
- 1/lib64/libc.so.6: version `GLIBC_2.7' not found 解决方案
- 2ESXI系统引导盘
- 3python语言中with as的用法使用详解_with as函数
- 4Vue 中循环渲染多个相同 echarts 图表,并传入不同的数据_vue里如何给相同的echart图标传进去不同的数据显示在不同元素内
- 5进制概念和IP的换算方法简析_ip进制怎么算技巧
- 6独立开发变现周刊(第105期):开发一个年收入120万美元的拍照工具
- 7unity动画状态机_unity 动画状态机
- 8无法将类型为“Microsoft.Office.Interop.Excel.ApplicationClass”的COM 对象强制转换为接口类型“Microsoft.Office.Interop.Exc...
- 9帕鲁服务器怎么开,palworld,palserver,steamcmd,内存泄露解决_帕鲁 docker 存档
- 1010 查看及切换目录_man hier命令
GPT-1,GPT-2和GPT-3发展历程及核心思想,GTP-4展望_gpt-1,gpt-2,gpt-3,gpt-4区别
赞
踩
看了很多文章,还是这位大佬介绍的比较透彻,特此转载:
词向量之GPT-1,GPT-2和GPT-3 - 知乎 (zhihu.com)![]() https://zhuanlan.zhihu.com/p/350017443
https://zhuanlan.zhihu.com/p/350017443
目录
前言
Generative Pre-trained Transformer(GPT)系列是由OpenAI提出的非常强大的预训练语言模型,这一系列的模型可以在非常复杂的NLP任务中取得非常惊艳的效果,例如文章生成,代码生成,机器翻译,Q&A等,而完成这些任务并不需要有监督学习进行模型微调。而对于一个新的任务,GPT仅仅需要非常少的数据便可以理解这个任务的需求并达到接近或者超过state-of-the-art的方法。
当然,如此强大的功能并不是一个简单的模型能搞定的,GPT模型的训练需要超大的训练语料,超多的模型参数以及超强的计算资源。GPT系列的模型结构秉承了不断堆叠transformer的思想,通过不断的提升训练语料的规模和质量,提升网络的参数数量来完成GPT系列的迭代更新的。GPT也证明了,通过不断的提升模型容量和语料规模,模型的能力是可以不断提升的。
| 模型 | 发布时间 | 参数量 | 预训练数据量 |
| GPT | 2018 年 6 月 | 1.17 亿 | 约 5GB |
| GPT-2 | 2019 年 2 月 | 15 亿 | 40GB |
| GPT-3 | 2020 年 5 月 | 1,750 亿 | 45TB |
这篇文章会依次介绍GPT-1[1],GPT-2[2],GPT-3[3],并介绍它们基于上个版本的改进点,文章主要的介绍的包括四个主要方向:算法的思想和目标,使用的数据集和预处理方式,模型结构以及算法的性能。
1. GPT-1:无监督学习
在GPT-1之前(和ELMo同一年),传统的NLP模型往往使用大量的数据对有监督的模型进行任务相关的模型训练,但是这种有监督学习的任务存在两个缺点:
- 需要大量的标注数据,高质量的标注数据往往很难获得,因为在很多任务中,图像的标签并不是唯一的或者实例标签并不存在明确的边界;
- 根据一个任务训练的模型很难泛化到其它任务中,这个模型只能叫做“领域专家”而不是真正的理解了NLP。
这里介绍的GPT-1的思想是先通过在无标签的数据上学习一个通用的语言模型,然后再根据特定热任务进行微调,处理的有监督任务包括
