
- 1我的测试成长心得_测试的成长思路怎么写
- 2压缩感知常用测试集 SET5, SET11, SET14下载_set5数据集下载
- 3Qt 制作安装程序(使用 binarycreator.exe)
- 4视觉SLAM理论与实践第四节课习题_在优化中经常会遇到矩阵微分的问题。例如,当自变量为向量 x,求标量函数 u(x) 对 x
- 5vscode官方网站下载,显示网络错误。_vscode下载一直显示网络问题
- 6python 淘宝联盟_Python 淘宝联盟-佣金设置 批量设置佣金和服务费
- 7用python制作简单的小游戏,用python设计一个小游戏_python编写简单小游戏
- 8关于 java.lang.NullPointerException: null 的一种情况及处理_cause: java.lang.nullpointerexception] with root c
- 9dicom坐标系以及确定两平面交点_dicom location imageposition
- 10阿里云服务器租用价格表最新发布,持续更新
在MySQL对于批量更新操作的一种优化方式_c#使用mysql更新3w条记录优化
赞
踩
引言
批量更新数据,不同于这种 update a=a+1 where pk > 500,而是需要对每一行进行单独更新 update a=1 where pk=1;update a=12 where pk=7;… 这样连续多行update语句的场景,是少见的。
可以说是偶然也是一种必然,在GreatDB 5.0的开发过程中,我们需要对多语句批量update的场景进行优化。
两种多行更新操作的耗时对比
在我们对表做多行更新的时候通常会遇到以下两种情况
1.单语句批量更新(update a=a+1 where pk > 500)
2.多语句批量更新(update a=1 where pk=1;update a=12 where pk=7;…)
下面我们进行实际操作比较两种场景,在更新相同行数时所消耗的时间。
数据准备
数据库版本:MySQL 8.0.23
t1表,建表语句以及准备初始数据1000行
create database if not exists test; use test ##建表 create table t1(c1 int primary key,c2 int); ##创建存储过程用于生成初始数据 DROP PROCEDURE IF EXISTS insdata; DELIMITER $$ CREATE PROCEDURE insdata(IN beg INT, IN end INT) BEGIN WHILE beg <= end DO INSERT INTO test.t1 values (beg, end); SET beg = beg+1; END WHILE; END $$ DELIMITER ; ##插入初始数据1000行 call insdata(1,1000);

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
1.单语句批量更新
更新语句
update t1 set c2=10 where c1 <=1000;
- 1
执行结果
mysql> update t1 set c2=10 where c1 <=1000;
Query OK, 1000 rows affected (0.02 sec)
Rows matched: 1000 Changed: 1000 Warnings: 0
- 1
- 2
- 3
2.多语句批量更新
以下脚本用于生成1000行update语句,更新c2的值等于1000以内的随机数
#!/bin/bash
for i in {1..1000}
do
echo "update t1 set c2=$((RANDOM%1000+1)) where c1=$i;" >> update.sql
done
- 1
- 2
- 3
- 4
- 5
- 6
生成sql语句如下
update t1 set c2=292 where c1=1;
update t1 set c2=475 where c1=2;
update t1 set c2=470 where c1=3;
update t1 set c2=68 where c1=4;
update t1 set c2=819 where c1=5;
... ....
update t1 set c2=970 where c1=1000;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
因为source /ssd/tmp/tmp/1000/update.sql;执行结果如下,执行时间不易统计:
Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0 Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0 Query OK, 1 row affected (0.01 sec) Rows matched: 1 Changed: 1 Warnings: 0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
所以利用Linux时间戳进行统计:
#!/bin/bash
start_time=`date +%s%3N`
/ssd/tmp/mysql/bin/mysql -h127.0.0.1 -uroot -P3316 -pabc123 -e "use test;source /ssd/tmp/tmp/1000/update.sql;"
end_time=`date +%s%3N`
echo "执行时间为:"$(($end_time-$start_time))"ms"
- 1
- 2
- 3
- 4
- 5
- 6
执行结果:
[root@computer-42 test]# bash update.sh
mysql: [Warning] Using a password on the command line interface can be insecure.
