架,使用“黑匣子”分类器集成对噪声EEG信号进行自动癫痫检测,报告的分类准确率为95%。然而,由于四个分类器都是“黑匣子”,集成方法并没有提供理想的准确度。
- 2018年,Lahmiri等人[92]利用广义赫斯特指数(GHE)和KNN,提出了一种从颅内EEG记录中识别“发作”和“非发作”类别的系统,检测率为100%,准确率为100%。此外,Lahmiri等人[43]利用支持向量机对GHE进行分类,对“癫痫”和“非癫痫”进行分类,并且他们发现在更短的时间内100%的准确率。在这里,一个很好的迹象是,作者声称癫痫检测在更短的时间内具有良好的准确性。但是,作者没有明确定义癫痫发作能被检测到多少次。
- 在Al Ghayab等人[88]的另一项研究中,由于使用信息增益理论的概念,从EEG信号数据集中提取有意义的特征并对其进行排序,因此获得的准确率为100%。然后应用**最小二乘支持向量机(LS-SVM)**对癫痫病例进行分类。此外,由于应用分类器的“黑盒”性质,作者无法探索知识发现方面的任何其他相关方面。
- Zabihi等人[81]使用SVM分类器对处理后的数据集进行了针对患者的癫痫发作检测,该数据集具有一组良好的特征,包括时域、频域、时频域和非线性特征。该模型的平均灵敏度为93.78%,特异性为99.05%。在这里,值得注意的是,他们跳过了现有文献中的一个重要特征——“线长度”,这一特征在癫痫检测中被显著使用。我们还认为CHB-MIT数据集[60]是不平衡的,因为在一小时(s)的记录中,发作时间跨度为几秒钟。
观察:
“黑匣子”分类器的主要问题是,它们只进行预测,而不提供逻辑规则或模式。这就是为什么不建议将其用于提取sensible的知识。例如,对于EEG数据集中的类型不平衡问题,发现相关文献不足并试图研究这个问题的研究人员没有提供一个可行的解决方案,即如何在检测癫痫发作的同时解决类型不平衡问题。
5.3 基于非黑盒分类器的癫痫发作检测
“黑匣子”分类器无法表达它们的分类过程以供人类解释[67104116]。因此,知识发现的机会更少,也无法更好地提高其准确性。决策树和决策森林等“非黑盒”分类器的概念开始付诸实践。
- Chen等人[119]首先将决策树引入EEG数据集,用于癫痫检测。
- 凯末尔和萨利赫[120]使用C5.0决策树[121]算法探索癫痫发作检测的逻辑规则,平均准确率为75%。当同样的C5.0应用于经傅里叶变换处理的同一数据集,但交叉验证获得的准确率为98.62%。
目前已有一些相关工作,其中只有一种决策树方法用于癫痫检测,因为准确性较低,并且从决策树的逻辑规则中获得的pattern数量有限[122]。因此,知识发现和准确性都会受到影响。然而,这种差距可以通过应用决策森林方法来填补[51,57,123]。
通过文献,我们发现决策森林方法比单一决策树更有效[57,124],因为决策树通常给出一组有限的规则,并且存在过拟合问题[68]。这些规则是通过一个决策树从训练数据中提取出来的,该决策树可以生成有限的或一组逻辑规则(例如,只要C2_entropy)≤ 101.01然后Class_value=‘seizure’),并在接受规则后停止在训练数据集中进一步增加树记录。然而,如果我们在训练数据上生成一个决策森林,我们可以通过合理的逻辑规则组合实现多组决策树,并且由于多数投票方法,可以获得更高的准确率[57]。决策森林分类器[54,68]是一种经常使用的集成方法。它们还用于癫痫检测,因为它们提供了高准确率,这取决于决策树集合中的多数投票方法。此外,它们根据训练数据(D)[123]生成多个决策树,从而生成更多逻辑规则。这些逻辑规则是人类可以解释的,数据科学家可以很容易地将它们与EEG数据集中的其他与癫痫相关的信息联系起来。