- 自然语言推理(Natural Language Inference 或者 Textual Entailment):判断两个句子是包含关系(entailment),矛盾关系(contradiction),或者中立关系(neutral);
- 问答和常识推理(Question answering and commonsense reasoning):类似于多选题,输入一个文章,一个问题以及若干个候选答案,输出为每个答案的预测概率;
- 语义相似度(Semantic Similarity):判断两个句子是否语义上市是相关的;
- 分类(Classification):判断输入文本是指定的哪个类别。
将无监督学习左右有监督模型的预训练目标,因此叫做通用预训练(Generative Pre-training,GPT)。
1.1 GPT-1的训练
GPT-1的训练分为无监督的预训练和有监督的模型微调,下面进行详细介绍。
1.1.1 无监督预训练
GPT-1的无监督预训练是基于语言模型进行训练的,给定一个无标签的序列 ,语言模型的优化目标是最大化下面的似然值:
其中 是滑动窗口的大小, 是条件概率, 是模型的参数。这些参数使用SGD进行优化。
在GPT-1中,使用了12个transformer[5]块的结构作为解码器,每个transformer块是一个多头的自注意力机制,然后通过全连接得到输出的概率分布。
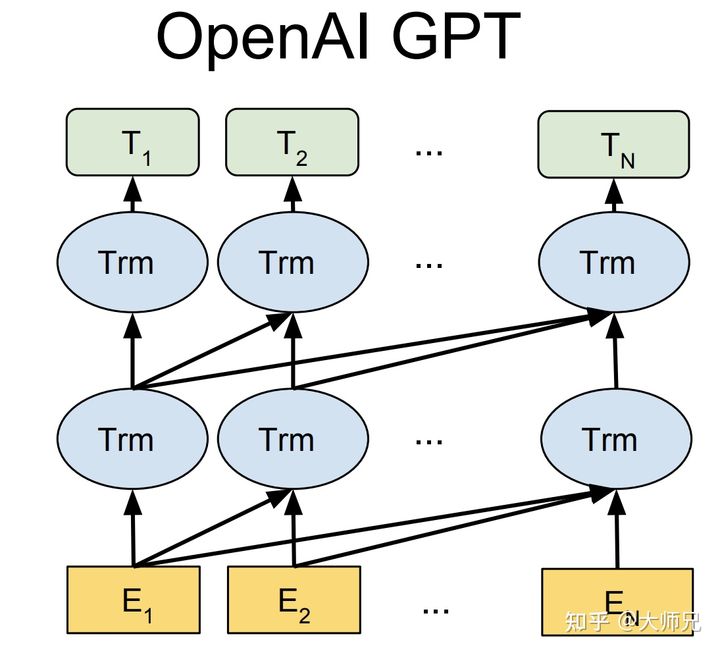
图1:GPT系列的基本框架
其中$U=(u_{-k},\dots,u_{-1})$是当前时间片的上下文token,$n$是层数,$W_e$是词嵌入矩阵,$W_p$是位置嵌入矩阵。
1.1.2 有监督微调
当得到无监督的预训练模型之后,我们将它的值直接应用到有监督任务中。对于一个有标签的数据集 ,每个实例有 个输入token: ,它对于的标签 组成。首先将这些token输入到训练好的预训练模型中,得到最终的特征向量 。然后再通过一个全连接层得到预测结果 :
其中 为全连接层的参数。有监督的目标则是最大化(5)式的值:
作者并没有直接使用 ,而是向其中加入了 ,并使用 进行两个任务权值的调整, 的值一般为 :
当进行有监督微调的时候,我们只训练输出层的 和分隔符(delimiter)的嵌入值。
1.1.3 任务相关的输入变换
在第1节的时候,我们介绍了GPT-1处理的4个不同的任务,这些任务有的只有一个输入,有的则有多组形式的输入。对于不同的输入,GPT-1有不同的处理方式,具体介绍如下:
- 分类任务:将起始和终止token加入到原始序列两端,输入transformer中得到特征向量,最后经过一个全连接得到预测的概率分布;
- 自然语言推理:将前提(premise)和假设(hypothesis)通过分隔符(Delimiter)隔开,两端加上起始和终止token。再依次通过transformer和全连接得到预测结果;
- 语义相似度:输入的两个句子,正向和反向各拼接一次,然后分别输入给transformer,得到的特征向量拼接后再送给全连接得到预测结果;
- 问答和常识推理:将 个选项的问题抽象化为 个二分类问题,即每个选项分别和内容进行拼接,然后各送入transformer和全连接中,最后选择置信度最高的作为预测结果。
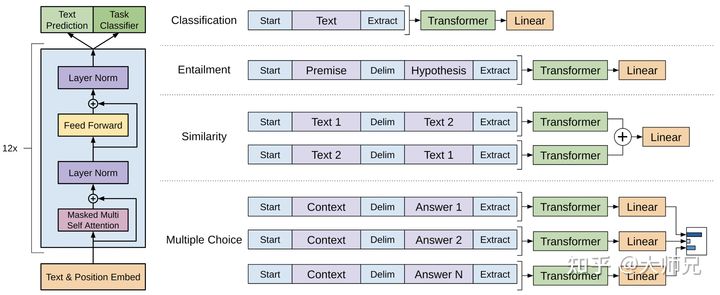
图2:(左):transformer的基本结构,(右):GPT-1应用到不同任务上输入数据的变换方式
1.2 GPT-1的数据集
