
- 1“access denied for user ‘root‘@‘localhost‘_phpmyadmin root
- 2精品微信小程序基于Uniapp+springboot基于微信小程序的摄影平台设计与实现|计算机毕业设计|Java毕业设计|课程设计|Python毕设|小程序|毕业设计推荐_基于微信小程序的摄影作品交流平台
- 3探讨生产环境下缓存雪崩的几种场景及解决方案_生产环境的redis、雪崩
- 4Android开发 8.0及以上调用相机/相册,并根据Uri获取图像绝对路径,并进行文件上传_android.media.action.image_capture
- 5Java加密与解密的艺术~AES-GCM-NoPadding实现_aes/gcm/nopadding
- 6【C++】【C++ Primer】9-顺序容器_yaml::const_iterator 是有序的吗?
- 7Linux/Unix解压缩unzip命令_unzip -oq
- 8Python学习笔记(十九)——Matplotlib入门_import matplotlib
- 9神经网络系列---池化
- 10Android Studio:如何修改JDK版本和获知使用的Java版本_android studio jdk
如何优化大型语言模型,让AI回应更智能、更准确?_大语言模型回复,“对不起没有听懂你的问题”
赞
踩
什么是检索增强生成(RAG)?
检索增强生成(RAG)是一种优化大型语言模型输出的过程,它在生成回应之前会参考其训练数据源之外的权威知识库。大型语言模型(LLM)在大量数据上进行训练,使用数十亿参数来生成原创输出,以执行回答问题、翻译语言和完成句子等任务。RAG将LLM已经强大的能力扩展到特定领域或组织的内部知识库,而无需重新训练模型。这是一种成本效益高的方法,用于改进LLM的输出,使其在各种情境中保持相关性、准确性和实用性。
LLM是推动智能聊天机器人和其他自然语言处理(NLP)应用的关键人工智能(AI)技术。目标是创建能够通过参考权威知识源,在各种情境中回答用户问题的机器人。不幸的是,LLM技术的性质引入了LLM回应的不可预测性。此外,LLM训练数据是静态的,对它拥有的知识引入了一个截止日期。
LLM的已知挑战包括:
● 当没有答案时提供错误信息。
● 当用户期望具体、当前的回应时,提供过时或泛化的信息。
● 从非权威来源创建回应。
● 由于术语混淆而创建不准确的回应,不同的训练源使用相同的术语来讨论不同的事物。
你可以将大型语言模型想象为一个过于热情的新员工,他拒绝了解当前事件,但总是会满怀信心地回答每一个问题。不幸的是,这种态度可能会对用户信任产生负面影响,这不是你希望你的聊天机器人模仿的!
RAG是解决这些挑战的一种方法。它引导LLM检索来自权威、预先确定的知识源的相关信息。组织可以更好地控制生成文本输出,用户可以了解LLM如何生成回应。
为什么RAG是重要的?
LLM是推动智能聊天机器人和其他自然语言处理(NLP)应用的关键人工智能(AI)技术。目的是创建能够通过参考权威知识源,在不同情境中回答用户问题的机器人。遗憾的是,LLM技术的本质引入了对LLM响应的不可预测性。此外,LLM训练数据是静态的,对它掌握的知识设置了一个截止日期。
LLM面临的已知挑战包括:
● 当没有答案时提供错误信息。
● 当用户期望具体、当前的回应时,提供过时或泛化的信息。
● 从非权威来源创建回应。
● 由于术语混淆而创建不准确的回应,不同的训练源使用相同的术语来讨论不同的事物。
你可以将大型语言模型看作是一个过度热情的新员工,他拒绝了解当前事件,但总是会满怀信心地回答每个问题。不幸的是,这种态度可能会对用户信任产生负面影响,这并不是你希望你的聊天机器人模仿的!
RAG是解决这些挑战的一种方法。它引导LLM检索来自权威、预先确定的知识源的相关信息。组织可以更好地控制生成的文本输出,用户可以了解LLM如何生成回应。
RAG有什么好处?
检索增强生成(RAG)技术为组织的生成式人工智能工作带来了几个好处。
成本效益的实施
聊天机器人的开发通常是从基础模型开始的。基础模型(FMs)是可通过API访问的、在广泛的泛化和未标记数据上训练的大型语言模型(LLM)。为了使FMs适应组织或特定领域的信息,重新训练的计算和财务成本很高。RAG是引入新数据到LLM的更经济有效的方法。它使生成式人工智能(生成AI)技术更广泛地被接入和使用。
最新信息
即使LLM的原始训练数据源适合您的需求,保持相关性也是一个挑战。RAG允许开发人员提供最新的研究、统计数据或新闻给生成模型。他们可以使用RAG将LLM直接连接到实时社交媒体源、新闻网站或其他频繁更新的信息源。LLM可以向用户提供最新信息。
增强用户信任
RAG使LLM能够提供带有来源归属的准确信息。输出可以包括引用或参考来源。如果用户需要进一步的澄清或更多的细节,他们也可以自行查找源文件。这可以增加用户对您的生成AI解决方案的信任和信心。
更多开发者控制
使用RAG,开发者可以更有效地测试和改进他们的聊天应用程序。他们可以控制并更改LLM的信息来源,以适应不断变化的需求或跨功能使用。开发者还可以限制对不同授权级别的敏感信息检索,并确保LLM生成适当的回应。此外,如果LLM针对特定问题引用了错误的信息来源,他们还可以进行故障排除和修复。组织可以更有信心地为更广泛的应用实施生成AI技术。
RAG是如何执行的?
