
- 1Android WebView版本升级的方法_webview怎么升级
- 2解决router跳转组件实例被复用,数据不响应_vue跳转路由 加载js, 获取不到响应
- 3Gen-AI 的知识图和分析(无需图数据库)_gen ai
- 4Unity UGUI的StandaloneInputModule (标准输入模块)组件的介绍及使用
- 5关于Sora文生视频你需要知道的核心知识点,OpenAI Sora技术报告原文深度解读_openai sora学习资料
- 6MIPI DSI的linux kernel驱动原理 | 基于RK3399_kernel dsi
- 7智能合约安全——溢出漏洞_智能合约漏洞
- 8微信小程序——保存图片到手机相册(代码详解)_微信小程序下载图片到本地
- 9竞赛 大数据疫情分析及可视化系统_疫情大数据exc
- 10使用gradio库的File模块实现文件上传和展示_gradio上传文件
基于新一代kaldi项目的语音识别应用实例_next kaldi 接口
赞
踩
本文是由郭理勇在第二届SH语音技术研讨会和第七届Kaldi技术交流会上对新一代kaldi项目在学术及“部署”两个方面报告的内容上的整理。如果有误,欢迎指正。
文字整理丨李泱泽
编辑丨语音小管家
喜报:新一代Kaldi团队三篇论文均被语音顶会ICASSP-2023接收
论文链接:
-
Fast and parallel decoding for transducer
https://arxiv.org/abs/2211.00484
-
Delay-penalized transducer for low-latency streaming ASR
https://arxiv.org/abs/2211.00490
-
Predicting Multi-Codebook Vector Quantization Indexes for Knowledge Distillation
https://arxiv.org/abs/2211.00508

感谢各位对新一代Kaldi社区的关注。今天我主要介绍新一代Kaldi在学术及“部署”两个方面应用实例。“部署”在这里打了引号,是因为部署是一个复杂的系统,25分钟无法很好地描述它。因此今天只有一两页PPT会涉及到它,更多介绍在学术方面的应用。

今天的演讲主要包含以下几个环节,首先是我们项目以及团队的介绍。第二个环节是关于k2的学术应用,第三个环节是模型部署和sherpa子项目的介绍。由于只有25分钟时间,后面Q&A的时间可能不是特别充足,欢迎大家关注我们的公众号,扫码进入交流群。公众号每周五会推送一篇k2的文章,会介绍我们近期的工作和k2论文核心算法的实现。我们非常用心地去准备并且写得非常详细,强烈推荐对新一代Kaldi应用以及核心算法感兴趣的朋友关注我们公众号。

我们团队在小米有一个7人小组,同时也有很多来自开源社区广大工程师的支持。另外 Daniel Povey 教授领衔开发了k2 Lhotse 和 Icefall 项目,数据处理项目是以 Piotr 博士领衔开发。再次感谢广大开源社区工程师的支持。

今天的演讲主要涉及k2项目,熟悉新一代Kaldi项目的同学知道它包含很多子项目(而第一代Kaldi是一个单独的项目)。新一代Kaldi采用项目群的方式有利有弊。先说弊端,有的刚接触的朋友可能会说这项目哪是哪,我怎么一键跑不起来,一会儿要装这个一会儿要装那个。然后好处呢,如果朋友们听完今天的分享,可能会意识到为什么要拆成一个一个子项目,以及拆成子项目的好处。

新一代Kaldi是一个项目群,所以现代Kaldi项目并不完全等同于k2。k2只是其中一个子项目。今天我们主要涉及k2的学术应用。这个截图是k2 官网上截的一个介绍,当时 Dan 哥在写这个介绍时,我其实没有太看懂什么意思,今天我把这个重点标出来。第一段讲的是无缝融合,k2与Pytorch以及状态求导转换机的无缝结合。结合的目的在于可以很容易地修改结合各种不同的损失函数,像这里写到的交叉熵损失函数、CTC损失函数。第二个重点在于Compose函数,如何把一个神经网络的 embedding 转成状态机,转成状态机后,它就可以与很多传统的状态机的状态图去结合计算。我们今天主要针对这两段展开介绍。

