
- 1深度学习毕设项目 深度学习实现行人重识别 - python opencv yolo Reid_yolo 行人重识别
- 2MySQL存储引擎及索引机制
- 3【Web开发】Vue+Springboot项目服务器部署(环境搭建+部署流程)_vue+springboot项目如何部署
- 4RxJava应用_rxjava使用
- 5Node isRunning函数_is_running
- 6Qt对excel操作_qaxobject是什么模块的
- 7Mac 开启局域网smb文件共享(附全平台连接方法)_mac samba
- 8JavaWeb毕设分享100个(四)_基于javaweb的毕业设计选题
- 9如何在windows下运行.sh文件_windows .sh
- 10Android中实现如win7里边屏幕保护图案中三维文字的效果。_android 立体字
K8s进阶之网络:pod内不同容器、同节点不同pod通信、CNI插件、不同节点pod通信、Flannel容器网络、Serivce连接外部网络、服务发现、Nginx反向代理与域名、Ingress代理_k8s不同容器暴露相同端口
赞
踩

1.Pod网络:同一pod内不同容器通信
Pod是Kubernetes中最小的可部署单元,它是一个或多个紧密关联的容器的组合,这些容器共享同一个网络命名空间和存储卷,因此Pod中的
所有容器都共享相同的网络命名空间和IP地址——PodIP,所以在同一个Pod内的容器间通信可以通过localhost直接通信。

k8s创建Pod时永远都是首先创建Infra 容器,也可以被称为pause容器。这个容器为其他容器提供了一个共享的基础设施,包括网络和存储功能,其他业务容器共享pause容器的网络栈和Volume挂载卷。
pause 容器被创建后会初始化Network Namespace网络栈,之后其他容器就可以加入到pause 容器中共享Infra容器的网络了。而对于同一个 Pod 里面的所有用户容器来说,它们的进出流量,认为都是通过 pause 容器完成的。
pause 容器会创建并管理虚拟以太网(veth)接口。在容器启动之前,pause 容器会为每个容器创建一个虚拟以太网接口,一个保留在宿主机上(称为 vethxxx),另一个保留在容器网络命名空间内并重命名为 eth0,如下图所示。这两个虚拟接口的两端是连接在一起的,从一端进入的数据会从另一端出来。
