
- 1django 重定向如何解决iframe页面嵌套问题_django 重定向 禁止iframe
- 2C语言求n的阶乘(n!)的3种方法
- 3python中的时间戳和日期的相互转化_python timestamp转换成date
- 4第十四届蓝桥杯第三期模拟赛 【python】_蓝桥杯模拟赛第三期python
- 5基于SpringBoot+VUE的考试题库刷题系统_在线刷题系统springboot+vue
- 6Git Gui相关术语_amend last commit
- 7JavaScript的基础运算符重点表达式_js 字符串+1
- 82024-01-06-AI 大模型全栈工程师 - 机器学习基础
- 9英伟达3080Ti、3070Ti来了:继续封锁挖矿性能,网友:不信,空气卡+1
- 10深入浅出Java基础_autoboxcachemax
Webserver简易项目
赞
踩
pr# Webserver组成部分
这个项目,粗略的看可以分为下面几个部分
- 建立socket通讯
- 服务器处理与客户端的IO
- 解析客户端的HTTP请求,并响应请求
建立socket通讯
Webserver服务器,肯定不可能只接收一个客户端的连接吧。所以这个项目是多线程并发同步执行的,而这之中就存在许多需要处理的细节,共享资源的访问,建立并维护线程池等。
locker.h
线程的主要优势在于,能够通过全局变量来共享信息。不过,这种便捷的共享是有代价的:必须确保多个线程不会同时修改同一变量,或者某一线程不会读取正在由其他线程修改的变量。
下面就创建一个线程同步机制封装类 —— locker.h
#ifndef LOCKER_H #define LOCKER_H #include <pthread.h> #include <exception> #include <semaphore.h> //线程同步机制封装类 //互斥锁类 class locker{ public: locker(){ if(pthread_mutex_init(&m_mutex,NULL)!=0){ throw std::exception(); } } ~locker(){ pthread_mutex_destroy(&m_mutex); } bool lock(){ return pthread_mutex_lock(&m_mutex)==0; } bool unlock(){ return pthread_mutex_unlock(&m_mutex)==0; } pthread_mutex_t * get(){ return &m_mutex; } private: pthread_mutex_t m_mutex; }; // 信号量类 class sem{ public: sem(){ if(sem_init(&m_sem,0,0)!=0){ throw std::exception(); } } sem(int num){ if(sem_init(&m_sem,0,num)!=0){ throw std::exception(); } } ~sem(){ sem_destroy(&m_sem); } // 等待信号量 bool wait(){ return sem_wait(&m_sem)==0; } // 增加信号量 bool post(){ return sem_post(&m_sem)==0; } private: sem_t m_sem; }; #endif

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
线程池
为什么需要线程池?
线程的创建和销毁都是需要时间的。Web服务器在运行时,必然会频繁的创建和销毁线程,那线程池就是用来解决线程生命周期开销问题。通过对多个任务重复使用线程,线程创建的开销就被分摊到了多个任务上了,而且由于在请求到达时线程已经存在,所以消除了线程创建所带来的延迟。这样,就可以立即为请求服务,使用应用程序响应更快。另外,通过适当的调整线程中的线程数目可以防止出现资源不足的情况。
线程池的组成部分:线程池管理器、工作线程、任务列队、任务接口等部分
这个项目,我们先创建线程池,任务类就先用模板来代替,template<typename T>,使用模板或许还可以稍加修改就能在其他项目使用。
那线程池的成员,大致也能分析出来,有需要后面再补充
private: // 线程的数量 int m_thread_number; // 描述线程池的数组,大小为m_thread_number pthread_t * m_threads; // 请求队列中最多允许的、等待处理的请求的数量 int m_max_requests; // 请求队列 std::list< T* > m_workqueue; // 保护请求队列的互斥锁 locker m_queuelocker; // 是否有任务需要处理 sem m_queuestat; // 是否结束线程 bool m_stop;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
