
块是一个字节序列(例如,一个 512 字节的数据块)。基于块的存储接口是最常见的存储数据方法,它们基于旋转介质,像硬盘、 CD 、软盘、甚至传统的 9 磁道磁带。无处不在的块设备接口使虚拟块设备成为与 Ceph 这样的海量存储系统交互的理想之选。
Ceph 块设备是精简配置的、大小可调且将数据条带化存储到集群内的多个 OSD 。 Ceph 块设备利用 RADOS 的多种能力,如快照、复制和一致性。 Ceph 的 RADOS 块设备( RBD )使用内核模块或 librbd 库与 OSD 交互。

注意:内核模块可使用 Linux 页缓存。对基于 librbd 的应用程序, Ceph 可提供 RBD 缓存
Ceph 块设备靠无限伸缩性提供了高性能,如向内核模块、或向 abbr:KVM (kernel virtual machines) (如 Qemu 、 OpenStack 和 CloudStack 等云计算系统通过 libvirt 和 Qemu 可与 Ceph 块设备集成)。你可以用同一个集群同时运行 Ceph RADOS 网关、 Ceph FS 文件系统、和 Ceph 块设备。
注意:要使用 Ceph 块设备,你必须有一个在运行的 Ceph 集群。
一、块设备命令
rbd 命令可用于创建、罗列、内省和删除块设备映像,也可克隆映像、创建快照、回滚快照、查看快照等等。 rbd 命令用法详情见 RBD – 管理 RADOS 块设备映像。
Important
要使用 Ceph 块设备命令,你必须有对应集群的访问权限。
创建块设备映像
要想把块设备加入某节点,你得先在 Ceph 存储集群中创建一个映像,使用下列命令:
rbd create --size {megabytes} {pool-name}/{image-name}
例如,要在 swimmingpool 这个存储池中创建一个名为 bar 、大小为 1GB 的映像,执行:
rbd create --size 1024 swimmingpool/bar
如果创建映像时不指定存储池,它将使用默认的 rbd 存储池。例如,下面的命令将默认在 rbd 存储池中创建一个大小为 1GB 、名为 foo 的映像:
rbd create --size 1024 foo
指定此存储池前必须先创建它,详情见存储池。
罗列块设备映像
要列出 rbd 存储池中的块设备,可以用下列命令(即 rbd 是默认存储池名字):
rbd ls
用下列命令罗列某个特定存储池中的块设备,用存储池的名字替换 {poolname} :
rbd ls {poolname}
例如:
rbd ls swimmingpool
检索映像信息
用下列命令检索某个特定映像的信息,用映像名字替换 {image-name} :
rbd info {image-name}
例如:
rbd info foo
用下列命令检索某存储池内的映像的信息,用映像名字替换 {image-name} 、用存储池名字替换 {pool-name} :
rbd info {pool-name}/{image-name}
例如:
rbd info swimmingpool/bar
调整块设备映像大小
Ceph 块设备映像是精简配置,只有在你开始写入数据时它们才会占用物理空间。然而,它们都有最大容量,就是你设置的 --size 选项。如果你想增加(或减小) Ceph 块设备映像的最大尺寸,执行下列命令:
rbd resize --size 2048 foo (to increase) rbd resize --size 2048 foo --allow-shrink (to decrease)
删除块设备映像
可用下列命令删除块设备,用映像名字替换 {image-name} :
rbd rm {image-name}
例如:
rbd rm foo
用下列命令从某存储池中删除一个块设备,用要删除的映像名字替换 {image-name} 、用存储池名字替换 {pool-name} :
rbd rm {pool-name}/{image-name}
例如:
rbd rm swimmingpool/bar
二、内核模块
要用内核模块操作,必须有一个在运行的 Ceph 集群。
映射块设备
用 rbd 把映像名映射为内核模块。必须指定映像名、存储池名、和用户名。若 RBD 内核模块尚未加载, rbd 命令会自动加载。
sudo rbd map {pool-name}/{image-name} --id {user-name}
例如:
sudo rbd map rbd/myimage --id admin
如果你启用了 cephx 认证,还必须提供密钥,可以用密钥环或密钥文件指定密钥。
sudo rbd map rbd/myimage --id admin --keyring /path/to/keyring
sudo rbd map rbd/myimage --id admin --keyfile /path/to/file
三、快照
快照是映像在某个特定时间点的一份只读副本。 Ceph 块设备的一个高级特性就是你可以为映像创建快照来保留其历史。 Ceph 还支持分层快照,让你快速、简便地克隆映像(如 VM 映像)。 Ceph 的快照功能支持 rbd 命令和多种高级接口,包括 QEMU 、 libvirt 、 OpenStack 和 CloudStack 。
注意:要使用 RBD 快照功能,你必须有一个在运行的 Ceph 集群。
笔记:
如果在做快照时映像仍在进行 I/O 操作,快照可能就获取不到该映像准确的或最新的数据,并且该快照可能不得不被克隆到一个新的可挂载的映像中。
所以,我们建议在做快照前先停止 I/O 操作。如果映像内包含文件系统,在做快照前请确保文件系统处于一致的状态。
要停止 I/O 操作可以使用 fsfreeze 命令。详情可参考 fsfreeze(8) 手册页。对于虚拟机,qemu-guest-agent 被用来在做快照时自动冻结文件系统。

Cephx 注意事项
启用了 cephx 时(默认的),你必须指定用户名或 ID 、及其对应的密钥文件,详情见用户管理。你也可以用 CEPH_ARGS 环境变量来避免重复输入下列参数。
rbd --id {user-ID} --keyring=/path/to/secret [commands]
rbd --name {username} --keyring=/path/to/secret [commands]
例如:
rbd --id admin --keyring=/etc/ceph/ceph.keyring [commands]
rbd --name client.admin --keyring=/etc/ceph/ceph.keyring [commands]
注意:把用户名和密钥写入 CEPH_ARGS 环境变量,这样就无需每次手动输入。
快照基础
下列过程演示了如何用 rbd 命令创建、罗列、和删除快照。
创建快照
用 rbd 命令创建快照,要指定 snap create 选项、存储池名和映像名。