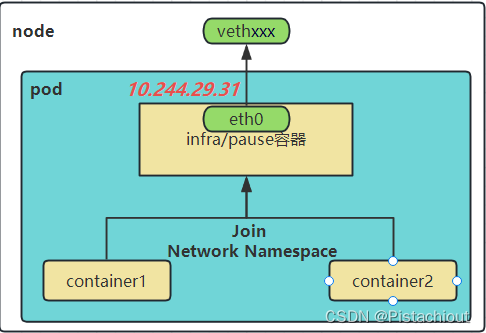
pause容器主要为每个业务容器提供以下功能:
- IPC命名空间:Pod中的多个容器能够使用SystemV IPC或POSIX消息队列进行通信。
- 网络命名空间:Pod中的多个容器能够访问同一个IP和端口范围。
- PID命名空间:Pod中的不同应用程序可以看到其他应用程序的进程ID。
- UTS命名空间:Pod中的多个容器共享一个主机名;
- Volumes(共享存储卷):Pod中的各个容器可以访问在Pod级别定义的Volum
2.Pod网络:同一节点不同pod间相互通信
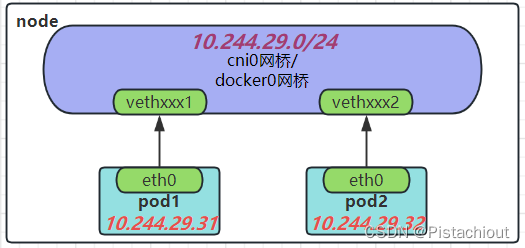
同一节点不同POD之间的通信是通过将容器网络接口(CNI)与主机网络命名空间中的虚拟以太网(veth)接口相连来实现的。 每生成一个新的Pod,那么在Node上都会根据插件来生成一个新的虚拟网卡如vethxxxx或者calixxxx,这个网卡会对应到Pod里的eth0。
如图,veth接口则被保留在主机的网络命名空间中,并被连接到CNI插件(如Flannel或Calico等)创建的虚拟网桥(如cni0或flannel0等)上。一旦这些veth接口被正确地连接起来,它们就可以进行通信了。当一个POD发送数据包时,数据包会通过其veth接口被发送到主机网络命名空间中的veth接口,然后该veth接口会将数据包发送到虚拟网桥上。虚拟网桥又会将数据包路由到目标POD的veth接口,最终将数据包发送到目标POD。
如图所示的ip地址与网桥网段,同一节点的不同POD的IP地址通常属于同一网段,并通过CNI插件连接到同一个虚拟网桥(如cni0)上。虚拟网桥会管理其IP地址空间和分配,确保不同POD的IP地址不会冲突。
具体的IP地址和网段取决于所使用的CNI插件和网络方案。例如,Flannel插件默认使用10.244.x.0/24的网段,其中x是随机分配给每个POD的。这意味着不同POD的IP地址将位于10.244.x.0/24的网段中,其中x是不同的值。
2.1 CNI介绍
CNI如Calico、flannel等本身并不能提供网络服务,它只是定义了对容器网络进行操作和配置的规范。CNI仅关注在创建容器时分配网络资源,和在销毁容器时删除网络资源。常见的CNI插件包括Calico、flannel等。
具体的流程如下图所示:
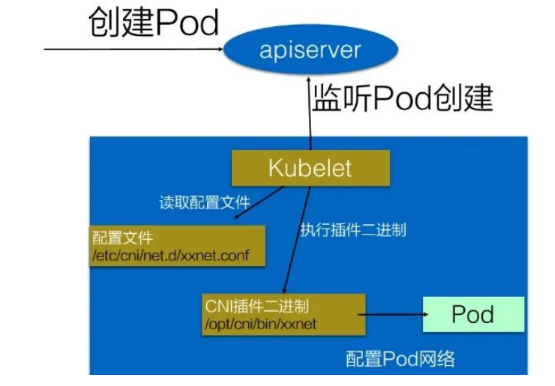
