
- 1Android 将Activity以对话框(Dialog)形式显示
- 2The engine “node“ is incompatible with this module. Expected version问题解决_the engine "node" is incompatible with this module
- 3【单片机】STM32单片机频率计程序,外部脉冲计数程序,基于脉冲计数的频率计程序,STM32F103_stm32频率计
- 4智能营销模型-Uplift Model详解及Python使用
- 5基于vue.js求职招聘系统设计与实现(uni-app框架+PHP后台) 研究背景和意义、国内外现状_uniapp的现状
- 6【jieba分词】中文分词工具jieba_jieba 的常用user_dict.txt 下载
- 7【12】Git工具 协同工作平台使用教程 Gitee使用指南 腾讯工蜂使用指南【Gitee】【腾讯工蜂】【Git】
- 8spring security oauth2 使用说明_oauth2authorizedclientservice
- 9老大让我整理下公司内部mysql使用规范,分享给大家
- 10利用Foxit SDK快速实现自己的Mobile PDF阅读器-iOS 篇_ios pdf reader 源码
LlamaIndex使用指南_llamaindex怎么扩展token上限
赞
踩
点击上方“Deephub Imba”,关注公众号,好文章不错过 !
LlamaIndex是一个方便的工具,它充当自定义数据和大型语言模型(llm)(如GPT-4)之间的桥梁,大型语言模型模型功能强大,能够理解类似人类的文本。LlamaIndex都可以轻松地将数据与这些智能机器进行对话。这种桥梁建设使你的数据更易于访问,为更智能的应用程序和工作流铺平了道路。