rbd snap create {pool-name}/{image-name}@{snap-name}
例如:
rbd snap create rbd/foo@snapname
rbd snap ls {pool-name}/{image-name}
例如:
rbd snap ls rbd/foo
回滚快照
用 rbd 命令回滚到某一快照,指定 snap rollback 选项、存储池名、映像名和快照名。
rbd snap rollback {pool-name}/{image-name}@{snap-name}
例如:
rbd snap rollback rbd/foo@snapname
把映像回滚到某一快照的意思是,用快照中的数据覆盖映像的当前版本,映像越大,此过程花费的时间就越长。从快照克隆要快于回滚到某快照,这也是回到先前状态的首选方法。
Ceph 支持为某一设备快照创建很多个写时复制( COW )克隆。分层快照使得 Ceph 块设备客户端可以很快地创建映像。例如,你可以创建一个包含有 Linux VM 的块设备映像;然后做快照、保护快照,再创建任意多个写时复制克隆。快照是只读的,所以简化了克隆快照的语义 —— 使得克隆很迅速。

注意:这里的术语“父”和“子”指的是一个 Ceph 块设备快照(父),和从此快照克隆出来的对应映像(子)。这些术语对下列的命令行用法来说很重要。
各个克隆出来的映像(子)都存储着对父映像的引用,这使得克隆出来的映像可以打开父映像并读取它。
一个快照的 COW 克隆和其它任何 Ceph 块设备映像的行为完全一样。克隆出的映像没有特别的限制,你可以读出、写入、克隆、调整克隆映像的大小。然而快照的写时复制克隆引用了快照,所以你克隆快照前必须保护它。下图描述了此过程。
笔记:Ceph 仅支持克隆 format 2 的映像(即用 rbd create --image-format 2 创建的)。内核客户端从 3.10 版开始支持克隆的映像。
分层入门
Ceph 块设备的分层是个简单的过程。你必须有个映像、必须为它创建快照、并且必须保护快照,执行过这些步骤后,你才能克隆快照。

克隆出的映像包含对父快照的引用,也包含存储池 ID 、映像 ID 和快照 ID 。包含存储池 ID 意味着你可以把一个存储池内的快照克隆到其他存储池。
映像模板: 块设备分层的一个常见用法是创建一个主映像及其快照,并作为模板以供克隆。例如,用户可以创建某一 Linux 发行版(如 Ubuntu 12.04 )的映像、并对其做快照。此用户可能会周期性地更新映像、并创建新的快照(如在 rbd snap create 之后执行 sudo apt-get update 、 sudo apt-get upgrade 、 sudo apt-get dist-upgrade )。当映像成熟时,用户可以克隆任意快照。 扩展模板: 更高级的用法包括扩展映像模板,来提供比基础映像更多的信息。例如,用户可以克隆一个映像(如 VM 模板)、并安装其它软件(如数据库、内容管理系统、分析系统等等),然后为此扩展映像做快照,做好的快照可以像基础映像一样进行更新。 模板存储池: 块设备分层的一种用法是创建一个存储池,存放作为模板的主映像和那些模板的快照。然后把只读权限分给用户,这样他们就可以克隆快照了,而无需分配此存储池的写和执行权限。 映像迁移/恢复: 块设备分层的一种用法是把某一存储池内的数据迁移或恢复到另一存储池。
保护快照
克隆映像要访问父快照。如果用户不小心删除了父快照,所有克隆映像都会损坏。为防止数据丢失,在克隆前必须先保护快照。
rbd snap protect {pool-name}/{image-name}@{snapshot-name}
例如:
rbd snap protect rbd/my-image@my-snapshot
你删除不了受保护的快照。
克隆快照
要克隆快照,你得指定父存储池、父映像名和快照,还有子存储池和子映像名。克隆前必须先保护快照。
rbd clone {pool-name}/{parent-image}@{snap-name} {pool-name}/{child-image-name}
例如:
rbd clone rbd/my-image@my-snapshot rbd/new-image
你可以把某个存储池中映像的快照克隆到另一存储池。例如,你可以把某一存储池中的只读映像及其快照作为模板维护,把可写克隆置于另一存储池。
取消快照保护
删除快照前,必须先取消保护。另外,你不可以删除被克隆映像引用的快照,所以在你删除快照前,必须先拍平( flatten )此快照的各个克隆。
rbd snap unprotect {pool-name}/{image-name}@{snapshot-name}
例如:
rbd snap unprotect rbd/my-image@my-snapshot
rbd children {pool-name}/{image-name}@{snapshot-name}
例如:
rbd children rbd/my-image@my-snapshot
拍平克隆映像
克隆出来的映像仍保留了对父快照的引用。要从子克隆删除这些到父快照的引用,你可以把快照的信息复制给子克隆,也就是“拍平”它。拍平克隆映像的时间随快照尺寸增大而增加。要删除快照,必须先拍平子映像。
rbd flatten {pool-name}/{image-name}
例如:
rbd flatten rbd/my-image
因为拍平的映像包含了快照的所有信息,所以拍平的映像占用的存储空间会比分层克隆要大。
四、RBD 镜像
可以在两个 Ceph 集群中异步备份 RBD images。该能力利用了 RBD image 的日志特性,以确保集群间的副本崩溃一致性。镜像功能需要在同伴集群( peer clusters )中的每一个对应的 pool 上进行配置,可设定自动备份某个存储池内的所有 images 或仅备份 images 的一个特定子集。用 rbd 命令来配置镜像功能。 rbd-mirror 守护进程负责从远端集群拉取 image 的更新,并写入本地集群的对应 image 中。
注意:
1.RBD 镜像功能需要 Ceph Jewel 或更新的发行版本。
2.要使用 RBD 镜像功能,你必须有 2 个 Ceph 集群, 每个集群都要运行 rbd-mirror 守护进程。
存储池配置
下面的程序说明了如何执行一些基本的管理工作,来用 rbd 命令配置镜像功能。镜像功能是在 Ceph 集群内的存储池级别上配置的。
配置存储池的步骤需要在 2 个同伴集群内都执行一遍。为清楚起见,下面的步骤假定这两个集群分别叫做“本地(local)”和“远端(remote)”,而且单主机对这 2 个集群都拥有访问权。
如何连接不同的 Ceph 集群,详情可参考 rbd 手册页。
在下面的例子中,集群名称和 Ceph 配置文件的名称相同(比如 /etc/ceph/remote.conf)。可参考 ceph-conf 文档来配置多集群环境。
