
- 1OKHttp从入门到放弃(自己编写测试服务端)_okhttp服务端
- 2【Linux】锁的简单封装以及原理解析
- 3爬虫是什么 怎么预防
- 4python爬虫知识点:5种线程锁
- 5Vue学习笔记之应用创建和基础知识
- 6信息系统安全(第二章)
- 7Mac OS配置Tomcat服务器教程_mac tomcat
- 8【A情感文本分类实战】2023 Pytorch+Bert、Roberta+TextCNN、BiLstm、Lstm等实现IMDB情感文本分类完整项目(项目已开源)_roberta文本分类
- 9Gartner发布2024年威胁暴露面管理战略路线图
- 10vue + element-ui 聊天_vue网页版聊天Vue+ElementUI仿微信界面聊天实例
c语言实现数据结构---堆_c语言堆
赞
踩
堆的概念
我们首先来看看堆的概念是什么?如果有一个关键码的集合K = { K0,K1,K2,K3,K4…,Kn-1},把它的所有元素按完全二叉树的顺序存储方式存储在一个一维数组中,并满足:ki <=k2i+1 且ki <=k2i+2 ( ki >= k2i+1且 ki >= k2i+2) i = 0,1,2…,则称为小堆(或大堆)。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。那么这个就是我们堆的概念,是不是看起来非常的容易非常的通俗易懂啊,那么接下来我们就来以口语化的形式来大家深入的了解一下这个堆的概念,首先我们通过上面的介绍知道这么几件事情第一:这里的堆本质上就是一个完全二叉树。第二:堆还分为两种一种是大堆,一种是小堆。那么首先我们来看看完全二叉树是什么?我们之前介绍过树的概念,我们说一颗树中会存在着诸多的节点,每个节点含有的子树的个数称为该节点的度,那么我们这里的二叉树的意思就是说我们这棵树中的每个节点的度都为2,然后我们这里的堆他是一个完全二叉树,所以我们这里就知道这个数的特征就是这个树的特征就是前k-1层都是满的,第k层可以满也可以满,但是第k层从左到右必须得是连续的,并且每个节点的度都为2 ,那么这是我们的堆的第一个特征,我们再来看看第二个特征就是这里的大小堆是什么意思?他说小堆得满足一个特点就是ki <=k2i+1 且ki <=k2i+2,这是什么意思啊?我们把这个算术式改成人话来看的话就是说我们这个堆中下标为i个元素得小于我们这个堆中下标为2i+1的元素和下标为2i+2的元素,嗯?这里大家是不是感觉非常的奇怪啊!为什么非要小于这两个元素呢?那么我们这里就来画图看看,首先我们先创建一个数组这个数组里面装有10个元素,然后我们将其以完全二叉树的形式来进行排列来看看会发生什么,那么我们这里就简单一点数组的10个元素就分别为1到10然后按照顺序依次放到完全二叉树里面: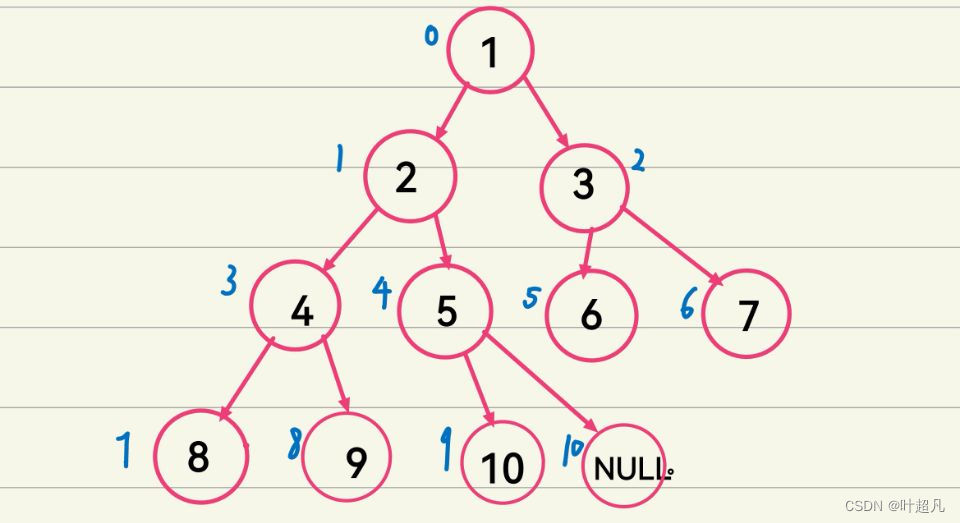
那么这时候我们的二叉树就长这样,然后我们再来分析一下,我们让i的值为0也就是这里的根节点,然后我们就可以算出来2i+1的值和2i+2的值分别为1 和2 ,那么我们这里再回到这个图中看看下标为1 和2 的节点在哪?嗯?竟然为下标为0的两个子节点,斯!是不是纯属巧合啊我们再来试一下,我们假设i的值为2 ,那么2i+1的值和2i+2的值分别为5和6我们再来看看下标为5和6 的节点在哪?斯也刚好是小标为2的两个子节点,那么看到这里想必大家应该知道了一件事就是当我们的小标为i的时候,这个节点的左子节点的下标为2*i+1,右子节点的下标就为2*i+2,那么我们再回过头来看这个那个算式,我们是不是就可以很清楚理解这个小堆的概念就是每一个子节点的值要比该子节点的双亲节点的值要大,比如说我们上面的例子就是一个小堆,下标为1 的节点的值是2,当他作为子节点的时候他的值要比他的双亲结点(下标为0,值为1 )的值要大,而当他作为双亲节点的时候他又比他的子节点的值要小,他的子节点的下标分别为:3和4,子节点的值分别为5和6,那么看到这里想必大家应该知道了小堆的概念,那么我们这里的大堆的概念就完全与之相反,之前小堆的概念是所有的双亲节点的值都要比子节点的值要小,那么我们大堆的概念就是所有的双亲的节点的值都要比子节点的值要大,大家可以自行推导一下这里就不用过多的赘述。好看来上面的描述想必大家应该对堆的概念有了一定的了解,那么我们这里就来拿总结一下堆的性质:
- 堆中某个节点的值总是不大于或不小于其父节点的值。
- 堆总是一颗完全二叉树。
- 通过小堆或者大堆我们能够快速的找到一个数组中的最小值或者最大值。
其次这里大家要注意的一点就是我们的堆实际的存储方式是以数组的形式来存储的,但是我们上面在表示的时候是以树的形式来表示的,这是因为我们的表示方法有两种:一种是逻辑结构,一种就是存储结构,那么我们这里看到的树就是逻辑结构,而以数组的形式存储的数组就是存储结构。好看到这里我们就有了一个问题要解决了,就是如何把我们的存储结构改成逻辑结构?并且对存储结构进行一系列的删除添加操作之后还能够保持其原有的逻辑结构就成了我们这里的主要问题。
堆的实现
堆的准备工作