LlamaIndex最初被称为GPT Index, 后来大语言模型的快速发展,改名为LlamaIndex。它就像一个多功能的工具,可以在处理数据和大型语言模型的各个阶段提供帮助
首先,它有助于“摄取”数据,这意味着将数据从原始来源获取到系统中。其次,它有助于“结构化”数据,这意味着以语言模型易于理解的方式组织数据。第三,它有助于“检索”,这意味着在需要时查找和获取正确的数据。最后,它简化了“集成”,使您更容易将数据与各种应用程序框架融合在一起。
LlamaIndex里有什么
LlamaIndex是可以作为定制数据上创建由大型语言模型(llm)支持的健壮应用程序的首选平台。无论是复杂的问答系统、交互式聊天机器人还是智能代理,LlamaIndex都可以使用检索增强生成(RAG)提供良好的基础组件。
知识库(输入):知识库就像一个图书馆,里面装满了有用的信息,如faq、手册和其他相关文档。当有人提出问题时,系统就会在这里寻找答案。
触发/查询(输入):它是来自客户的一个问题或请求,向系统发出信号,使其立即采取行动。这
任务/动作(输出):在理解触发器或查询后,系统执行特定的任务来处理它。例如,如果它是一个问题,系统将提供答案,或者如果它是一个特定操作的请求,它将相应地执行该操作。
我们将需要使用Llamaindex实现以下两个阶段,以向我们的RAG机制提供两个输入-
索引阶段:准备知识库。
查询阶段:利用知识库和LLM通过生成最终输出/执行最终任务来响应查询。
让我们在LlamaIndex的框架下仔细看看这些阶段。
1、索引阶段:制作知识库
LlamaIndex为提供了一套工具来创建知识库:
数据连接器:这些实体(也称为reader)将来自不同来源和格式的数据摄取到统一的Document表示中。
文档/节点:文档是数据的容器,无论它来自PDF、API还是数据库。Node是Document的一个片段,丰富了元数据和关系,为精确的检索操作铺平了道路。
数据索引:在获取数据后,LlamaIndex将数据整理成可检索的格式。这个过程包括解析、嵌入和元数据推理,并最终导致知识库的创建。
2、询问阶段:运用你的知识
在此阶段,根据查询从知识库中获取相关上下文,并将其与LLM的见解混合以生成响应。这不仅为LLM提供了最新的相关知识,也防止了幻觉。这里的核心挑战围绕着跨多个知识库的检索、编排和推理展开。
LlamaIndex提供模块化结构来将其用于问答、聊天机器人或代理驱动的应用程序。
以下是LlamaIndex的组成
查询引擎:这些是端到端的管道,用于查询数据、接受自然语言查询并返回响应以及引用的上下文。
聊天引擎:它们将交互提升到会话级别,允许与数据进行来回交流。
代理:代理是自动决策制定者,通过工具包与世界进行交互,并通过动态的行动计划而不是固定的逻辑来完成任务。
检索器:它们规定了根据查询从知识库中获取相关上下文的技术。例如,针对向量索引的密集检索是一种流行的方法。
节点后处理器:它们通过转换、过滤或重新排序来细化节点集。
响应合成器:它们引导LLM生成响应,将用户查询与检索的文本块混合在一起。
在使用LlamaIndex时,以上这些组件是我们需要使用的基本组件。
安装和设置
如果您熟悉Python,使用以下命令安装:
pip install llama-index
- 1
默认情况下,LlamaIndex使用OpenAI的gpt-3.5 turbo来创建文本,并使用text- embedting -ada-002来获取和嵌入文本。所以这里需要一个OpenAI API Key来使用这些。在OpenAI的网站上注册即可免费获得API密钥。然后在python文件中以OPENAI_API_KEY的名称设置环境变量。
importos
os.environ["OPENAI_API_KEY"] ="your_api_key"
- 1
- 2
如果你不想使用OpenAI,也可以使用LlamaCPP和llama2-chat-13B来创建文本,使用BAAI/ big -small-en来获取和嵌入。这些模型都可以离线工作。要设置LlamaCPP,请按照Llamaindex的官方文档进行设置。这将需要大约11.5GB的CPU和GPU内存。要使用本地嵌入,需要安装这个库:
pip install sentence-transformers
- 1
创建Llamaindex文档
数据连接器(也称为reader)是LlamaIndex中的重要组件,它有助于从各种来源和格式摄取数据,并将其转换为由文本和基本元数据组成的简化文档表示形式。
fromllama_indeximportdownload_loader
GoogleDocsReader=download_loader('GoogleDocsReader')
loader=GoogleDocsReader()
documents=loader.load_data(document_ids=[...])
- 1
- 2
- 3
- 4
- 5
LlamaIndex提供了的各种数据连接器包括:
SimpleDirectoryReader:支持本地文件目录中的多种文件类型(.pdf, .jpg, .png, .docx等)。
NotionPageReader:从Notion获取数据。
lackReader:从Slack导入数据。
ApifyActor:能够抓取网页,抓取,文本提取和文件下载。
如何找到正确的数据连接器?
首先查找并检查Llamaindex文档中是否列出了相关的数据连接器,如果没有,可以访问Llamahub,看看是否有现成的连接器

