
- 1python+pygame 最强大脑联动归位游戏_联动归位试玩
- 2Yum(Yellowdog Updater Modified)命令大全详解
- 330天自学(白帽黑客)网络安全技术
- 4大量机器学习&深度学习资料
- 5LeetCode:贪心算法(30道经典题目)_贪心算法经典例题
- 6涵盖从Java 5到Java 11所有重要特性,让Java学习不再难!_java5到java11特性
- 7Idea Community社区版,新建module不使用maven archetype
- 8安装NVIDIA-DOCKER_windows系统安装nvidia-docker
- 9Elasticsearch:如何创建 Elasticsearch PEM 和/或 P12 证书?_elastic-certificates.p12证书生成
- 10MQ选型:ActiveMQ、RocketMQ、RabbitMQ、Kafka对比_rocketmq和rabbitmq哪个用的多
【java爬虫】selenium+browsermob入门实战_java selenium proxy-pool
赞
踩
在爬虫领域,selenium几乎是最无所不能的一个框架了,在传统的爬虫无能为力的时候,我们可以使用selenium来请求动态页面获取信息。
当然,只有selenium还是不够的,因为使用selenium我们只能获取页面上展示的数据,但是无法获取Network请求和响应结果,有些网页并不会将从接口接收到的所有数据都展示到页面上,为了捕捉到这些信息,我们就需要引入到browsermob。这两个框架的强强联合,几乎可以解决我们99%的需求。
使用selenium接管已开启的浏览器
一般情况下使用selenium都是重新开一个浏览器,但是这样会产生一些问题,比如有一些网站你需要登录后才能查询到信息,如果每次都重新开一个浏览器的话,我们就需要重复进行登录的操作,这样非常繁琐。为了适应这样的场景,我们可以打开一个浏览器,然后让selenium将浏览器接管,这样浏览器就会保留我们的登录信息,selenium可以很方便地开始工作。
为了能让selenium顺利接管浏览器,我们首先需要指定端口号来打开浏览器。
首先找到 chrome.exe 快捷方式指向的具体地址,然后将这个地址加入到环境变量
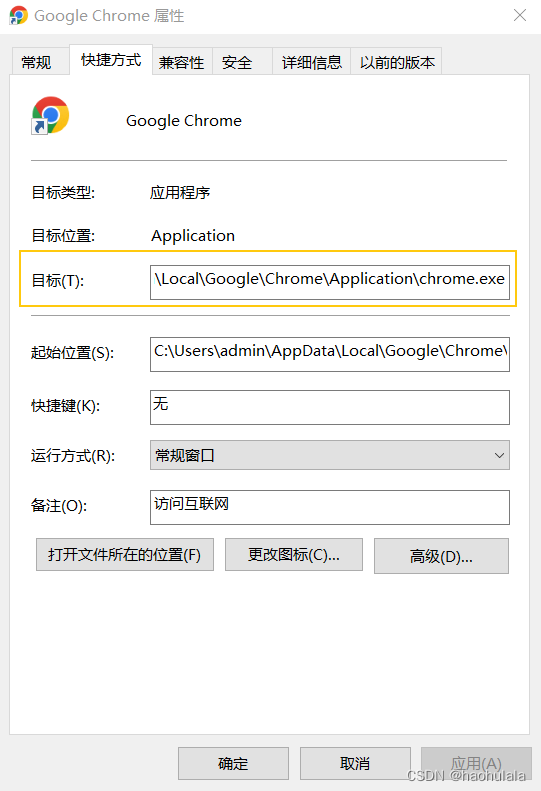
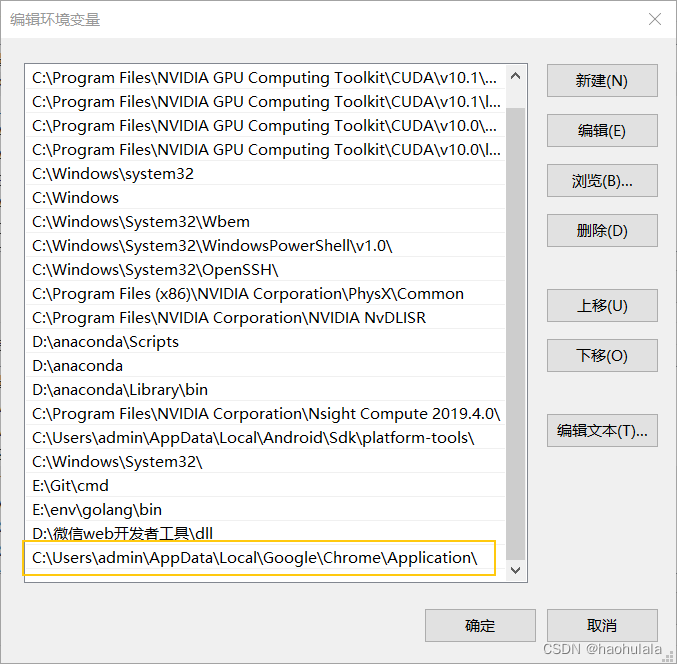