首先我们得想明白一件事情就是我们的堆得用什么来实现?我们说堆的存储结构是数组,所以我们这里的实现的方式是以顺序表的形式来进行实现,那我们是采用静态的顺序表还是动态的顺序表呢?我们说静态的顺序表有着许多的不足,所以我们这里采用动态的顺序表来实现这个堆,那么我们这里的结构体就长这样:
typedef int HpDataType;
typedef struct Heap
{
HpDataType* a;//指向动态开辟内存的地址
int size;//目前数据的数目
int capacity;//动态内存的大小
}HP;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
堆的插入
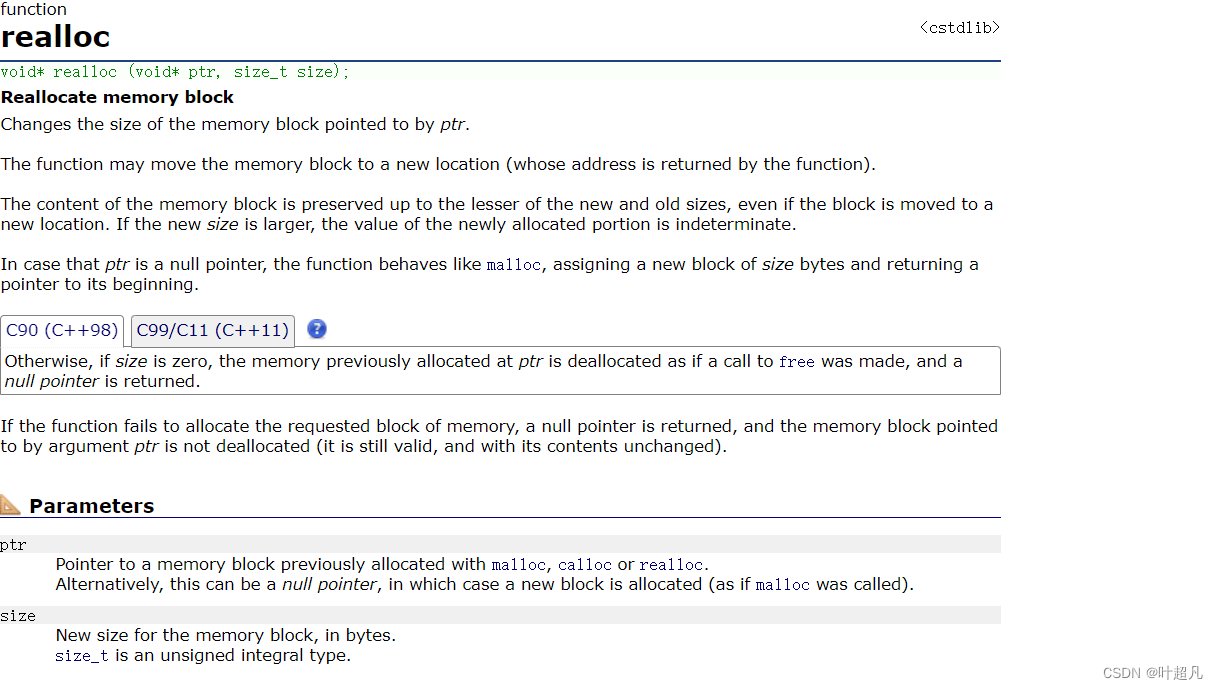
好我们的初始化工作准备好了,。那么接下来我们就要来实现我们的堆的第一个功能就是往这个堆里面插入数据,啊这时候有小伙伴会说啊,插入还不简单嘛,我们直接根据size的大小来实现尾插不就可以了吗?如果大家要是这么想的话,那可能就对堆的概念理解的不是很透彻了,我们这里的插入不能是简简单单的尾插,因为我们在插入数据之前这组数据本来就是一个堆,而且我们还不知道插入的数据的大小是多少,所以我们在插入数据之后还得做出一系列的调整来使其插入数据之后这组数据依然有堆的性质,所以如何调整就成了我们要解决的一个问题,在解决这个问题之前我们还得解决一个问题就是,我们这里是一个动态开辟的空间,我们在插入数据之前首先得判断一下我们这里开辟的空间大小还够不够是否需要对其进行扩容,那么我们这里就来先写一个函数来判断一下,那么我们这里的判断的依据就是size的大小是否等于我们capacity的值,小于的话我们就不需要对其进行扩容,如果等于的话说明我们这个空间已经满了,我们就得用realloc对其进行扩容将其大小变成两倍,但是这里有一种情况就是我们一开始的空间大小为0,我们对其扩容两倍的话大小还是为0,所以我们这里还得分为两种情况一种就是一开始capacity为0的时候,另外一种就是capacity不为0的时候,如果为0的话我们就将其赋值为4表示能够装下4个元素,如果不为0的话我们就将其扩大两倍。然后我们这里的扩容和开辟空间用到的都是同一个函数realloc因为这个函数当你给的地址为NULL的话他就会给你开辟一个新的空间,功能和malloc的功能一模一样,大家如果忘了话可以看看这个函数的介绍:
 、
、
那么我们这里在扩容完之后不能着急的将这个函数的返回值赋值给我们这里结构体的指针,因为我们这里可能会因为扩容失败而返回一个空指针,所以我们这里得再创建出来一个指针变量来先接收一下这个函数的返回值,然后再来判断一下这个变量的值是否为空,如果不为空的话我们再将他赋值到结构体里面去,那么我们这里的代码就如下:
void Heapcheckcapcity(HP* php) { assert(php); if (php->capacity == php->size)//判断空间是否满了 { int newnumber = php->capacity == 0 ? 4: php->capacity * 2;//判断一下capacity一开始的值是否为0 HpDataType* cur = realloc(php->a, newnumber*sizeof(HpDataType)); if (cur == NULL)//判断扩容是否成功 { perror("realloc fail");//打印一下扩容失败 exit(-1); } php->a = cur;//将扩容成功之后的地址赋值给我们的结构体里面的指针 php->capacity = newnumber;//更改容量的指向 } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
好我们的检查并且扩容的函数完成之后我们就来实现调整函数,那么我们这里就建立一个小堆,我们一开始是将这个元素插入到这个数组的尾部,就像这样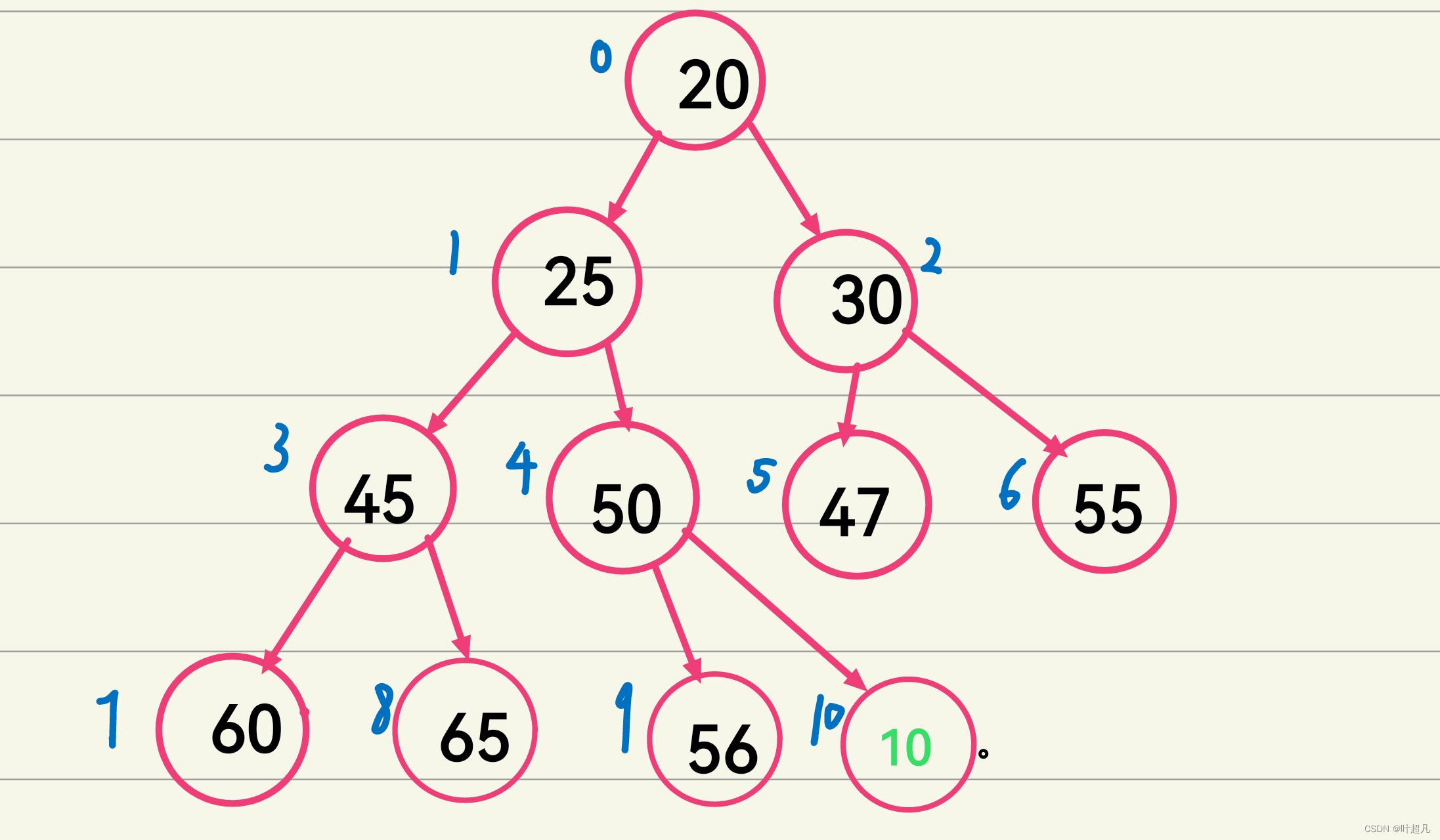
我们这里的10就是直接尾插到我们的数组里面没有做出任何的调整,所以他就会直接来到我们这个树的最后面,但是大家仔细观察一下就会发现在没有插入这个数据之前我们这里的数据关系是一个小堆,但是我们这里插入数据之后我们似乎就破坏了这里的结构,因为10的双亲节点的值为50比10大,所以这就不够成我们对小堆的定义,所以我们这里就要对其做一下调整,我们将10与50做一下替换,这样我们就能保证这三个节点能够是一小堆,就像这样:
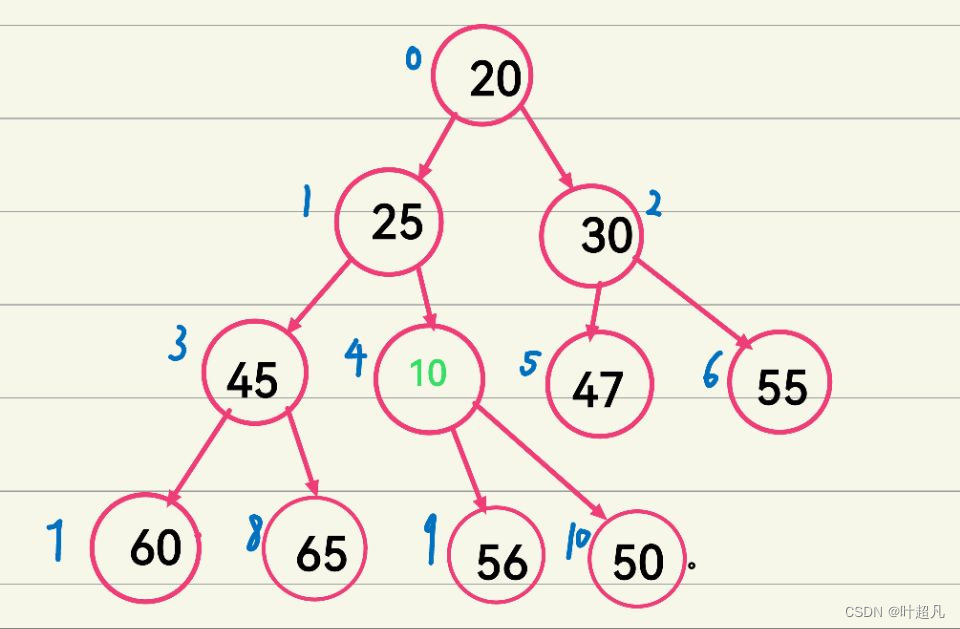
经过上面的操作我们的10就来到他原来的双亲节点的位置也就是下标为4的位置,但是这样的话他的双亲节点也就同样的发生了一点改变,变成了下标为1,所以他的双亲节点的值也就变成了25,那这么看的话我们这里是不是就不符合小堆的条件了,所以我们这里再做出一个调整,我们将他与他的双亲节点的值进行一下交换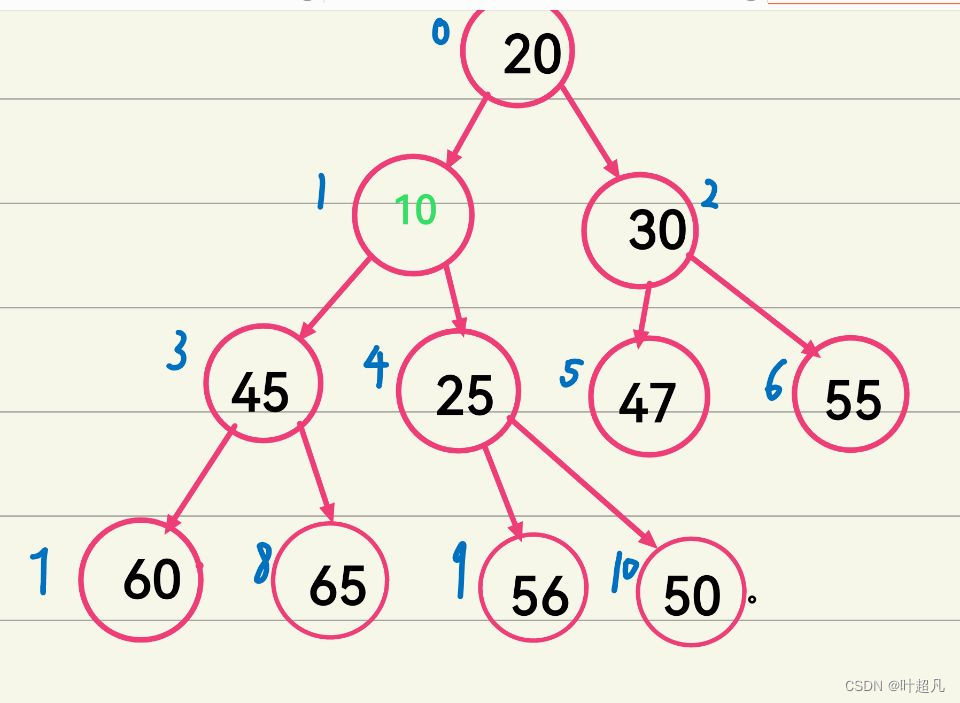
但是交换之后我们发现好像又出现了同样的问题,所以我们这里就得再来做一下调整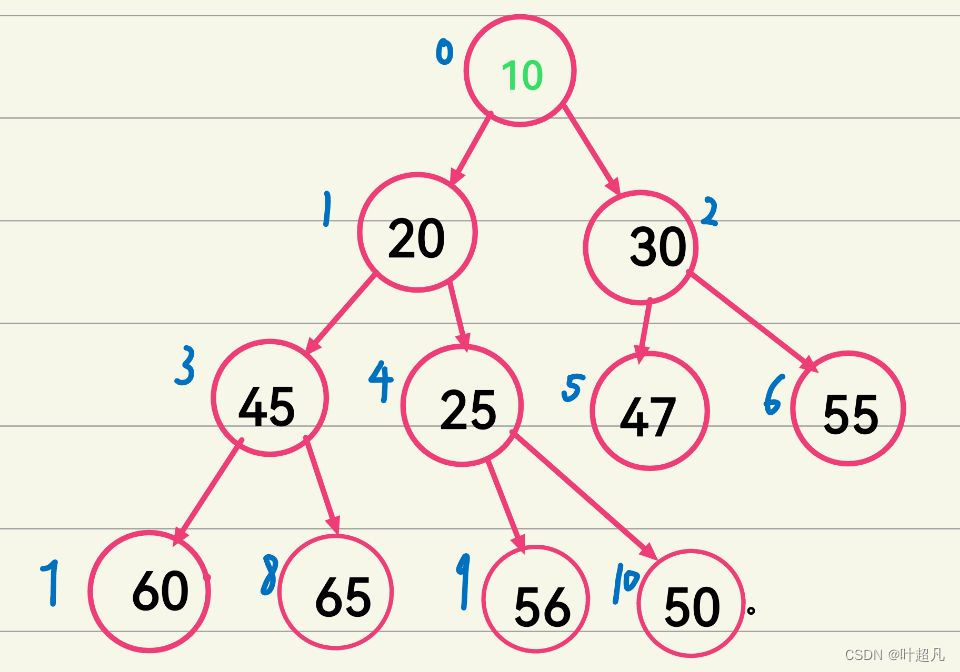