GPT-1使用了BooksCorpus数据集[7],这个数据集包含 本没有发布的书籍。作者选这个数据集的原因有二:1. 数据集拥有更长的上下文依赖关系,使得模型能学得更长期的依赖关系;2. 这些书籍因为没有发布,所以很难在下游数据集上见到,更能验证模型的泛化能力。
1.3 网络结构的细节
GPT-1使用了12层的transformer,使用了掩码自注意力头,掩码的使用使模型看不见未来的信息,得到的模型泛化能力更强。
1.3.1 无监督训练
- 使用字节对编码(byte pair encoding,BPE),共有 个字节对;
- 词编码的长度为 ;
- 位置编码也需要学习;
- 层的transformer,每个transformer块有 个头;
- 位置编码的长度是 ;
- Attention, 残差,Dropout等机制用来进行正则化,drop比例为 ;
- 激活函数为GLEU;
- 训练的batchsize为 ,学习率为 ,序列长度为 ,序列epoch为 ;
- 模型参数数量为 亿。
1.3.2 有监督微调
- 无监督部分的模型也会用来微调;
- 训练的epoch为 ,学习率为 ,这表明模型在无监督部分学到了大量有用的特征。
1.4 GPT-1的性能
在有监督学习的12个任务中,GPT-1在9个任务上的表现超过了state-of-the-art的模型。在没有见过数据的zero-shot任务中,GPT-1的模型要比基于LSTM的模型稳定,且随着训练次数的增加,GPT-1的性能也逐渐提升,表明GPT-1有非常强的泛化能力,能够用到和有监督任务无关的其它NLP任务中。GPT-1证明了transformer对学习词向量的强大能力,在GPT-1得到的词向量基础上进行下游任务的学习,能够让下游任务取得更好的泛化能力。对于下游任务的训练,GPT-1往往只需要简单的微调便能取得非常好的效果。
GPT-1在未经微调的任务上虽然也有一定效果,但是其泛化能力远远低于经过微调的有监督任务,说明了GPT-1只是一个简单的领域专家,而非通用的语言学家。
2. GPT-2:多任务学习
GPT-2的目标旨在训练一个泛化能力更强的词向量模型,它并没有对GPT-1的网络进行过多的结构的创新与设计,只是使用了更多的网络参数和更大的数据集。下面我们对GPT-2展开详细的介绍。
2.1 GPT-2的核心思想
GPT-2的学习目标是使用无监督的预训练模型做有监督的任务。因为文本数据的时序性,一个输出序列可以表示为一系列条件概率的乘积:
上式也可以表示为 ,它的实际意义是根据已知的上文 预测未知的下文 ,因此语言模型可以表示为 。对于一个有监督的任务,它可以建模为 的形式。在decaNLP[8]中,他们提出的MQAN模型可以将机器翻译,自然语言推理,语义分析,关系提取等10类任务统一建模为一个分类任务,而无需再为每一个子任务单独设计一个模型。
基于上面的思想,作者认为,当一个语言模型的容量足够大时,它就足以覆盖所有的有监督任务,也就是说所有的有监督学习都是无监督语言模型的一个子集。例如当模型训练完“Micheal Jordan is the best basketball player in the history”语料的语言模型之后,便也学会了(question:“who is the best basketball player in the history ?”,answer:“Micheal Jordan”)的Q&A任务。
综上,GPT-2的核心思想概括为:任何有监督任务都是语言模型的一个子集,当模型的容量非常大且数据量足够丰富时,仅仅靠训练语言模型的学习便可以完成其他有监督学习的任务。