启用镜像功能
使用 rbd 启用某个存储池的镜像功能,需要指定 mirror pool enable 命令,存储池名和镜像模式:
rbd mirror pool enable {pool-name} {mode}
镜像模式可以是 pool 或 image:
pool:当设定为 pool 模式,存储池中所有开启了日志特性的 images 都会被备份。
image:当设定为 image 模式,需要对每个 image 显式启用镜像功能。
例如:
rbd --cluster local mirror pool enable image-pool pool
rbd --cluster remote mirror pool enable image-pool pool
禁用镜像功能
使用 rbd 禁用某个存储池的镜像功能,需要指定 mirror pool disable 命令和存储池名:
rbd mirror pool disable {pool-name}
当采用这种方式禁用某个存储池的镜像功能时,存储池内的任一个 image 的镜像功能也会被禁用,即使曾显式启用过。
例如: rbd --cluster local mirror pool disable image-pool rbd --cluster remote mirror pool disable image-pool
添加同伴集群
为了使 rbd-mirror 守护进程发现它的同伴集群,需要向存储池注册。使用 rbd 添加同伴 Ceph 集群,需要指定 mirror pool peer add 命令、存储池名和集群说明:
rbd mirror pool peer add {pool-name} {client-name}@{cluster-name}
例如:
rbd --cluster local mirror pool peer add image-pool client.remote@remote
rbd --cluster remote mirror pool peer add image-pool client.local@local
移除同伴集群
使用 rbd 移除同伴 Ceph 集群,指定 mirror pool peer remove 命令、存储池名和同伴的 UUID(可通过 rbd mirror pool info 命令获取):
rbd mirror pool peer remove {pool-name} {peer-uuid}
例如:
rbd --cluster local mirror pool peer remove image-pool 55672766-c02b-4729-8567-f13a66893445
rbd --cluster remote mirror pool peer remove image-pool 60c0e299-b38f-4234-91f6-eed0a367be08
Image 配置
不同于存储池配置,image 配置只需针对单个 Ceph 集群操作。
镜像 RBD image 被指定为主镜像或者副镜像。这是 image 而非存储池的特性。被指定为副镜像的 image 不能被修改。
当一个 image 首次启用镜像功能时(存储池的镜像模式设为 pool 且启用了该 image 的日志特性,或者通过 rbd 命令显式启用),它会自动晋升为主镜像。
启用 Image 的日志支持
RBD 镜像功能使用了 RBD 日志特性,来保证 image 副本间的崩溃一致性。在备份 image 到另一个同伴集群前,必须启用日志特性。该特性可在使用 rbd 命令创建 image 时通过指定 --image-feature exclusive-lock,journaling 选项来启用。
或者,可以动态启用已有 image 的日志特性。使用 rbd 开启日志特性,需要指定 feature enable 命令,存储池名,image 名和特性名:
rbd feature enable {pool-name}/{image-name} {feature-name}
例如:
rbd --cluster local feature enable image-pool/image-1 journaling
注意:
1.日志特性依赖于独占锁(exclusive-lock)特性。如果没有启用独占锁,则必须在启用日志特性之前先启用独占锁。
2.你可以通过在 Ceph 配置文件中增加 rbd default features = 125 ,使得所有新建 image 默认启用日志特性。
启用 Image 镜像功能
如果把某个存储池的镜像功能配置为 image 模式,还需要对存储池中的每一个 image ,明确启用镜像功能。通过 rbd 启用某个特定 image 的镜像功能,要指定 mirror image enable 命令、存储池名和 image 名:
rbd mirror image enable {pool-name}/{image-name}
例如:
rbd --cluster local mirror image enable image-pool/image-1
禁用 Image 镜像功能
通过 rbd 禁用某个特定 image 的镜像功能,要指定 mirror image disable 命令、存储池名和 image 名:
rbd mirror image disable {pool-name}/{image-name}
例如:
rbd --cluster local mirror image disable image-pool/image-1
Image 的升级与降级
在需要把主名称转移到同伴 Ceph 集群这样一个故障切换场景中,应该停止所有对主 image 的访问(比如关闭 VM 的电源或移除 VM 的相关驱动),当前的主 image 降级为副,原副 image 升级为主,然后在备份集群上恢复对该 image 访问。
Note
RBD 仅提供了一些必要的工具来帮助 image 有序的故障切换。还需要一种外部机制来协调整个故障切换流程(比如在降级之前关闭 image)。
通过 rbd 降级主 image,需要指定 mirror image demote 命令、存储池名和 image 名:
rbd mirror image demote {pool-name}/{image-name}
例如:
rbd --cluster local mirror image demote image-pool/image-1
通过 rbd 升级副 image,需要指定 mirror image promote 命令、存储池名和 image 名:
rbd mirror image promote {pool-name}/{image-name}
例如:
rbd --cluster remote mirror image promote image-pool/image-1