- Siddiqui和Islam[125]使用系统森林(SySFor)来检测ECoG上的癫痫发作,而不进行epoch缩减。此外,Siddiqui等人[63]应用了两个决策森林——Systematic Forest[123]和Forest CERN[51]的九个统计特征,利用历元长度缩减的概念进行快速癫痫检测。它基于将训练数据集 D D D的大小划分为 D 1 、 D 2 、 . . . 、 D n D_1、D_2、...、D_n D1、D2、...、Dn并在数据集的每个epoch测试准确性。这些子数据集的持续时间按降序排列。如果癫痫发作可以在较短的epoch长度内被检测到,而准确度没有下降,那么我们可以使用相同的历元长度,从而实现快速癫痫发作检测。他们达到了100%的准确率。这项工作的局限性在于,作者只采集了一名患者的数据集,可以对更多患者进行测试。
一些研究人员利用随机森林分类器的优势来检测癫痫发作[76、78、82、126]。因为研究人员/数据科学家能够看到逻辑规则并相应地解释它们。此外,它还提供了良好的准确性[44,76–78,80,82]。
- Donos等人[44]应用了决策森林分类器——随机森林,基于时域和频域的特征,这是从IEEG(颅内脑电图)数据集中提取的。它有助于选择颅内通道,以便在闭环电路中进行早期癫痫检测。结果表明,该系统对癫痫发作的检测灵敏度为93.8%。
- Wang等人[94]开发了随机森林的贪婪方法,即森林网格搜索优化(RF-GSO),使用这种方法,他们发现准确率为96.7%。这种技术的缺点是,如果EEG信号太过嘈杂,性能可能会下降。
- Tzimourta等人[93]在两个基准癫痫数据集[64,65]上应用随机森林监测癫痫发作活动,报告的表现为99.74%。
- Pinto Orellana和Fábio R.Cerqueira[76]还通过频谱-时间特征和70s在处理过的CHB-MIT数据集上使用了随机森林,每个区块的准确率为98.30%。
- Truong ND等人[82]在检测癫痫发作的同时进行了新的通道选择工作。他们的主要贡献是,他们还专注于主要有助于自动癫痫检测的通道。他们使用随机森林解决了通道选择和癫痫发作检测问题,实现了96.94%的曲线下面积(AUC)。
- 在另一项研究中,Mursalin等人[80]提出了一种通过改进的基于相关性的特征选择(ICFS)选择特征来检测癫痫发作的方法。基本上,它是时域和频域的融合。然后,将随机森林分类器应用于癫痫检测模型。该方法得到的平均分类准确率为98.75%。
其他一些作品使用了“非黑盒”分类器的集合,如boosting、bagging和random subspace[78127]。
- Yan等人[78]应用了一个boosting分类器,实现了94.26%的准确率,尽管结果不如[44]使用随机森林分类器得到的结果令人印象深刻。
- Hosseini[128]使用随机子空间分类器和SVM分类器对癫痫进行分类和检测。在这里,在大数据集上应用子空间的好处是基于随机子空间概念将它们划分为子数据集,然后对每个子数据集应用SVM分类器。集成准确度(EA)采用多数投票法计算,为95%。
- 除了这项研究之外,Hosseini等人[126]最近还使用了一组分类器进行了另一项研究。首先,他们使用随机子空间方法创建bootstrap样本,然后应用SVM、KNN、扩展最近邻(ENN)和多层感知器(MLP)等分类器,获得97%的准确率。
- Hussein等人[100]提出了一种新的特征提取方法,即L1-penalized robust regression(L1PRR),该方法使用癫痫发作期间的三种常见症状:肌肉伪影、眼睛运动和白噪声。输入这些特征有助于随机森林分类器获得100%的准确度。
观察:
与决策树相比,决策森林分类器在大脑数据集上被大量用于探索不同的研究目标。在处理高维数据集时,很难推荐一个特定的分类器,但随机森林分类器可能是一个有能力的分类器。然而,它也批评了并非所有的“非黑盒”分类器都能检测癫痫发作,并指出了使用单一决策树分类器的缺点。
5.4 基于黑盒和非黑盒机器学习分类器的癫痫发作检测
从文献中可以发现,仅仅一个机器学习分类器是不够的。因此,为了同时利用“黑盒”和“非黑盒”分类器,一些研究人员在实验中使用了它们。本节全面回顾了用于检测癫痫发作的分类器。
- Acharya等人[111]使用了七种不同分类器的集合——模糊外科医生分类器(FSC)、SVM、KNN、概率神经网络、GMM、决策树和朴素贝叶斯,将患者的三种状态区分为“正常”、“发作前”和“发作期”。总体准确率为98.1%。
- Fergus等人[83]还使用了不同的分类器,如线性判别分析(LDA)、二次判别分类器(QDC)、逻辑分类器、基于不相关正态密度的分类器(UDC)、多项式分类器、KNN、PARZEN、SVM和决策树,对处理后的数据进行分类,并具有熵、均方根、偏斜度和方差等七个特征。他们指出,被检测到的患者在不同的患者中患有“全身性癫痫”(即影响整个大脑区域),而事先没有关于癫痫发作焦点的信息。
- Mursalin等人[101]提出了一种减少数据量的方法,称为最佳样本分配技术的统计抽样技术,并开发了一种特征选择算法来减少特征。对支持向量机、KNN、NB、逻辑模型树(LMT)和随机森林五种分类器的组合进行了分析。
- Rand和Sriram[95]在由28个特征准备的高维数据集上使用了四种分类器,如SVM、KNN、random forest和Adaboost。结果表明,支持向量机在三次核上的性能优于三次核。
- 在另一项研究中,Manzouri等人[98]在由10个时间和频率特征生成的数据集上使用了SVM和随机森林。与基于SVM的检测器相比,随机森林分类器的性能更好。
- Subasi等人[96]在两个流行的数据集Freiburg和CHB-MIT上使用了四种机器学习分类器,如ANN、KNN、SVM和random forest,将癫痫发作的三种不同状态分类为“发作前”、“发作期”和“发作间”,达到了100%的准确率。
- Sharma等人[102]提出了一种使用迭代滤波和随机森林对EEG信号进行分类的自动化系统。这项工作在波恩数据集(A-E)上实现了99.5%的分类准确率,对于A和E亚组,96%的D和E亚组,以及98.4%的ABCD和E类EEG信号。
- Birjandtalab等人[77]出于不同的目的使用了两个分类器;KNN用于区分“发作”和“非发作”类别,而随机森林用于探索重要通道。在这里,随机森林也有助于降维问题。选择合适的通道的主要好处是,它有助于从所选通道中提供相关的所需信息,并降低分类器的计算成本。然而,作者在这里没有提到通道选择的重要信息,比如从大脑头皮找到癫痫发作的位置。[95,98,101]中的主要批评是,由于大量的特征,数据集的属性大小会增加,因此准确性和计算时间会受到影响。
5.4.1 观察结果
我们观察到,一些工作使用了一组杰出的分类器来分别获取好处。例如,有影响力的通道选择可以使用决策林分类器(如随机林)独立完成。但作者使用了其他分类器,如SVM和KNN,对癫痫发作记录进行了准确分类。
6 癫痫定位