例如:
PDF文件:可以使用SimpleDirectoryReader数据连接器。下面的示例加载BCG年度可持续发展报告。

维基百科页面:Llamahub 也有相关的连接器可以直接使用。

创建LlamaIndex节点
在LlamaIndex中,一旦数据被摄取并表示为文档,就可以选择将这些文档进一步处理为节点。节点是更细粒度的数据实体,表示源文档的“块”,可以是文本块、图像或其他类型的数据。它们还携带元数据和与其他节点的关系信息,这有助于构建更加结构化和关系型的索引。
为了将文档解析为节点,LlamaIndex提供了NodeParser类。这些类有助于自动地将文档的内容转换为节点,遵循一个特定的结构,可以在索引构造和查询中进一步利用。
下面是如何使用SimpleNodeParser将文档解析为节点:
fromllama_index.node_parserimportSimpleNodeParser
# Assuming documents have already been loaded
# Initialize the parser
parser=SimpleNodeParser.from_defaults(chunk_size=1024, chunk_overlap=20)
# Parse documents into nodes
nodes=parser.get_nodes_from_documents(documents)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
在这个代码片段中,SimpleNodeParser.from_defaults()用默认设置初始化一个解析器,get_nodes_from_documents(documents)用于将加载的文档解析为节点。
参数选项包括:
text_splitter(默认:TokenTextSplitter)
include_metadata(默认值:True)
include_prev_next_rel(默认值:True)
metadata_extractor(默认值:无)
在定义好节点后,会根据需要将节点的文本通过文本分割器拆分成token,这里可以使用llama_index.text_splitter中的senencesplitter、TokenTextSplitter或CodeSplitter。例子:
SentenceSplitter:
importtiktoken
fromllama_index.text_splitterimportSentenceSplitter
text_splitter=SentenceSplitter(
separator=" ", chunk_size=1024, chunk_overlap=20,
paragraph_separator="\n\n\n", secondary_chunking_regex="[^,.;。]+[,.;。]?",
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser=SimpleNodeParser.from_defaults(text_splitter=text_splitter)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
TokenTextSplitter:
importtiktoken
fromllama_index.text_splitterimportTokenTextSplitter
text_splitter=TokenTextSplitter(
separator=" ", chunk_size=1024, chunk_overlap=20,
backup_separators=["\n"],
tokenizer=tiktoken.encoding_for_model("gpt-3.5-turbo").encode
)
node_parser=SimpleNodeParser.from_defaults(text_splitter=text_splitter)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
CodeSplitter:
fromllama_index.text_splitterimportCodeSplitter
text_splitter=CodeSplitter(
language="python", chunk_lines=40, chunk_lines_overlap=15, max_chars=1500,
)
node_parser=SimpleNodeParser.from_defaults(text_splitter=text_splitter)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
对于特定的范围嵌入,还需要使用SentenceWindowNodeParser将文档拆分为单独的句子,同时捕获周围的句子窗口。
importnltk
fromllama_index.node_parserimportSentenceWindowNodeParser
node_parser=SentenceWindowNodeParser.from_defaults(
window_size=3, window_metadata_key="window", original_text_metadata_key="original_sentence"
)
- 1
- 2
- 3
- 4
- 5
- 6
为了获得更多控制,也可以使用手动创建Node对象并定义属性和关系:
fromllama_index.schemaimportTextNode, NodeRelationship, RelatedNodeInfo
# Create TextNode objects
node1=TextNode(text="<text_chunk>", id_="<node_id>")
node2=TextNode(text="<text_chunk>", id_="<node_id>")
# Define node relationships
node1.relationships[NodeRelationship.NEXT] =RelatedNodeInfo(node_id=node2.node_id)
node2.relationships[NodeRelationship.PREVIOUS] =RelatedNodeInfo(node_id=node1.node_id)
# Gather nodes
nodes= [node1, node2]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
上面的代码中,TextNode创建带有文本内容的节点,而noderrelationship和RelatedNodeInfo定义节点关系。
下面我们为已经创建的PDF和Wikipedia页面文档创建基本节点。

用节点和文档创建索引
LlamaIndex的核心本质在于它能够在被摄取的数据上构建结构化索引,这些数据表示为文档或节点。这种索引有助于对数据进行有效的查询。让我们深入研究如何使用Document和Node对象构建索引,以及在此过程中会发生什么。
下面是如何使用VectorStoreIndex从文档中直接创建索引:
fromllama_indeximportVectorStoreIndex
# Assuming docs is your list of Document objects
index=VectorStoreIndex.from_documents(docs)
- 1
- 2
- 3
- 4
LlamaIndex中不同类型的索引以不同的方式处理数据:
Summary Index :将节点存储为一个顺序链,在查询期间,如果没有指定其他查询参数,则将所有节点加载到Response Synthesis模块中。
Vector Store Index:将每个节点和相应的嵌入存储在Vector Store中,查询涉及获取top-k最相似的节点。
Tree Index:从一组节点构建层次树,查询涉及从根节点向下遍历到叶节点。
Keyword Table Index:从每个Node中提取关键字构建映射,查询提取相关关键字获取对应的Node。
具体使用索引,请详细查看官方文芳并根据用例做出选择。
使用下面代码为PDF文件创建一个索引。