2.2 GPT-2的数据集
GPT-2的文章取自于Reddit上高赞的文章,命名为WebText。数据集共有约800万篇文章,累计体积约40G。为了避免和测试集的冲突,WebText移除了涉及Wikipedia的文章。
2.3 模型参数
- 同样使用了使用字节对编码构建字典,字典的大小为 ;
- 滑动窗口的大小为 ;
- batchsize的大小为 ;
- Layer Normalization移动到了每一块的输入部分,在每个self-attention之后额外添加了一个Layer Normalization;
- 将残差层的初始化值用 进行缩放,其中 是残差层的个数。
GPT-2训练了4组不同的层数和词向量的长度的模型,具体值见表2。通过这4个模型的实验结果我们可以看出随着模型的增大,模型的效果是不断提升的。
| 参数量 | 层数 | 词向量长度 |
| 117M(GPT-1) | 12 | 768 |
| 345M | 24 | 1024 |
| 762M | 36 | 1280 |
| 1542M | 48 | 1600 |
2.4 GPT-2的性能
- 在8个语言模型任务中,仅仅通过zero-shot学习,GPT-2就有7个超过了state-of-the-art的方法;
- 在“Children's Book Test”数据集上的命名实体识别任务中,GPT-2超过了state-of-the-art的方法约7%;
- “LAMBADA”是测试模型捕捉长期依赖的能力的数据集,GPT-2将困惑度从99.8降到了8.6;
- 在阅读理解数据中,GPT-2超过了4个baseline模型中的三个;
- 在法译英任务中,GPT-2在zero-shot学习的基础上,超过了大多数的无监督方法,但是比有监督的state-of-the-art模型要差;
- GPT-2在文本总结的表现不理想,但是它的效果也和有监督的模型非常接近。
2.4 总结
GPT-2的最大贡献是验证了通过海量数据和大量参数训练出来的词向量模型有迁移到其它类别任务中而不需要额外的训练。但是很多实验也表明,GPT-2的无监督学习的能力还有很大的提升空间,甚至在有些任务上的表现不比随机的好。尽管在有些zero-shot的任务上的表现不错,但是我们仍不清楚GPT-2的这种策略究竟能做成什么样子。GPT-2表明随着模型容量和数据量的增大,其潜能还有进一步开发的空间,基于这个思想,诞生了我们下面要介绍的GPT-3。
3. GPT-3:海量参数
截止编写此文前,GPT-3是目前最强大的语言模型,仅仅需要zero-shot或者few-shot,GPT-3就可以在下游任务表现的非常好。除了几个常见的NLP任务,GPT-3还在很多非常困难的任务上也有惊艳的表现,例如撰写人类难以判别的文章,甚至编写SQL查询语句,React或者JavaScript代码等。而这些强大能力的能力则依赖于GPT-3疯狂的 亿的参数量, TB的训练数据以及高达 万美元的训练费用。
3.1 In-context learning
In-context learning是这篇论文中介绍的一个重要概念,要理解in-context learning,我们需要先理解meta-learning(元学习)[9, 10]。对于一个少样本的任务来说,模型的初始化值非常重要,从一个好的初始化值作为起点,模型能够尽快收敛,使得到的结果非常快的逼近全局最优解。元学习的核心思想在于通过少量的数据寻找一个合适的初始化范围,使得模型能够在有限的数据集上快速拟合,并获得不错的效果。