执行时间为:4246ms
- 1
- 2
- 3
执行所用时间为:4246ms=4.246 sec
结果比较
| 单语句批量更新 | 多语句批量更新 |
|---|---|
| 0.02sec | 4.246sec |
总结
由上述例子我们可以看到,同样是更新1000行数据。单语句批量更新与多语句批量更新的执行效率差距很大。
而产生这种巨大差异的原因,除了1000行sql语句本身的网络与语句解析开销外,影响性能的地方主要是以下几个方面:
1.如果会话是auto_commit=1,每次执行update语句后都要执行commit操作。commit操作耗费时间较久,会产生两次磁盘同步(写binlog和写redo日志)。在进行比对测试时,尽量将多个语句放到一个事务内,保证只提交一次事务。
2.向后端发送多语句时,后端每处理一个语句均会向client返回一个response包,进行一次交互。如果多语句使用一个事务的话,网络io交互应该是影响性能的主要方面。之前在性能测试时发现网卡驱动占用cpu很高。
我们的目标是希望在更新1000行时,第二种场景的耗时能够减少到一秒以内。
对第二种场景的优化
接下来我们来探索对更新表中多行为不同值时,如何提高它的执行效率。
简单分析
从执行的update语句本身来说,两种场景所用的表结构都进行了最大程度的简化,update语句也十分简单,且where条件为主键,理论上已经没有优化的空间。
如果从其他方面来考虑,根据上述原因分析会有这样三个优化思路:
1、减少执行语句的解析时间来提高执行效率
2、减少commit操作对性能的影响,尽量将多个语句放到一个事务内,保证只提交一次事务。
3、将多条语句合并成一条来提高执行效率
方案一:使用prepare语句,减小解析时间
以下脚本用于生成prepare执行语句
#!/bin/bash
echo "prepare pr1 from 'update test.t1 set c2=? where c1=?';" > prepare.sql
for i in {1..1000}
do
echo "set @a=$((RANDOM%1000+1)),@b=$i;" >>prepare.sql
echo "execute pr1 using @a,@b;" >> prepare.sql
done
echo "deallocate prepare pr1;" >> prepare.sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
生成语句如下
prepare pr1 from 'update test.t1 set c2=? where c1=?';
set @a=276,@b=1;
execute pr1 using @a,@b;
set @a=341,@b=2;
execute pr1 using @a,@b;
set @a=803,@b=3;
execute pr1 using @a,@b;
... ...
set @a=582,@b=1000;
execute pr1 using @a,@b;
deallocate prepare pr1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
执行语句
#!/bin/bash
start_time=`date +%s%3N`
/ssd/tmp/mysql/bin/mysql -h127.0.0.1 -uroot -P3316 -pabc123 -e "use test;source /ssd/tmp/tmp/test/prepare.sql;"
end_time=`date +%s%3N`
echo "执行时间为:"$(($end_time-$start_time))"ms"
- 1
- 2
- 3
- 4
- 5
- 6
执行结果:
[root@computer-42 test]# bash prepare_update_id.sh
mysql: [Warning] Using a password on the command line interface can be insecure.
执行时间为:4518ms
- 1
- 2
- 3
与优化前相比
| 优化前 | 优化后 | 提升效率 |
|---|---|---|
| 4.246 sec | 4.518 sec | 无提升 |
很遗憾,执行总耗时反而增加了。
这里笔者有一点推测是由于原本一条update语句,被拆分成了两条语句:
set @a=276,@b=1;
execute pr1 using @a,@b;
- 1
- 2
这样在MySQL客户端和MySQL进程之间的通讯次数增加了,所以增加了总耗时。
因为prepare预处理语句执行时只能使用用户变量传递,以下执行语句会报错
mysql> execute pr1 using 210,5;
ERROR 1064 (42000): You have an error in your SQL syntax;
check the manual that corresponds to your MySQL server version
for the right syntax to use near '210,5' at line 1
- 1
- 2
- 3
- 4
所以无法在语法方面将两条语句重新合并,笔者便使用了以下另外一种执行方式
执行语句
#!/bin/bash start_time=`date +%s%3N` /ssd/tmp/mysql/bin/mysql -h127.0.0.1 -uroot -P3316 -pabc123 <<EOF use test; DROP PROCEDURE IF EXISTS pre_update; DELIMITER $$ CREATE PROCEDURE pre_update(IN beg INT, IN end INT) BEGIN prepare pr1 from 'update test.t1 set c2=? where c1=?'; WHILE beg <= end DO set @a=beg+1,@b=beg; execute pr1 using @a,@b; SET beg = beg+1; END WHILE; deallocate prepare pr1; END $$ DELIMITER ; call pre_update(1,1000); EOF end_time=`date +%s%3N` echo "执行时间为:"$(($end_time-$start_time))"ms"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
执行结果:
[root@computer-42 test]# bash prepare_update_id.sh
mysql: [Warning] Using a password on the command line interface can be insecure.