在没有RAG的情况下,LLM会接收用户输入并基于它所接受的训练信息(或它已经知道的内容)来创建回应。使用RAG后,引入了一个信息检索组件,它利用用户输入首先从新的数据源提取信息。用户查询和相关信息都提供给LLM。LLM使用新的知识和它的训练数据来创建更好的回应。以下部分提供了这一过程的概览。
创建外部数据
LLM原始训练数据集之外的新数据称为外部数据。它可以来自多个数据源,例如APIs、数据库或文档存储库。数据可能以文件、数据库记录或长文本等各种格式存在。另一种称为嵌入式语言模型的AI技术,将数据转换成数值表示并存储在向量数据库中。这个过程创建了生成AI模型可以理解的知识库。
检索相关信息
下一步是执行相关性搜索。用户查询被转换为向量表示并与向量数据库进行匹配。例如,考虑一个可以回答组织人力资源问题的智能聊天机器人。如果员工搜索“我有多少年假?”系统将检索年假政策文档以及个别员工的过去请假记录。这些特定文档将被返回,因为它们与员工的输入高度相关。相关性是通过数学向量计算和表示来计算和确定的。
增强LLM提示
接下来,RAG模型通过添加相关检索数据的上下文来增强用户输入(或提示)。这一步使用提示工程技术有效地与LLM通信。增强提示允许大型语言模型生成对用户查询的准确回答。
更新外部数据
接下来的问题可能是——如果外部数据变得陈旧怎么办?为了保持检索的当前信息,异步更新文档并更新文档的嵌入表示。您可以通过自动化实时过程或定期批处理来实现。这是数据分析中的一个常见挑战——可以使用不同的数据科学方法进行变更管理。
以下图表显示了使用RAG与LLM的概念流程。
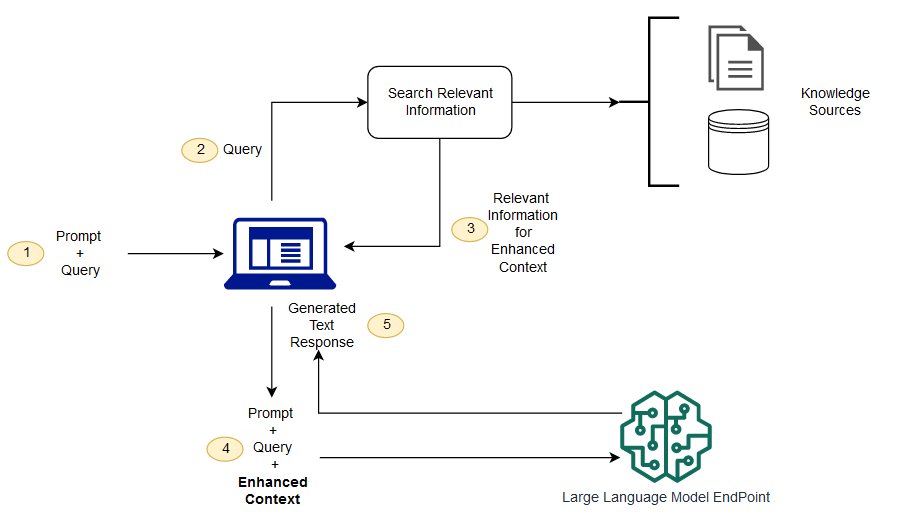
检索增强生成(RAG)与语义搜索(semantic search)之间的区别是什么?
对于希望将大量外部知识源添加到其LLM应用程序中的组织来说,语义搜索增强了RAG的结果。现代企业在各种系统中存储了大量信息,如手册、常见问题解答、研究报告、客户服务指南和人力资源文件存储库。在大规模情况下进行上下文检索具有挑战性,因此降低了生成输出的质量。
语义搜索技术可以扫描大型异构信息数据库并更准确地检索数据。例如,它们可以通过将问题映射到相关文档并返回特定文本而不是搜索结果来回答诸如“去年在机械维修上花费了多少钱?”之类的问题。开发者然后可以使用该答案为LLM提供更多上下文。
RAG中的常规或关键字搜索解决方案在知识密集型任务中产生有限的结果。开发者还必须处理词嵌入、文档分块和在手动准备数据时的其他复杂性。相比之下,语义搜索技术完成了知识库准备的所有工作,因此开发者不必这样做。它们还生成按相关性排序的语义相关段落和词汇,以最大化RAG载荷的质量。