这里的介绍使用的是MAML(Model-Agnostic Meta-Learning)算法[10],正常的监督学习是将一个批次的数据打包成一个batch进行学习。但是元学习是将一个个任务打包成batch,每个batch分为支持集(support set)和质询集(query set),类似于学习任务中的训练集和测试集。

图3:meta-learning的伪代码
对一个网络模型 ,其参数表示为 ,它的初始化值被叫做meta-initialization。MAML的目标则是学习一组meta-initialization,能够快速应用到其它任务中。MAML的迭代涉及两次参数更新,分别是内循环(inner loop)和外循环(outer loop)。内循环是根据任务标签快速的对具体的任务进行学习和适应,而外学习则是对meta-initialization进行更新。直观的理解,我用一组meta-initialization去学习多个任务,如果每个任务都学得比较好,则说明这组meta-initialization是一个不错的初始化值,否则我们就去对这组值进行更新,如图4所示。目前的实验结果表明元学习距离学习一个通用的词向量模型还是有很多工作要做的。
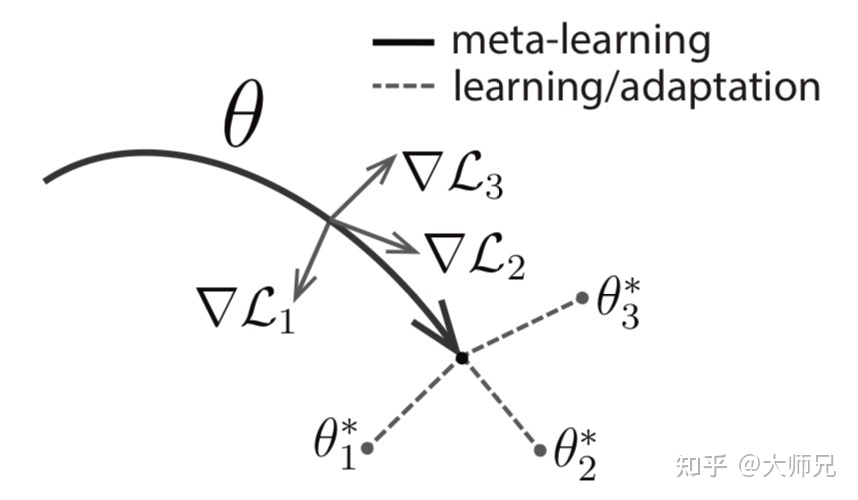
图4:meta-learning的可视化结果
而GPT-3中据介绍的in-context learning(情境学习)则是元学习的内循环,而基于语言模型的SGT则是外循环,如图5所示。
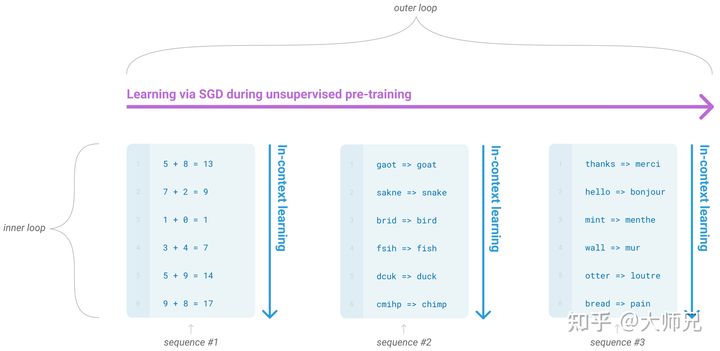
图5:GPT-3中的内循环和外循环
而另外一个方向则是提供容量足够大的transformer模型来对语言模型进行建模。而近年来使用大规模的网络来训练语言模型也成为了非常行之有效的策略(图6),这也促使GPT-3一口气将模型参数提高到 亿个。
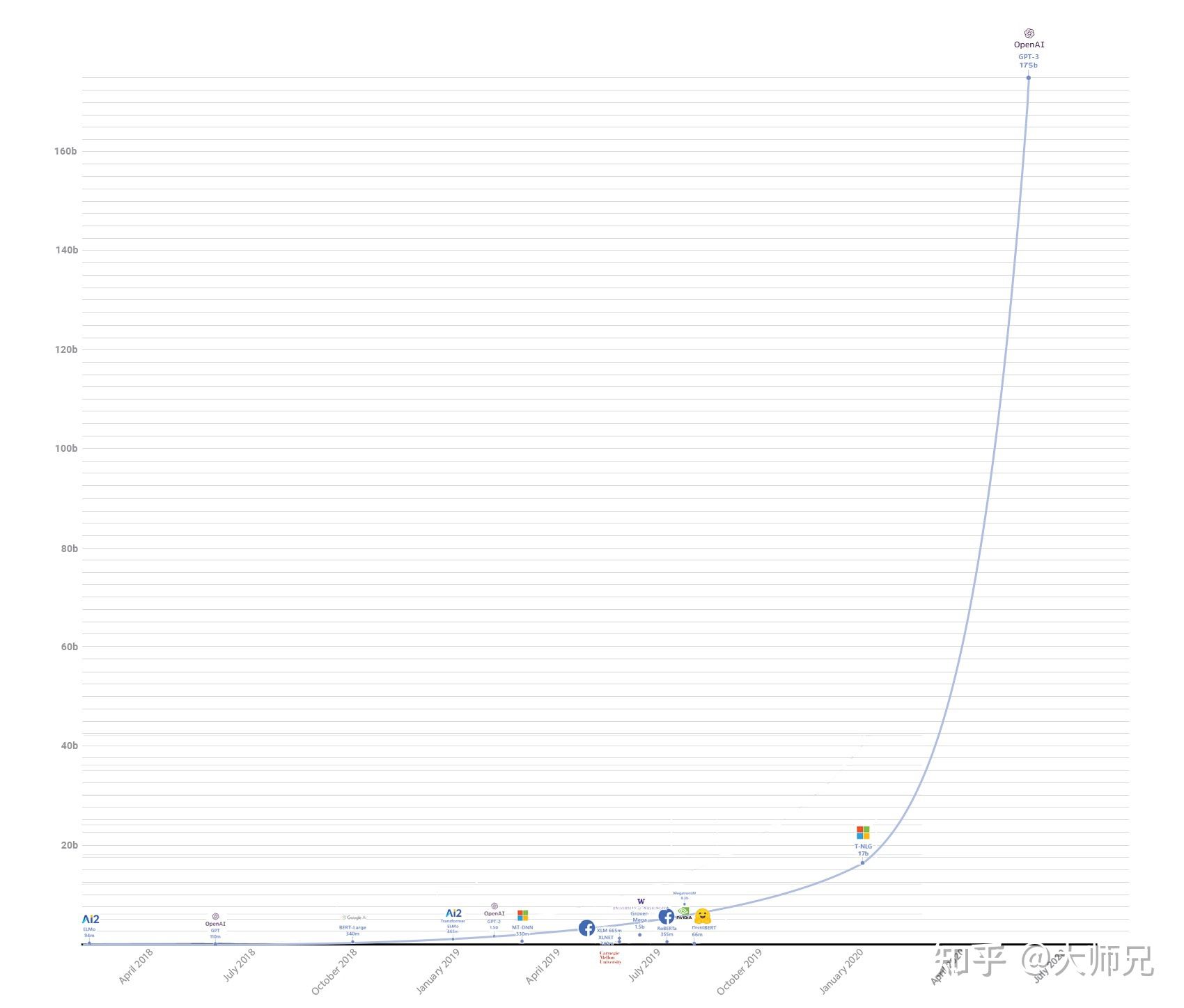
图6:历代state-of-the-art词向量模型的参数量
3.2 Few-shot,one-shot,zero-shot learning
在few-shot learning中,提供若干个( - 个)示例和任务描述供模型学习。one-shot laerning是提供1个示例和任务描述。zero-shot则是不提供示例,只是在测试时提供任务相关的具体描述。作者对这3种学习方式分别进行了实验,实验结果表明,三个学习方式的效果都会随着模型容量的上升而上升,且few shot > one shot > zero show。
从理论上讲GPT-3也是支持fine-tuning的,但是fine-tuning需要利用海量的标注数据进行训练才能获得比较好的效果,但是这样也会造成对其它未训练过的任务上表现差,所以GPT-3并没有尝试fine-tuning。

图7:随着参数量的提升,三种学习方式的模型的效果均有了不同程度的提升
3.3 数据集
GPT-3共训练了5个不同的语料,分别是低质量的Common Crawl,高质量的WebText2,Books1,Books2和Wikipedia,GPT-3根据数据集的不同的质量赋予了不同的权值,权值越高的在训练的时候越容易抽样到,如表1所示。
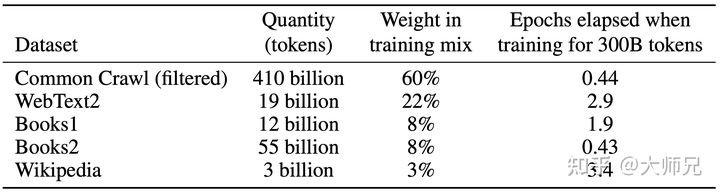
3.4 模型
GPT-3沿用了GPT-2的结构,但是在网络容量上做了很大的提升,具体如下:
- GPT-3采用了 层的多头transformer,头的个数为 ;
- 词向量的长度是 ;
- 上下文划窗的窗口大小提升至 个token;
- 使用了alternating dense和locally banded sparse attention[11]。