在集群里面创建一个 Pod 的时候,首先会通过 apiserver 将 Pod 的配置写入。apiserver 的一些管控组件(比如 Scheduler)会调度到某个具体的节点上去。Node节点上的Kubelet 监听到这个Pod的创建之后,它首先会读取刚才我们所说的配置目录中的配置文件,配置文件里面会声明所使用的是哪一个插件,然后去执行具体的CNI插件的二进制文件,再由CNI插件进入Pod的网络空间去配置Pod的网络。在这个过程中,CNI插件会为Pod创建一个网络命名空间,并将其中一个veth接口连接到该命名空间中,另一个veth接口保留在主机的网络命名空间中,并连接到CNI插件创建的虚拟网桥上。
3.Pod网络:不同节点pod相互通信
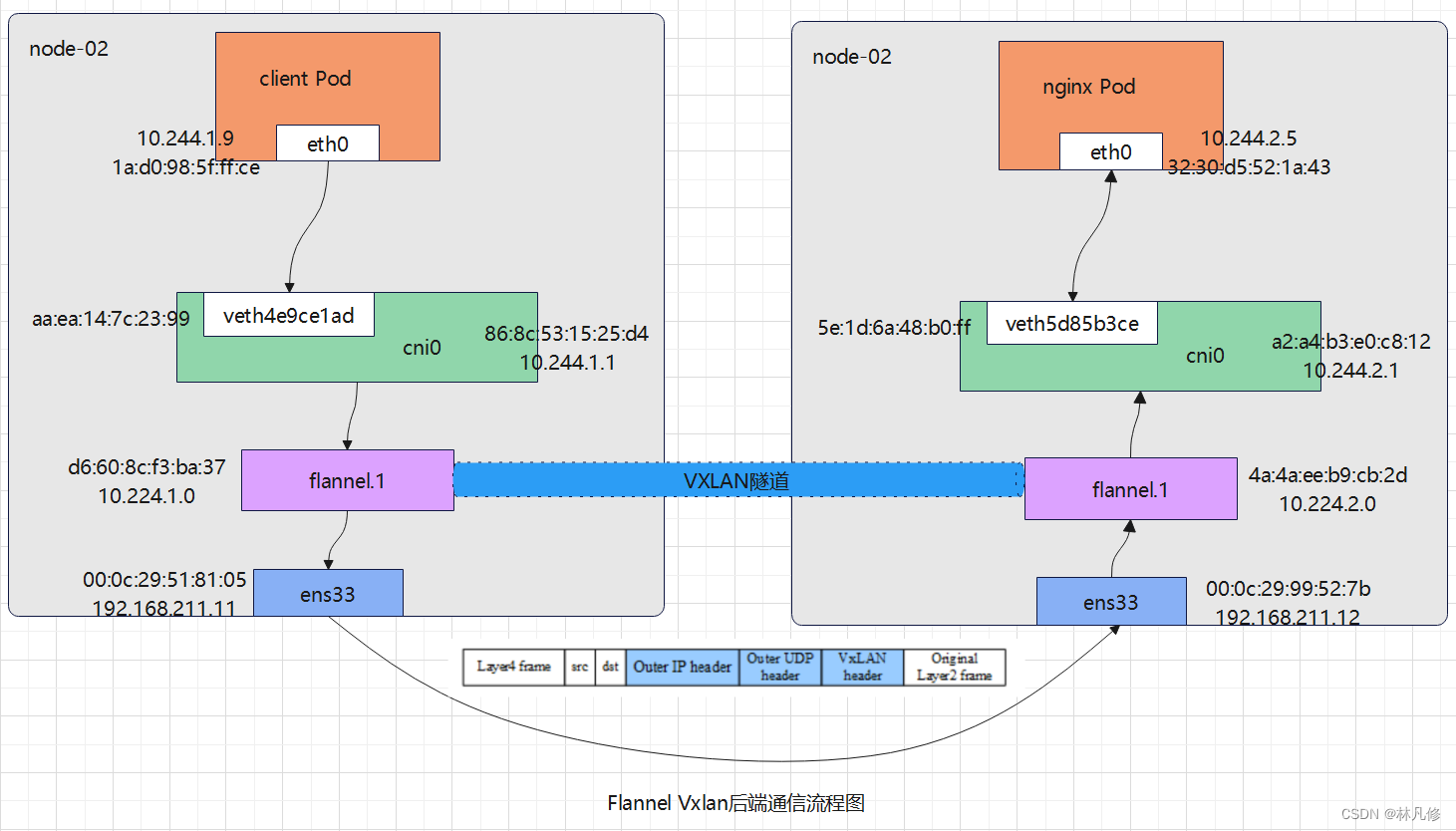
若不同节点pod想要相互通信,在cni0网桥外还有一层CNI插件配置的网络隧道,如上图新的虚拟网卡flannel0接收cni0网桥的数据,并通过维护路由表,对接收到的数据进行封包和转发(vxlan隧道)。
cni0:网桥设备,每创建一个pod都会创建一对 veth pair。其中一段是pod中的eth0,另一端是cni0网桥中的端口。
VTEP设备:、VXLAN Tunnel End Point(虚拟隧道端点),在Flannel中 VNI的默认值是1,这也是为什么宿主机的VTEP设备都叫flannel.1的原因。VTEP设备之间通过二层数据帧进行通信,源VTEP设备收到原始IP包后,在上面加上一个目的MAC地址,封装成一个内部数据帧,发送给目的VTEP设备。
flannel.1:vxlan网关设备,用户 vxlan 报文的解包和封包。不同的 pod 数据流量都从overlay设备以隧道的形式发送到对端。flannel.1不会发送arp请求去获取目标IP的mac地址,而是由Linuxkernel将一个"L3 Miss"事件请求发送到用户空间的flanneld程序,flanneld程序收到内核的请求事件后,从etcd中查找能够匹配该地址的子网flannel.1设备的mac地址,即目标pod所在host中flannel.1设备的mac地址。
flanneld:在每个主机中运行flanneld作为agent,它会为所在主机从集群的网络地址空间中,获取一个小的网段subnet,本主机内所有容器的IP地址都将从中分配。同时Flanneld监听K8s集群数据库,为flannel.1设备提供封装数据时必要的mac,ip等网络数据信息。