我们也可以直接从Node对象中创建索引,然后将文档解析为Node或手动创建Node:
fromllama_indeximportVectorStoreIndex
# Assuming nodes is your list of Node objects
index=VectorStoreIndex(nodes)
- 1
- 2
- 3
- 4
下面我们为维基百科节点创建一个摘要索引。

存储索引
LlamaIndex可以为所以提供多种存储方式,可以根据不同的需要进行选择。
1、基本方法
LlamaIndex使用persist()方法可以存储数据,使用load_index_from_storage()方法可以毫不费力地检索数据。
# Persisting to disk
index.storage_context.persist(persist_dir="<persist_dir>")
# Loading from disk
fromllama_indeximportStorageContext, load_index_from_storage
storage_context=StorageContext.from_defaults(persist_dir="<persist_dir>")
index=load_index_from_storage(storage_context)
- 1
- 2
- 3
- 4
- 5
- 6
- 7

2、存储组件(高级)
LlamaIndex提供了可定制的存储组件,允许用户指定存储各种数据元素的位置。这些组成部分包括:
Document Stores:用于存储表示为Node对象的摄取文档的存储库。
Index Stores:保存索引元数据的地方。
Vector Stores:用于存放嵌入向量的存储器。
LlamaIndex在存储后端支持方面是通用的,已确认支持:
本地文件系统、AWS S3、Cloudflare R2等
这些后端通过使用fsspec库得就进行访问,因为该库支持各种存储后端。
创建或重新加载索引的示例如下:
# build a new index
fromllama_indeximportVectorStoreIndex, StorageContext
fromllama_index.vector_storesimportDeepLakeVectorStore
vector_store=DeepLakeVectorStore(dataset_path="<dataset_path>")
storage_context=StorageContext.from_defaults(vector_store=vector_store)
index=VectorStoreIndex.from_documents(documents, storage_context=storage_context)
# reload an existing index
index=VectorStoreIndex.from_vector_store(vector_store=vector_store)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
为了利用存储抽象,需要定义一个StorageContext对象:
fromllama_index.storage.docstoreimportSimpleDocumentStore
fromllama_index.storage.index_storeimportSimpleIndexStore
fromllama_index.vector_storesimportSimpleVectorStore
fromllama_index.storageimportStorageContext
storage_context=StorageContext.from_defaults(
docstore=SimpleDocumentStore(),
vector_store=SimpleVectorStore(),
index_store=SimpleIndexStore(),
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
使用索引查询数据
在使用LlamaIndex建立了结构良好的索引之后,下一个关键步骤是查询该索引,本文的这一部分将说明查询LlamaIndex中索引的数据的过程和方法。
1、高级查询API
LlamaIndex提供了一个高级API,可以简化简单的查询,非常适合常见的用例。
# Assuming 'index' is your constructed index object
query_engine=index.as_query_engine()
response=query_engine.query("your_query")
print(response)
- 1
- 2
- 3
- 4
在这种简单的方法中,使用as_query_engine()方法从索引创建查询引擎,使用query()方法执行查询。
我们可以在PDF索引上试一下

默认情况下,index.as_query_engine()使用LlamaIndex中指定的默认设置创建查询引擎。
可以根据用例从官方的列表中选择自己的查询引擎,并使用它来查询索引,查询引擎很多,这里就不列举了