调整成这样我们发现没有地方可以调整了,我们的10来到了根节点的位置,所以我们这里的调整就结束了,那么大家仔细地回顾一下这个过程,我们发现其实这就是一个循环地过程,我们每次循环都调整一下两个位置地值,那么既然是循环,是不是就得有停止地时候,那这里什么时候停止呢?我们上面地例子是不是当我们的10来到根节点的位置的时候没有值可以比较了才截至,所以这就是一种情况,当然还有另外一种情况就是我们比较结束了,我们的10来到了一个位置他的值比他的双亲节点的值要大,不需要进行调整了是不是也就调整结束了啊,所以这两种情况就是我们比较结束的条件,那么我们的代码应该怎么写呢?我们这里就来创建出来两个变量一个叫child一个叫parent这两个变量就分别记录新插入的节点的位置,和该节点的双亲节点的位置,那么一开始我们的孩子节点的位置就是size的值,然后我们可以根据之前讲过的parent值的计算公式得出parent的下标为(child-1)/2,因为我们每次都会改变parent和child的值所以我们得将其放到一个循环里面,然后在这个循环里面我们就得用一个if语句来判断一下他和他的双亲节点的大小,因为我们这里是建立的小堆,所以我们这里判断的内容就是a[child]>a[parent]的时候我们就交换一下两个位置的值,然后再将我们的parent和child的值进行一下交换,既然我们这里是大于的时候就执行下面交换的值,那其他情况呢?我们是不是就可以直接退出这个循环啊,因为我们已经找到他应该在的位置了,不需要调整了所以我们就在写一个else在里面直接放一个break,好那么我们大致的代码就写出来了:
void adjustdown(HpDataType* a, int child) { int parent = (child - 1) / 2; while () { if (a[child] > a[parent]) { swap(&a[child], a[parent]); child = parent; parent = (child - 1) / 2; } else { break; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
那么我们这里就差一个循环的条件和swap函数没有写,那么我们这里就来看看这里的循环结束的条件是啥?我们说这里结束的条件有两个,一个是当这个插入的节点到了合适的位置就结束,那么我们这里的break语句做了一点,另外一个就是当插入的节点调整到了根节点的位置时候就结束了,那我们这里while就来解决另外一种情况,我们想想插入的节点来到根节点的位置的特征是什么?是不是就是child的值等于0的时候啊,这个时候他来到了根节点的位置我们就不需要调整了,当child大于0的时候都还需要调整,那么我们这里循环结束的条件就可以是child的值大于0,但是这时候有小伙伴说那能不能是parent的值小于0 的时候循环结束呢?哎这么一说好像还挺有道理呢!当parent的值还大于等于0我们就继续这个循环,当小于0的时候我们就退出循环,循环的条件就是:parent>=0,那我们能不能以这个作为循环的条件呢?答案是不行的,因为我们这里parent的值的改变是通过这个算式来进行改变的:parent = (child - 1) / 2但是我们发现当我们的child等于0的时候他的parent的值算出来还是等于0,所以这里就又会进入一个循环,但是进入循环之后他还是会通过else语句跳出循环,也就是说结果是对的,那这时就有小伙伴说啊,那结果是对的不就够了吗?管他是怎么实现的,那这里我们就要说一件事啊,他的结果却是事对的,但是他的过程是错的,你把这个循环的条件去掉,然后将其改成一个死循环他也能给出你正确的答案,但是你有没有想过一件事情就是如果有人读你的代码他会怎么想呢?你把这个循环改成一个死循环他也能给出真确的答案,但是读你代码的人他会怎么想,他会想着这里给一个死循环干嘛啊?对吧,而且这么写的话要是以后做出一定的修改,而这种修改结合到你这个错误的条件导致出现了新的问题那又该怎么办呢?对吧,所以我们这里还是谨慎一点为好,我们该是什么样的条件结束就以什么样的条件的结束,不能依靠其他的条件。好看到这里我们这个函数的实现就完成了,我们完整的代码就如下:
void AdjustUp(HpDataType* a, int child) { int parent = (child - 1) / 2; while (child>0) { if (a[child] < a[parent]) { swap(&a[child], a[parent]); child = parent; parent = (child - 1) / 2; } else { break; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
那么接下来我们再来实现一下swap函数,这个函数就非常的容易的实现了,我们就不多废话直接上代码:
void swap(HpDataType* a, HpDataType* b)
{
HpDataType c = *a;
*a = *b;
*b = c;