这一页ppt是将k2官网首页的愿景翻译成中文。第一个就是Pytorch的无缝融合。既然说到k2 与 Pytorch是无缝融合。我们先来看看原来的缝在哪里。在没有k2的时候,也有很多把状态图的算法实现出来给Pytorch打补丁。早期的时候,我们有一个用pybind11给Kaldi 打包的项目(注:第一代Kaldi 项目中的pybind11分支),它和Pytorch有那么一点点的缝,不像k2那么无缝结合。它的缝在于底层内存分配没有用 torch的Allocator。k2 消除的另一缝在于它关键数据结构和算法都继承了 torch.autograd.Function。熟悉 Pytorch 的朋友可能知道,一旦继承了这个 function 之后,相当于就被 Pytorch 的 outograd graph 图追踪。所以k2的这些函数和Pytorch的自动求到就无缝结合上了。
在无缝结合的基础上,k2另一个愿景是实现很多FSA和FST算法,并且这些算法实现可以高效地运行于显卡之上。整个k2的运算不是在 tensor 维度,而是在 FST 维度。在k2里面有一个函数,它可以把Pytorch的tensor embedding转换为FSA。随后整个计算就转为了一个FSA/FST的操作,一个神经网络的embedding转化为FST/FSA的效果如上页ppt右图所示。这个示意图画的是,如果我有两个时刻,每个时刻有8帧的概率,那么这个 T x C = 2 x 8的这么一个矩阵,它转成FST/FSA后大概就长这个样子。这个也很容易理解,现在就2帧,第一个时刻和第二个时刻之间可以随意跳,第零个时刻和第一个时刻之间也可以随意跳,跳转概率就是每个token自己神经网络对应的概率。
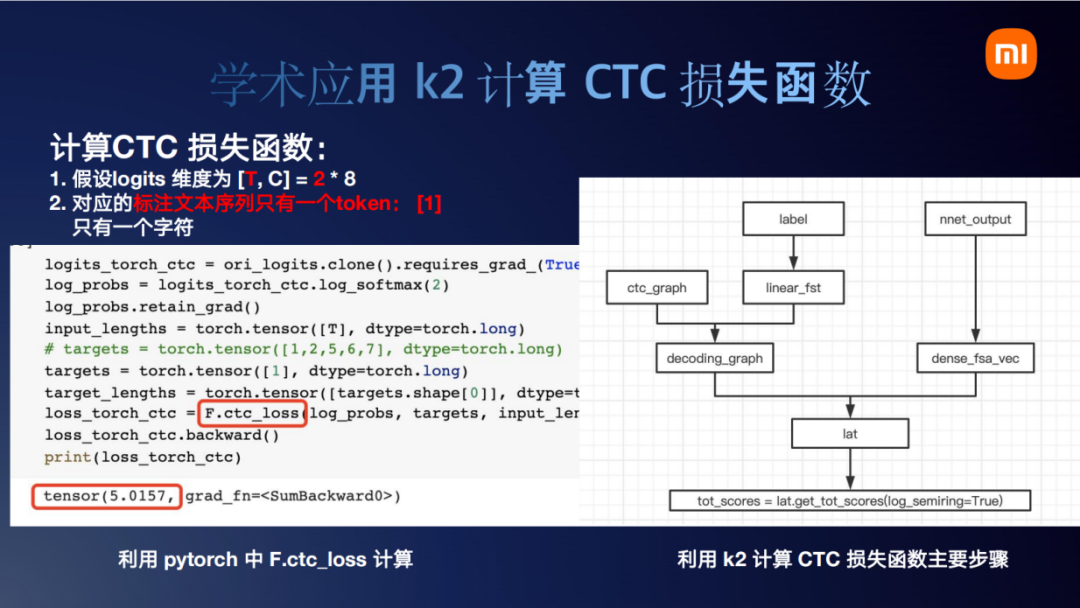
k2要将所有的东西都转换为FST/FSA。接下来我们分析一个应用:k2是如何计算CTC损失函数的。现在假设 logits 也就是神经网络的输出为 2 x 8,标注文本只有一个token。即:两个时刻个logits, 一个tokenn。如果用Pytorch去计算的话,就是左边这个真实的代码,只需要调用 torch.Function.ctc_loss,一行就出来了(结果是5.0157)。如果用k2去实现的话,整个流程大概如右图所示。