添加完环境变量后,我们就可以使用某个指定的端口打开一个chrome客户端
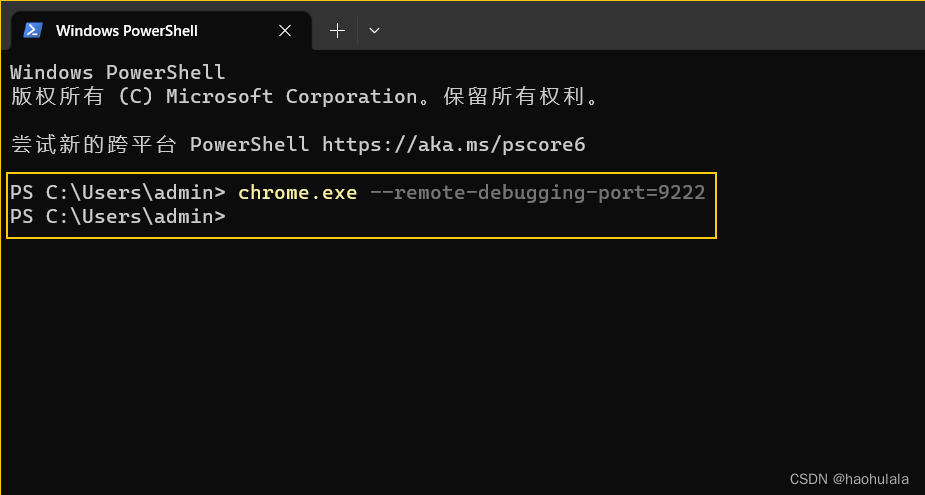
接着我们在selenium中使用配置信息启动Chrome就可以接管客户端了

使用selenium爬取百度热搜信息
在selenium接管浏览器后,我们就可以进行响应操作。我们这边简单地爬取一下百度首页的热搜信息来熟悉一下操作。
首先介绍一下本文会用到的jar包。
- <dependency>
- <!-- fastjson -->
- <groupId>com.alibaba</groupId>
- <artifactId>fastjson</artifactId>
- <version>1.2.47</version>
- </dependency>
-
-
- <dependency>
- <groupId>cn.hutool</groupId>
- <artifactId>hutool-core</artifactId>
- <version>5.6.5</version>
- </dependency>
-
-
- <dependency>
- <groupId>net.lightbody.bmp</groupId>
- <artifactId>browsermob-core</artifactId>
- <version>2.1.5</version>
- </dependency>
-
- <dependency>
- <groupId>net.lightbody.bmp</groupId>
- <artifactId>browsermob-legacy</artifactId>
- <version>2.1.5</version>
- </dependency>
-
- <dependency>
- <groupId>org.seleniumhq.selenium</groupId>
- <artifactId>selenium-java</artifactId>
- <version>4.1.1</version>
- </dependency>
-
-
- <dependency>
- <groupId>com.google.guava</groupId>
- <artifactId>guava</artifactId>
- <version>31.0.1-jre</version>
- </dependency>