3.5 GPT-3的性能
仅仅用惊艳很难描述GPT-3的优秀表现。首先,在大量的语言模型数据集中,GPT-3超过了绝大多数的zero-shot或者few-shot的state-of-the-art方法。另外GPT-3在很多复杂的NLP任务中也超过了fine-tune之后的state-of-the-art方法,例如闭卷问答,模式解析,机器翻译等。除了这些传统的NLP任务,GPT-3在一些其他的领域也取得了非常震惊的效果,例如进行数学加法,文章生成,编写代码等。
4. GTP-4----100万亿参数
WSE-2芯片和GPT-4模型
两周前,《Wired》杂志发表了一篇文章里面包含了两条重要消息。
首先,Cerebras再次制造了市场上最大的芯片,Wafer Scale Engine Two (WSE-2)。它大约22厘米,有2.6万亿晶体管。相比之下,特斯拉全新的训练芯片只有有1.25万亿晶体管。
Cerebras找到了一种有效压缩计算能力的方法,因此WSE-2有85万个核心(计算单元),而典型的gpu只有几百个。他们还用一种新颖的冷却系统解决了散热问题,并创建了高效的IO流。
像WSE-2这样的超级专业、超级昂贵、超级强大的芯片用途并不多。训练大型神经网络就是其中之一。所以Cerebras和OpenAI进行了对话。
这是第二条新闻:Cerebras首席执行官Andrew Feldman对《Wired》杂志表示:“从与OpenAI的对话来看,GPT-4将会有大约100万亿个参数。(……)但是发布的话可能还需要几年的时间。。。”
从GPT-3开始,人们就对OpenAI及其下一个版本充满了期待。现在我们知道它会在几年内问世,而且会非常大。它的尺寸将超过GPT-3的500倍。你没看错:500倍。
我们可以从 GPT-4 中期待什么?
100 万亿个参数很多。要了解这个数字有多大,让我们将它与我们的大脑进行比较。一般人类的大脑有大约 80-1000 亿个神经元和大约 100 万亿个突触。

GPT-4 将拥有与大脑具有突触一样多的参数。
将人工神经网络与大脑进行比较是一件棘手的事情。这种比较看似是公平的,但这只是因为我们假设人工神经元至少松散地基于生物神经元。最近发表在 Neuron 上的一项研究表明情况并非如此。他们发现至少需要一个 5 层神经网络才能够模拟单个生物神经元的行为。也就是说需要大约1000 个人工神经元才能够模拟一个生物神经元。
这么看来GPT-4还是没有达到我们大脑的水平,但是即使 GPT-4 没有我们的大脑那么强大,它也肯定会给我们带来惊喜。与 GPT-3 不同它可能不仅仅是一个语言模型。 OpenAI 的首席科学家 Ilya Sutskever 在 2020 年 12 月撰写有关多模态的文章时暗示了这一点:
“到 2021 年,语言模型将开始了解视觉世界。仅文字就可以表达关于世界的大量信息,但它是不完整的因为我们也生活在视觉世界中。”
我们已经在 DALL·E 中看到了其中的一些,它是 GPT-3 的较小版本(120 亿个参数),专门针对文本-图像对进行训练。 OpenAI 当时表示,“通过语言描述视觉概念现在已经触手可及。”
OpenAI 一直在不停地利用 GPT-3 的隐藏能力。 DALL·E 仅仅是 GPT-3 的一个特例,很像 Codex。但它们并不是绝对的改进更像是特殊情况。 而GPT-4 能够提供更多的功能。例如 DALL·E(文本图像)和 Codex(编码)等专业系统的深度与 GPT-3(通用语言)等通用系统的宽度相结合。
那么其他类似人类的特征呢,比如推理或常识?在这方面,Sam Altman说他们也无法确定,但他仍然“乐观”。