}
- 1
- 2
- 3
- 4
- 5
- 6
好这些主要的部分我们实现之后我们就来完成整个插入函数的功能,首先判断一下传过来的指针是否为空,然后再检查一下空间是否还够,然后我们再对其进行一下尾插,最后在调整一下之间的位置,那么我们这里的代码就如下:
void HeapPush(HP* php, HpDataType* a)
{
assert(php);
Heapcheckcapcity(php);
php->a[php->size] = a;
php->size++;
AdjustUp(php->a, php->size);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
那么我们这个函数写完之后我们就来测试一下这个代码写的是否是正确的,但是这里为了测试的方便我们再创建一个函数这个函数就来打印我们这个顺序表里面的值,那么这个打印的函数就非常的简单根我们之前的顺序表是一模一样的我们就不多说了直接上代码:
void HeapPrint(HP* php)
{
assert(php);
int i = 0;
while (i < php->size)
{
printf("%d ", php->a[i]);
i++;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
然后我们这里还差一个初始化函数这个函数的功能就是将我们这个顺序表里面创建的结构体进行一下初始化将一开始的值初始化为0 ,将指针初始化为空,那么我们这里的代码就如下:
void HeapInit(HP* php)
{
assert(php);
php->capacity = php->size = 0;
php->a = NULL;
}
- 1
- 2
- 3
- 4
- 5
- 6
好这几个函数写完之后我们就可以来测试一下我们的代码写的对不对,那么我们测试的代码就如下:
#include<stdio.h> #include"heap.h" int main() { HP tem; HeapInit(&tem); HeapPush(&tem, 10); HeapPush(&tem, 9); HeapPush(&tem, 8); HeapPush(&tem, 7); HeapPush(&tem, 6); HeapPush(&tem, 5); HeapPush(&tem, 4); HeapPush(&tem, 3); HeapPush(&tem, 2); HeapPush(&tem, 1); HeapPrint(&tem); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
我们插入数据的顺序就是10,9,8,7…1,然后我们调整之后的顺序就是:

那么这是一个小堆吗?我们可以画个图来看看:
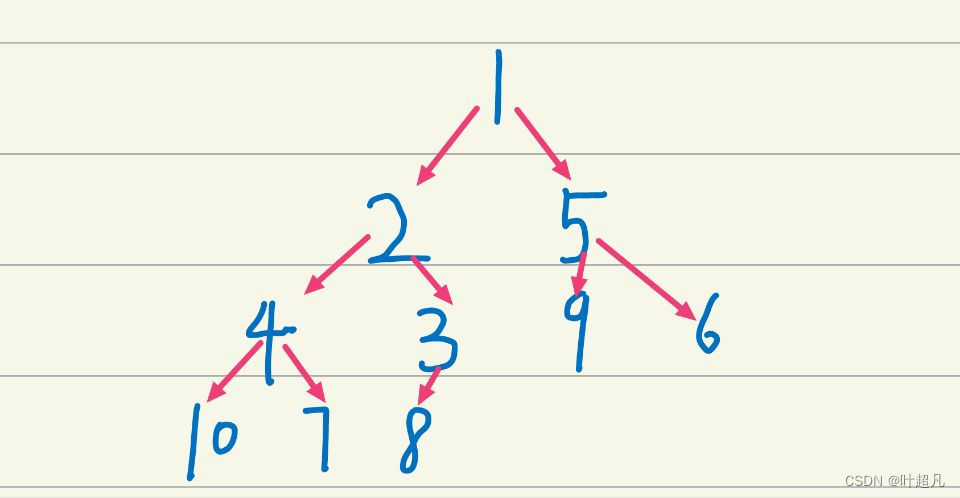
那么我们看一看这个图就可以发现我们这里建立的确实是一个小堆,但是这个堆建立的过程是对的吗也就是说我们这个堆建立的就一定是对的吗?可不可能确实是小堆但是是另外的一种形式呢?那么我这里验证了一下还是对的,我们这里没有错哈。那么我们这个堆的的建立就完成了。但是只是将这个堆建立出来是完全不够的,我们还得对堆进行一系列其他的操作比如说我们想要得到这个堆顶的元素,那我们是不是得再写出一个函数出来来实现这个功能,那这个功能就非常好的实现,因为我们的堆顶的元素就是数组种下标为0的元素,所以我们这里就可以利用数组名和数组的下标来获得我们堆顶的元素,但是这里我们得先用assert函数来判断一下我们这里传过来的地址是否为空,并且还得判断一下这个数组中还有没有元素?以此来增强我们代码的稳定性,所以在实现这个函数之前我们得先实现一个函数就是判断一下这个数组是否为空,那么这个函数也十分好实现我们直接看这个结构体中的的size的大小是否为0,如果为0就说明该数组为空,大于0就说明不为空,那么我们的代码就如下:
int HeapEmpty(HP* php)
{
assert(php);
return php->size;
}
- 1
- 2
- 3
- 4
- 5
那么有了这个函数之后我们的返回堆顶的元素的函数的代码就如下:
HpDataType HeapTop(HP* php)
{
assert(php);
assert(HeapEmpty(php));
return php->a[0];
}
- 1
- 2
- 3
- 4
- 5
- 6
我们可以再来测试一下这个函数实现的正确性,那么我们测试的代码就如下:
#include<stdio.h> #include"heap.h" int main() { HP tem; HeapInit(&tem); HeapPush(&tem, 10); HeapPush(&tem, 9); HeapPush(&tem, 8); HeapPush(&tem, 7); HeapPush(&tem, 6); HeapPush(&tem, 5); HeapPush(&tem, 4); HeapPush(&tem, 3); HeapPush(&tem, 2); HeapPush(&tem, 1); HeapPrint(&tem); printf("\n"); printf("顶部的元素为:%d", HeapTop(&tem)); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