百度热搜是放在一个<ul>标签下的,并且id为hotsearch-content-wrapper,使用这个id可以找到这个元素,然后逐个遍历其中的<li>就能得到首页的6个热搜信息。
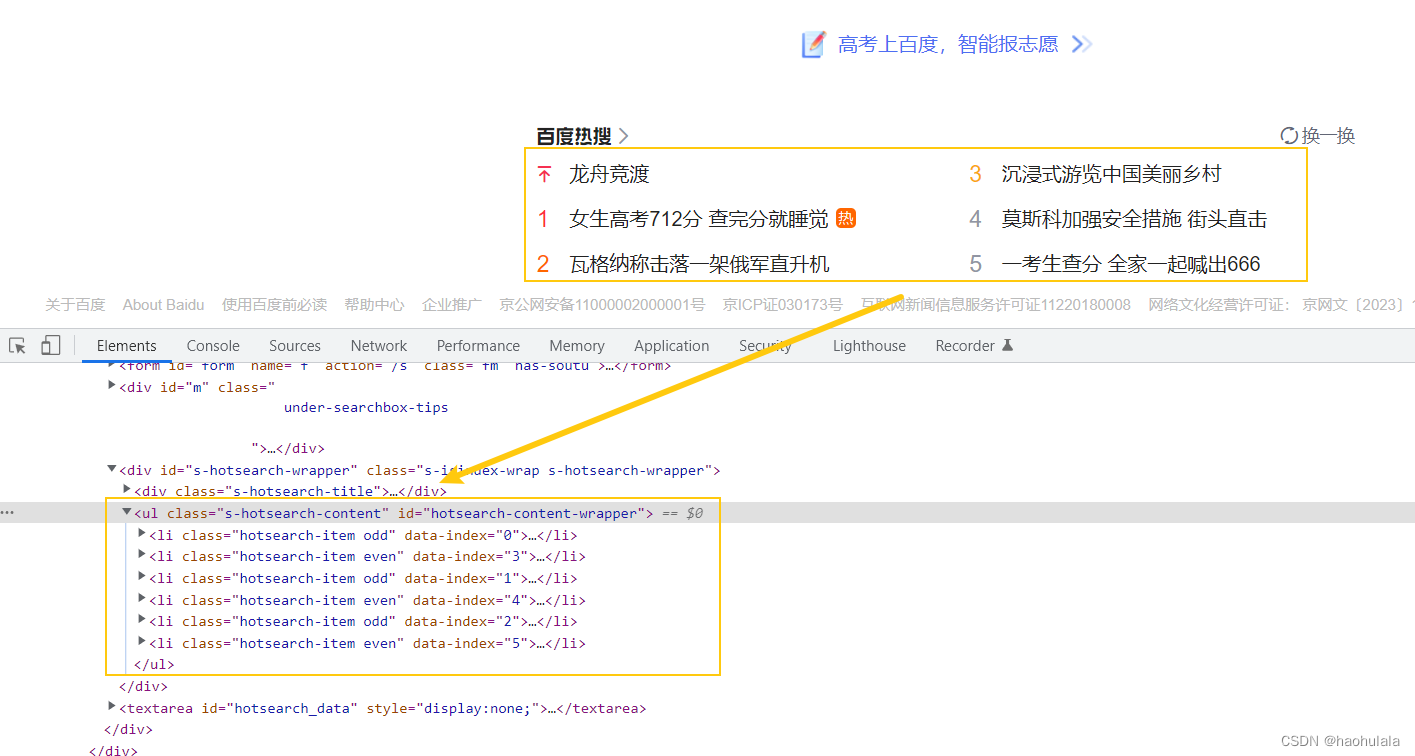
不难发现,每个<li>标签里面都有一个<a>标签用来表示url地址,还有一个<span>标签用来表示热搜的标题,我们主要关注这个两个元素对应的信息

这里简单贴一下selenium中findElement的api
- findElement(By.id())
- findElement(By.name())
- findElement(By.className())
- findElement(By.tagName())
- findElement(By.linkText())
- findElement(By.partialLinkText())
- findElement(By.xpath())
- findElement(By.cssSelector())
基本上以上的几个方法就可以解决我们的需求了。
代码非常简单
- @Override
- public void startSelenium() {
- log.debug("开启浏览器");
- System.setProperty("webdriver.chrome.driver", DRIVER_PATH);
- ChromeOptions options = new ChromeOptions();
- options.setExperimentalOption("debuggerAddress", "127.0.0.1:9222");
- WebDriver driver = new ChromeDriver(options);
- log.debug("浏览器启动成功");
- driver.get("http://www.baidu.com");
- log.debug("开始获取热搜信息");
- WebElement element = driver.findElement(By.id("hotsearch-content-wrapper"));
- List<WebElement> element_lis = element.findElements(By.tagName("li"));
- for(WebElement el : element_lis) {
- String url = el.findElement(By.tagName("a")).getAttribute("href");