癫痫发作检测成功后,定位是癫痫手术的一项基本任务[129–131]。通常,局限性癫痫可以通过手术治愈,手术发生在大脑的左侧或右侧区域。ECoG和EEG等癫痫监测工具对确定癫痫发作部位有显著帮助。电极\通道以非侵入性(用于EEG)和侵入性方式(用于ECoG)植入。他们的定位基于10/20(10-20)国际系统,该系统有助于识别癫痫发作的位置[132]。癫痫定位的概念是指识别受癫痫影响的大脑区域。虽然某些类型的癫痫发作,如“强直阵挛”可以通过抗癫痫药物(AED)治愈,但在某些情况下,部分癫痫发作的患者可能会接受手术[13]。为了解决这个问题,对于神经学家和神经外科医生来说,找到癫痫发作的位置是一项重要且具有挑战性的任务[129130]。手术的目标是找到癫痫发作的起始点/部位/焦点区域。10-20定位系统提供了一些线索,用于识别癫痫发作的位置。最近,计算和机器学习方法被用于识别癫痫发作部位[130133]。
- Acar等人[133]使用了trucker和非线性multi-trucker核,并声称SVD和主成分分析(PCA)等其他分类器无法定位癫痫发作。
- GhannadRezaie[134]将一种先进的群体智能算法应用于癫痫发作数据,以找到癫痫发作的位置。他们的研究产生了一些值得注意的结果,并探索了患者的颞叶是否受到癫痫发作的影响。他们还表示,支持向量机可能能够检测到癫痫发作的位置。此外,他们还专注于ECoG电极的还原。
- Mansouri等人[135]提出了一种癫痫定位算法,并在卡鲁尼亚大学10秒的EEG数据集上进行了测试。在这里,他们使用了小型数据集,因为记录通常需要几个小时。如果他们在一个大数据集上进行测试,情况会好得多。
- Fakhraei等人[130]计算了大脑每个区域的敏感性。从79名患者(31名男性,48名女性)的197项医学特征数据集中,将置信预测率(CPR)与六个分类器获得的ROC图的AUC进行比较。研究发现CPR比ROC更合适。他们还发现,43名患者左侧患有颞叶癫痫(TLE),而36名患者右侧患有TLE。
- 同样,Rai等人[136]提出了一种方法,通过将两种基于熵的特征——“renyi熵”和“负熵”应用于神经网络分类器来识别癫痫发作的焦点。S
- iddiqui等人[63]使用两个决策森林分类器对癫痫发作进行定位,他们的结果表明,大脑左半球受癫痫发作的影响更大。
观察:
研究发现,与癫痫检测相比,机器学习分类器在癫痫定位中的应用并不广泛。但是关于这个问题有一些文献。在这些报告的研究中,作者没有提到癫痫发作对大脑受影响区域的百分比,他们也无法确定脑叶的确切位置,如枕叶、额叶、左顶叶和右顶叶。虽然这不是我们在这篇综述文章中的主要目标,但在讨论相关已发表的研究时,我们发现了一些关于癫痫定位的有趣线索。
7 现有文献中发现的问题
最重要和决定性的步骤之一是选择合适的统计特征,因为植入大脑的每个通道或电极提供不同的统计度量。毫无疑问,早期的研究人员一直在努力寻找最佳特征。虽然一些研究人员使用了许多特征[34,79],但其他研究人员使用了一些特征[31,36,108,112,137]来检测癫痫发作。作为一名数据科学家,通过分析诸如熵、能量和偏度等特征的统计特性,了解每个大脑信号的不同统计角度是非常重要的。我们不能把重点放在获取不相关的特性上,因为这会不必要地增加数据集的大小。因此,对机器学习分类器来说,这将是一个负担,而不是一个好处。如果我们像以前的研究人员那样只使用很少的特征[71,73,79],这将产生低维数据集,并且对有效的知识发现过程没有好处。因此,我们应该选择那些可以提供逻辑结果的潜在特征。因此,建议选择一组特征,以避免机器学习分类器的负担,并在相关知识发现中获得帮助。