如果我们使用子问题查询引擎来解决多个数据源回答复杂查询的问题。它首先将复杂的查询分解为每个相关数据源的子问题,然后收集所有中间响应并合成最终响应。我们以Wikipedia为例:
import nest_asyncio from llama_index import VectorStoreIndex, SimpleDirectoryReader from llama_index.tools import QueryEngineTool, ToolMetadata from llama_index.query_engine import SubQuestionQueryEngine from llama_index.callbacks import CallbackManager, LlamaDebugHandler from llama_index import ServiceContext nest_asyncio.apply() # We are using the LlamaDebugHandler to print the trace of the sub questions captured by the SUB_QUESTION callback event type llama_debug = LlamaDebugHandler(print_trace_on_end=True) callback_manager = CallbackManager([llama_debug]) service_context = ServiceContext.from_defaults( callback_manager=callback_manager )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
创建一个基本的矢量索引和子问题查询引擎。

然后查询问题获得最终响应。

可以看到,在查询引擎的内部,问题被分成了3个子问题,然后返回给我们最终的结果。引擎给出的最终可以打印出来。

2、低级组合API
对于更细粒度的控制或高级查询场景,可以使用低级组合API,它可以在查询过程的各个阶段进行定制。
Retrievers
Retrievers模块规定了针对查询从知识库获取相关上下文的技术。也有很多的官方实现方法,请查看官方文档