执行时间为:3862ms
- 1
- 2
- 3
与优化前相比:
| 优化前 | 优化后 | 提升效率 |
|---|---|---|
| 4.246 sec | 3.862 sec | 9.94% |
这样的优化幅度符合prepare语句的理论预期,但仍旧不够理想。
方案二:多个update语句放到一个事务内执行,最终commit一次
以下脚本用于生成1000行update语句在一个事务内,更新c2的值等于1000以内的随机数
#!/bin/bash
echo "begin;" > update.sql
for i in {1..1000}
do
echo "update t1 set c2=$((RANDOM%1000+1)) where c1=$i;" >> update.sql
done
echo "commit;" >> update.sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
生成sql语句如下
begin;
update t1 set c2=279 where c1=1;
update t1 set c2=425 where c1=2;
update t1 set c2=72 where c1=3;
update t1 set c2=599 where c1=4;
update t1 set c2=161 where c1=5;
... ....
update t1 set c2=775 where c1=1000;
commit;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行时间统计的方法,同上
[root@computer-42 test]# bash update.sh
mysql: [Warning] Using a password on the command line interface can be insecure.
执行时间为:194ms
- 1
- 2
- 3
执行时间为194ms=0.194sec
与优化前相比:
| 优化前 | 优化后 | 提升效率 |
|---|---|---|
| 4.246 sec | 0.194sec | 20.89倍 |
可以看出多次commit操作对性能的影响还是很大的。
方案三:使用特殊SQL语法,将多个update语句合并
合并多条update语句
在这里我们引入一种并不常用的MySQL语法:
1)优化前:
update多行执行语句类似“update xxx; update xxx;update xxx;… …”
2)优化后:
改成先把要更新的语句拼成一个视图(结果集表),然后用结果集表和源表进行关联更新。这种更新方式有个隐式限制“按主键或唯一索引关联更新”。
UPDATE t1 m, (
SELECT 1 AS c1, 2 AS c2
UNION ALL
SELECT 2, 2
UNION ALL
SELECT 3, 3
... ...
UNION ALL
SELECT n, 2
) r
SET m.c1 = r.c1, m.c2 = r.c2
WHERE m.c1 = r.c1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3)具体的例子:
###建表 create table t1(c1 int primary key,c2 int); ###插入5行数据 insert into t1 values(1,1),(2,1),(3,1),(4,1),(5,1); select * from t1; ###更新c2为c1+1 UPDATE t1 m, ( SELECT 1 AS c1, 2 AS c2 UNION ALL SELECT 2, 3 UNION ALL SELECT 3, 4 UNION ALL SELECT 4, 5 UNION ALL SELECT 5, 6 ) r SET m.c1 = r.c1, m.c2 = r.c2 WHERE m.c1 = r.c1; ###查询结果 select * from t1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
执行结果:
mysql> create table t1(c1 int primary key,c2 int); Query OK, 0 rows affected (0.03 sec) mysql> insert into t1 values(1,1),(2,1),(3,1),(4,1),(5,1); Query OK, 5 rows affected (0.00 sec) Records: 5 Duplicates: 0 Warnings: 0 mysql> select * from t1; +----+------+ | c1 | c2 | +----+------+ | 1 | 1 | | 2 | 1 | | 3 | 1 | | 4 | 1 | | 5 | 1 | +----+------+ 5 rows in set (0.00 sec) mysql> update t1 m,(select 1 as c1,2 as c2 union all select 2,3 union all select 3,4 union all select 4,5 union all select 5,6 ) r set m.c1=r.c1,m.c2=r.c2 where m.c1=r.c1; Query OK, 5 rows affected (0.01 sec) Rows matched: 5 Changed: 5 Warnings: 0 mysql> select * from t1; +----+------+ | c1 | c2 | +----+------+ | 1 | 2 | | 2 | 3 | | 3 | 4 | | 4 | 5 | | 5 | 6 | +----+------+ 5 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