VXLAN:Virtual eXtensible Local Area Network,虚拟扩展局域网。采用L2 over L4(MAC-in-UDP)的报文封装模式,将二层报文用三层协议进行封装,实现二层网络在三层范围内进行扩展,同时满足数据中心大二层虚拟迁移和多租户的需求。flannel只使用了vxlan的部分功能,VNI被固定为1。
内部数据桢,并不能在宿主机的二层网络传输,Linux内核还需要把它进一步封装成为宿主机的一个普通的数据帧,承载着内部数据帧通过宿主机的eth0进行传输。
容器跨网络通信解决方案:如果集群的主机在同一个子网内,则跳过flannel.1隧道,而是直接通过路由eth0转发过去;若不在一个子网内,就通过隧道转发过去。
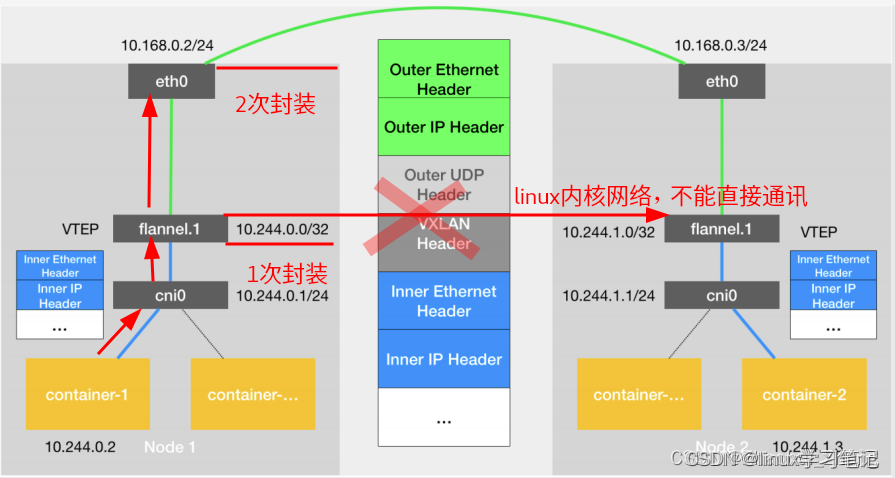
不同node上的pod通信流程:
- pod中的数据,根据pod的路由信息,发送到网桥 cni0
- cni0 根据节点路由表,将数据发送到隧道设备flannel.1
- flannel.1 查看数据包的目的ip,从flanneld获取对端隧道设备的必要信息,封装数据包 flannel.1,将数据包发送到对端设备。
- 数据包中包括
Outer IP 与 Inner IP等相关信息, 将PodIP和所在的NodeIP关联起来,通过这个关联让不同的Pod互相访问。 - 对端节点的网卡接收到数据包,发现数据包为overlay数据包,解开外层封装,并发送内层封装到flannel.1
- 设备 Flannel.1 设备查看数据包,根据路由表匹配,将数据发送给cni0设备
- cni0匹配路由表,发送数据到网桥
3.1 Flannel容器网络介绍
Flannel之所以可以搭建kubernets依赖的底层网络,是因为它可以实现以下两点:
- 给每个node上的docker容器分配相互不想冲突的IP地址;
- 能给这些IP地址之间建立一个覆盖网络,同过覆盖网络,将数据包原封不动的传递到目标容器内。
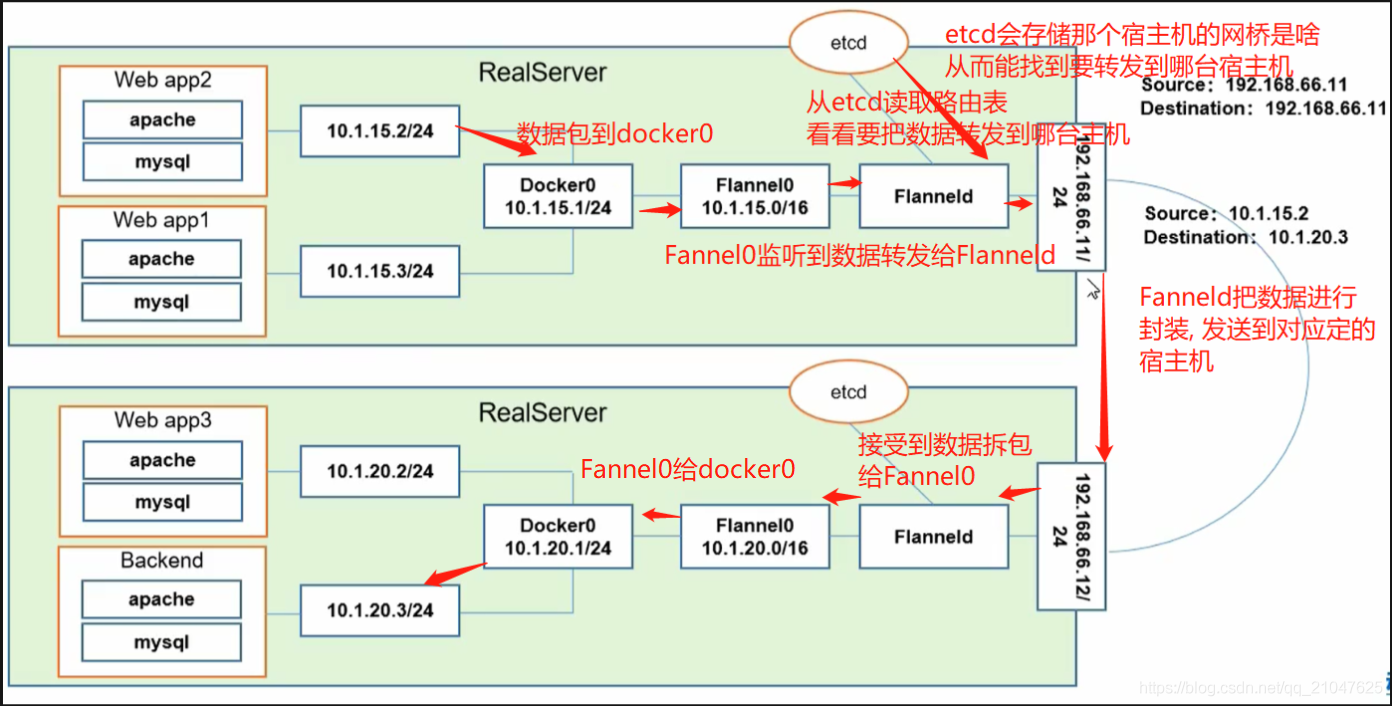
Flannel网络传输过程:
- 数据从源容器中发出后,经由所在主机的dockerO虚拟网卡转发到flannel0虚拟网卡这是个P2P的虚拟网卡,flanneld服务监听在网卡的另外—端(Flannel通过Etcd服务维护了—张节点间的路由表);