- String title = el.findElement(By.className("title-content-title")).getText();
- log.info(title + "=>" + url);
- }
-
- }
运行一下代码得到如下信息就代表大功告成啦
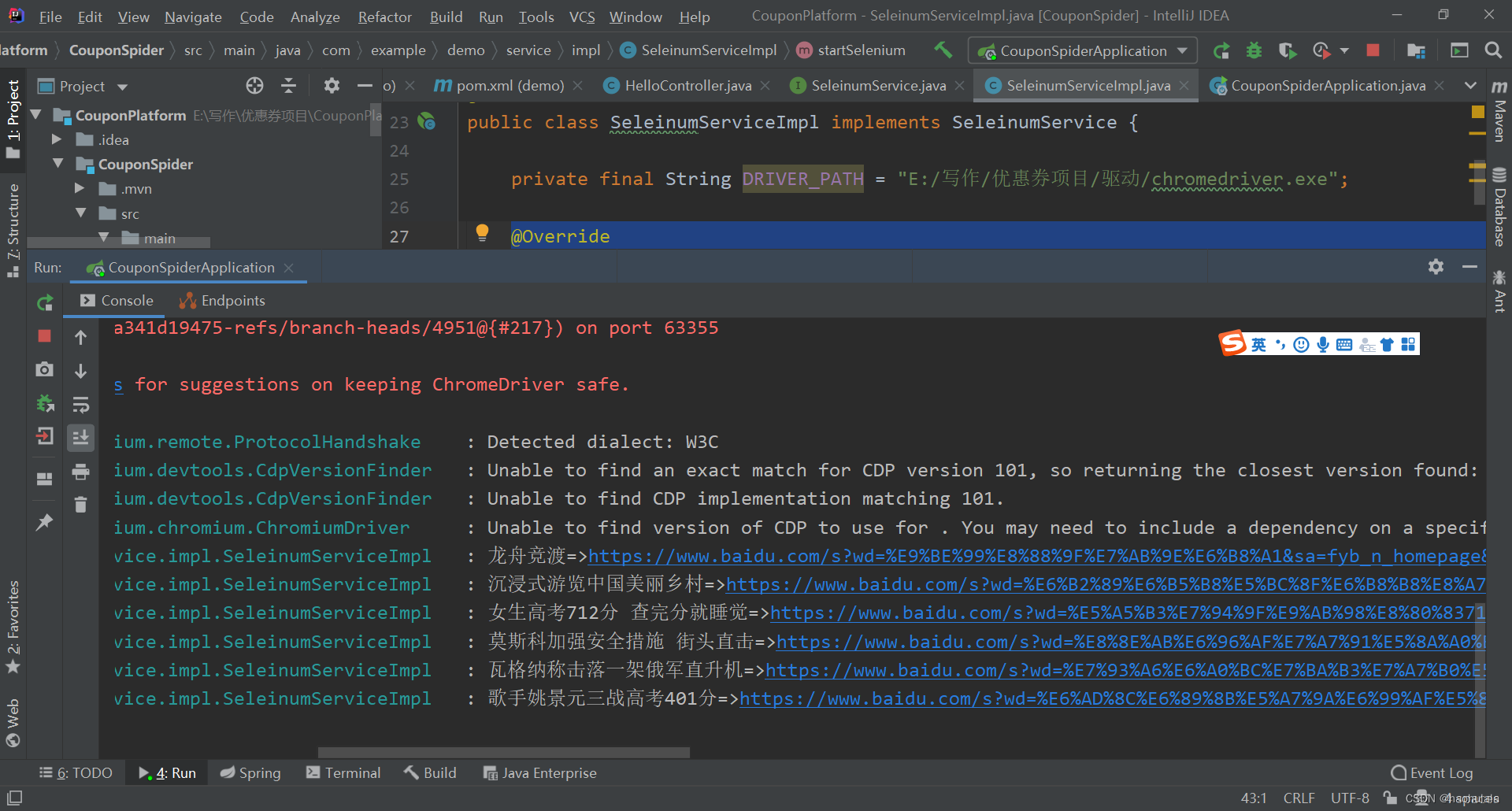
使用browsermob获取Network数据
大部分网站使用selenium都可以获取数据,但是有一些网站并不会将所有获取的数据都进行展示,或者说,我们直接读取接口返回的数据会更快速的获取数据,我们这里以淘宝联盟举例。
淘宝联盟的url如下,需要进行登录
阿里妈妈
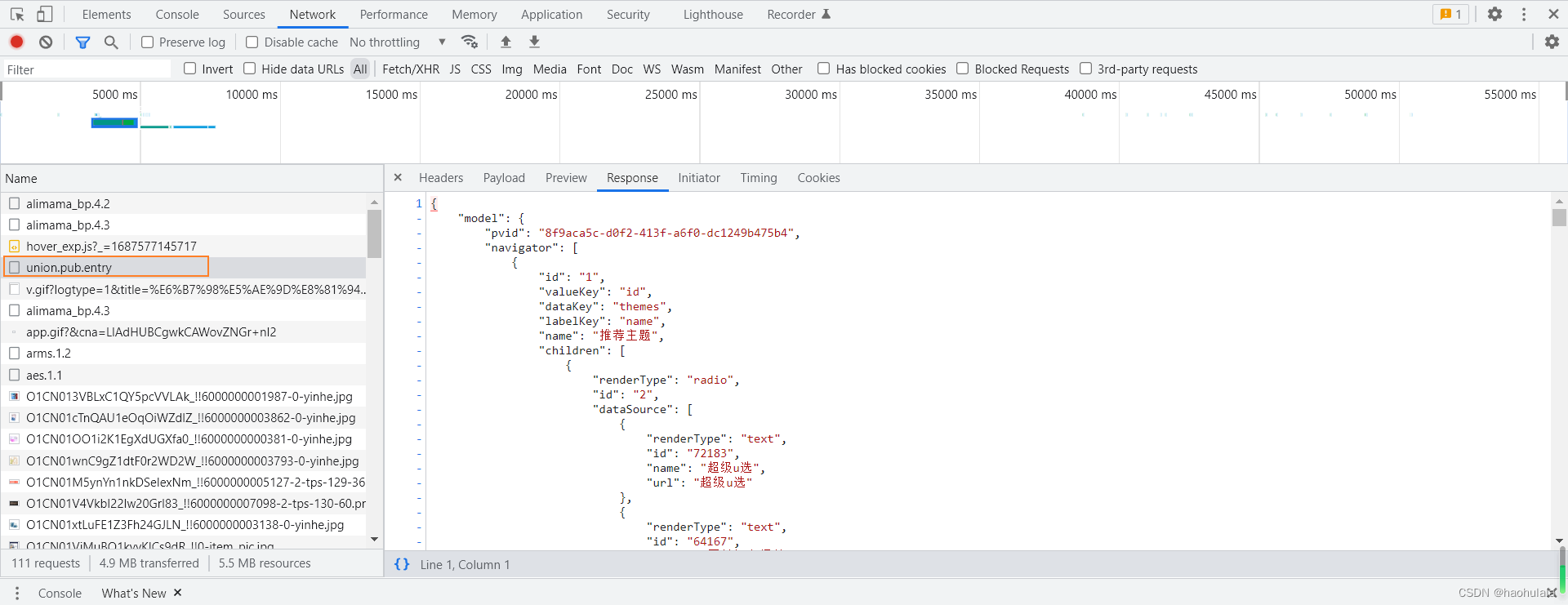
在编码的时候发现了一个问题,就是使用selenium+browsermob的时候没办法对已经打开的浏览器配置代理信息,所以如果使用selenium接管已经打开的浏览器是拿不到Network数据的,所以本文只能退而求其次,让selenium打开新的浏览器,然后进行登录。
browsermob-proxy +selenium使用 - 知乎browsermob-proxy 一个浏览器的代理 在调试浏览器或者爬取数据的时候,需要使用浏览器的开发者模式,尤其是动态网页,在使用selenium的时候,想要知道到底调用了哪些接口 ##安装 pip install browsermob-proxy这里…![]() https://zhuanlan.zhihu.com/p/363008064我们首先需要实例化browsermob的代理,然后将代理添加到selenium的参数中,接着再实例化selenium,打开chrome浏览器。使用browsermob获取网络请求的方法就是设置两个回调函数,一个是请求的回调函数,一个是响应的回调函数。回调函数的意思就是,有请求或者响应信息的时候,就会执行我们回调函数里面编写的代码。
https://zhuanlan.zhihu.com/p/363008064我们首先需要实例化browsermob的代理,然后将代理添加到selenium的参数中,接着再实例化selenium,打开chrome浏览器。使用browsermob获取网络请求的方法就是设置两个回调函数,一个是请求的回调函数,一个是响应的回调函数。回调函数的意思就是,有请求或者响应信息的时候,就会执行我们回调函数里面编写的代码。
