
- 1从jdk1.8升级到jdk17踩过的所有坑的总结_升级jdk17后commonsmutipartfile报错
- 2图像检索(花卉)_python+flask制作图像检索系统
- 3【搞懂AI】有免费的ChatGPT4.0吗?GPT血泪白嫖记_免费gpt4.0接口
- 4python批量卸载应用软件_使用python编写批量卸载android应用的脚本
- 5tensor的索引、切片、拼接和压缩等_tensor命令
- 6Python海南海口二手房源爬虫数据可视化分析大屏全屏系统 开题报告
- 7php建立服务器,利用 PHP 快速建立一个 Web 服务器
- 8深度学习--基础(一)pytorch安装--cpu & GPU版本_pytorch cpu版本和gpu版本
- 9Linux红帽认证管理员(RHCAS)考试笔记
- 10bisect_funbisect
云计算基础 -NUMA
赞
踩
UMA
UMA中文翻译叫:一致性内存访问
多个CPU通过同一根前端总线(FSB)来访问内存(所有的内存访问都需要通过北桥芯片来完成),若多个CPU访问内存的不同内存单元还是相同内存单元,同一时刻,只有一个CPU能够访问内存
随着CPU内核越来越多,性能越来越强,现在已经有双路、四路的服务器,若是UMA架构的话,前端总线很容易造成瓶颈
NUMA
NUMA中文翻译:非一致性内存访问
NUMA解决了UMA架构所有CPU同时访问内存时FSB性能瓶颈的问题
在NUMA出现之前,所有的CPU Core都是通过共享一个北桥芯片来读取内存,随着CPU的发展,CPU频率越来越快,核心越来越多,北桥在响应时间上的性能瓶颈也越来越明显。
为了解决前端总线性能瓶颈的问题,于是出现了NUMA架构
在NUMA这种架构下,不同的内存器件和CPU核心从属不同的NODE(节点),每个NODE都有自己集成的内存控制器(IMC),在NUMA内部,使用IMC Bus进行不同核心间的通信,不同的Node间通过QPI(快速互联通道)进行通信
一般来说,一个内存插槽对应一个Node,需要注意的一个特点时,QPI的延迟要高于IMC Bus,也就是说,CPU访问内存有了远近之别
同一NUMA NODE内的内存访问叫本机访问,不同NODE访问叫远地访问
每一个CPU(节点)都有自己的PCIE设备(本地IO资源),和内存相似,远地访问PCIE设备相对访问本地PCIE设备存在延时
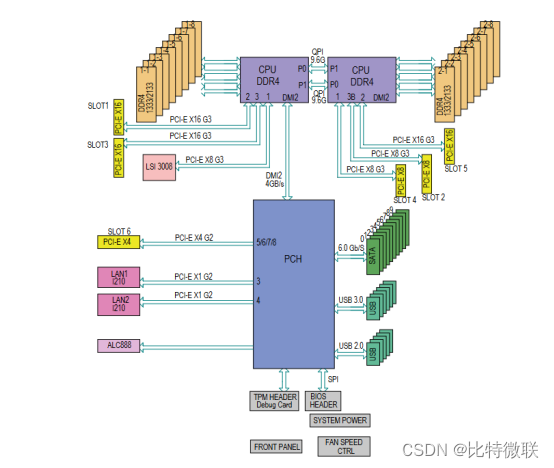
如下图,是超微某双路主板的逻辑图,可以看到,两颗CPU都有自己可以本地访问的内存,远地内存访问需要经过CPU之间的QPI通道,每颗CPU也有自己的PCIE设备等等
NUMA在云平台(虚拟机上)的应用
虚拟机NUMA就是把QEMU模拟出来的虚拟节点,绑定在某颗物理CPU上,对应的内存同样绑定在该CPU的本地内存,使其与物理架构相对应,在物理上也尽可能地使用CPU访问本地内存,这样我们就可以认为虚拟机能够识别服务器NUMA拓扑
具体优化方式如下
1. vCPU数如果比一颗物理CPU核数少,那么这个虚拟节点就会绑定在一颗物理CPU上
如:服务器双路,每颗物理CPU为8核8线程,创建一台虚拟机,虚拟机分配的vCPU是4颗,则这台虚拟机的虚拟节点就会绑定在CPU0或CPU1上