- 源主机的flanneld服务将原本的数据内容UDP封装后根据自己的路由表投递给目的节点的flanneld服务,数据到达以后被解包,然后直接进入目的节点的flannel0虚拟网卡,然后被转发到目的主机的dockerO虚拟网卡;
- ·最后就像本机容器通信一下的有docker路由到达目标容器,这样整个数据包的传递就完成了。

4. Service网络:ClusterIp
在Kubernetes中,Pod是非持久性的资源,可以按照需要创建和销毁。当使用Deployment来运行应用时,可以根据需要动态地创建或销毁Pod,实现水平扩缩容。
当引入Deployment,并为Pod设置多个副本时,那么某一个服务就会有多个pod及多个podIp,此时即使知道了这些Pod的IP,那访问起来也并不方便。此外,Pod的IP地址是动态分配的,可能发生变化,所以在实际通信中,直接使用Pod的IP地址进行通信会有一些问题。为了解决这个问题,Kubernetes引入了Service的概念。
所以,这里需要有一个统一入口,其它Pod通过这个统一入口去请求该服务(Nginx)对应的所有Pod。这时就有了Service这个资源对象,它主要作用就是用来提供统一入口,也就是说只需要一个IP就能访问所有的Pod,而这个入口IP就是ClusterIP,也就是Service的IP。
Pod IP 地址是实际存在于某个网卡(可以是虚拟设备)上的,但
Cluster IP是一个完全虚拟的IP,没有网络设备与其对应。
- Cluster IP仅仅作用于Kubernetes Service这个对象,并由Kubernetes管理和分配P地址
- Cluster IP无法被ping,他没有一个“实体网络对象”来响应
- Cluster IP只能结合Service Port组成一个具体的通信端口,单独的Cluster IP不具备通信的基础,并且他们属于Kubernetes集群这样一个封闭的空间。
- 虚拟 ip 是固定的,这也是service可以解决pod动态ip的原因
Service是一种持久性资源,它可以提供一个或多个端点(Endpoint),并通过标签选择器选择指向集群中的一组Pod。Service使用ClusterIP来提供内部集群的网络连接,ClusterIP是固定的虚拟ip,这样就可以通过Service来访问Pod,而不需要直接使用Pod的动态IP地址。当创建一个Deployment并运行应用时,通常会创建一个或多个Service来提供访问Pod的接口。这样,即使Pod的IP地址发生变化,通过Service的端点仍然可以访问到Pod,以确保集群内的可靠通信,并避免因Pod的动态变化而引起的问题。