接着写类的构造函数,析构函数,以及一个向任务队列添加任务的函数
public: //thread_number是线程池中线程的数量,max_requests是请求队列中最多允许的、等待处理的请求的数量 threadpool(int thread_number = 8, int max_requests = 10000); ~threadpool(); bool append(T* request); // 具体实现 template< typename T > threadpool< T >::threadpool(int thread_number, int max_requests) : m_thread_number(thread_number), m_max_requests(max_requests), m_stop(false), m_threads(NULL) { if((thread_number <= 0) || (max_requests <= 0) ) { throw std::exception(); } m_threads = new pthread_t[m_thread_number]; if(!m_threads) { throw std::exception(); } // 创建thread_number 个线程,并将他们设置为脱离线程。 for ( int i = 0; i < thread_number; ++i ) { printf( "create the %dth thread\n", i); // worker函数必须是一个静态的成员函数 if(pthread_create(m_threads + i, NULL, worker, this ) != 0) { delete [] m_threads; throw std::exception(); } // 成功返回 0,失败返回错误号 if( pthread_detach( m_threads[i] ) ) { delete [] m_threads; throw std::exception(); } } } template< typename T > threadpool< T >::~threadpool() { delete [] m_threads; m_stop = true; } template< typename T > bool threadpool< T >::append( T* request ) { // 操作工作队列时一定要加锁,因为它被所有线程共享。 m_queuelocker.lock(); if ( m_workqueue.size() > m_max_requests ) { m_queuelocker.unlock(); return false; } m_workqueue.push_back(request); m_queuelocker.unlock(); m_queuestat.post(); return true; } // 工作线程运行的函数,它不断从工作队列中取出任务并执行之 private: static void* worker(void* arg); void run(); // 静态worker,不会有this指针 template< typename T > void* threadpool< T >::worker( void* arg ) { threadpool* pool = ( threadpool* )arg; pool->run(); return pool; } // 线程池运行 template< typename T > void threadpool< T >::run() { while (!m_stop) { m_queuestat.wait(); m_queuelocker.lock(); if ( m_workqueue.empty() ) { m_queuelocker.unlock(); continue; } T* request = m_workqueue.front(); m_workqueue.pop_front(); m_queuelocker.unlock(); if ( !request ) { continue; } // 任务类的函数 request->process(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
pthread_create函数的第四个参数,是第三个参数worker函数的参数,但如果把worker为类成员函数的话,而worker其实还有一个隐藏的this指针,那这里就create不成功。所以需要把worker函数写为静态,将this指针去掉,但又会有另一个问题,就是worker函数可能会用到threadpool的成员变量或函数,静态函数不能访问非静态成员吧。那解决办法就是,把worker的参数,写为this指针,不就可以通过这个this访问了。
main()函数
socket相关的代码就直接写在main()函数中