我们刚才说,k2把所有的概念所有的变量都转换为了FST/FSA。那么看到这个右边,k2计算CTC loss整体分为两大块。首先是左边,左边先处理文本信息label,然后和ctc_graph compose得到decoding_graph(注:逻辑上可以通过compose实现,在实际生产环节,会直接采用更为高效的k2.ctc_graph,“跳过”compose过程)。右边是处理神经网络的输出nnet_output,将它转为dense_fsa_vec,就是我们前一页看的那个图。然后decoding_graph和dense_fsa_vec compose后去做一个lattice,最后lattice再最大score。
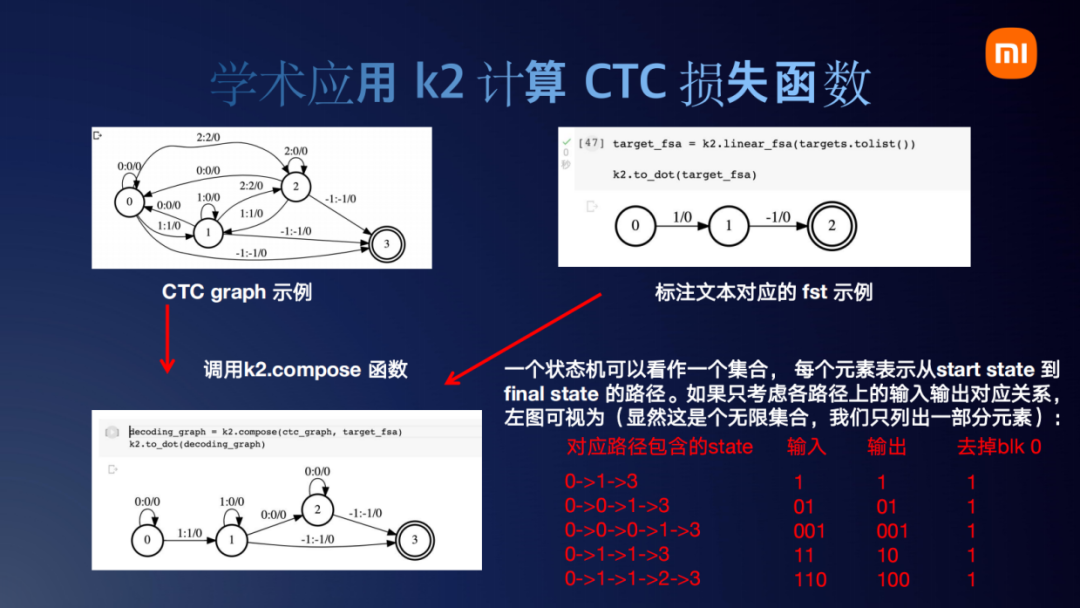
token也就是右上角这个文本对应的fst也很好理解,token就是1,跳一步生成一个1。最后这个-1到0的边,是k2里自定义的一个特殊要求,每一个fst必须以-1结尾,这个不影响我们的理解,所以这个-1我们可以暂时忽略。左边的CTC graph,熟悉CTC的朋友可能知道,一般我们在论文里面画CTC gragh也都是这样画。现在把CTC graph和文本对应的线性序列去做compose的话,它会得到左下角这个图。左下角这个图其实就是表示怎样生成一个token 1。我们解释一下这个图,一个状态机可以看作一个集合,它的每一个状态就是一个路径。首先这个路径无法穷举,因为含有自环。我们就列出来几个,可以看出,无论左下角这个图怎么走,它最后输出的token都是1。所以这页PPT 展示了如果文本标注是一个token 1,它所对应的fst图结构会如左下角所示。
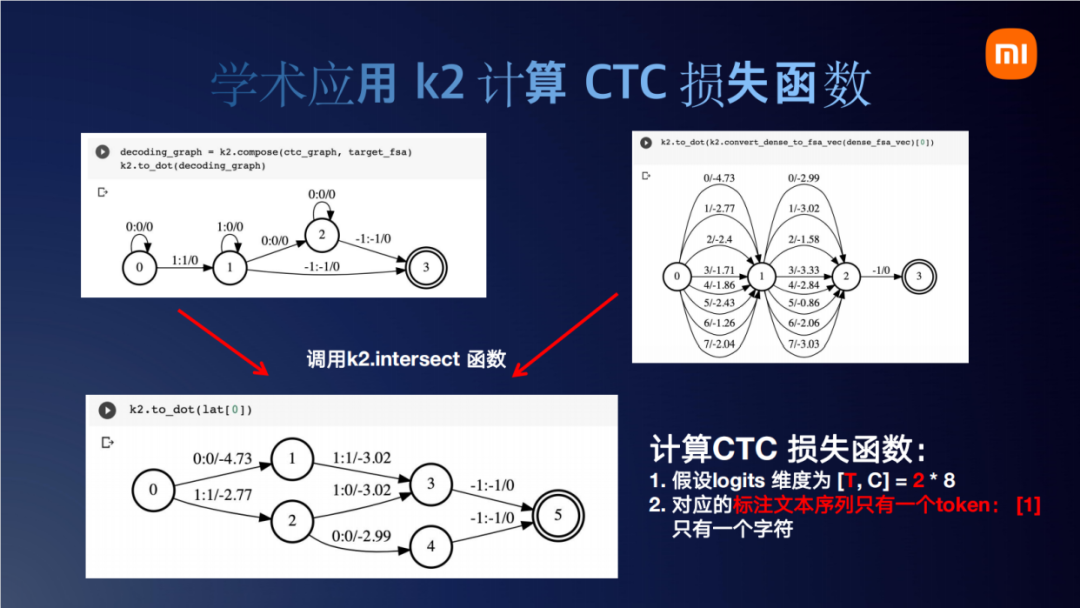
刚才我们将文本处理完了,现在处理神经网络。神经网络会转成这么一个dense_fsa,它和文本token对应的图结构(左上)去做intersect之后,输出左下角这个图。我们大概走一下这个图,比如0到1、1到3,它输出0 1,那么0是一个blank我们不要,相当于输出一个token 1。边上的概率就是从神经网络里拿到的,此时得到这个lattice,可以看到确实只有两个时刻(最后-1对应的边可以忽略)。各个边上的概率就是从神经网络上获取的概率,然后输出的label刚好就是我们文本要求的一个1。