注意:
1.由于主 / 副状态是对于每个 image 而言的,故可以让两个集群拆分 IO 负载来进行故障切换 / 故障自动恢复。
2.可以使用 --force 选项来强制升级。当降级要求不能被正确传播到同伴 Ceph 集群的时候(比如 Ceph 集群故障,通信中断),就需要强制升级。这会导致两个集群间的脑裂,而且在调用强制重新同步命令之前,image 将不会自动同步。
强制 Image 重新同步
如果 rbd-daemon 探测到了脑裂事件,它在此情况得到纠正之前,是不会尝试去备份受到影响的 image。为了恢复对 image 的镜像备份,首先判定降级 image 已经过时,然后向主 image 请求重新同步。 通过 rbd 重新同步 image,需要指定 mirror image resync 命令、存储池名和 image 名:
rbd mirror image resync {pool-name}/{image-name}
例如:
rbd mirror image resync image-pool/image-1
此条 rbd 命令仅标记了某 image 需要重新同步。本地集群的 rbd-mirror 守护进程会异步实施真正的重新同步过程。
rbd-mirror 守护进程
有两个 rbd-mirror 守护进程负责监控远端同伴集群的 image 日志,并针对本地集群进行日志重放。RBD image 日志特性会按发生的顺序记录下对该 image 的所有修改。这保证了远端 image 的崩溃一致性镜像在本地是可用的。
通过安装可选发行包 rbd-mirror 来获取 rbd-mirror 守护进程。
每一个 rbd-mirror 守护进程需要同时连接本地和远程集群。
每个 Ceph 集群只能运行一个 rbd-mirror 守护进程。将来的 Ceph 发行版将会支持对 rbd-mirror 守护进程进行水平扩展
五、QEMU
Ceph 块设备最常见的用法之一是作为虚拟机的块设备映像。例如,用户可创建一个安装、配置好了操作系统和相关软件的“黄金标准”映像,然后对此映像做快照,最后再克隆此快照(通常很多次)。详情参见快照。能制作快照的写时复制克隆意味着 Ceph 可以快速地为虚拟机提供块设备映像,因为客户端每次启动一个新虚拟机时不必下载整个映像。

注意:
1.Ceph 块设备可以和 QEMU 虚拟机集成到一起,关于 QEMU 可参考 QEMU 开源处理器仿真器,其文档可参考 QEMU 手册。关于如何安装见安装。
2.要让 QEMU 使用 Ceph 块设备,你必须有个运行着的 Ceph 集群。
用法
QEMU 命令行要求你指定 存储池名和映像名,还可以指定快照名。
QEMU 会假设 Ceph 配置文件位于默认位置(如 /etc/ceph/$cluster.conf ),并且你是以默认的 client.admin 用户执行命令,除非你另外指定了其它 Ceph 配置文件路径或用户。指定用户时, QEMU 只需要 ID 部分,无需完整地指定 TYPE:ID ,详情见`用户管理——用户`_。不要在用户 ID 前面加客户端类型(即 client. ),否则会认证失败。还应该把 admin 用户、或者你用 :id={user} 选项所指定用户的密钥文件保存到默认路径(即 /etc/ceph )或本地目录内,并修正密钥环文件的所有权和权限。命令格式如下:
qemu-img {command} [options] rbd:{pool-name}/{image-name}[@snapshot-name][:option1=value1][:option2=value2...]
例如,应该这样指定 id 和 conf 选项:
qemu-img {command} [options] rbd:glance-pool/maipo:id=glance:conf=/etc/ceph/ceph.conf
注意:配置中的值如果包含这些字符: : 、 @ 、 = ,可在此符号前加反斜线 \ 转义。
用 QEMU 创建映像
你可以用 QEMU 创建块设备映像。必须指定 rbd 、存储池名、要创建的映像名以及映像尺寸。
qemu-img create -f raw rbd:{pool-name}/{image-name} {size}
例如:
qemu-img create -f raw rbd:data/foo 10G
注意:raw 数据格式是使用 RBD 时的唯一可用 format 选项。从技术上讲,你可以使用 QEMU 支持的其他格式(例如 qcow2 或 vmdk),但是这样做可能会带来额外开销,而且在开启缓存(见下)模式下进行虚拟机的热迁移时会导致卷的不安全性。
qemu-img resize rbd:{pool-name}/{image-name} {size}
例如:
qemu-img resize rbd:data/foo 10G
qemu-img info rbd:{pool-name}/{image-name}
例如:
qemu-img info rbd:data/foo
通过 RBD 运行 QEMU
QEMU 能把一主机上的块设备传递给客户机,但从 QEMU 0.15 起,不需要在主机上把映像映射为块设备了。 QEMU 现在能通过 librbd 直接把映像作为虚拟块设备访问。这样性能更好,因为它避免了额外的上下文切换,而且能利用开启 RBD 缓存带来的好处。
你可以用 qemu-img 把已有的虚拟机映像转换为 Ceph 块设备映像。比如你有一个 qcow2 映像,可以这样转换:
qemu-img convert -f qcow2 -O raw debian_squeeze.qcow2 rbd:data/squeeze
要从那个映像启动虚拟机,执行:
qemu -m 1024 -drive format=raw,file=rbd:data/squeeze
启用 RBD 缓存可显著提升性能。从 QEMU 1.2 起, QEMU 的缓存选项可控制 librbd 缓存:
qemu -m 1024 -drive format=rbd,file=rbd:data/squeeze,cache=writeback
如果你的 QEMU 版本较老,你可以用 ‘file’ 参数更改 librbd 缓存配置(就像其它 Ceph 配置选项一样):
qemu -m 1024 -drive format=raw,file=rbd:data/squeeze:rbd_cache=true,cache=writeback
注意:如果你设置了 rbd_cache=true ,那就必须设置 cache=writeback, 否则有可能丢失数据。不设置 cache=writeback , QEMU 就不会向 librbd 发送回写请求。如果 QEMU 退出时未清理干净, rbd 之上的文件系统就有可能崩溃。
启用 Discard/TRIM 功能