节点后处理程序
在查询输出后,可以通过后处理程序转换、过滤或重新排序来细化节点集。LlamaIndex后置处理器包括:
SimilarityPostprocessor:使用similarity_cutoff设置阈值。移除低于某个相似度分数的节点。
KeywordNodePostprocessor:使用required_keywords和exclude_keywords。根据关键字包含或排除过滤节点。
MetadataReplacementPostProcessor:用其元数据中的数据替换节点内容。
LongContextReorder:重新排序节点,这有利于需要大量顶级结果的情况,可以解决模型在扩展上下文中的困难
SentenceEmbeddingOptimizer:选择percentile_cutoff或threshold_cutoff作为相关性。基于嵌入删除不相关的句子。
CohereRerank:使用coherence ReRank对节点重新排序,返回前N个结果。
SentenceTransformerRerank:使用SentenceTransformer交叉编码器对节点重新排序,产生前N个节点
LLMRerank:使用LLM对节点重新排序,为每个节点提供相关性评分。
FixedRecencyPostprocessor:返回按日期排序的节点。
EmbeddingRecencyPostprocessor:按日期对节点进行排序,但也会根据嵌入相似度删除较旧的相似节点。
TimeWeightedPostprocessor:对节点重新排序,偏向于最近未返回的信息。
PIINodePostprocessor(β):可以利用本地LLM或NER模型删除个人身份信息。
PrevNextNodePostprocessor(β):根据节点关系,按顺序检索在节点之前、之后或两者同时出现的节点。
以上是一些常用的后处理程序,官网还有很多其他的模块。
合成响应器
合成相应器引导LLM生成响应,将用户查询与检索到的文本块混合在一起。
响应合成器可能听起来很奇特,但它们实际上是根据问题和一些给定的文本数据生成回复或答案的工具。
假设有一堆文本(就像一堆书)。现在,你问了一个问题,并希望根据这些文本得到答案。响应合成器就像图书管理员一样,浏览文本,找到相关信息,并生成回复。
把查询引擎中的整个过程想象成一条工厂线:
机器根据问题提取出相关的文本片段。我们已经讨论过了(Retrievers)。如果需要的话,还有一个步骤可以对这些部分进行微调(节点后处理程序)。最后,响应合成器将这些片段收集起来,并给出一个精心设计的答案。
响应合成器也有多种选择
Refine:这种方法遍历每一段文本,一点一点地精炼答案。
Compact:是Refine的精简版。它将文本集中在一起,因此需要处理的步骤更少。
Tree Summarize:想象一下,把许多小的答案结合起来,再总结,直到你得到一个主要的答案。
Simple Summarize::只是把文本片段剪短,然后给出一个快速的总结。
No Text:这个问题不会给你答案,但会告诉你它会使用哪些文本。
Accumulate:为每一篇文章找一堆小答案,然后把它们粘在一起。
Compact Accumulate:是“Compact”和“Accumulate”的合成词。
如果上面都满足不了需求,也可以建立自定义合成器。任何合成器的主要工作都是接受一个问题和一些文本片段,并返回一串文本作为答案。
下面是每个响应合成器应该具有的基本结构。他们应该能够接受一个问题和部分文本,然后给出答案。
classBaseSynthesizer(ABC): """Response builder class.""" def__init__( self, service_context: Optional[ServiceContext] =None, streaming: bool=False, ) ->None: """Init params.""" self._service_context=service_contextorServiceContext.from_defaults() self._callback_manager=self._service_context.callback_manager self._streaming=streaming @abstractmethod defget_response( self, query_str: str, text_chunks: Sequence[str], **response_kwargs: Any, ) ->RESPONSE_TEXT_TYPE: """Get response.""" ... @abstractmethod asyncdefaget_response( self, query_str: str, text_chunks: Sequence[str], **response_kwargs: Any, ) ->RESPONSE_TEXT_TYPE: """Get response asynchronously.""" ...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
解析响应
对于我们的查询,会返回一个Response对象,其中包含响应文本和响应源。
response=query_engine.query("<query_str>")
# Get response
print(str(response))
# Get sources
print(response.source_nodes)
print(response.get_formatted_sources())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
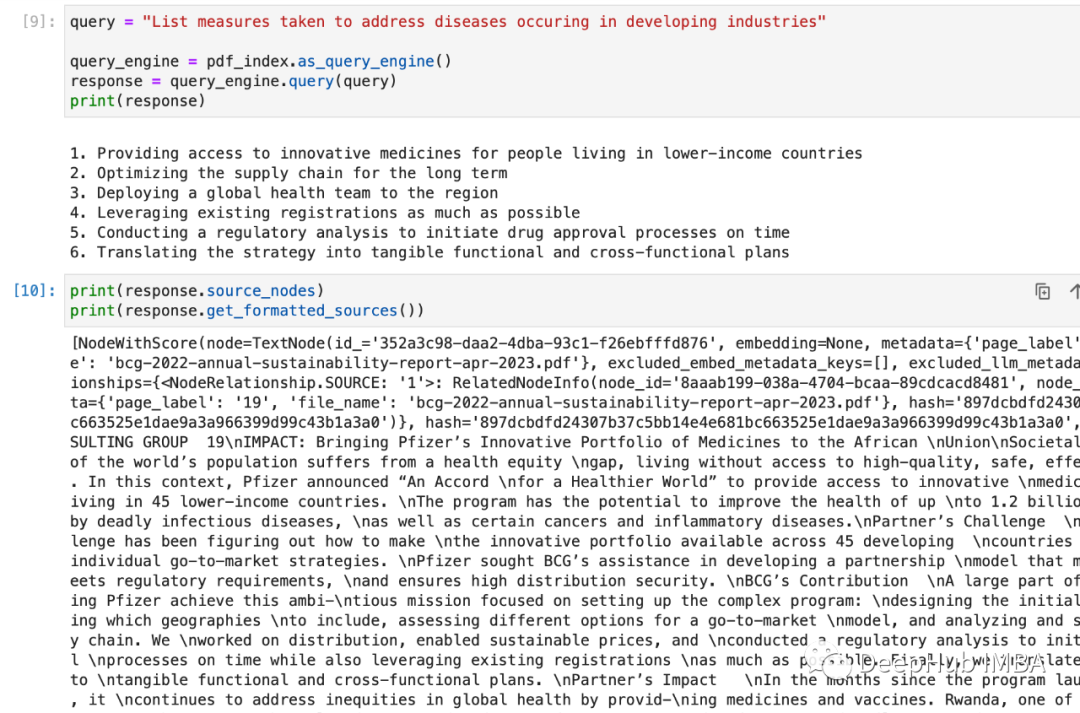
完整的结构包含了详细检查查询输出和响应的来源,我们可以根据自定义的需求自行解析使用。
结构化输出
结构化数据对于工作流程至关重要。LlamaIndex利用大型语言模型(llm)的功能来交付结构化结果。
结构化结果不仅仅是一种花哨的数据呈现方式;它们对于依赖于解析值的精度和固定结构的应用程序至关重要。
llm可以通过两种方式提供结构化的输出:
1、Pydantic Programs
使用函数调用api,可以获得自然结构化的结果,然后使用Pydantic Programs将其塑造成所需的格式。LlamaIndex提供了现成的Pydantic程序,可以将某些输入更改为特定的输出类型,如数据表。
让我们使用Pydantic Programs文档从维基百科的非结构化文章中提取关于这些国家的结构化数据。
我们创建pydantic输出对象-