那再对这个lattice做一个tot_score,得到5.0157。这个基于k2的CTC的损失函数结果有三个注意的点,首先它也等于5.0157(和前面torch.Function.ctc_loss结果完全一致)。第二点是,它是一个torch的tensor,这个的意义在于,神经网络的tensor转换为fsa/fst后经过k2的一番操作它还是一个tensor。从这个角度上我们可以说k2和Pytorch是无缝融合的。第三个点在于它有一个grad_fn,如果熟悉Pytorch就知道任何一个tensor只要它有grad_fn,它就可以做backward。
目前位置,我们以基于k2的CTC损失函数为例,解释了一下什么是Pytorch与k2的无缝融合。

明明Pytorch一行就能实现的东西,k2搞得这么复杂化简为繁是不是吃饱了没事干。其实不是,前面的几页PPT都是为接下来的两篇论文做铺垫。

首先我们分享一下英伟达的论文。如同刚开始宝秋总分享的那样,k2项目不只是小米一个团队开源出来的,还有很多开源社区的朋友一起贡献代码。不只是我们的工作值得关注,那些用k2来做研发的很好的一些点也值得大家关注。今天我们分享特意选了两篇不是我们团队的论文,避免大家说我们“王婆卖瓜,自卖自夸”。第一篇是英伟达最近被Interspeech接收的一篇论文。

