
- 1HarmonyOS官网案例解析——保存应用数据_华为harmonyos官网案例代码
- 2【Linux操作系统】——基础知识题集1_linux的内核版本2.3.20
- 3【ARK UI】HarmonyOS 如何实现新闻列表_harmony开发新闻页面
- 4Android界月老Intent详解_什么是android中的intent,运用场景是什么
- 5HarmonyOS系统架构_鸿蒙架构
- 6linux arm mmu基础
- 7鸿蒙系统ArkTs语法入门_鸿蒙开发基础语法学习
- 8Android Studio 如何使用真机调试 ( 华为 )_华为手机 android studio 真机调试
- 9SSM总结(一)
- 10时间序列预测的8种常用方法简介_时间序列预测方法
stable diffusion中的u net_stablediffusion u2net
赞
踩
Stable Diffusion 包含几个核心的组件:
- 一个文本编码器(在 Stable Diffusion 中使用 CLIP 的 ViT-L/14 的文本编码器),用于将用户输入的 Prompt 文本转化成 text embedding;
- 一个 Image Auto Encoder-Decoder,用于将 Image 编码成隐含向量
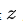 ,或者从隐含向量
,或者从隐含向量 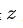 中还原出图片;
中还原出图片; - 一个 UNET 结构,使用 UNET 进行迭代降噪,在文本引导下进行多轮预测,将随机高斯噪声
 转化成图片隐含向量
转化成图片隐含向量 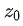 。
。
这三个部分是相互独立的,其中最重要的是 UNET 结构。UNET 是从噪音中生成图像的主要组件,在预测过程中,通过反复调用 UNET,将 UNET 预测输出的 noise slice 从原有的噪声中去除,得到逐步去噪后的图像表示。Stable Diffusion Model 的 UNET 包含约 860M 的参数,以 float32 的精度编码大概需要 3.4G 的存储空间。整个 UNET 的如下图所示:
Stable Diffusion Unet 结构
图中列出了 UNET 的核心组件和各组件的参数数量。其中主要的组件包括:
ResnetBlock
左下角小图展示了 ResnetBlock 的结构。Resnet 接受两个输入:latent 向量,和 timestep_embedding。latent 向量经过卷积变换后和经过全连接投影的 timestep_embedding 做加和,再和经过 skip connection 的原始 latent 向量做加和,送入另一个卷积层,得到经 Resnet 编码变换后的 latent 输出。
注意左侧的 ResnetBlock 和右侧的 ResnetBlock 的细微不同。左侧的 Resnet Block 接受的 latent 向量从 UNET 的上一层传入,而右侧的 ResnetBlock 除了接受 UNET 上一层的结果 latent 外,还需要接受左侧对应的 UNET 层的输出,两个 latent concat 起来作为 输入。所以,如果右侧的 ResnetBlock 上层的输出结果 shape 为 (64, 64, 320),左侧对应 UNET 层的输出结果为 (64, 64, 640),那么这个 ResnetBlock 得到的输入 latent 的 shape 为 (64, 64, 960)。
Spatial Transformer(Cross Attention)
右下角小图展示了 Spatial Transformer 的结构。Spatial Transformer 同样接受两个输入:经过上一个网络模块(一般为 ResnetBlock)处理和变换后的 latent 向量,及对应的 context embedding(文本 prompt 经过 CLIP 编码后的输出)。latent 向量对应的是是图片 token,和 context embedding 做 cross attention 之后,得到变换后的 latent 向量(通过注意力机制,将 token 对应的语义信息注入到模型认为应该影响的图片 patch 中)。 Spatial Transformer 输出的 shape 和输出的 shape 保持一致,但在对应的位置上融合了语义信息。
DownSample/UpSample
DownSample 将 latent 向量的前两个轴的大小缩减 50%,而 UpSample 将 latent 向量的前两个轴的大小增大一倍。DownSample 使用一个步长为 2 的二维卷积来实现,同时将输入 latent 向量的 channel 数变化成输出 latent 向量的 channel 数;而 UpSample 使用插值算法来实现,在插值之后进行一个步长为 1 的卷积,同时通过一个步长为 1 的二维卷积来将输入 latent 向量的 channel 数变化成输出 latent 向量的 channel 数。
需要注意的是,在整个 UNET 执行一次的过程中,timestep_embedding 和 content embedding 始终保持不变。而在 UNET 反复执行多次的过程中,timestep_embedding 每次都会发生变化,而 content embedding 始终保持不变。在迭代过程中,每次 UNET 输出的 noise_slice 都原有的 latent 向量相减,作为下次迭代时,UNET 的 Latent 输入。