然后使用wikipedia文档对象创建索引。

最后启动查询引擎并指定Pydantic输出类。

检索这三个国家的信息。

响应对象如下。

2、输出解析器
LlamaIndex的输出解析器可以在LLM执行任务之前和之后指导它,确保最终结果与所需的结构保持一致。输出解析器在生成最终响应之前充当看门人。他们在法学硕士文本回复之前确保一切正常。
我们导入LangChain输出解析器。

定义结构化LLM和响应格式,如文档中所示。

使用上面定义的response_schemas定义输出解析器及其查询模板。
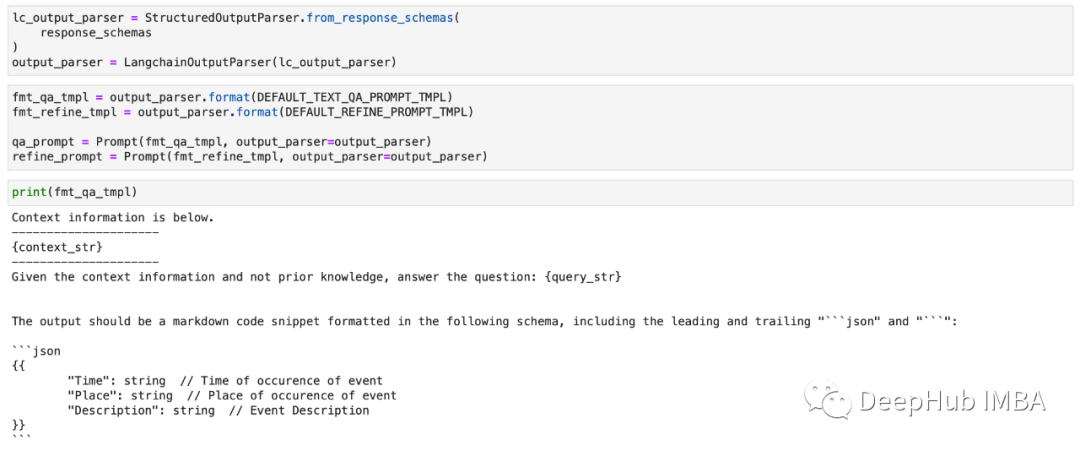
定义查询引擎,并在创建查询引擎时将结构化输出解析器模板传递给它。