根据数据集属性和要求,每个分类器都有自己的优缺点[138]。一般来说,很难指出哪种分类器对大脑数据集最有效。为了识别有能力的分类器,在EEG数据集上测试了几种分类器,并对它们的性能进行了评估,在解决癫痫检测和传授知识发现时,需要考虑性能良好的分类器。文献显示,以前的研究人员应用了不同的方法,其中大多数来自“黑盒”,如ANN、KNN和SVM。它们最大的缺点是无法对模型中隐藏的模式和逻辑规则提供适当的解释。这就是为什么不建议将其用于卓越的知识发现过程。数据科学家可能无法探索模式的内部处理过程[51104]。然而,从文献中可以看出,“非黑盒”方法,尤其是随机森林,被广泛用于癫痫检测[44,76,77],因为它的性质是在建立决策森林的同时生成引导样本[124,139]。对机器学习分类器在EEG数据集上的性能进行了分析,发现集成非黑盒分类器的性能非常有效[104]。我们认为,随机森林是基于自举样本的,它遗漏了一些有影响的属性,因为它随机选择属性,有时还会生成相同的逻辑规则集。因此,有时它也会产生不相关的信息。为了克服这个问题,我们还提出了一些其他决策林算法,如SysFor[123]和forest CERN[51]在癫痫检测中的方法。
所有这些关于癫痫检测的发现都提出了一些有趣的研究问题,例如选择合适的统计特征和机器学习分类器以减少计算时间,因为数据集具有高容量和高维,而机器学习分类器最重要的缺失信息是在脑叶定位准确的癫痫发作点。
7.1 癫痫检测中的类别不平衡问题
类别不平衡是机器学习中的一个严重问题[140],大多数问题出现在医学数据集中[141],尤其是在脑电图信号中。这是因为EEG记录的持续时间很长,很耗时,发作持续时间只有几秒钟,因此容易出错[91]。结果,数据集变得高度不平衡。之前的研究人员主要关注癫痫发作的检测。在过去的几年里,研究人员一直在关注类别不平衡的挑战,同时检测癫痫发作,并试图通过应用一些新颖的不同传统方法来解决它。
- Javad Birjandtalab等人[91]通过实现86%的F-measure,使用带有加权代价函数的人工神经网络来处理不平衡的EEG数据集。
- El Saadi等人[142]使用支持向量机分类器的欠采样方法获得了97.3%的准确率。
- 在Saadullah和Awais[143]的另一项研究中,他们结合使用SMOTE和RUSTBOST技术来检测癫痫发作到不平衡发作数据,准确率为97%。
然而,袁琦等人[86]的研究非常接近令人满意的结果,因为他们将权重分配给少数类别的数据,以保持有效平衡,并解决了偏差问题。对这项工作的主要批评是,作者没有提到分配了哪些权重,以及它们的阈值是多少?在这里,我们认为,尽管由于长时间的脑电图记录,脑电图数据高度不平衡,但记录会一直持续到癫痫发作被检测出来。发作时间从几秒到几分钟不等。尽管研究人员[76,86,117,143]努力使用“黑盒”和“非黑盒”分类器来解决这个问题,但他们并没有提出任何合理的解决方案,即少数(癫痫发作)类别的权重应该有多大。
8 关于有能力的分类器和统计特征的总体观察
建议一个特定的分类器应该能够检测癫痫发作是一个挑战。如果我们讨论分类器,在选择能够处理高维数据集、模型的高精度和能够检索敏感知识的分类器时,三个约束非常重要。并不是所有的机器学习分类器都适用于癫痫检测和知识发现任务,主要是因为它们具有黑盒性质。这意味着数据科学家无法看到和理解逻辑规则/模式。在决策树[53]和决策森林[54]中的“非黑盒”分类器中,只有决策森林算法更具能力,因为单个决策树发现的逻辑规则和知识往往有限且不足。例如,如果我们在一个训练数据集上构建一个决策树,它将提供一组有限的或单一的逻辑规则,并停止进一步增长树,因为训练集中的所有数据点都接受该规则。另一方面,如果我们在同一个训练集上建立一个决策林,我们会得到多个具有更合理逻辑规则的决策树。
- Siddiqui等人[104]对CHB-MIT数据集进行了分析,以了解哪个分类器的性能更好。为此,他们应用了两个黑盒(SVM和KNN)和两个非黑盒(决策树和树集合,即bagging、随机子空间、boosting);他们发现,与其他黑盒分类器相比,非黑盒分类器(集成)的性能更好。即使是集成也比单个决策树(非黑盒分类器)表现更好。