目前看来,问题还是很多但答案却很少。没有人知道 AGI 是否真的称为可能,也没有人知道如何建造它。没有人知道更大的神经网络是否会越来越接近它。但不可否认的是虽然可能还要等几年,但GPT-4 将是值得关注的东西,让我们拭目以待。
5. 总结
GPT系列从1到3,通通采用的是transformer架构,可以说模型结构并没有创新性的设计。在微软的资金支持下,这更像是一场赤裸裸的炫富:1750亿的参数,31个分工明确的作者,超强算力的计算机( 个CPU, 个GPU),1200万的训练费用,45TB的训练数据(维基百科的全部数据只相当于其中的 )。这种规模的模型是一般中小企业无法承受的,而个人花费巨金配置的单卡机器也就只能做做微调或者打打游戏了。甚至在训练GPT-3时出现了一个bug,OpenAI自己也没有资金重新训练了。
读懂了GPT-3的原理,相信我们就能客观的看待媒体上对GPT-3的过分神话了。GPT-3的本质还是通过海量的参数学习海量的数据,然后依赖transformer强大的拟合能力使得模型能够收敛。基于这个原因,GPT-3学到的模型分布也很难摆脱这个数据集的分布情况。得益于庞大的数据集,GPT-3可以完成一些令人感到惊喜的任务,但是GPT-3也不是万能的,对于一些明显不在这个分布或者和这个分布有冲突的任务来说,GPT-3还是无能为力的。例如通过目前的测试来看,GPT-3还有很多缺点的:
- 对于一些命题没有意义的问题,GPT-3不会判断命题有效与否,而是拟合一个没有意义的答案出来;
- 由于40TB海量数据的存在,很难保证GPT-3生成的文章不包含一些非常敏感的内容,例如种族歧视,性别歧视,宗教偏见等;
- 受限于transformer的建模能力,GPT-3并不能保证生成的一篇长文章或者一本书籍的连贯性,存在下文不停重复上文的问题。
OpenAI的CEO也发Twitter说“The GPT-3 hype is way too much. It's impressive (thanks for the nice compliments!) but it still has serious weaknesses and sometimes makes very silly mistakes. AI is going to change the world, but GPT-3 is just a very early gimpse. We have a lot still to figure out.”
GPT-3对AI领域的影响无疑是深远的,如此强大性能的语言模型的提出,为下游各种类型的NLP任务提供了非常优秀的词向量模型,在此基础上必将落地更多有趣的AI应用。近年来,硬件的性能在飞速发展,而算法的研究似乎遇见了瓶颈,GPT-3给冷清的AI领域注入了一剂强心剂,告诉各大硬件厂商它们的工作还要加油,只要算力足够强,AI的性能还有不断提升的上界。
同时GPT-3如此高昂的计算代价也引发了一些关于AI领域垄断的一些担心,对于如此高的算力要求,中小企业是否有能力负担的起,或者对于这些企业来说,是否有必要花这么多钱就训练一个词向量模型。长此以往,恐怕会形成AI巨头对算力要求高的算法的技术垄断。
神经网络之父、图灵奖获得者杰弗里·辛顿(Geoffrey Hinton)表示,“ 鉴于 GPT-3 在未来的惊人前景,可以得出结论:生命、宇宙和万物的答案,就只是 4.398 万亿个参数而已。” 这一观点也引发了人们的广泛讨论,被认为是对 NLP 发展尽头的预言。当未来人类的算力不断突破极限时,包含全人类文明的 GPT-N 是否会是 NLP 的终点呢?
