
- 1关于java插入数据返回主键问题_
- 2Go语言学习--Gin框架之Hello World
- 3RHCS+GFS2+ISCSI+CLVM实现共享存储
- 4加盐密码哈希:如何正确使用 (密码加密的经典文章)
- 5【nRF Connect】一、下载方法及简介_nrfconnect官网下载
- 6Vue中数组常用操作函数/迭代器使用总结 -- 数组亦可称为集合_vue 数组函数
- 7人工智能发展史总结_智能技术发展经历了
- 8APP以隐私政策弹窗的形式向用户明示收集使用规则,未经用户同意,存在收集Android ID、IMEI的行为。——YonStudio开发_app收集android id
- 9ADS1256+STM32程序详解
- 10Android Studio中 安卓模拟器不能联网的解决方案_idea 模拟器 汉化 androidwifi has no internet accesstap
Python笔记 | 数据筛选_python筛选列表数据
赞
踩
无论是在数据分析还是数据挖掘的时候,数据筛选总会涉及到。这里我总结了一下python中列表,字典,数据框中一些常用的数据筛选的方法。
1.列表
案例一:从一个含有数字0-9的列表中筛选出偶数(奇数):
- enumerate方法(生成两列数据,第一列是索引,第二列是数值)
num=[i for i in range(10)]
num1=[]
for index,count in enumerate(num):
if count%2==0:
num1.append(num[index])
print(num1)
- 1
- 2
- 3
- 4
- 5
- 6
2.列表推导式(常用)
num=[i for i in range(10) if i%2==0]
print(num)
- 1
- 2
二者输出结果都是[0,2,4,6,8],相比之下列表推导式要简洁的多
2.字典
案例二:从一个包含学生姓名和成绩的字典中,筛选出成绩大于60的学生
首先,我们构造一个字典inf:
name=['Bob','Jim','Gin','Angel']
grade=[80,55,75,95]
inf=dict(zip(name,grade))
print(inf)
- 1
- 2
- 3
- 4
输出结果为:{‘Bob’: 80, ‘Jim’: 55, ‘Gin’: 75, ‘Angel’: 95}
以下,我们可以通过字典推导式筛选出学生成绩(大于60):
dict1={key:value for key,value in inf.items() if value>60}
print(dict1)
- 1
- 2
输出结果:{‘Bob’: 80, ‘Gin’: 75, ‘Angel’: 95}
如果你只是想要返回成绩大于60的学生名字或者分数的话,可以将dict1中的key:value部分改为key或者value即可.当然上述步骤是先建立一个字典,然后再从字典里筛选出符合特定条件的值。可不可以一步完成呢?
当然阔以~
dict2={name[i]:grade[i] for i in range(len(grade)) if grade[i]>60}