我们回顾一下,这个就是刚才说的k2计算CTC的主要步骤。这篇论文主要修改了绿色这个点,也就是ctc_graph这一块儿。

看一下论文中的截图,常见的ctc_graph图是图a,论文里提出将这个图改为更简单一点的c、d。总体上来说,改了之后别的流程都不需要动,只需要把绿色这块儿的结构改了,就可以调用k2完成后续的计算。
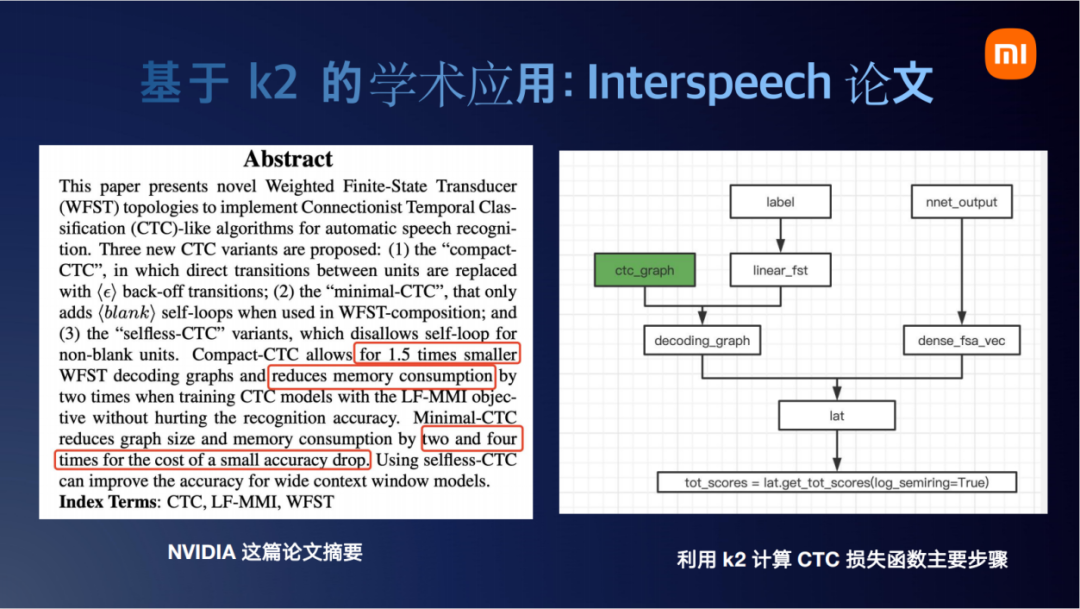
它最终获得的效果是,如果去裁剪一下这个图,不按标准做法去做,去画一个特别小的图,准确率会有一定的损失,但是图的大小和内存占用可以小2到4倍。看到这里,我们就想这篇论文的工作,没有k2也是可以实现的。但是肯定会复杂一点,而且Pytorch CTC也不支持这样的操作。那k2究竟为这项工作带来多大的便利性呢。

我们看一下它的代码实现。这个代码是真实的代码,我直接从英伟达开源项目NVIDIA NeMo里截取出来的。看一下它是如何实现的,为什么说使用k2会给这个论文带来极大的便利性。他们最核心的函数就是我画红框和绿框的这两个,它调用的接口是k2.Fsa.from_str。我们只需要把边的信息写成一行一行的文本文件或者写成string类型。它前面这个构图实际上就写了一个for循环,构建了一个Python的代码。然后再写一个字符串的处理函数,就把这个图构出来了。构出来以后呢,直接就使用k2.Fsa.from_str导入进来。右边这个也是写一个字符串的处理函数去构一个图。构图之后,用k2.Fsa.from_str就把这个图导进来了。导进来之后,对k2来说,无论是标准的CTC拓扑图,还是改进后的拓扑图,或者还是你自己特地设计出来的别的图,只要合法,都能用k2.Fsa.from_str导进来,后续都可以用compose、intersect操作计算出来损失函数。所以说k2的便利性做的特别好。总体上来讲,用户只需要用python 字符串处理程序生成图,后续的操作都可以交给k2来探索不同结构的fst 的效果。

第二篇我们分享北京大学和腾讯基于k2的ICASSP论文,最近被ICASSP接受了。
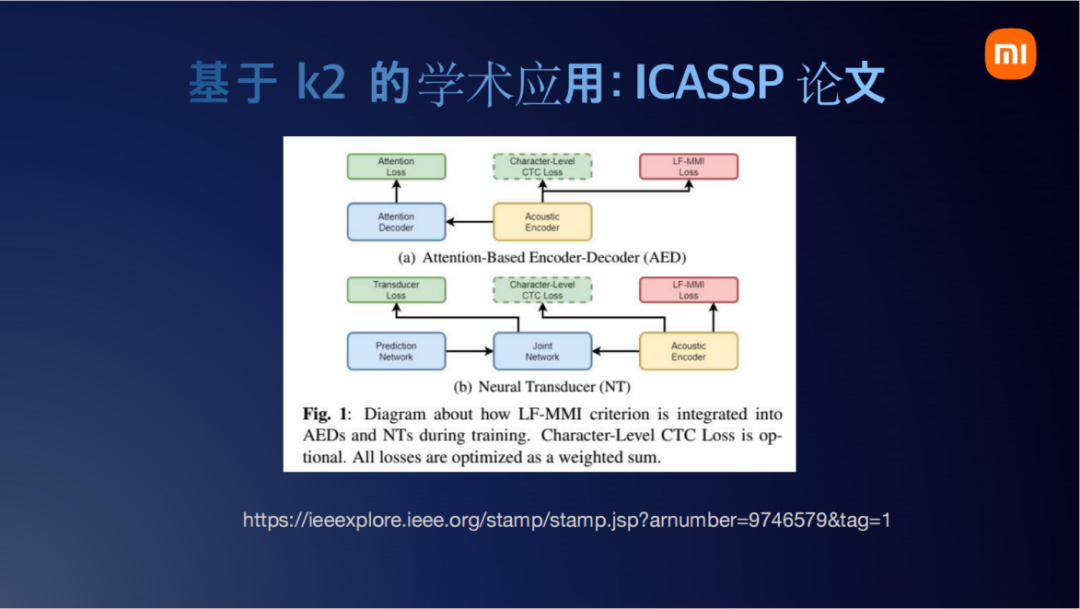
它的工作是在经典的端到端训练框架上加了两个loss。一个是Character-Level CTC Loss,一个是LF-MMI Loss。结合上面那个例子,使用k2来实现这个的话就是天衣无缝了。我们只需要把图导进来,LF-MMI也是一个分子图一个分母图。把图做进来后,剩下的compose和intersect操作k2都是无缝支持的。