K8s通过在引入一层Service抽象,还能解决以下问题:
-
服务发现:Service提供统一的ClusterIP来解决服务发现问题,Client只需通过ClusterIP就可以访问App的Pod集群,不需要关心集群中的具体Pod数量和PodIP,即使是PodIP发生变化也会被ClusterIP所屏蔽。注意,这里的ClusterIP实际是个虚拟IP,也称Virtual IP(VIP)。
-
负载均衡:Service抽象层具有负载均衡的能力,支持以不同策略去访问App集群中的不同Pod实例,以实现负载分摊和HA高可用。K8s中默认的负载均衡策略是RoundRobin,也可以定制其它复杂策略。
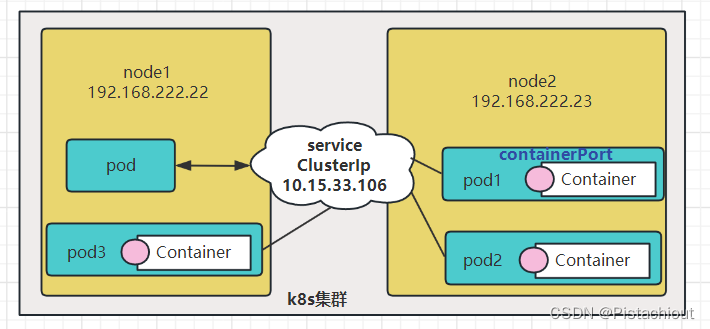
Service在上述K8s集群中被画成一个独立组件,实际是没有独立Service这样一个组件的,只是一个抽象概念。
4.1 服务发现
K8s通过一个ServiceName+ClusterIP统一屏蔽服务发现和负载均衡,底层技术是在DNS+Service Registry基础上发展演进出来。K8s的服务发现和负载均衡是在客户端通过Kube-Proxy + iptables转发实现,它对应用无侵入,且不穿透Proxy,没有额外性能损耗。K8s服务发现机制,可以认为是现代微服务发现机制和传统Linux内核机制的优雅结合。
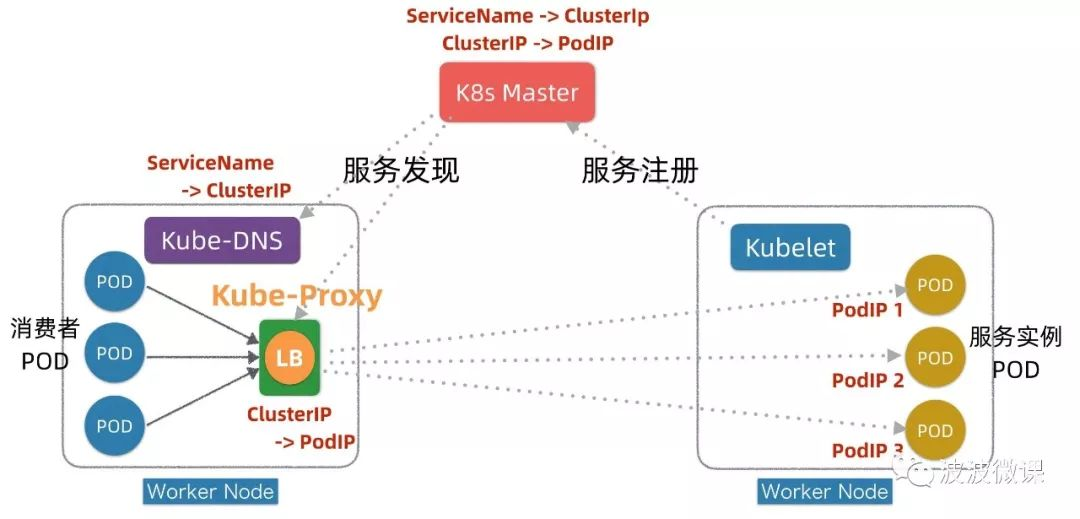

5. 外部访问集群网络
5.1 NodePort
K8s的Service网络ClusterIp只是一个集群内部网络,集群外部是无法直接访问的。如果我们要将K8s内部的一个服务通过NodePort方式暴露出去,使用Service的NodePort类型,将Service的ClusterIP对应的Port映射到每一个Node的IP上,映射出去的Port范围为30000~32767。
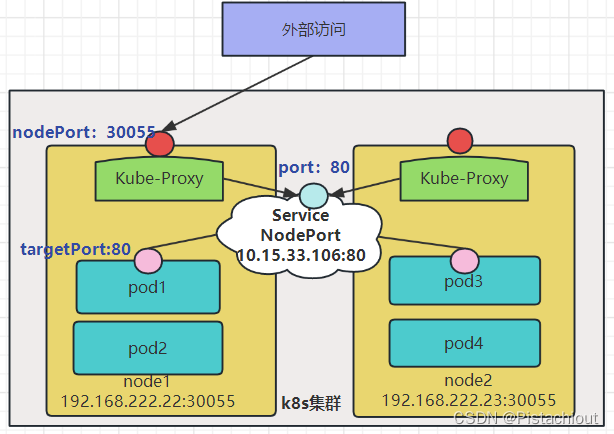