我们来看看这段代码的运行结果为:
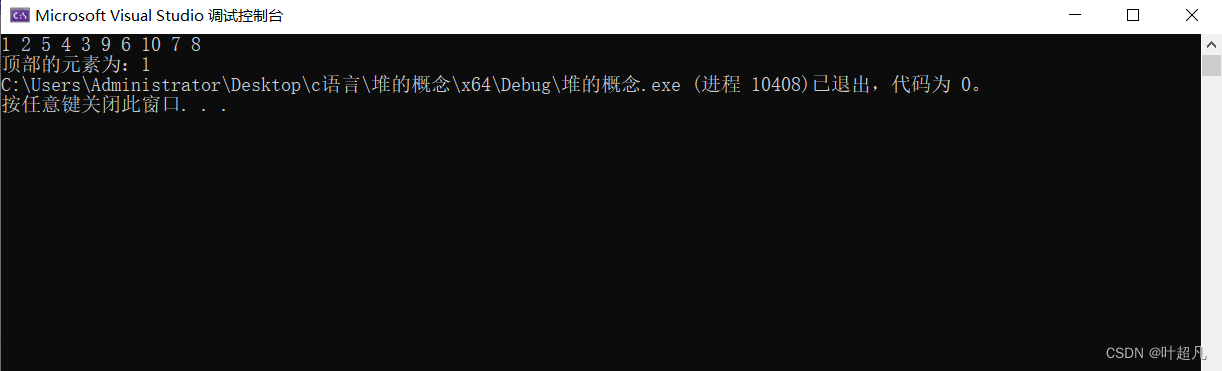
那么看到这个结果就说明我们这里的代码实现的是真确的,那么我们接着往下看。
堆的删除
大家看了上面的讲解应该知道了堆的建立的过程,那我这里问大家一个问题,我们这里大堆小堆中堆顶的意义是什么呢?我们还是拿小堆举例子,小堆中堆顶位置的元素是不是就是这个数组中最小的元素,那我们把堆顶的元素删除掉呢?是不是这个数组为了保持堆的性质,还会做出一些调整,这时候堆顶就会放置一个新的数据进来,那这时这个堆顶的元素是不是就是原来的数组中次小的元素,所以我们知道了一件我们每次删除堆顶的元素之后就能获得一个一个次大或者次小的元素,那么我们这里的删除又该如何来删除呢?啊这时候有小伙伴们就说啊,删除还不好删吗?直接把头元素删除之后,把后面的元素往前面挪动不就可以了吗?根之前的顺序表一模一样的啊,但是如果大家这么做的话,我们之前构造的逻辑关系就全部都混乱了啊,我们构造的堆那就完全不是堆了,所以我们就不能采用这样简单粗暴的方法,所以我就想另一个方法,我们这里是要删除头部的元素,但是我们直接删除这个头部元素并且挪动数据的话会影响这个堆的组成,那如果我们删除的是尾部的数据呢?是不是就不会影响整个堆啊,所以我们这里能不能采用这么一个思路,我们先将这个堆中的第一个元素和最后的一个元素进行互换,然后这时我们的尾部就是我们想要删除的元素,我们再来执行一下尾删这样的话是不是就将之前头顶的元素给删除了啊!而且我们还保证了一个大致的堆的结构,但是我们这里没有完,因为我们这只是一个大致的堆的结构,我们根节点的两个子树是堆,但是加上这个根节点变成一个整体的时候就不是一个堆了,所以我们这里就还得做出一个调整,我们得将这个顶部的元素调整到它应在的位置,那么我们这里就得来一个向下调整,之前我们插入元素的时候做出的调整是向上调整,我们做出向上调整的原因是因为我们插入的数据会存在着比它的双亲节点大的情况(对于大堆而言)也可能存在插入的数据比它的双亲节点小的情况(对于小堆而言),所以我们这里就创建了一个向上调整的函数,来解决这个问题,那么我们这里是不是也存在着同样的情况啊!对吧因为我们将数据进行了替换导致一个元素在此位置而影响了整个数组不是堆的情况,所以我们就再来写一个函数这个函数叫做向下调整这个函数的功能就是将此时头顶的元素往下进行调整将其放到一个合适的位置,那么我们这个函数实现的方法与之前的向上调整类似,因为我们这里调整的是双亲结点,(对于小堆而言)所以我们每次都将双亲节点与两个子节点中较小的节点进行比较,如果子节点较小的话,我们就将子节点与双亲节点进行交换,又因为这里的比较不止一次,所以我们将其放到一个循环里面,那么这个循环结束的条件是不是也会有两个,一个是在数组的中间就找到了合适的位置不需要进行调整了直接跳出循环,另外一种就是来到树的最下面已经没有子节点了就结束循环这两种情况,那么第一种情况好说直接用if语句比较一下就可以了,那第二种呢?我们要在while后面的括号种填入什么呢?我们想一想不难发现当我们根据父节点的位置算出子节点的位置时,我们直接拿该值与结构体中的size的值进行一下比较不就够了嘛,如果比size的值要大的话我们就说明没有子节点了,如果要小的话就说明是有子节点的,那么我们向下调整的代码就如下:
void AdjustDown(HpDataType* a, int n, int parent) { int minChild = parent * 2 + 1;; while (minChild < n) { if (minChild + 1 < n && a[minChild + 1] < a[minChild]) { minChild++; } if(a[minChild]<a[parent]) { swap(&a[minChild], &a[parent]); parent = minChild; minChild = parent * 2 + 1; } else { break; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
那么这个代码我们这里还有一些解释的地方,首先就是第一个if语句:
if (minChild + 1 < n && a[minChild + 1] < a[minChild])
{
minChild++;
}
- 1
- 2
- 3
- 4
我们这个代码的思路就是让两个子节点的最小的节点与父节点进行一下比较,但是首先我们要干的第一件事就是要找到那个较小的子节点,所以我们这里代码的思路就是先创建一个变量将这个变量的值赋值为左节点的下标,然后我们再来一个if语句如果我们的右节点存在,并且右节点的值小于左节点的值我们就让那个变量的值加一,这样我们的那个变量就会指向右节点,那么这就是我们这个代码的意思,那么我们这个函数里面的就是结构体里面size的值,那么我们写完了向下调整函数我们就可以完成这个函数了,首先判断一下php会不会为空指针,然后判断顺序表会不会为空,再交换一下首和尾的值,然后再让size的值–,最后来一个向下调整就完成了该函数的功能,那么我们的代码就如下:
}
void HeapPop(HP* php)
{
assert(php);
assert(HeapEmpty(php));
swap(&php->a[0], &php->a[php->size - 1]);
php->size--;
AdjustDown(php->a, php->size, 0);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
那么我们这里就可以来测试一下这个函数的真确性,那么我们测试的代码就如下:
#include<stdio.h> #include"heap.h" int main() { HP tem; HeapInit(&tem); HeapPush(&tem, 10); HeapPush(&tem, 9); HeapPush(&tem, 8); HeapPush(&tem, 7); HeapPush(&tem, 6); HeapPush(&tem, 5); HeapPush(&tem, 4); HeapPush(&tem, 3); HeapPush(&tem, 2); HeapPush(&tem, 1); HeapPop(&tem); HeapPrint(&tem); return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
那么我们这里测试的结果就如下:
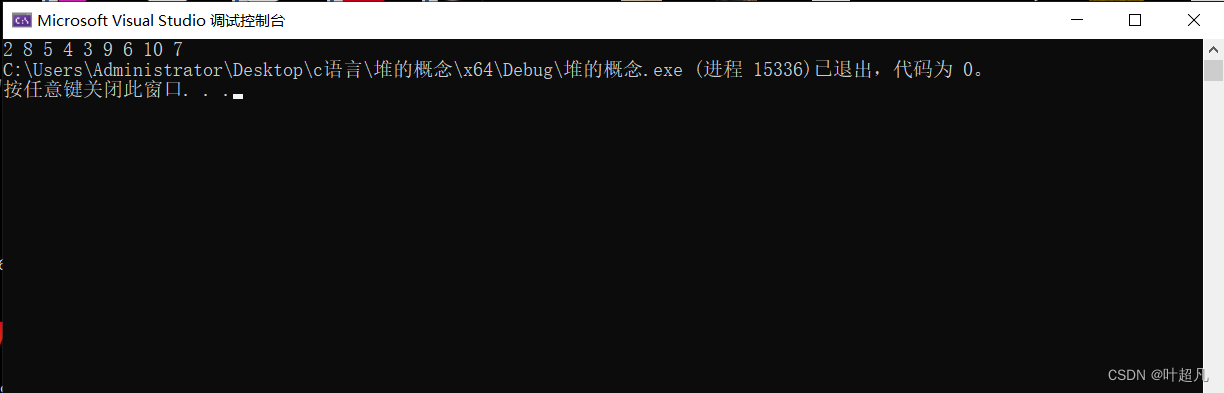
大家可以看到当我们把头部的数据删除之后我们这里的头部数据就变成了2,而2刚好也是次小的数据,所以我们这里的数据的删除实现的就是真确的。
堆排序
那么我堆的建立就算是完成了,那么这里大家应该能够发现一个特点就是我们可以通过堆的删除来不停的得到最小,次小,次次小…等数据,那么也就是说我们可以通过这个规律来获得一个个呈递增或者递减的数据,进而说我们好像可以通过这个数据来实现一下排序的功能,比如说下面的代码:
#include<stdio.h> #include"heap.h" int main() { HP tem; HeapInit(&tem); HeapPush(&tem, 10); HeapPush(&tem, 4); HeapPush(&tem, 6); HeapPush(&tem, 15); HeapPush(&tem, 21); HeapPush(&tem, 16); HeapPush(&tem, 8); HeapPush(&tem, 20); HeapPush(&tem, 25); HeapPush(&tem, 30); HeapPush(&tem, 40); HeapPush(&tem, 1); HeapPush(&tem, 2); //HeapPrint(&tem); int i = 0; int num = tem.size; HpDataType arr[13]; for (i = 0; i < num; i++) { arr[i] = HeapTop(&tem); HeapPop(&tem); } for (i = 0; i < num; i++) { printf("%d ", arr[i]); } return 0; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
那么这里我们就来打印看看这个代码的运行结果:
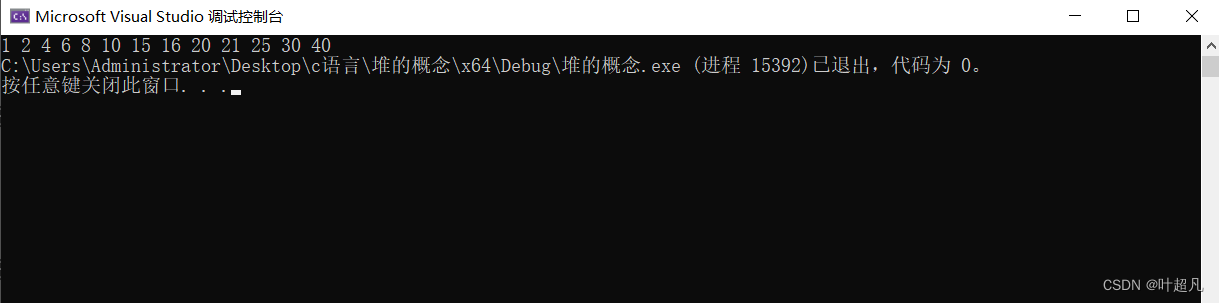
大家可以看到我们这里的数据确实都按照了递增的顺序进行了排列,但是大家有没有发现 这样的排序存在着一些问题首先就是我们要实现这个排序那前提是不是得要提前实现堆的建立啊对吧,我们得把有关堆的一个个的函数全部实现了才能实现这个排序,并且我们这个方法还得再创建一个数组出来,那这是不是就又会造成一定空间程度上的浪费啊对吧,如果我们这个数组有10000个数据,那我们是不是就得再创建一个能够容纳10000个数据的数组,所以这个方法就不是很可取,那么我们这里就得另寻一个更加高效的方法来解决这个问题,首先我们这里实现的方法就不能有创建数组的这个操作,其次我们实现堆的排序还不需要创建堆,那么我们这里就可以这么想,当我们的堆只有一个元素的时候他是不是堆?是的,那如果我们再往里面插入一个数据呢?那他可能是堆也可能不是堆,那我们这里再将其向上调整呢?那他这时就一定是堆了,所以我们这里就可以这么想,我们这里是一个数组,但是我们不将其看成一个整体,我们先用指针指向第二个元素,然后将这第二个元素进行向上调整,调整之后我们指针指向的元素加之前的元素就能够构成一个堆,大家想一想这是为什么?是不是因为我们的向上调整他与该元素的后面的元素是没有关系的,我们来看一些图来理解一下,首先我们的数组是这样:

我们的指针指向的是第一个元素,那么此时我们就不看10后面的元素,那这单独的一个10是不是就是一个堆,那此时我们再将指针往后面移动指向9,