print(dict2)
- 1
- 2
输出结果也是{‘Bob’: 80, ‘Gin’: 75, ‘Angel’: 95}.不过,这里需要注意的是:如果列表name 和列表grade长度不一致的话,后面for循环中的len函数应该去长度较短的列表!
3.数据框
案例三:利用pandas从招聘信息表中筛选出特定条件的信息
首先,导入数据
import pandas as pd
df=pd.read_excel('job_information.xls',encoding='utf-8')
df
- 1
- 2
- 3
招聘信息表如下:
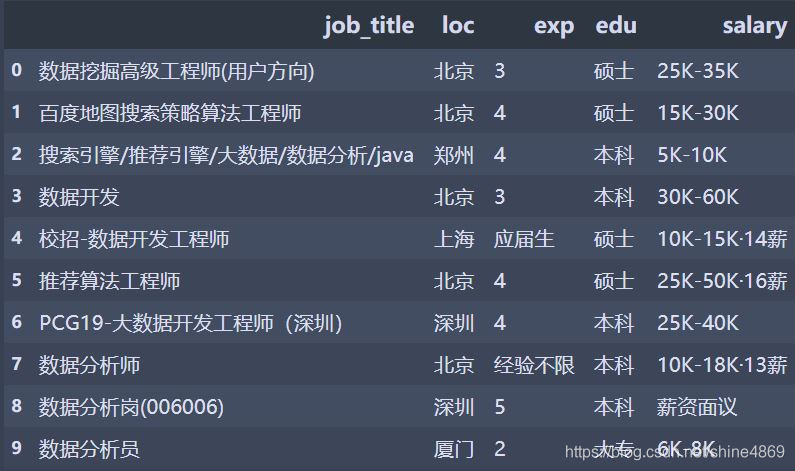
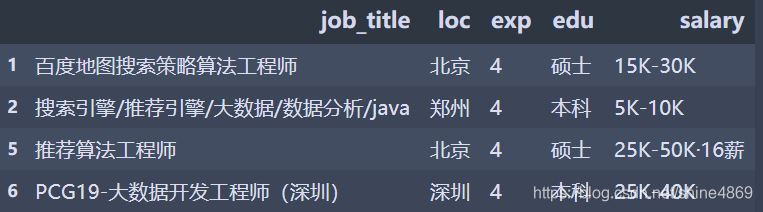
A. 筛选出工作经验(exp)为4年的招聘信息
df[df['exp'].isin([4])]
- 1
通用筛选方式:data[data[‘筛选列’].isin([num])]
需要注意的是:isin函数里筛选的num必须用[]括起来!可以是一个,也可以是多个。但只能对特定的数字进行筛选,最后筛选的结果如下:
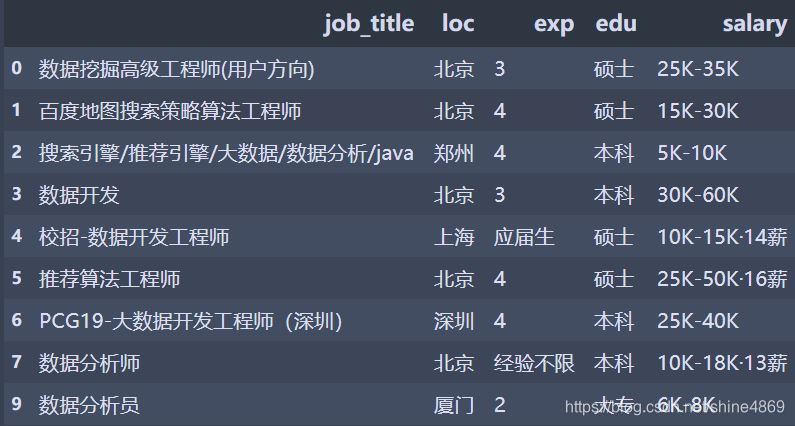
B. 筛选出具体给明的工资(salary)(过滤掉薪资面议)
df[df['salary'].str.contains('K')]
- 1
通用筛选方式:data[data[‘筛选列’].str.contains(‘特定字符’)]
需要注意的是:只能对特定的字符串进行筛选,最后筛选结果如下:
C.筛选出只含有K的工资(过滤14薪等以及薪资面议)
df[~df['salary'].str.contains('薪')]
- 1
因为这里需要过滤的字符都出现了"薪",我们依旧可以使用contains函数。需要注意的是"~“代表"非”(在对于isin函数也有用!),即排除salary中包含"薪" 这个字符的所有数据。最后,筛选结果如下:

D.筛选出含有K的工资(包括14薪等)
这里由于展示的数据样本少,该方法最终呈现的效果是和方法B是一样的。使用的方法是:apply函数+正则
def select(x):
pat='[0-9]?[0-9]K-[0-9]?[0-9]K'
rst=re.search(pat,x)
if rst:
return rst.group(0)
return 0
df['salary'].apply(select)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
需要注意的是:在使用group函数的时候,需要先判断是否可以先查到对应的值。否则会报错(NoneType object has no attribute ‘group’ )。最后筛选的结果如下:
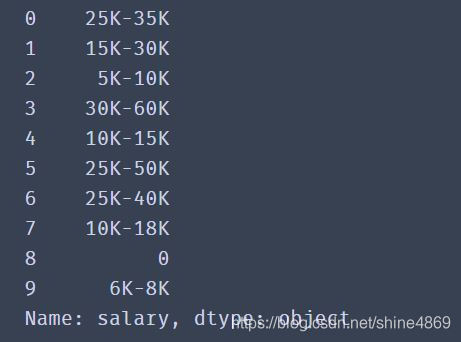
此外,还有一些筛选数据的方法如pivot_table(数据透视表),filter函数+lambda函数等,这就需要大家在实际应用的时候灵活选择。
以上就是本次分享的全部内容~