- public void startSelenium() {
-
- // 实例化BrowserMob代理
- System.setProperty("webdriver.chrome.driver", DRIVER_PATH);
- BrowserMobProxy browserMobProxy = new BrowserMobProxyServer();
- browserMobProxy.start();
- browserMobProxy.enableHarCaptureTypes(CaptureType.REQUEST_CONTENT, CaptureType.RESPONSE_CONTENT);
- browserMobProxy.setHarCaptureTypes(CaptureType.RESPONSE_CONTENT);
- browserMobProxy.newHar("kk");
- Proxy seleniumProxy = ClientUtil.createSeleniumProxy(browserMobProxy);
-
- // 实例化Selenium
- ChromeOptions options = new ChromeOptions();
- options.setProxy(seleniumProxy);
- options.setAcceptInsecureCerts(true);
- //options.setExperimentalOption("debuggerAddress", "127.0.0.1:9222");
- WebDriver driver = new ChromeDriver(options);
-
-
- // 网络请求回调函数
- browserMobProxy.addRequestFilter(new RequestFilter() {
- @Override
- public HttpResponse filterRequest(HttpRequest httpRequest, HttpMessageContents httpMessageContents, HttpMessageInfo httpMessageInfo) {
- // 打印请求信息
- // log.info("request=>" + httpMessageInfo.getUrl());
- return null;
- }
- });
-
- // 网络响应回调函数
