
- 1搭建属于自己的数字IC EDA环境(番外):S家EDA工具 license失效,TCP端口占用问题_scl_keygen运行不生成license
- 2react项目引入electron进行mac、windows桌面应用打包,通过浏览器下载安装包
- 3Python抓取腾视频所有电影,不用钱就可以看会员电影_爬取腾讯视频vip视频
- 4k8s学习笔记(四):命名空间(namespace)详解_k8s namespace
- 5微信小程序开题报告ssm的物流快递管理平台的设计与实现+后台管理系统|前后分离VUE[包运行成功]Java毕业设计源代码_基于ssm快递管理系统报告
- 6如何制作知识付费课程?_知乎如何设置付费视频
- 7微信小程序-云开发模式pk传统开发模式【详细】_pk学习小程序开发
- 8Linux命令之 systemctl 指令_liunx systemctl 命令
- 9win10pro不够pro,win10专业工作站版本才是真的牛
- 102020年前端Vue面试题(04-04)_腾讯前端vue面试2020
新版本 | GreatSQL 5.7.36正式发布,这些新增特性不容错过~_arm编译安装greatsql5.7
赞
踩
经过近期几个月的努力,开源产品GreatSQL 5.7.36今天正式发布了,欢迎小伙伴们积极选用、多多交流。新推出的GreatSQL 版本新增了MGR角色列、MGR网络开销阈值等一系列特性,并大幅提升了稳定性、性能,修复了以往的一些bug,产品功能、性能较以往版本进行了优化升级,可以让大家在5.7版本下更放心地使用MGR。
GreatSQL 5.7.36新版本亮点
► 新增特性
1.1 新增MGR角色列
1.2 采用全新的流控机制
1.3 新增MGR网络开销阈值
1.4 调整MGR大事务限制
► 稳定性提升
► 性能提升
► bug修复
1 新增特性
1.1新增MGR角色列
在MySQL 5.7中,查询
performance_schema.replication_group_members时,没有 MEMBER_ROLE 这个列,这很不便于快速查看哪个节点是Primary Node。
在GreatSQL中,增加了这个列,查看节点角色更便利了,对一些中间件支持也更友好。
- mysql> select * from performance_schema.replication_group_members;
- +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+
- | CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+
- | group_replication_applier | 4c21e81e-953f-11ec-98da-d08e7908bcb1 | 127.0.0.1 | 3308 | ONLINE | SECONDARY |
- | group_replication_applier | b5e398ac-8e33-11ec-a6cd-d08e7908bcb1 | 127.0.0.1 | 3306 | ONLINE | PRIMARY |
- | group_replication_applier | b61e7075-8e33-11ec-a5e3-d08e7908bcb1 | 127.0.0.1 | 3307 | ONLINE | SECONDARY |
- +---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+
1.2采用全新的流控机制
原生的流控算法有较大缺陷,触发流控阈值后,会有短暂的流控停顿动作,之后继续放行事务,这会造成1秒的性能抖动,且没有真正起到持续流控的作用。
在GreatSQL中,重新设计了流控算法,增加主从延迟时间来计算流控阈值,并且同时考虑了大事务处理和主从节点的同步,流控粒度更细致,不会出现MySQL社区版本的1秒小抖动问题。
新增选项
group_replication_flow_control_replay_lag_behind 用于控制MGR主从节点复制延迟阈值,当MGR主从节点因为大事务等原因延迟超过阈值时,就会触发流控机制。

该选项默认为600秒,可在线动态修改,例如:
mysql> SET GLOBAL group_replication_flow_control_replay_lag_behind = 600;正常情况下,该参数无需调整。
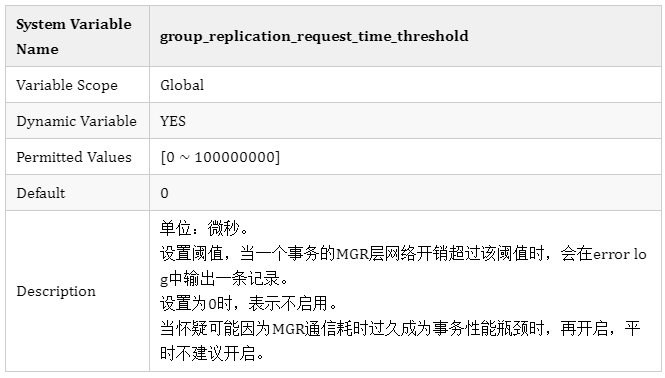
1.3 新增MGR网络开销阈值
新增相应选项 group_replication_request_time_threshold
在MGR结构中,一个事务的开销包含网络层以及本地资源(例如CPU、磁盘I/O等)开销,GreatSQL针对MGR的网络层开销进行了多项优化工作,因此在网络层的开销通常不会成为瓶颈。
当事务响应较慢想要分析性能瓶颈时,可以先确定是网络层的开销还是本地性能瓶颈导致的。通过设置选项
group_replication_request_time_threshold 即可记录超过阈值的事件,便于进一步分析。输出的内容记录在error log中,例如:
2022-03-04T09:45:34.602093+08:00 128 [Note] Plugin group_replication reported: 'MGR request time:33775'表示当时这个事务在MGR层的网络开销耗时33.775毫秒,再去查看那个时段的网络监控,分析网络延迟较大的原因。
选项 group_replication_request_time_threshold 单位是微秒,默认值是0,最小值0,最大值100000000,建议值20000(即20毫秒)。
1.4 调整MGR大事务限制
调整MGR事务限制选项 group_replication_transaction_size_limit,其默认值为150000000(同时也是最大值)。
在MySQL 5.7中,MGR事务没有进行分片处理,执行大事务很容易造成超时(并反复重发事务数据),最终导致节点报错并退出集群。