从 Ceph 0.46 和 QEMU 1.1 起, Ceph 块设备支持 discard 操作。这意味着客户机可以发送 TRIM 请求来让 Ceph 块设备回收未使用的空间。此功能可在客户机上挂载 ext4 或 XFS 时加上 discard 选项。
客户机要想使用此功能,必须对块设备显式启用。为此,你必须在相关驱动器上指定 discard_granularity :
qemu -m 1024 -drive format=raw,file=rbd:data/squeeze,id=drive1,if=none \ -device driver=ide-hd,drive=drive1,discard_granularity=512
注意此处使用 IDE 驱动器, virtio 驱动不支持 discard 。
如果用的是 libvirt ,需要用 virsh edit 编辑配置文件,加上 xmlns:qemu 值。然后加一个 qemu:commandline 块作为那个域的子域。下例展示了如何用 qemu id= 为两个设备设置不同的 discard_granularity 值。
<domain type='kvm' xmlns:qemu='http://libvirt.org/schemas/domain/qemu/1.0'> <qemu:commandline> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-0.discard_granularity=4096'/> <qemu:arg value='-set'/> <qemu:arg value='block.scsi0-0-1.discard_granularity=65536'/> </qemu:commandline> </domain>
QEMU 缓存选项
QEMU 的缓存选项对应下列的 Ceph RBD 缓存选项。
回写:
rbd_cache = true
透写:
rbd_cache = true rbd_cache_max_dirty = 0
无:
rbd_cache = false
QEMU 的缓存选项会覆盖 Ceph 的默认选项(就是那些 Ceph 配置文件里没有的选项)。如果你在 Ceph 配置文件内设置了 RBD 缓存选项,那么它们会覆盖 QEMU 缓存选项。如果你在 QEMU 命令行中设置了缓存选项,它们则会覆盖 Ceph 配置文件里的选项。
六、libvirt
libvirt 库是管理程序和软件应用间的一个虚拟机抽象层。通过 libvirt ,开发者和系统管理员只需要关注这些管理器的一个通用管理框架、通用 API 、和通用 shell 接口(即 virsh )即可,包括:
QEMU/KVM
XEN
LXC
VirtualBox
等等
Ceph 块设备支持 QEMU/KVM ,所以你可以通过能与 libvirt 交互的软件来使用 Ceph 块设备。下面的堆栈图解释了 libvirt 和 QEMU 如何通过 librbd 使用 Ceph 块设备。
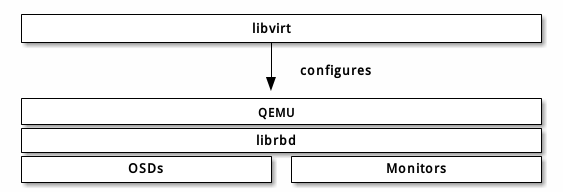
libvirt 常见于为云解决方案提供 Ceph 块设备,像 OpenStack 、 ClouldStack 。它们用 libvirt 和 QEMU/KVM 交互、 QEMU/KVM 再通过 librbd 与 Ceph 块设备交互。详情见块设备与 OpenStack 和块设备与 CloudStack 。关于如何安装见安装。
你也可以通过 libvirt 、 virsh 和 libvirt API 使用 Ceph 块设备,详情见 libvirt 虚拟化 API 。
要创建使用 Ceph 块设备的虚拟机,请参照下文中的步骤。在示范性实施例中,我们用 libvirt-pool 作为存储池名、 client.libvirt 作为用户名、 new-libvirt-image 作为映像名。你可以任意命名,但请确保在后续过程中用自己的名字替换掉对应名字。
配置 Ceph
配置 Ceph 用于 libvirt ,执行下列步骤:
1.创建——存储池(或者用默认的)。本例用 libvirt-pool 作存储池名,设定了 128 个归置组。
ceph osd pool create libvirt-pool 128 128
验证存储池是否存在。
ceph osd lspools
2.创建—— Ceph 用户( 0.9.7 及之前的版本用 client.admin ),本例用 client.libvirt 、且权限限制到 libvirt-pool 。
ceph auth get-or-create client.libvirt mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=libvirt-pool'
验证名字是否存在。
ceph auth list
注:libvirt 访问 Ceph 时将用 libvirt 作为 ID ,而不是 client.libvirt 。关于 ID 和名字不同之处的详细解释请参考用户管理——用户和用户管理——命令行界面。
3.用 QEMU 在 RBD 存储池中创建映像。本例中映像名为 new-libvirt-image 、存储池为 libvirt-pool 。
qemu-img create -f rbd rbd:libvirt-pool/new-libvirt-image 2G
验证映像是否存在。
rbd -p libvirt-pool ls
注:你也可以用 rbd create 创建映像,但我们建议使用示例中的命令,来顺便确认 QEMU 可正常运行。
新建虚拟机
要用 virt-manager 创建 VM ,请按下列步骤:
1.点击 Create New Virtual Machine 按钮。
2.命名新虚拟机的域,本例中我们用 libvirt-virtual-machine 。你可以任意命名,但请在后续命令行和配置实例中替换 libvirt-virtual-machine 为你自己选择的名字。
libvirt-virtual-machine
3.导入映像。
/path/to/image/recent-linux.img
注:请导入一个较新的映像。一些较老的映像未必能正确地重扫虚拟设备。
4.配置并启动 VM 。
5.可以用 virsh list 验证 VM 域是否存在。
sudo virsh list
6.登入 VM ( root/root )
7.在修改配置让它使用 Ceph 前,请先停止 VM 。
配置 VM
配置 VM 使用 Ceph 时,切记尽量用 virsh 。另外, virsh 命令通常需要 root 权限(如 sudo ),否则不会返回正确结果或提示你需要 root 权限。 virsh 命令参考见 Virsh 命令参考。
1.用 virsh edit 打开配置文件。
sudo virsh edit {vm-domain-name}
<devices> 下应该有 <disk> 条目。
<devices>