- Siddiqui等人[63]利用历元长度缩减的概念,将两种决策森林系统森林(SysFor)和Forest CERN应用于快速癫痫检测。他们达到了100%的准确率。
- 同样,侯赛因等人[100]也使用决策森林-随机森林方法实现了100%的准确率。
文献显示,在过去几年中,“非黑盒”分类器,尤其是决策森林方法,被广泛用于EEG和ECoG的大脑数据集,用于不同的研究目标[76,82,94,144]。使用决策森林进行癫痫发作检测的原因如下:
- 决策林克服了决策树的一些缺点。决策树只从输入数据集中发现一组逻辑规则。单个决策树发现的逻辑规则可能无法正确预测和分类类值;
- 与单个决策树相比,一个决策林可以产生更多的逻辑规则集/模式,并且与单个决策树相比,有很高的机会进行良好的预测/分类;
- 能够处理高维集合;
- 由于决策林的集成性质,与单个树和其他分类器相比,它的精度通常较高[54];
- 计算时间更少(特别是对于随机森林);
- 逻辑规则清晰且人性化,分析师/领域专家可以轻松理解并提出最佳意见。例如,通过癫痫发作影响脑叶,识别合适的统计特征等。
此外,许多统计特征已被用于癫痫检测。然而,由于它们的异质性,很难对它们进行比较。一些研究人员使用了能量和熵等单一特征。另一方面,能量、峰度、线宽、熵、偏度、最大值、标准差和最小值等统计特征的组合可能会产生有希望的结果。大多数研究[34、46、92、100、109、145]使用这些特征取得了更好的结果。[29、63、104、125]的新颖之处在于,选定的九个统计特征能够帮助高准确度的癫痫检测,即100%。通过合理的逻辑规则,这也为癫痫定位提供了线索。因此,所选的特征组不会对机器学习分类器造成负担,但它将有助于相关知识的发现。
9 癫痫检测的研究方向
在本研究分析中,我们调查了用于癫痫检测的不同机器学习分类器。毫无疑问,在这一主题中已经发现了持续尝试的进展,但也提出了一些有趣的研究问题。在这一部分中,我们将指出可以提升该领域未来研究的重大挑战。
- 选择合适的统计特征和机器学习分类器,以减少计算时间,因为数据集具有高容量和高维度。
- 在长时程脑电记录数据集的不平衡数据集上准确检测癫痫发作。
- 长时间脑电图记录的快速癫痫检测。
- 在选择机器分类器时,应记住分类器不会遗漏任何必要的EEG通道\电极
- 从机器学习分类器中发现知识,例如癫痫定位,准确指出影响脑叶的点,通道重要性,以及基于参与癫痫发作的通道,可以向神经学家或神经外科医生提供知识,以建议癫痫类别。
10 结论
随着癫痫发病率的增加,其准确检测变得越来越重要。一个主要挑战是从大量数据中正确检测癫痫发作。由于这些数据集中脑电信号的复杂性,机器学习分类器适用于精确的癫痫检测。然而,选择合适的分类器和特征至关重要。
因此,本文全面回顾了用于癫痫检测的机器学习方法, 我们得出结论,“非黑盒”分类器决策林(决策树的集合)是最有效的。这是因为它可以产生多个合理的、解释性的逻辑规则,具有很高的预测精度。此外,它还可以帮助发现一些相关信息,如癫痫发作定位和探索癫痫发作类型。相反,“黑盒”分类器不能生成逻辑规则,尽管它们可以实现高预测精度。至于选择合适的特性,我们应该选择那些能够提供逻辑结果的特性。通过文献回顾,利用熵、线长、能量、偏度、峰度和标准差等特征可以在分类器中实现100%的准确率。随着数据维度的增加,我们建议不要使用不相关的特征。这是因为分类器的计算成本会增加,并且可能会产生不敏感的模式。如果我们只使用一个或两个特征,例如线长度和能量,就会生成低维数据集。然而,这个数据集对于知识发现过程来说并不会有什么成果。
这篇综述文章为正在使用EEG信号进行癫痫发作检测的数据科学家提供了新的视角。总之,本文主要对机器学习分类器的选择和合适的特征进行了综述。