4)更进一步的证明
在这里笔者选择通过观察语句执行生成的binlog,来证明优化方式的正确性。
首先是未经优化的语句:
begin;
update t1 set c2=2 where c1=1;
update t1 set c2=3 where c1=2;
update t1 set c2=4 where c1=3;
update t1 set c2=5 where c1=4;
update t1 set c2=6 where c1=5;
commit;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
...... ### UPDATE `test`.`t1` ### WHERE ### @1=1 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=1 /* INT meta=0 nullable=0 is_null=0 */ ### @2=2 /* INT meta=0 nullable=1 is_null=0 */ ...... ### UPDATE `test`.`t1` ### WHERE ### @1=2 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=2 /* INT meta=0 nullable=0 is_null=0 */ ### @2=3 /* INT meta=0 nullable=1 is_null=0 */ ...... ### UPDATE `test`.`t1` ### WHERE ### @1=3 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=3 /* INT meta=0 nullable=0 is_null=0 */ ### @2=4 /* INT meta=0 nullable=1 is_null=0 */ ...... ### UPDATE `test`.`t1` ### WHERE ### @1=4 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=4 /* INT meta=0 nullable=0 is_null=0 */ ### @2=5 /* INT meta=0 nullable=1 is_null=0 */ ...... ### UPDATE `test`.`t1` ### WHERE ### @1=5 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=5 /* INT meta=0 nullable=0 is_null=0 */ ### @2=6 /* INT meta=0 nullable=1 is_null=0 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
…
然后是优化后的语句:
UPDATE t1 m, (
SELECT 1 AS c1, 2 AS c2
UNION ALL
SELECT 2, 3
UNION ALL
SELECT 3, 4
UNION ALL
SELECT 4, 5
UNION ALL
SELECT 5, 6
) r
SET m.c1 = r.c1, m.c2 = r.c2
WHERE m.c1 = r.c1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
### UPDATE `test`.`t1` ### WHERE ### @1=1 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=1 /* INT meta=0 nullable=0 is_null=0 */ ### @2=2 /* INT meta=0 nullable=1 is_null=0 */ ### UPDATE `test`.`t1` ### WHERE ### @1=2 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=2 /* INT meta=0 nullable=0 is_null=0 */ ### @2=3 /* INT meta=0 nullable=1 is_null=0 */ ### UPDATE `test`.`t1` ### WHERE ### @1=3 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=3 /* INT meta=0 nullable=0 is_null=0 */ ### @2=4 /* INT meta=0 nullable=1 is_null=0 */ ### UPDATE `test`.`t1` ### WHERE ### @1=4 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=4 /* INT meta=0 nullable=0 is_null=0 */ ### @2=5 /* INT meta=0 nullable=1 is_null=0 */ ### UPDATE `test`.`t1` ### WHERE ### @1=5 /* INT meta=0 nullable=0 is_null=0 */ ### @2=1 /* INT meta=0 nullable=1 is_null=0 */ ### SET ### @1=5 /* INT meta=0 nullable=0 is_null=0 */ ### @2=6 /* INT meta=0 nullable=1 is_null=0 */
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