<emulator>/usr/bin/kvm</emulator>
<disk type='file' device='disk'>
<driver name='qemu' type='raw'/>
<source file='/path/to/image/recent-linux.img'/>
<target dev='vda' bus='virtio'/>
<address type='drive' controller='0' bus='0' unit='0'/>
</disk>
用你的 OS 映像路径替换 /path/to/image/recent-linux.img 。使用较快的 virtio 总线的最低内核版本是 2.6.25 ,参见 Virtio 。
重要:要用 sudo virsh edit 而非文本编辑器,如果你用文本编辑器编辑了 /etc/libvirt/qemu 下的配置文件, libvirt 未必能识别出这些更改。如果 /etc/libvirt/qemu 下的 XML 文件和 sudo virsh dumpxml {vm-domain-name} 输出结果内容不同, VM 可能会运行异常。
2.把你创建的 Ceph RBD 映像创建为 <disk> 条目。
<disk type='network' device='disk'> <source protocol='rbd' name='libvirt-pool/new-libvirt-image'> <host name='{monitor-host}' port='6789'/> </source> <target dev='vda' bus='virtio'/> </disk>
用你的主机名替换 {monitor-host} ,可能还要替换存储池和/或映像名。你可以为 Ceph monitor 添加多条 <host> , dev 属性是将出现在 VM /dev 目录下的逻辑设备名。可选的 bus 属性是要模拟的磁盘类型,有效的设定值是驱动类型,如 ide 、 scsi 、 virtio 、 xen 、 usb 或 sata 。关于 <disk> 标签及其子标签和属性,详见硬盘。
3.保存文件。
4.如果你的 Ceph 存储集群启用了 Ceph 认证(默认已启用),那么必须生成一个 secret。
cat > secret.xml <<EOF <secret ephemeral='no' private='no'> <usage type='ceph'> <name>client.libvirt secret</name> </usage> </secret> EOF
5.定义 secret。
sudo virsh secret-define --file secret.xml
<uuid of secret is output here>
6.获取 client.libvirt 密钥并把字符串保存于文件。
ceph auth get-key client.libvirt | sudo tee client.libvirt.key
7.设置 secret 的 UUID 。
sudo virsh secret-set-value --secret {uuid of secret} --base64 $(cat client.libvirt.key) && rm client.libvirt.key secret.xml
还必须手动设置 secret,把下面的 <auth> 条目添加到前面的 <disk> 标签内(用上一命令的输出结果替换掉 uuid 值)。
sudo virsh edit {vm-domain-name}
然后,把 <auth></auth> 标签加进域配置文件:
... </source> <auth username='libvirt'> <secret type='ceph' uuid='9ec59067-fdbc-a6c0-03ff-df165c0587b8'/> </auth> <target ...
注:示例 ID 是 libvirt ,不是第 2 步配置 Ceph 生成的 Ceph 名 client.libvirt 。确保你用的是 Ceph 名的 ID 部分。如果出于某些原因你需要更换 secret,必须先执行 sudo virsh secret-undefine {uuid} ,然后再执行 sudo virsh secret-set-value 。
总结
一旦完成上面的配置,你就可以启动 VM 了。为确认 VM 和 Ceph 在通信,你可以执行如下过程。
1.检查 Ceph 是否在运行:
ceph health
2.检查 VM 是否在运行。
sudo virsh list
3.检查 VM 是否在和 Ceph 通信,用你的 VM 域名字替换 {vm-domain-name} :
sudo virsh qemu-monitor-command --hmp {vm-domain-name} 'info block'
4.检查一下 <target dev='hdb' bus='ide'/> 定义的设备是否出现在 /dev 或 /proc/partitions 里。
ls dev
cat proc/partitions
如果看起来一切正常,你就可以在虚拟机内使用 Ceph 块设备了。
七、Openstack
通过 libvirt 你可以把 Ceph 块设备用于 OpenStack ,它配置了 QEMU 到 librbd 的接口。 Ceph 把块设备映像条带化为对象并分布到集群中,这意味着大容量的 Ceph 块设备映像其性能会比独立服务器更好。
要把 Ceph 块设备用于 OpenStack ,必须先安装 QEMU 、 libvirt 和 OpenStack 。我们建议用一台独立的物理主机安装 OpenStack ,此主机最少需 8GB 内存和一个 4 核 CPU 。下面的图表描述了 OpenStack/Ceph 技术栈。

注意:要让 OpenStack 使用 Ceph 块设备,你必须有相应的 Ceph 集群访问权限。
OpenStack 里有三个地方可以和 Ceph 块设备结合:
Images: OpenStack 的 Glance 管理着 VM 的 image 。Image 相对恒定, OpenStack 把它们当作二进制文件、并以此格式下载。 Volumes: Volume 是块设备, OpenStack 用它们引导虚拟机、或挂载到运行中的虚拟机上。 OpenStack 用 Cinder 服务管理 Volumes 。 Guest Disks: Guest disks 是装有客户操作系统的磁盘。默认情况下,启动一台虚拟机时,
它的系统盘表现为 hypervisor 文件系统的一个文件(通常位于 /var/lib/nova/instances/<uuid>/)。
在 Openstack Havana 版本前,在 Ceph 中启动虚拟机的唯一方式是使用 Cinder 的 boot-from-volume 功能.