他们这里面也提到引入图操作的损失函数,准确率会获得大约4.1%到4.4%的提升。他们这个工作也是基于k2来实现的,也开源了,感兴趣的朋友可以关注一下。

这两篇是友商基于k2实现的论文,可以看一下他们用了大概哪些接口。第一个接口就是k2.Fsa.from_str,我个人感觉,翻译成·白话就是只要你会用Python处理字符串,你就可以构建Fsa的图,导进来后和pytorch无缝结合。from_str()还有一个接口是openfst=True。如果你现在已经有了一个由openfst构建的图,转成字符串后k2也可以识别,可以非常丝滑得导入。k2的图也可以非常丝滑地转成openfst的图。另一个我个人非常推荐的就是k2.to_dot,之前PPT里的都不是我特意去找什么画图工具画的,就是使用的k2.to_dot。可以看到截图里还有代码,调用k2.to_dot(fsa)。如果你在k2里做了一个字符串,想看看画的图对不对,直接就可以所见即所得,所得即所见,非常方便。还有一个函数就是k2.convert_dense_to_fsa_vec,如果想把一个torch的tensor转成fsa,只需要调用这个函数,接下整个fsa操作完成后返回的仍然是torch的tensor。tensor转成fsa之后,剩下的可以调用一系列k2里的工具,你可以用compose、intersect等各种各样的工具去处理它,处理完后返回的tensor与Pytorch无缝衔接,并且可导。
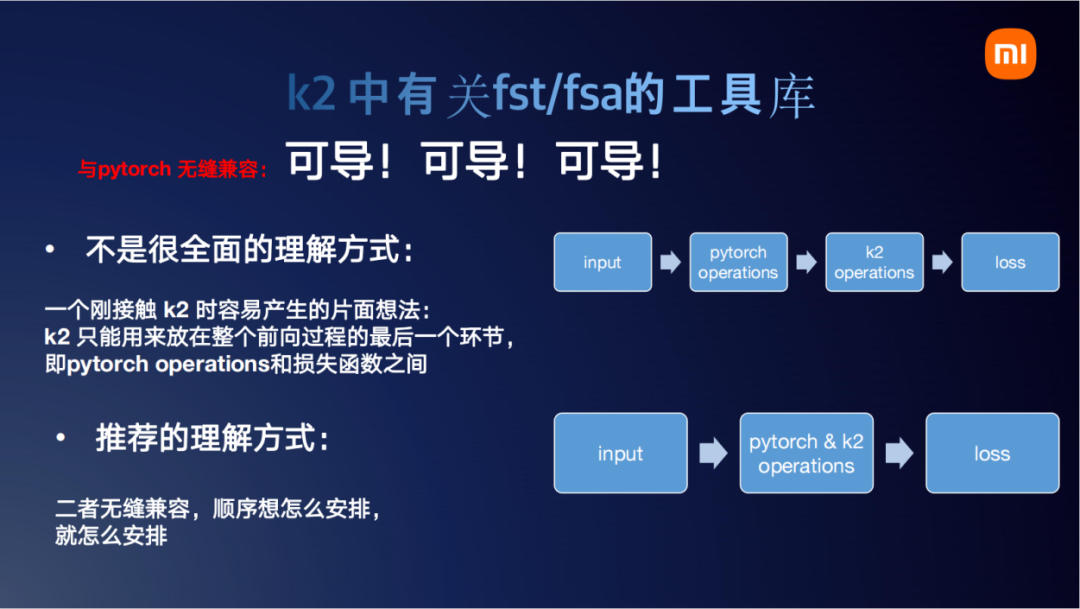
我们继续讲一下Pytorch这个可导该怎么理解。一种我个人感觉不是很全面的理解方式,可能受我们早期kaldi-pybind11的影响,总是觉得k2的函数是不是只能到最后计算损失函数的时候稍微用一下。以前把Pytorch和LF-MMI损失函数结合起来的时候,要把kaldi的LF-MMI函数打包成一个Python的接口。这样的话这个接口只能实现LF-MMI这个函数,别的什么都实现不了。从那个时代过来的朋友可能会有一个误区,觉得k2是不是也这样。input音频,经过Pytorch的transformer、Linear或是什么一大段处理,处理完后再送给k2的一个操作,返回一个loss。事实上这个理解是对的,刚才那两篇论文里也是这么实现的,但不是特别全面。