在GreatSQL 5.7中,针对该问题进行优化,并设置事务上限,超过该上限事务会失败回滚,但节点不会再退出集群。
注意,这是硬限制,即便将其设置为0,也会自动调整成150000000。
- mysql> set global group_replication_transaction_size_limit = 150000001;
- Query OK, 0 rows affected, 1 warning (0.00 sec)
-
- -- 提示被重置了
- mysql> show warnings;
- +---------+------+-------------------------------------------------------------------------+
- | Level | Code | Message |
- +---------+------+-------------------------------------------------------------------------+
- | Warning | 1292 | Truncated incorrect group_replication_transaction_si value: '150000001' |
- +---------+------+-------------------------------------------------------------------------+
- 1 row in set (0.00 sec)
-
- mysql> set global group_replication_transaction_size_limit=0;
- Query OK, 0 rows affected (0.00 sec)
-
- -- 虽然没有error也没warning,但也被重置了
- mysql> select @@global.group_replication_transaction_size_limit;
- +---------------------------------------------------+
- | @@global.group_replication_transaction_size_limit |
- +---------------------------------------------------+
- | 150000000 |
- +---------------------------------------------------+

当执行一个超限的大事务时,会报告下面的错误:
ERROR 3100 (HY000): Error on observer while running replication hook 'before_commit'.以测试工具sysbench生成的表为例,事务一次可批量执行的数据行上限约73.2万条记录:
- mysql> insert into t1 select * from sbtest1 limit 732000;
- Query OK, 732000 rows affected (16.07 sec)
- Records: 732000 Duplicates: 0 Warnings: 0
-
- mysql> insert into t1 select * from sbtest1limit 733000;
- ERROR 3100 (HY000): Error on observer while running replication hook 'before_commit'.
如果大事务能执行成功,也会记录类似下面的日志,告知该事务的字节数:
[Note] Plugin group_replication reported: 'large transaction size:149856412'
-
修复了在异常情况下(节点崩溃,关闭节点,网络分区)的剧烈性能抖动问题。
-
提升数个大事务造成的长时间阻塞的问题。
3 性能提升
-
重新设计事务认证队列清理算法。MySQL社区版本中,对事务认证队列清理时采用了类似全表扫描的算法,清理效率较低,性能抖动较大。在GreatSQL版本中,对事务认证队列增加了类似索引机制,并控制每次清理的时间,可以有效解决清理效率低、性能抖动大的问题。
-
提升了Secondary节点上大事务并发应用回放的速度。
-
增加xcom cache条目,提升了在网络延迟较大或事务应用较慢场景下的性能。
4 bug修复
-
修复了在启用dns或hostname的情况下,bind意外失败问题。
-
修复了协程调度不合理的问题,该问题可能会造成在大事务时系统错误判断为网络错误。
-
修复了新加入节点在追paxos数据时,由于write超时导致连接提前关闭的问题。
-
修复了recovering节点被中途停止导致的数据异常问题。
-
修复了多主多写模式中,个别情况下可能丢数据的问题。
-
修复了在某些特殊场景下,多个节点同时启动一直处于recovering的状态
-
修复了applier线程在特殊场景下的诡异问题。
-
修复了在高并发情况下由于创建线程失败导致的死循环问题。
-
修复了某一个从节点hang住导致整个集群被拖垮的问题。
-
修复了单机部署多个节点场景下,tcp self connect导致的诡异问题。
-
修复了同时多个异常导致的视图问题。
-
修复了5个及以上节点数量同时重启导致的视图问题(某一个节点会一直处于recovering状态)。
-
修复了在某些场景下同时添加节点失败的问题。
-
修复了在特殊场景下组视图异常的问题。
以上,就是关于此次GreatSQL 5.7.36最新版本的介绍了,欢迎大家下载源码或安装包在线体验:
源码下载地址:
https://gitee.com/GreatSQL/GreatSQL/tree/greatsql-5.7.36
安装包下载地址:
https://gitee.com/GreatSQL/GreatSQL/releases/GreatSQL-5.7.36-39