不过,现在能够在 Ceph 中直接启动虚拟机而不用依赖于 Cinder,这一点是十分有益的,因为可以通过热迁移更方便地进行维护操作。
另外,如果你的 hypervisor 挂掉了,也可以很方便地触发 nova evacuate ,并且几乎可以无缝迁移虚拟机到其他地方。
你可以用 OpenStack Glance 把 image 存储到 Ceph 块设备中,还可以使用 Cinder 通过 image 的写时复制克隆来启动虚拟机。
下面将详细指导你配置 Glance 、 Cinder 和 Nova ,虽然它们不一定一起用。你可以在本地硬盘上运行 VM 、却把 image 存储于 Ceph 块设备,反之亦可。
注意:Ceph 不支持 QCOW2 格式的虚拟机磁盘,所以,如果想要在 Ceph 中启动虚拟机( 临时后端或者从卷启动),Glance 镜像必须是 RAW 格式。
创建存储池
默认情况下, Ceph 块设备使用 rbd 存储池。你可以用任何可用存储池。建议为 Cinder 和 Glance 单独创建池。确保 Ceph 集群在运行,然后创建存储池。
ceph osd pool create volumes 128 ceph osd pool create images 128 ceph osd pool create backups 128 ceph osd pool create vms 128
参考创建存储池为存储池指定归置组数量,参考归置组确定应该为存储池设定多少归置组。
配置 OpenStack 的 Ceph 客户端
运行着 glance-api 、 cinder-volume 、 nova-compute 或 cinder-backup 的主机被当作 Ceph 客户端,它们都需要 ceph.conf 文件。
ssh {your-openstack-server} sudo tee /etc/ceph/ceph.conf </etc/ceph/ceph.conf
安装 Ceph 客户端软件包
在运行 glance-api 的节点上你需要 librbd 的 Python 绑定:
sudo yum install python-rbd
在 nova-compute 、 cinder-backup 和 cinder-volume 节点上,要安装 Python 绑定和客户端命令行工具:
sudo yum install ceph
配置 Ceph 客户端认证
如果你启用了 cephx 认证,需要分别为 Nova/Cinder 和 Glance 创建新用户。命令如下:
ceph auth get-or-create client.cinder mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=volumes, allow rwx pool=vms, allow rx pool=images' ceph auth get-or-create client.glance mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=images' ceph auth get-or-create client.cinder-backup mon 'allow r' osd 'allow class-read object_prefix rbd_children, allow rwx pool=backups'
把 client.cinder 、 client.glance 和 client.cinder-backup 的密钥环复制到适当的节点,并更改所有权:
ceph auth get-or-create client.glance | ssh {your-glance-api-server} sudo tee /etc/ceph/ceph.client.glance.keyring ssh {your-glance-api-server} sudo chown glance:glance /etc/ceph/ceph.client.glance.keyring ceph auth get-or-create client.cinder | ssh {your-volume-server} sudo tee /etc/ceph/ceph.client.cinder.keyring ssh {your-cinder-volume-server} sudo chown cinder:cinder /etc/ceph/ceph.client.cinder.keyring ceph auth get-or-create client.cinder-backup | ssh {your-cinder-backup-server} sudo tee /etc/ceph/ceph.client.cinder-backup.keyring ssh {your-cinder-backup-server} sudo chown cinder:cinder /etc/ceph/ceph.client.cinder-backup.keyring
运行 nova-compute 的节点,其进程需要密钥环文件:
ceph auth get-or-create client.cinder | ssh {your-nova-compute-server} sudo tee /etc/ceph/ceph.client.cinder.keyring
还得把 client.cinder 用户的密钥存进 libvirt 。 libvirt 进程从 Cinder 挂载块设备时要用它访问集群。
在运行 nova-compute 的节点上创建一个密钥的临时副本:
ceph auth get-key client.cinder | ssh {your-compute-node} tee client.cinder.key
然后,在计算节点上把密钥加进 libvirt 、然后删除临时副本:
uuidgen 457eb676-33da-42ec-9a8c-9293d545c337 cat > secret.xml <<EOF <secret ephemeral='no' private='no'> <uuid>457eb676-33da-42ec-9a8c-9293d545c337</uuid> <usage type='ceph'> <name>client.cinder secret</name> </usage> </secret> EOF sudo virsh secret-define --file secret.xml Secret 457eb676-33da-42ec-9a8c-9293d545c337 created sudo virsh secret-set-value --secret 457eb676-33da-42ec-9a8c-9293d545c337 --base64 $(cat client.cinder.key) && rm client.cinder.key secret.xml
保留密钥的 uuid ,稍后配置 nova-compute 时要用。
注意:所有计算节点上的 UUID 不一定非要一样。但考虑到平台的一致性, 最好使用同一个 UUID 。
配置 OpenStack 使用 Ceph
配置 Glance
Glance 可使用多种后端存储 image 。要让它默认使用 Ceph 块设备,按如下配置 Glance 。
Juno 之前的版本
编辑 /etc/glance/glance-api.conf 并把下列内容加到 [DEFAULT] 段下:
default_store = rbd rbd_store_user = glance rbd_store_pool = images rbd_store_chunk_size = 8
Juno 版
编辑 /etc/glance/glance-api.conf 并把下列内容加到 [glance_store] 段下:
[DEFAULT] ... default_store = rbd ... [glance_store] stores = rbd rbd_store_pool = images rbd_store_user = glance rbd_store_ceph_conf = /etc/ceph/ceph.conf rbd_store_chunk_size = 8
关于 Glance 里可用的其它配置选项见 http://docs.openstack.org/trunk/config-reference/content/section_glance-api.conf.html。
注意:Glance 还没完全迁移到 ‘store’ ,所以我们还得在 DEFAULT 段下配置 store 。
任意版 OpenStack
如果你想允许使用 image 的写时复制克隆,再添加下列内容到 [DEFAULT] 段下:
show_image_direct_url = True
注意,这会通过 Glance API 暴露后端存储位置,所以此选项启用时 endpoint 不应该被公开访问。
禁用 Glance 缓存管理,以免 image 被缓存到 /var/lib/glance/image-cache/ 下,假设你的配置文件里有 flavor = keystone+cachemanagement :
[paste_deploy]
flavor = keystone
Image 属性
建议配置如下 image 属性:
hw_scsi_model=virtio-scsi: 添加 virtio-scsi 控制器以获得更好的性能、并支持 discard 操作; hw_disk_bus=scsi: 把所有 cinder 块设备都连到这个控制器; hw_qemu_guest_agent=yes: 启用 QEMU guest agent (访客代理) os_require_quiesce=yes: 通过 QEMU guest agent 发送 fs-freeze/thaw 调用