Reference
[1] Radford, A., Narasimhan, K., Salimans, T. and Sutskever, I., 2018. Improving language understanding by generative pre-training.
[2] Radford, A., Wu, J., Child, R., Luan, D., Amodei, D. and Sutskever, I., 2019. Language models are unsupervised multitask learners. OpenAI blog, 1(8), p.9.
[3] Brown, Tom B., Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan et al. “Language models are few-shot learners.” arXiv preprint arXiv:2005.14165 (2020).
[4] Rei, M., 2017. Semi-supervised multitask learning for sequence labeling. arXiv preprint arXiv:1704.07156.
[5] Waswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, L. and Polosukhin, I., 2017. Attention is all you need. In NIPS.
[6] https://medium.com/walmartglobaltech/the-journey-of-open-ai-gpt-models-32d95b7b7fb2
[7] Zhu, Yukun, et al. "Aligning books and movies: Towards story-like visual explanations by watching movies and reading books." Proceedings of the IEEE international conference on computer vision. 2015.
[8] McCann, Bryan, et al. "The natural language decathlon: Multitask learning as question answering." arXiv preprint arXiv:1806.08730 (2018).
[9] Rajeswaran, Aravind, et al. "Meta-learning with implicit gradients." arXiv preprint arXiv:1909.04630 (2019).
[10] Finn, Chelsea, Pieter Abbeel, and Sergey Levine. "Model-agnostic meta-learning for fast adaptation of deep networks." International Conference on Machine Learning. PMLR, 2017.
[11] Child, Rewon, et al. "Generating long sequences with sparse transformers." arXiv preprint arXiv:1904.10509 (2019).