那此时这里的10和9 的顺序就无法构成一个堆,所以我们就将这里的9进行向上调整,就成了这样:

然后我们再将指针往后挪动一位:
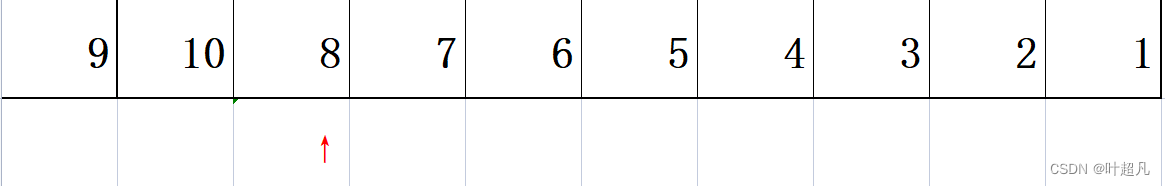
那这时指针前面的两个元素是不是就构成一个小堆了啊,那如果我们把这个8加上去呢?他还能构成堆吗?是不是就不能了所以我们这里就再将这个8进行向上调整,就成了这样:

然后我们再将这个指针往后挪动一位:

那这时我们指针前面的三个元素是不是就可以构成了一个小堆,那么我们这样依次类推当我们的指针来到了最末尾的时候是不是整个数组就构成了一个小堆了啊,所以当我们用这种思路就可以不提前创建堆就可以将一个数组修改成一个大堆或者小堆,但是这里大家有没有想过一个问题就是既然我们能够通过向上调整来建立一个堆的话,那我们这里能不能通过向下调整来建立一个堆呢?答案是可以的,但是我们这里的方法就会出现一点点的改变,之前的向上调整我们是从第二个元素开始,但是我们这里的向下调整建堆他却是从最后一个飞叶子节点开始,然后依次往前开始向上调整,比如说下面的这张图片:
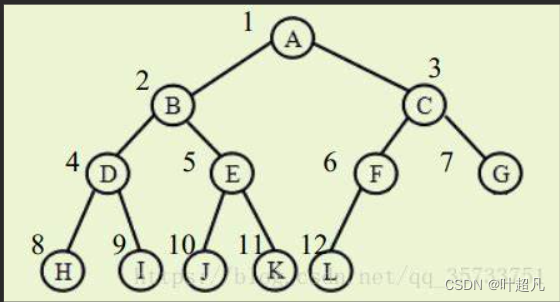
大家看看这张图,我们向下调整建堆就是从这里的下标为6的点开始的,因为该点是最后一个非子叶节点,那么我们这里就依次往上对这些节点进行向下调整,一直调整到根节点结束为止,那么我们这样做的作用是什么呢?大家可以想一下我们这里建立的是小堆,并且是从最后一个非子叶节点开始的,那么我们对该节点进行向下调整的作用就是让该双亲节点的值成为三个节点中的最小值,比如说上面的图,我们对E进行向下调整,那么这个E就会成为E,J,K中的最小值,然后我们再对D进行向下调整那么这个D就会成为D H I中的最小值,但是D E也有作为子节点的时候,当我们一顺来到B节点的时候我们再对其经行向下调整,那这个B是不是就会成为B D E 中的最小,那要是这样的话我们依次向下调整,我们的A经过向下调整是不是就会成为所有元素中的最小值,并且B会成为根节点的左子树的最小值,C也会成为根节点的右子树的最小值,所以我们这里向下调整的最后就可以构成一个小堆,那么我们这里既然有两种调整的方法,那这里到底使用哪一种呢?答案是向下调整的这种,因为这种调整的方式更快,为什么?大家可以这么想:首先同样的元素我们的向下调整是不是要调整的元素最少啊,因为我们是从最后一个非子叶节点开始调整的,而子叶节点一般都会在最后一层和倒数第二层,这两层占了整个元素的几乎一半,所以在调整的元素来看的话我们这里的向下调整的元素就更加的少,并且我们的向下调整越往下的元素调整的次数越少,比如说倒数第二层的部分元素就只用调整一层,而我们的向上调整最后一层却要调整好多次,而这种最后几层占的元素却是一大半,所以这就更加的导致了我们向上调整的效率低下,那么经过我们的计算我们这里的向下调整的时间复杂度向上调整建堆的时间复杂度是O(N*logN)而向下调整建堆的空间复杂度却是O(N),那么我们这里向下调整的建堆的代码就如下:
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i++)
{
AdjustDown(a, n, i);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
那么我们这里就可以来测试一下这个代码的正确性:
#include<stdio.h>
#include"heap.h"
int main()
{
HpDataType arr[10] = { 10,9,8,7,6,5,4,3,2,1 };
HeapSort(arr, sizeof(arr) / sizeof(arr[0]));
int i = 0;
while (i < 10)
{
printf("%d ", arr[i]);
i++;
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们来看看运行之后的结果为:

那么我们这里就是调整完之后的结果,我们仔细看一下的话就发现这个堆建立的是正确的,那我们的堆建立之后又该怎么办呢?比如说我们要这些数据降序,那我们该怎么办呢?我们这里建立的是小堆,我们可以轻松的得到最小的数,但是如果你想要得到次小的数呢?是不是就只能将这个数进行一下删除,来得到次小的数,但是这个删除还起到了一个非常奇妙的作用,我们这里的删除并不是将这个元素真正的删除,而是将他放到了这个数组的最后一个位置,我们之所以说删除是因为我们将能够访问的数组的长度减少了一个,这样我们就访问不到我们删除的数据,但是他实际还在,而这时我们再删除一个数据这时次小的元素就来到这个数组的倒数第二个元素啊,然后以此类推我们是不是就可以将整个数组有序了起来并且还是升序,那么我们这里是升序建立的大堆每次删除都将最大的元素放到堆的最后面,那如果是升序呢?我们建立的是不是就得是大堆每次都将最大的元素放到最后,然后再将其前n-1个元素看成一个整体再进行删除,那么这就是我们这里排序的过程,那么我们这里就得创建一个循环,每次循环都得将堆的第一个元素与第二个元素进行一下互换,然后再对这个第一个元素进行向下调整,又因为我们这里每次循环堆的元素个数都会少一个,所以我们这里就得创建一个i,每次在使用swap和AdjustDown的时候都将这个i减进去,并且每次循环都将i的值加一,那么我们这里的代码就如下:
void HeapSort(int* a, int n)
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
int i = 1;
while (i < n)
{
swap(&a[0], &a[n - i]);
AdjustDown(a, n - i, 0);
++i;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
那么我们就可以来测试一下这个代码的正确性,测试的代码如下:
#include<stdio.h>
#include"heap.h"
int main()
{
HpDataType arr[10] = { 10,15,13,4,23,45,49,1,2,6 };
HeapSort(arr, sizeof(arr) / sizeof(arr[0]));
int i = 0;
while (i<10)
{
printf("%d ", arr[i]);
i++;
}
return 0;
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
我们来看看 经过我们这个堆排序之后这个数组还能不能变成降序:
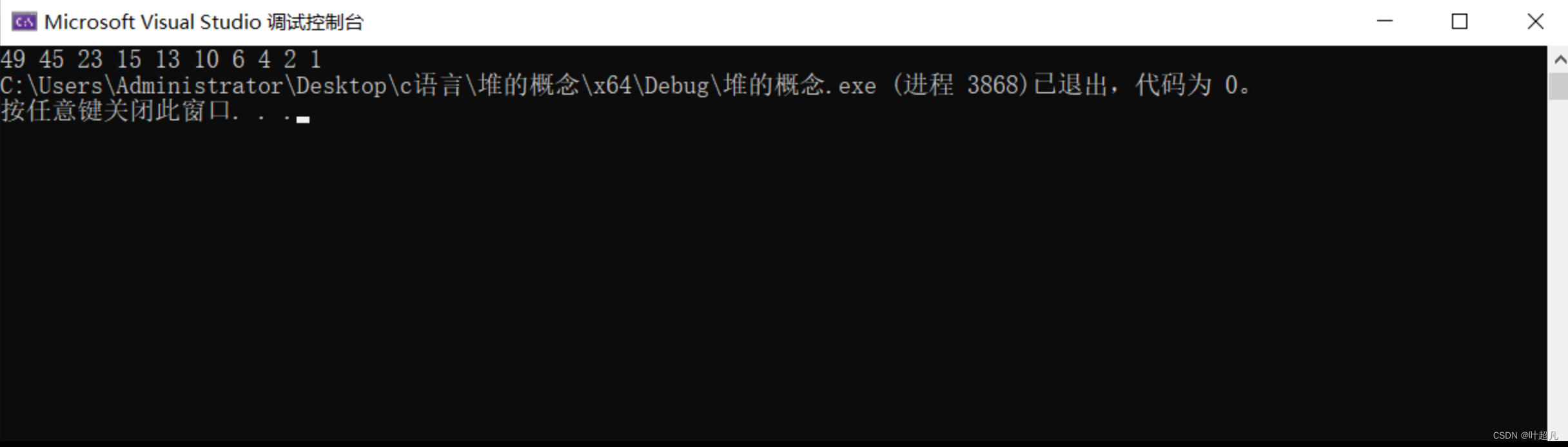
那么我们这里就可以看到我们的数组确实是以降序的形式进行排列,那么这个就是我们的堆排序的全部过程,由这个过程我们还引出了一个新的问题就是TopK问题,这个问题就是如何重一个没有顺序的数组中找到最大的K个元素,或者最小的k个元素,那么这时有小伙伴们说啊这还不简单嘛,我们直接对这个数组进行堆排序然后取出数组的开头或者末尾的K个元素不就够了吗?首先这个方法确实是没有问题的,但是如果我们这个数据非常的多呢?有10亿个数据有100亿个数据呢?这么多的数据是不可能放到我们的内存当中,所以我们有这个方法是不是就不行了啊,所以我们这里就采用另外的一种方法,我们首先创建一个堆,这个堆就刚好只能装下k个元素,因为这里的元素十分的多内存装不下,所以他就只能装到文件里面,那么我们这里就可以通过使用文件操作函数不停的往这个堆里面插入数据,将这个小堆装满之后我们再一次遍历后面的N-K个数据,那么这个遍历要做的事情就是与这个小堆的堆顶的元素进行比较,如果比这个堆顶的元素大的话我们就替换这个堆顶的元素,然后再将这个元素进行向下调整,这样依次遍历结束之后我们这里的小堆里面的元素就是最大的K个元素,那么我们这里原理就是我们小堆的堆顶的元素是该堆中最小的元素,而我们每次的比较的目的就是替换掉该堆中的最小值,因为我们这里是找到最大的k个元素,然后我们向下调整的目的就是从新找到堆中的最小值,再进行下一次的比较和调整,那么这就是我们的解决问题的思路,那么我们这里的代码就如下:
void PrintTopK(const char* filename, int k) { assert(filename); FILE* fout = fopen(filename, "r"); if (fout == NULL) { perror("fopen fail"); return; } int* minHeap = (int*)malloc(sizeof(int) * k); if (minHeap == NULL) { perror("malloc fail"); return; } for (int i = 0; i < k; i++) { fscanf(fout, "%d", minHeap[i]); } for (int j = (k - 2) / 2; j > 0; j--) { AdjustDown(minHeap, k, 0); } int val = 0; while (fscanf(fout, "%d", &val) != EOF) { if (val > minHeap[0]) { minHeap[0] = val; AdjustDown(minHeap, k, 0); } } for (int i = 0; i < k; i++) { printf("%d ", minHeap[i]); } fclose(fout); } void CreateDataFile(const char* filename, int N) { FILE* fin = fopen(filename, "w"); if (fin == NULL) { perror("fopen fail"); return; } srand(time(0)); for (int i = 0; i < N; ++i) { fprintf(fin, "%d\n", rand() % 1000000); } fclose(fin);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55