- browserMobProxy.addResponseFilter(new ResponseFilter() {
- @Override
- public void filterResponse(HttpResponse httpResponse, HttpMessageContents httpMessageContents, HttpMessageInfo httpMessageInfo) {
- // 这里获取打印的信息
- log.info(httpMessageInfo.getUrl());
- if(httpMessageInfo.getUrl().equals("https://pub.alimama.com/openapi/param2/1/gateway.unionpub/union.pub.entry")) {
- // 格式化输出
- String str = JSONObject.toJSONString(httpMessageContents.getTextContents(), true);
- System.out.println(str);
- // 将数据写到文件中
- try {
- FileWriter writer = new FileWriter("output.txt");
- writer.write(str);
- } catch (IOException e) {
- e.printStackTrace();
- }
- }
- }
- });
-
- // 打开网页
- driver.get("https://pub.alimama.com/portal/v2/pages/promo/goods/index.htm?pageNum=2");
-
-
- }
执行上述代码,打开浏览器并且登录后,我们就可以拿到相应接口的响应信息了,在项目的根目录看到output.txt就代表数据获取成功,可以发现这个接口的响应数据非常大,里面包含的信息非常多。

总结
到这里,本文的主要内容就介绍完了。使用selenium+browsermob可以非常方便地进行网络数据收集,不过我感觉有一个缺点就是运行起来非常慢,在爬下批量数据的情况下可以使用,但是如果要快速爬取大批量数据的话,还是直接用http去请求接口,对于反爬虫机制比较好的接口,可以去研究一下js逆向,selenium相对于直接去请求接口的一大优势就是不用花时间去研究js逆向,直接写代码去获取数据就完事了。
那么本文就到此结束,如果你有什么想和我交流讨论欢迎评论区留言。