Service NodePort服务发布以后,K8s在每个Worker节点上都会开启nodePort这个端口。这个端口的背后是Kube-Proxy,当K8s外部有Client要访问K8s集群内的某个服务,它通过这个服务的NodePort端口发起调用,这个调用通过Kube-Proxy转发到内部的Servcie抽象层,然后再转发到目标Pod上。
5.1.1 containerPort、port、nodePort、targetPort的区别与联系
- containerPort:
Container容器暴露的端口。containerPort是在pod控制器中定义的、pod中的容器需要暴露的端口。 - port:
service暴露在集群中的端口,仅限集群内部访问。port是暴露在cluster (集群网络)上的端口,提供了集群内部客户端访问service的入口,即clusterIP:port。mysql容器暴露了3306端口(参考DockerFile),集群内其他容器通过33306端口访问mysql服务,但是外部流量不能访问mysql服务,因为mysql服务没有配置NodePort。 - nodePort:
集群节点Node暴露在外网中的端口。nodePort提供了集群外部客户端访问service的一种方式,即nodeIP:nodePort提供了外部网络访问k8s集群中service的入口。 - targetPort:
Pod暴露的端口。targetPort是pod上的端口,从port/nodePort下来的数据,经过kube-proxy流入到后端pod的targetPort上,最后进入容器,因此targetPort与容器的containerPort必须一致。
5.2 LoadBalancer云负载均衡器
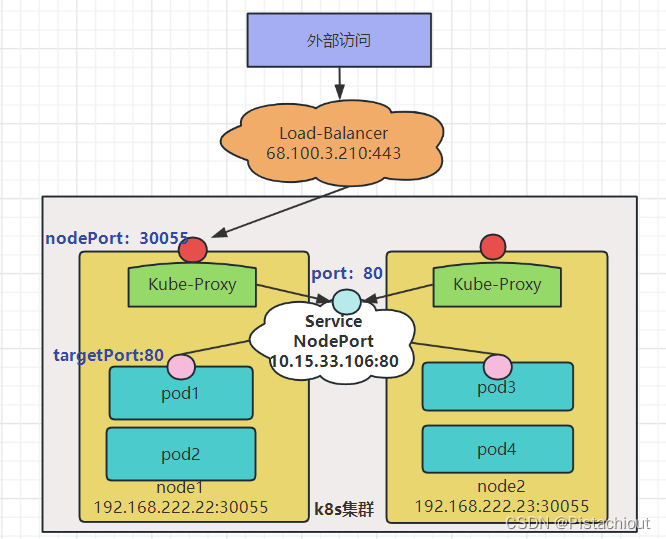
在NodePort的基础上增加了云服务商提供的负载均衡器Load-Balancer,使用该均衡器后进行访问时不需要再带着nodePort30055,可以将流量自动分配到集群的不同节点上。
5.3 Nginx Service反向代理、域名
Nodeport只支持四层的数据包转发,所以不支持基于域名的做分流,基于uri做匹配。因此我们考虑在Nodeport上添加一层Nginx Service进行反向代理。
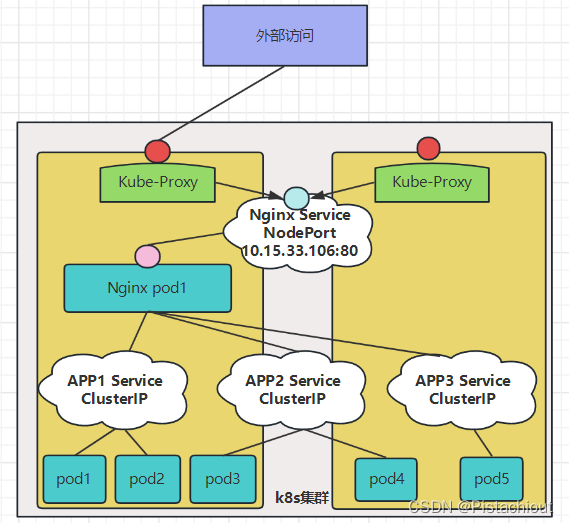