#define MAX_FD 65536 // 最大的文件描述符个数 // 内联函数,小且需要多次调用 void perr(int ret,char* err){ if(ret == -1){ perror(err); exit(-1); } } // 函数指针handler,返回值类型是void,参数类型是int void addsig(int sig, void( handler )(int)){ struct sigaction sa; memset( &sa, '\0', sizeof( sa ) ); sa.sa_handler = handler; sigfillset( &sa.sa_mask ); // 断言assert(expression)宏,当expression为假时,打印错误(表达式)并终止程序,否则无作用 // sigaction注册信号捕捉,当检测到sig信号,就执行sa对象中的handler // 这里就是检查到SIGPIPE信号,但进行SIG_ING忽视 assert( sigaction( sig, &sa, NULL ) != -1 ); } // argc是main函数的参数个数,argv[]数组是main函数的参数集合 int main( int argc, char* argv[] ) { // 只要执行了程序,程序就会有一个参数,那就是程序所在的路径加上程序名 // 即argv[0] == ./webserver // basename的功能是去掉argv[0]的路径,只留下文件名,有后缀也会去掉后缀 if( argc <= 1 ) { printf( "usage: %s port_number\n", basename(argv[0])); return -1; } // 这里不把webserver的端口写死,而是在启动程序是通过参数传入,也就是argv[1] int port = atoi( argv[1] ); // 当客户端向服务器端程序发送了消息,然后关闭客户端 // 服务器端返回消息的时候就会收到内核给的SIGPIPE信号 // SIGPIPE信号会使服务器终止程序 addsig( SIGPIPE, SIG_IGN ); // 创建线程池,初始化线程池 http_conn就是任务类,这个稍后会写 threadpool< http_conn >* pool = NULL; try { pool = new threadpool<http_conn>; } catch( ... ) { return 1; } // 创建一个数组,用于保存所有客户信息。 这里又用到了http_conn类 // 本来应该要把客户信息,和任务方法等区分在不同的类中,但这里为了方便就写在一起了 // MAX_FD, 文件描述符值的最大值 http_conn* users = new http_conn[ MAX_FD ]; // 监听 int listenfd = socket( PF_INET, SOCK_STREAM, 0 ); int ret = 0; struct sockaddr_in address; address.sin_addr.s_addr = INADDR_ANY; address.sin_family = AF_INET; address.sin_port = htons( port ); // 端口复用 在bind之前设置 int reuse = 1; ret = setsockopt( listenfd, SOL_SOCKET, SO_REUSEADDR, &reuse, sizeof( reuse ) ); perr(ret,(char *)"setsockopt"); ret = bind( listenfd, ( struct sockaddr* )&address, sizeof( address ) ); perr(ret,(char *)"bind"); // 最大的连接数和未连接数之和是5 ret = listen( listenfd, 5 ); perr(ret,(char *)"listen"); // 接着就是服务器等待连接了 accetp // ...... }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
IO
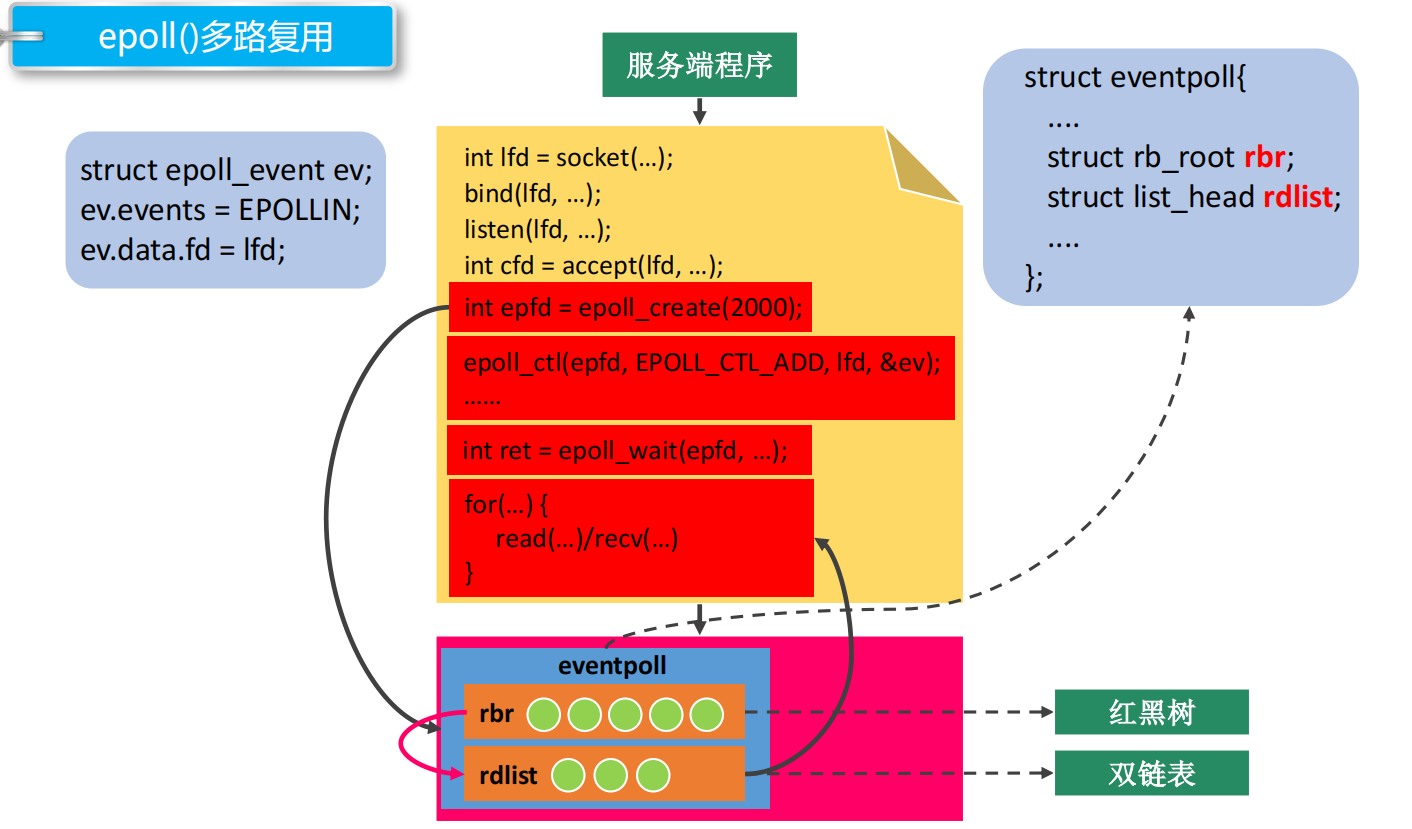
创建epoll对象后,在内核会有一个红黑树,用来存放注册的文件描述符;还会有一个双链表,用来存放发生事件的文件描述符,然后返回给程序,程序就能知道哪些客户端有需要读写数据
创建了epoll对象,把监听的文件描述符添加到epoll对象中,当有新的连接进来,主线程就能检测到并进行accept;accept之后得到的socket文件描述符,也注册到epoll对象中,等待事件发生。
// 接上面的代码声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/sysmno/article/detail/61660Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