配置 Cinder
OpenStack 需要一个驱动和 Ceph 块设备交互。还得指定块设备所在的存储池名。编辑 OpenStack 节点上的 /etc/cinder/cinder.conf ,添加:
[DEFAULT] ... enabled_backends = ceph ... [ceph] volume_driver = cinder.volume.drivers.rbd.RBDDriver rbd_pool = volumes rbd_ceph_conf = /etc/ceph/ceph.conf rbd_flatten_volume_from_snapshot = false rbd_max_clone_depth = 5 rbd_store_chunk_size = 4 rados_connect_timeout = -1 glance_api_version = 2
如果你使用了 cephx 认证,还需要配置用户及其密钥(前述文档中存进了 libvirt )的 uuid :
[ceph] ... rbd_user = cinder rbd_secret_uuid = 457eb676-33da-42ec-9a8c-9293d545c337
注意如果你为 cinder 配置了多后端, [DEFAULT] 节中必须有 glance_api_version = 2 。
配置 Cinder Backup
OpenStack 的 Cinder Backup 需要一个特定的守护进程,不要忘记安装它。编辑 Cinder Backup 节点的 /etc/cinder/cinder.conf 添加:
backup_driver = cinder.backup.drivers.ceph backup_ceph_conf = /etc/ceph/ceph.conf backup_ceph_user = cinder-backup backup_ceph_chunk_size = 134217728 backup_ceph_pool = backups backup_ceph_stripe_unit = 0 backup_ceph_stripe_count = 0 restore_discard_excess_bytes = true
配置 Nova 来挂载 Ceph RBD 块设备
为了挂载 Cinder 块设备(块设备或者启动卷),必须告诉 Nova 挂载设备时使用的用户和 uuid 。libvirt会使用该用户来和 Ceph 集群进行连接和认证。
rbd_user = cinder
rbd_secret_uuid = 457eb676-33da-42ec-9a8c-9293d545c337
这两个标志同样用于 Nova 的临时后端。
配置 Nova
要让所有虚拟机直接从 Ceph 启动,必须配置 Nova 的临时后端。
建议在 Ceph 配置文件里启用 RBD 缓存(从 Giant 起默认启用)。另外,启用管理套接字对于故障排查来说大有好处,给每个使用 Ceph 块设备的虚拟机分配一个套接字有助于调查性能和/或异常行为。
可以这样访问套接字:
ceph daemon /var/run/ceph/ceph-client.cinder.19195.32310016.asok help
编辑所有计算节点上的 Ceph 配置文件:
[client] rbd cache = true rbd cache writethrough until flush = true admin socket = /var/run/ceph/guests/$cluster-$type.$id.$pid.$cctid.asok log file = /var/log/qemu/qemu-guest-$pid.log rbd concurrent management ops = 20
调整这些路径的权限:
mkdir -p /var/run/ceph/guests/ /var/log/qemu/ chown qemu:libvirtd /var/run/ceph/guests /var/log/qemu/
要注意, qemu 用户和 libvirtd 组可能因系统不同而不同,前面的实例基于 RedHat 风格的系统。
注意:如果你的虚拟机已经跑起来了,重启一下就能得到套接字。
Havana and Icehouse
Havana 和 Icehouse 需要补丁来实现写时复制克隆、修复 rbd 临时磁盘的镜像大小和热迁移中的缺陷。这些补丁可从基于 Nova stable/havana 和 stable/icehouse 的分支中获取。虽不是强制性的,但**强烈建议**使用这些补丁,以便能充分利用写时复制克隆功能的优势。
编辑所有计算节点上的 /etc/nova/nova.conf 文件,添加:
libvirt_images_type = rbd libvirt_images_rbd_pool = vms libvirt_images_rbd_ceph_conf = /etc/ceph/ceph.conf libvirt_disk_cachemodes="network=writeback" rbd_user = cinder rbd_secret_uuid = 457eb676-33da-42ec-9a8c-9293d545c337
禁用文件注入也是一个好习惯。启动一个实例时, Nova 通常试图打开虚拟机的根文件系统。然后, Nova 会把比如密码、 ssh 密钥等值注入到文件系统中。然而,最好依赖元数据服务和 cloud-init 。
编辑所有计算节点上的 /etc/nova/nova.conf 文件,添加:
libvirt_inject_password = false libvirt_inject_key = false libvirt_inject_partition = -2
为确保热迁移能顺利进行,要使用如下标志:
libvirt_live_migration_flag="VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE,VIR_MIGRATE_PERSIST_DEST,VIR_MIGRATE_TUNNELLED"
Juno
在 Juno 版中, Ceph 块设备移到了 [libvirt] 段下。编辑所有计算节点上的 /etc/nova/nova.conf 文件,在 [libvirt] 段下添加:
[libvirt] images_type = rbd images_rbd_pool = vms images_rbd_ceph_conf = /etc/ceph/ceph.conf rbd_user = cinder rbd_secret_uuid = 457eb676-33da-42ec-9a8c-9293d545c337 disk_cachemodes="network=writeback"
禁用文件注入也是一个好习惯。启动一个实例时, Nova 通常试图打开虚拟机的根文件系统。然后, Nova 会把比如密码、 ssh 密钥等值注入到文件系统中。然而,最好依赖元数据服务和 cloud-init 。
编辑所有计算节点上的 /etc/nova/nova.conf 文件,在 [libvirt] 段下添加:
inject_password = false inject_key = false inject_partition = -2
为确保热迁移能顺利进行,要使用如下标志(在 [libvirt] 段下):
live_migration_flag="VIR_MIGRATE_UNDEFINE_SOURCE,VIR_MIGRATE_PEER2PEER,VIR_MIGRATE_LIVE,VIR_MIGRATE_PERSIST_DEST,VIR_MIGRATE_TUNNELLED"
Kilo
为虚拟机的临时根磁盘启用 discard 功能:
[libvirt]
...
...
hw_disk_discard = unmap # 启用 discard 功能(注意性能)
重启 OpenStack
在基于 Red Hat 的系统上执行:
sudo service openstack-glance-api restart sudo service openstack-nova-compute restart sudo service openstack-cinder-volume restart sudo service openstack-cinder-backup restart
一旦 OpenStack 启动并运行正常,应该就可以创建卷并用它启动虚拟机了。
从块设备引导
你可以用 Cinder 命令行工具从弄个 image 创建卷:
cinder create --image-id {id of image} --display-name {name of volume} {size of volume}
注意 image 必须是 RAW 格式,你可以用 qemu-img 转换格式,如:
qemu-img convert -f {source-format} -O {output-format} {source-filename} {output-filename}
qemu-img convert -f qcow2 -O raw precise-cloudimg.img precise-cloudimg.raw
Glance 和 Cinder 都使用 Ceph 块设备,此镜像又是个写时复制克隆,就能非常快地创建一个新卷。在 OpenStack 操作面板里就能从那个启动虚拟机,步骤如下:
启动新实例。 选择与写时复制克隆关联的 image 。 选择 ‘boot from volume’ 。 选择你刚创建的卷。