使用 Nginx 作为反向代理服务器是一种常见的做法,它可以为多个服务提供负载均衡和路由功能。在这种情况下,Nginx 通常被部署在一个单独的 Pod 中,并且该 Pod 会被 Service 暴露给外部网络。当外部请求到达 Nginx Service 时,它会被路由到 Nginx Pod。然后,Nginx Pod 根据配置将请求转发到相应的 APP Service。
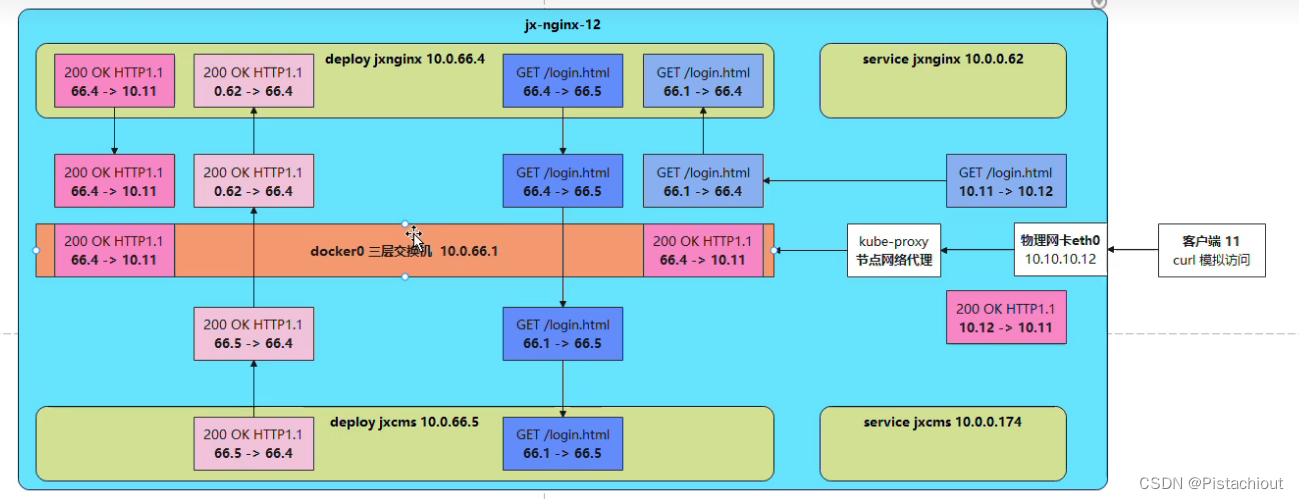
上图为抓包模拟客户端访问的情况,通过抓包我们可以发现在使用Nginx进行反向代理时访问pod中的服务需要进行大量包的传输,在实验时访问一个静态页面需要请求59个包,这带来了巨大的资源损失,因此引出了Ingress。
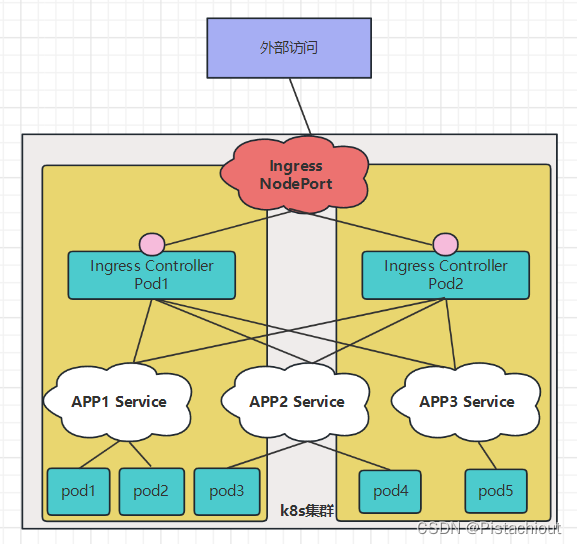
5.4 Ingress 代理服务
Ingress算是Service上面的一层代理,通常在 Service前使用Ingress来提供HTTP路由配置。它让我们可以设置外部 URL、基于域名的虚拟主机、SSL 和负载均衡。
ingress相当于一个7层的负载均衡器,是k8s对反向代理的一个抽象。大概的工作原理也确实类似于Nginx,可以理解成在 Ingress 里建立一个个映射规则 , ingress Controller 通过监听 Ingress这个api对象里的配置规则并转化成 Nginx 的配置(kubernetes声明式API和控制循环) , 然后对外部提供服务。ingress包括:ingress controller和ingress resources
- ingress controller:核心是一个deployment,实现方式有很多,比如nginx, Contour, Haproxy, trafik, Istio,需要编写的yaml有:Deployment, Service, ConfigMap, ServiceAccount(Auth),其中service的类型可以是NodePort或者LoadBalancer。
- ingress resources:这个就是一个类型为Ingress的k8s api对象了,这部分则是面向开发人员。
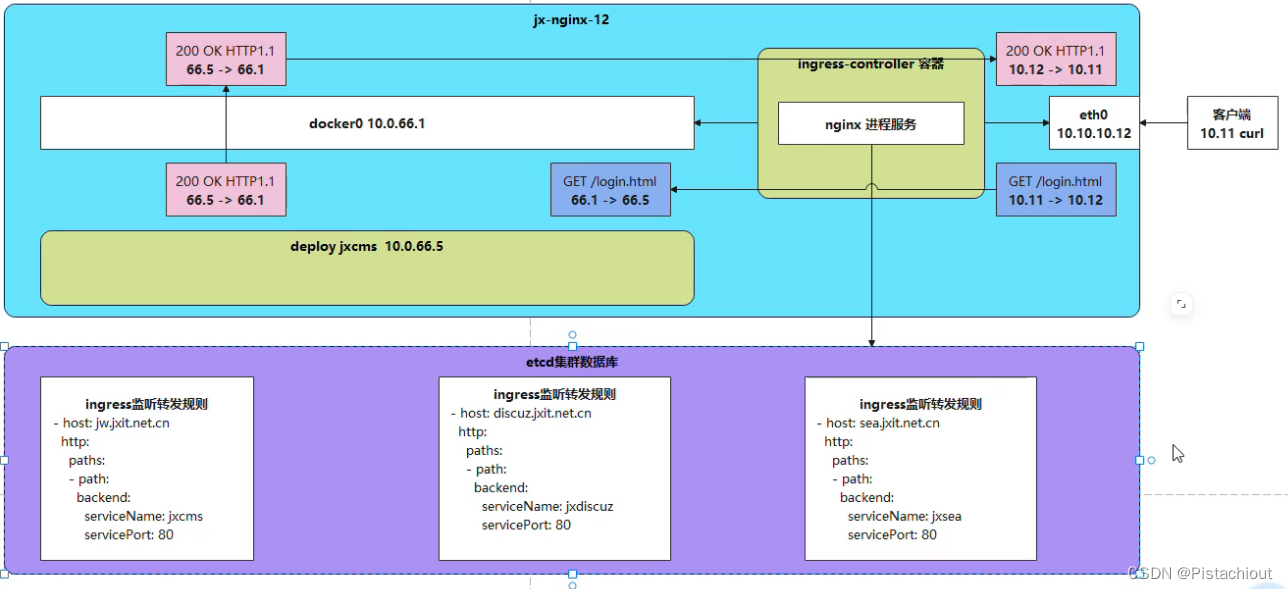
如上图所示,为使用Ingress之后的抓包流程,可以看到此时eth0与docker网桥并没有通过Kube-Proxy进行通信,而是直接通过Ingress Controller进行通信,再次抓包访问一个静态网页需要35个包。