现在运行任何查询都会获取结构化json输出!
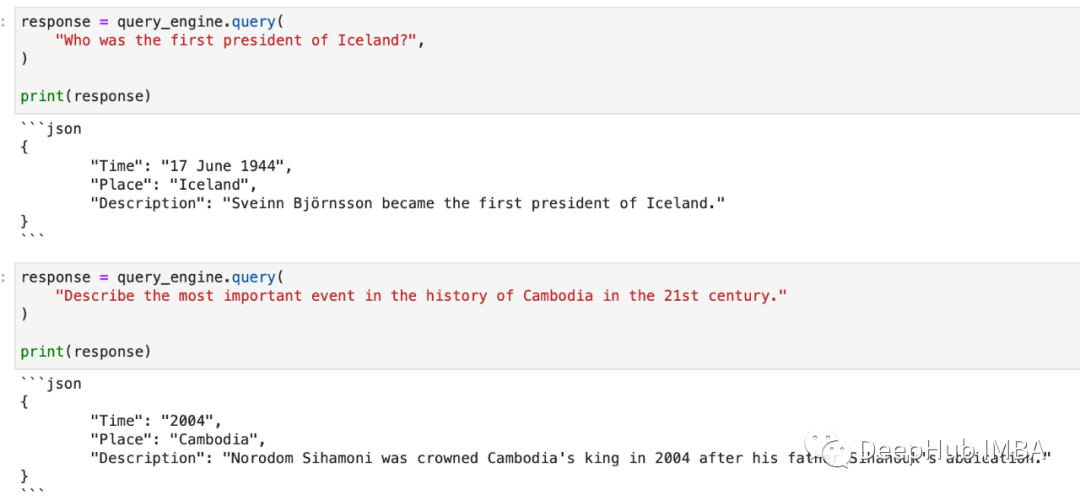
结构化输出使解析和下游处理变得轻而易举
使用案例:与数据聊天
LlamaIndex中的数据代理由大语言模型(llm)提供支持,充当数据的智能知识工作者,执行“读”和“写”操作。它们自动搜索和检索不同的数据类型(非结构化、半结构化和结构化)。与我们的查询引擎只从静态数据源“读取”不同,数据代理可以动态地摄取、修改数据,并跨各种工具与数据交互。它们可以调用外部服务api,处理返回的数据,并将其存储以供将来参考。
数据代理的两个组成部分是:
推理循环:指示代理的决策过程,决定使用哪些工具、它们的顺序,以及基于输入任务的每个工具调用的参数。
工具抽象:代理与一组api或工具交互以获取信息或改变状态。
推理循环的类型取决于agent;支持的类型包括OpenAI Function代理和ReAct代理(可以在任何聊天/文本完成端点上操作)。
以下是如何使用基于OpenAI函数api的数据代理:
fromllama_index.agentimportOpenAIAgent
fromllama_index.llmsimportOpenAI
...# import and define tools
llm=OpenAI(model="gpt-3.5-turbo-0613")
agent=OpenAIAgent.from_tools(tools, llm=llm, verbose=True)
- 1
- 2
- 3
- 4
- 5
我们使用LlamaHub中提供的代码解释器工具,通过给出自然语言指令来直接编写和执行代码。我们将使用Spotify数据集(这是一个csv文件),并通过让我们的代理执行python代码来读取和操作pandas中的数据来执行数据分析。
我们首先导入工具。

我们开始聊天

我们首先要求它获取列的列表。代理执行python代码并使用pandas读取列名。

然后要求它绘制一个loudness 与“speechiness”的图表,并将其保存在output.png文件中,所有这些都是通过与我们的代理聊天完成的,我们没有写任何代码。

得到的图如下:

要进行一些简单的分析工作也可以

总结
LlamaIndex是一个很好的工具,可以将数据(无论其格式如何)与LLM联系起来,并利用他们的能力与数据进行交互。我们已经看到了如何在数据和应用程序中使用自然语言来生成响应/执行任务。
对于企业来说,在企业应用程序中使用LlamaIndex可能会带来一些问题
虽然LlamaHub是一个很好的存储库,可以找到各种各样的数据连接器,但这个列表仍然不够详尽,并且没有提供与一些主要工作空间应用程序的连接。
调整LlamaIndex管道的每个元素(检索器、合成器、索引等等)的配置是一个繁琐的过程。最重要的是为给定的数据集和任务确定最佳管道是耗时的,而且并不总是直观的。
每个任务都需要一个独特的实现。没有一站式的解决方案可以将您的数据与llm连接起来。
LlamaIndex通过数据连接器获取静态数据,这些数据不会随着流入源数据库的新数据而更新。
但是无论如何LlamaIndex都是一个很好的库,如果你希望在大型语言模型有更深入的研究 LlamaIndex都值得你学习和使用。
https://avoid.overfit.cn/post/76ecdfe53b4d40099642be017ede68ef