2. vCPU数如果比一颗物理CPU核数多,那么就会分开,然后绑定在多个物理CPU上
如:服务器双路,每颗物理CPU为8核8线程,创建一台虚拟机,虚拟机分配的vCPU是12颗,那么这个虚拟机的虚拟节点就会分开,分别绑在两颗物理CPU上
3. 如果单颗物理CPU超配或者内存不足(NUMA Node内的内存不足了)了那么就需要进行负载平衡,平衡过程中会进行CPU之间的负载均衡,这时会把虚拟节点迁移到另一颗物理CPU上进行绑定,并且对应的内存也需要跟着迁移,保证之前的本地内存还是本地内存。(导致NUMA资源碎片的原因:虚拟机开关机,新建删除虚拟机等)
如:一台服务器开启了10台虚拟机,有可能这10台虚拟机所使用的CPU和内存资源都是同一颗物理CPU提供的,此时该CPU若计算性能不足,或该CPU的本地内存占用过高,那么此时就需要将该CPU上的部分虚拟机移动到这台服务器上的另一颗CPU上去运行(同一台服务器CPU之间的负载均衡),即:将虚拟节点迁移到另一颗CPU上去绑定,并且对应的内存也需要跟着迁移,这样就能保证虚拟节点切换绑定之后,依旧可以访问本地内存,从而保证虚拟机性能
4. 通过优化调度算法,使虚拟节点的NUMA绑定都是保持性能最佳的状态
虚拟机如何拆为几个虚拟节点放置
对于虚拟机如何拆为几个虚拟节点放置(即:虚拟机要配置几个插槽),这里要考虑:
1. 虚拟机有几个虚拟节点:透传NUMA架构给虚拟机后,各个虚拟节点允许放到不同的物理节点上去(虚拟机内部自己可以感知)
物理NUMA架构与QEMU模拟出来的虚拟节点进行绑定,虚拟节点可以同时绑定在多颗CPU上
2. 虚拟机一个虚拟节点的vcpu个数是多少:对于每一个虚拟节点,那么还需要尽量放到最小范围的物理节点调用。
不能把物理CPU的节点数配置的过多,否则过多的调用会导致更多的性能开销
比如有一台4路服务器,每颗物理CPU的核心数为8核,此时需要新建一台vCPU数为12的虚拟机,此时该虚拟机最佳分配vCPU分配为2*6,以保证虚拟节点尽量放到最小的物理节点调用,不能分配为3*4或4*3,因为这样会把虚拟节点调度的范围变大了就会增加物理机的性能开销
如果物理CPU数大于12,vCPU分配应满足最小范围物理节点调用原则(最小插槽数),分配为1*12
注意:若需要透传NUMA拓扑给虚拟机,则该虚拟机需安装性能优化工具,且配置的CPU总核数大于8核(深信服HCI)
平衡
主要是如果一个物理节点的CPU或者内存超配的情况下就会考虑迁移平衡,平衡包括CPU平衡核内存的平衡,CPU平衡是通过cGroup来实现,但一个调度单元的vCPU线程迁移到另一个物理节点的时候,那么对应的内存也需要移动过来,保证之前的本地内存还是本地内存,这里通过内核接口实现内存迁移,迁移每256M物理内存需要2s(深信服)
NUMA的适用场景
1. 内存访问旺盛的业务,NUMA能大幅度提升性能,如果需要大量吃内存的数据库服务(Oracle、SQL、Server),编译服务等,内存访问频繁的场景,开启NUMA,计算性能提高7%~30%
2. CPU需求密集的小应用,开启NUMA会影响一些性能,虽然造成的损失不足以影响业务员,所以大部分应用无需考虑该问题(NUMA不适合应用频繁访问CPU的场景)