因为我们说Pytorch与k2是完全无缝兼容的,两者的操作完全可以穿插着来。比如我现在有10个函数,第一个函数是Pytorch的函数。那现在我处理完后,我感觉到现在这个环节我需要一个k2的函数把它处理一下,比如k2的regular_tensor之类的去处理一下。那你第二个环节可以去插入一个k2的操作,k2的操作返回一个Pytorch的tensor。那你紧接着由可以在第三个环节插入一个Pytorch,在第四个环节插入一个k2。像三明治一样,一层加一层。我觉得这个可能是Pytorch与k2无缝理解的一种方式。包括我们最近在实现的MWER这样一种损失函数就是穿插着来的,先对神经网络的tensor做一个Pytorch的操作,然后做k2的操作,然后又是Pytorch的操作.....所以说完全无缝兼容。
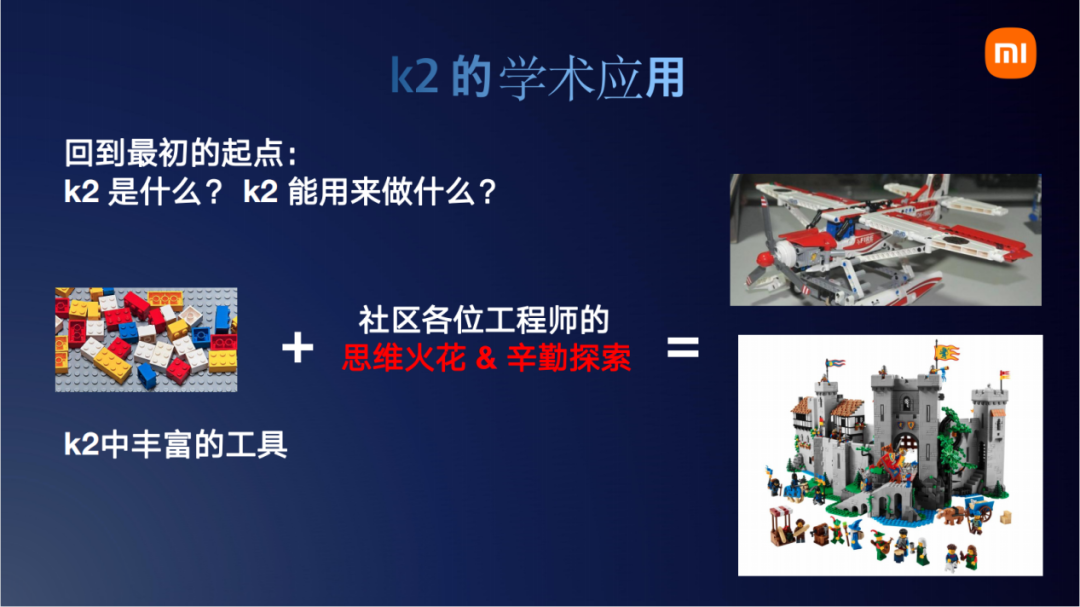
结合起来,我们回答一个问题,k2是什么或者说k2能用来做什么。我个人感觉是k2提供了各种各样丰富的工具。这个工具究竟有什么用,我们写的时候也不知道这个工具能发挥到多大的威力。比如英伟达那篇论文,看完之后我也感觉很巧妙。当初在设计k2里的那些接口的时候,也没有想到会这么用。但是英伟达他们团队就用很巧妙的思维,找的点非常好,再加上辛苦的实验,做出来这么好的结果。做一个类比的话,k2里的工具就像是乐高的积木。那能用积木块搭成什么样子完全取决于社区广大工程师的思维探索。k2的工具并不会限制我们的能力,不像原来那种对kaldi工具打个包,那你只能用原有的版本,干不了别的。k2的工具是非常丰富的,你想怎么组装就怎么组装,实现什么功能能限制的就只有我们自己的思维了,k2这个工具其实已经完全做好了。再举一个类比的例子,这有点像torch的Linear和Conformer、Transformer之间的关系。像Linear这个结构,一个线性的变化Y = w * X,这个接口很早就出来了。后面就出来很聪明的人,把LInear去搭建这种attetion的qkv结构。这个例子就类似与k2,k2提供了很多的小工具接口,这些接口怎么搭建起来去做实验的一个功能,这个可能就需要一些思维火花。所以我个人建议,有发论文的这种要求的朋友们可以去研究一下k2。把奇思妙想和k2这些现有的工具结合起来,然后为我们学术领域做贡献。