可以看到,优化前后binlog中记录的SQL语句是一致的。这也说明了我们优化后语句与原执行语句是等效的。
5)从语法角度的分析
UPDATE t1 m, --被更新的t1表设置别名为m
(
SELECT 1 AS c1, 2 AS c2
UNION ALL
SELECT 2, 3
UNION ALL
SELECT 3, 4
UNION ALL
SELECT 4, 5
UNION ALL
SELECT 5, 6
) r --通过子查询构建的临时表r
SET m.c1 = r.c1, m.c2 = r.c2
WHERE m.c1 = r.c1;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
将子查询临时表r单独拿出来,我们看一下执行结果:
mysql> select 1 as c1,2 as c2 union all select 2,3 union all select 3,4 union all select 4,5 union all select 5,6;
+----+----+
| c1 | c2 |
+----+----+
| 1 | 2 |
| 2 | 3 |
| 3 | 4 |
| 4 | 5 |
| 5 | 6 |
+----+----+
5 rows in set (0.00 sec)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以看到,这就是我们想要更新的那部分数据,在更新之后的样子。通过t1表与r表进行join update,就可以将t1表中相应的那部分数据,更新成我们想要的样子,完成了使用一条语句完成多行更新的操作。
6)看一下执行计划
以下为explain执行计划,使用了嵌套循环连接,外循环表t1 as m根据条件m.c1=r.c1过滤出5条数据,每更新一行数据需要扫描一次内循环表r,共循环5次:
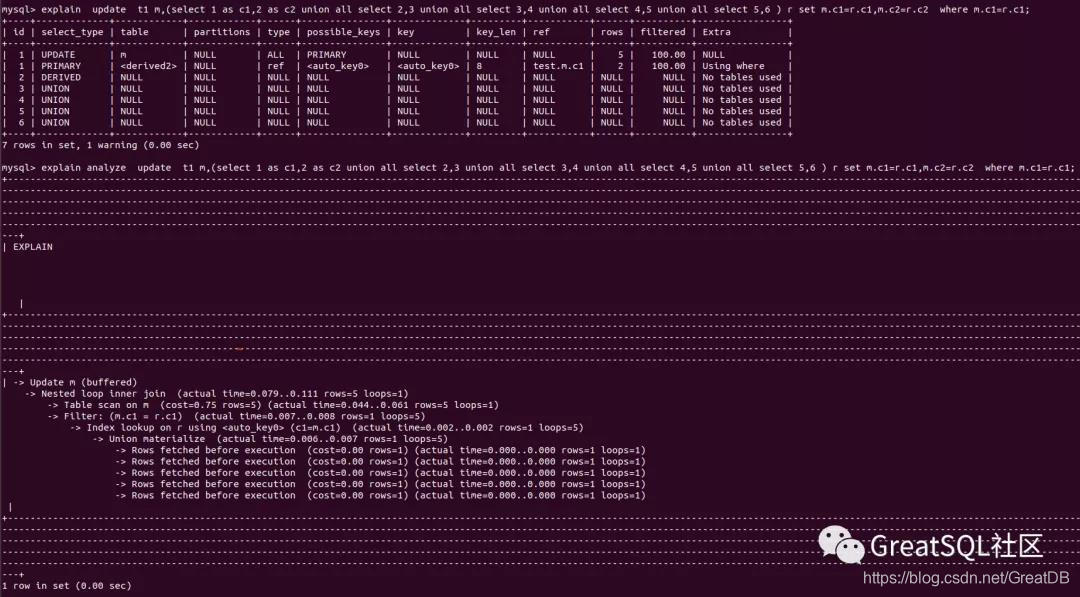
如果光看执行计划,似乎这条语句的执行效率不是很高,所以我们接下来真正执行一下。
7)实践检验
以下脚本用于生成优化后update语句,更新c2的值等于1000以内的随机数
#!/bin/bash
echo "update t1 as m,(select 1 as c1,2 as c2 " >> update-union-all.sql
for j in {2..1000}
do
echo "union all select $j,$((RANDOM%1000+1))" >> update-union-all.sql
done
echo ") as r set m.c2=r.c2 where m.c1=r.c1" >> update-union-all.sql
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
生成SQL语句如下
update t1 as m,(select 1 as c1,2 as c2
union all select 2,644
union all select 3,322
union all select 4,660
union all select 5,857
union all select 6,752
... ...
union all select 999,225
union all select 1000,77
) as r set m.c2=r.c2 where m.c1=r.c1
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行语句
#!/bin/bash
start_time=`date +%s%3N`
/ssd/tmp/mysql/bin/mysql -h127.0.0.1 -uroot -P3316 -pabc123 -e \
"use test;source /ssd/tmp/tmp/1000/update-union-all.sql;"
end_time=`date +%s%3N`
echo "执行时间为:"$(($end_time-$start_time))"ms"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
执行结果:
[root@computer-42 test]# bash update-union-all.sh
mysql: [Warning] Using a password on the command line interface can be insecure.
执行时间为:58ms
- 1
- 2
- 3
与优化前相比:
| 优化前 | 优化后 | 提升效率 |
|---|---|---|
| 4.246 sec | 0.058 sec | 72.21倍 |
|
多次测试对比结果如下:
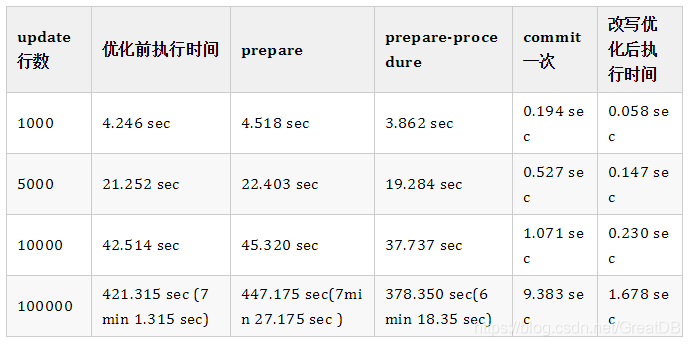
总结
根据以上理论分析与实际验证,我们找到了一种对批量更新场景的优化方式。