前面pr了一堆友商的论文,我们也介绍一下我们自己的论文。前面有朋友问有没有论文链接,这边也给了链接。第一个就是Puned RNN-T的函数,我个人觉得不那么谦虚地讲可能是地球上最快的RNN-T损失计算方法。第二个就是RNN-T高速并行的解码方法,它可以实现基于CUDA加速,可以多个音频同时解码,并且集成了基于FST的解码图。第三个工作是label delay的控制方法,我们这个方法不仅可以用在RNN-T上也可用在CTC上。第四个引入的Training overhead几乎可以忽略不计的新型蒸馏框架,Dan哥前面有介绍,这边都给出了论文链接。

接下来介绍k2工程部署的工作sherpa。这个图可能画的不是特别的全,因为sherpa这个项目正在不断地发展。但是我们还是希望以这个图尽量把sherpa项目的思想和大概设计展示给大家。第一是我们把这个项目以sherpa为核心分为前端和后端。后端支持k2的解码,包括各种各样的MACE、NCNN、ONNX这些神经网络的引擎。这些引擎驱动的模型或者来自于我们Icefall的训练,或者来自于WeNet的训练,甚至来自于Torchaudio和Espnet的训练。一旦能导成ONNX或者Torchscript的模型,就可以使用sherpa来驱动。Sherpa建立好语音服务的后端引擎后,你可以通过websocket或者HTTP,以及python的前端或者C++前端或者Javascript前端完全无缝地结合起来。解释到这里我还想解释一下为什么新一代kaldi选择用项目组的方式来组建这个项目而不是像kaldi一样单个项目。结合刚才我们两个工作,比如像英伟达和腾讯他们开源的项目都用了k2。从他们论文需求上讲,他们可能只是需要fst或者fsa的操作,他们只需要把k2的子项目去集成到他们整个语音项目里,不需要用我们sherpa、lhotest。另外一块比如说现在有一些公司或者团队他们想用sherpa项目,他们模型的工具可能是他们自己自研的一套。但是不影响,使用sherpa项目只需要把训练的流程转成ONNX或者任意一种sherpa支持的格式,那你就可以用sherpa驱动起来。我觉得这个也可以大概显示出来我们使用项目组,把各个子项目进行解耦管理的优势。

正如Dan哥所说,现场放demo总是可能有风险,再加上时间有限。对我们工作感兴趣的朋友,可以扫码关注一下公众号,也可以加入我们的群。我们尽量做到每周更新。朋友们对新一代kaldi有问题可以在群里面问,我们会写文章去回答,如果这个问题特别好的话。

总结一下今天我们简要的分享主要是分享了两个问题。一个是现代kaldi项目包含很多子项目,k2是其中一个主要用于实现fst和fsa算法的子项目。另一个是我们当前主力研发的sherpa子项目,它是用于部署我们训练所得的模型。

最后热烈欢迎朋友们来关注公众号。

