
- 12、golang开发工具VScode安装配置_vscode golang
- 2python爬虫实战——抖音
- 3返回路径平面上的间隙_整整100条!使信号完整性问题最小化的设计原则(超级干货)...
- 4BZOJ刷题集_bzoj 题目和数据
- 5人工智能版 Photoshop 2024 测试版 ,创成式填充(生成式AI填充也是正正意义上的人工智能AI修图)功能使用教程_ps2024ai功能在哪
- 6C语言(循环)单元练习
- 7基于SSM的个人健康饮食管理小程序系统源码_私人健康管家小程序代码
- 8curl (7) Failed connect to localhost8080; Connection refused_curl: (7) failed connect to localhost:8080; connec
- 9力扣大厂热门面试算法题 27-29
- 102024年您应该知道的 12个绝佳且免费的 AI 工具_目前有哪些免费的ai搜索
AIBigKaldi(十)| Kaldi的thchs30实例(源码解析)_data_thchs30
赞
踩
本文来自公众号“AI大道理”。
这里既有AI,又有生活大道理,无数渺小的思考填满了一生。
单音子模型的假设是一个音素的实际发音与其左右的音素无关。
这个假设与实际并不符合。
由于单音子模型过于简单,识别结果不能达到最好,因此需要继续优化升级。
就此引入多音子的模型。
最为熟悉的就是三音子模型,即上下文相关的声学模型。
在YesNo实例中没有进行三音子的模型训练。
因此我们转向thchs30这个实例。
 0 总过程
0 总过程
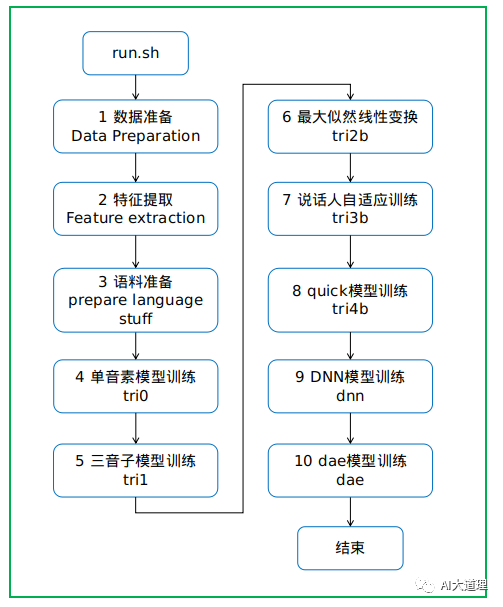
1 数据准备
先下载thchs30数据集,然后进行数据准备。
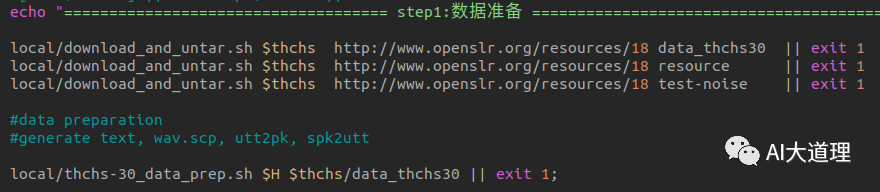
1.1 download_and_untar.sh
功能:
下载数据。
源码解析:
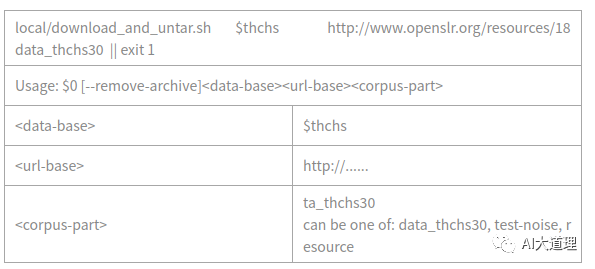
在egs/thchs30/s5下新建了一个文件夹thchs30-openslr,然后把三个文件解压在了该文件夹下。
这个数据集包含以下内容:

1.2 thchs-30_data_prep.sh
功能:
进入thchs30-openslr/data_thchs30/train、dev、test目录,它读取语料库并得到wav.scp和音标,生成文本text,wav.scp,uut3pk,spk2utt。
源码解析:

mkdir -p data/{train,dev,test} # 创建data目录。
在这三个目录下生成文件。
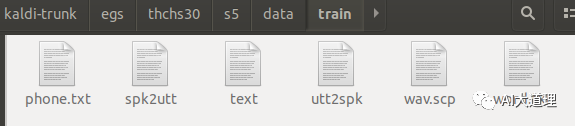
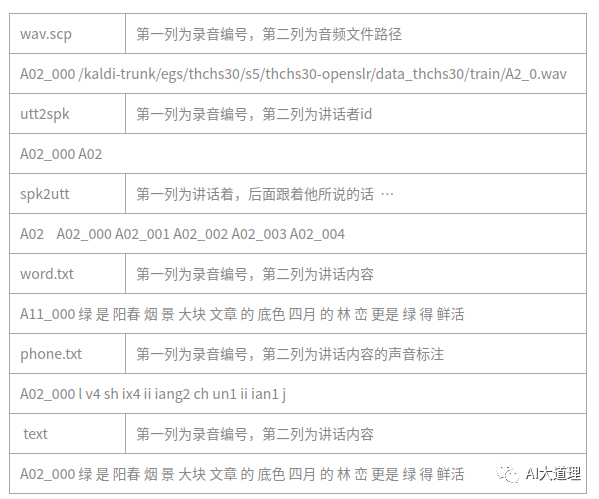
运行结果:
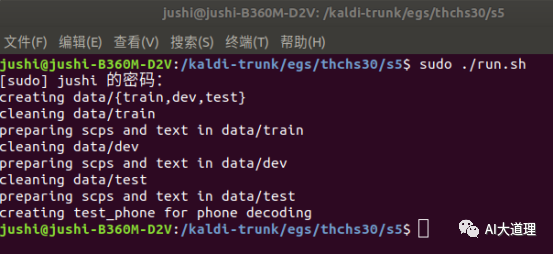
2 特征提取
2.1 make_mfcc.sh
功能:
MFCC特征提取。
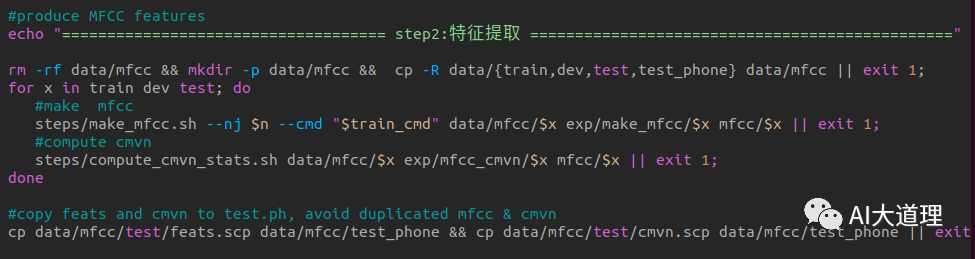
源码解析:

部分源码:
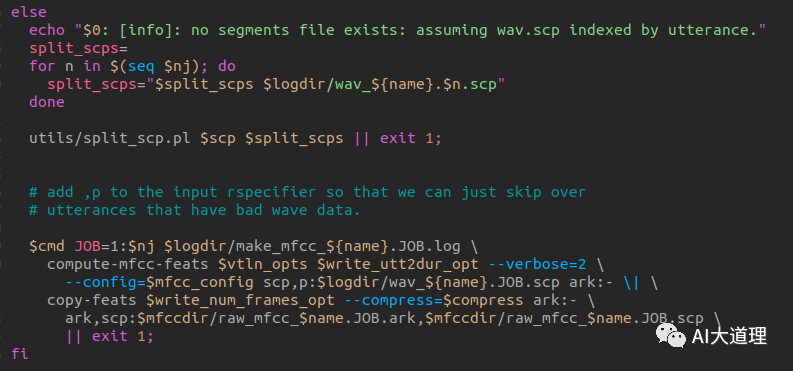
利用Kaldi的compute-mfcc-feats工具计算梅尔倒谱频率特征,然后利用copy-feats工具的参数—compress=true 压缩处理存储为两个文件类型ark和scp。
调用命令行工具compute-mfcc-feats,提取特征,创建feats.ark和feats.scp文件。
用法为:
compute-mfcc-feats [options...] <wav-rspecifier><feats-wspecifier>。
运行结果:
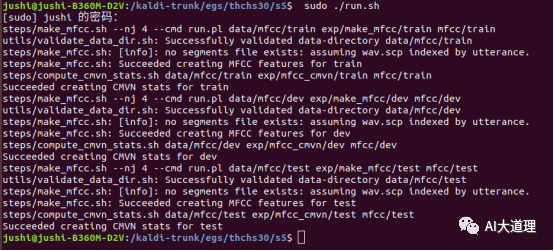
生成 mfcc特征,计算cmvn倒谱均值方差归一化完毕。
3 语料准备
准备发音词典和训练语言模型。
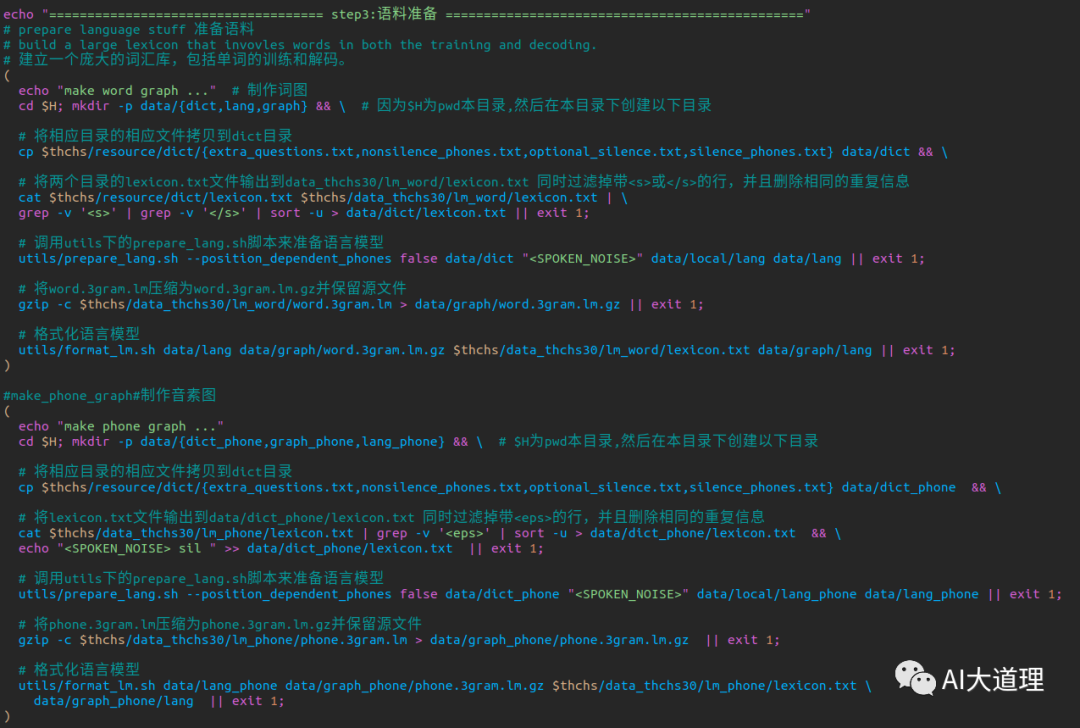
3.1 prepare_lang.sh
读取input的资源文件,生成data/lang目录,是Kaldi的标准语言文件夹。
3.2 format_lm.sh
格式化语言模型,就是把arpa的language model 转换成 FST格式。
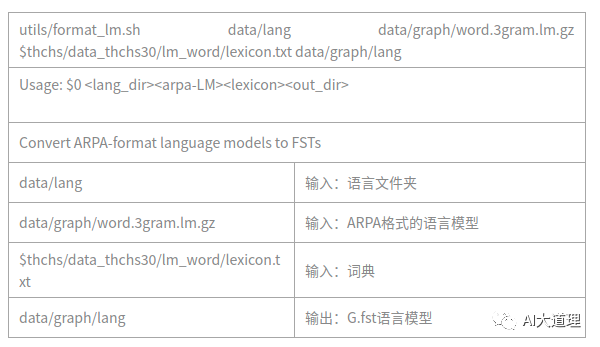
运行结果:
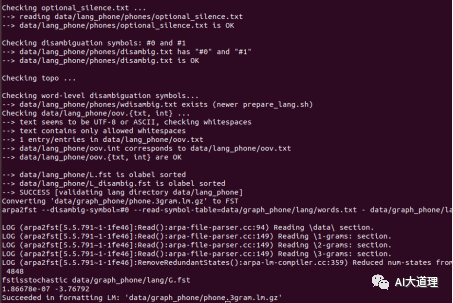
标准语言文件夹:

生成G.fst语言模型:
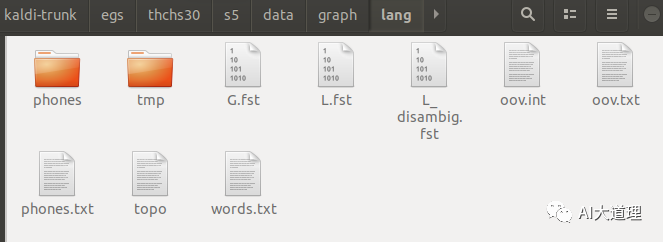
语料准备完毕。
4 单音子模型训练

4.1 train_mono.sh
用来训练单音子隐马尔科夫模型,一共进行40次迭代,每两次迭代进行一次对齐操作。
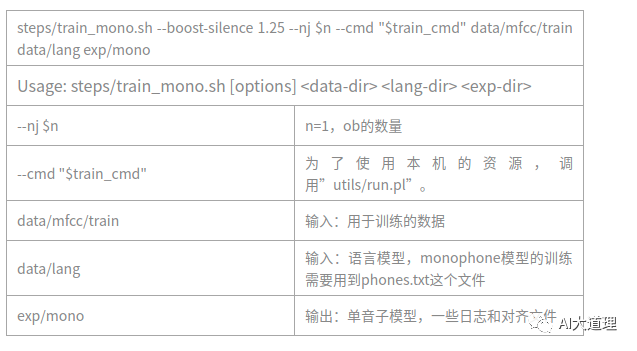
过程之道:
初始化模型->生成训练图HCLG.fst->对标签进行初始化对齐->统计估计模型所需的统计量->估计参数得到新模型->迭代训练->最后的模型final.mdl。
训练的模型:
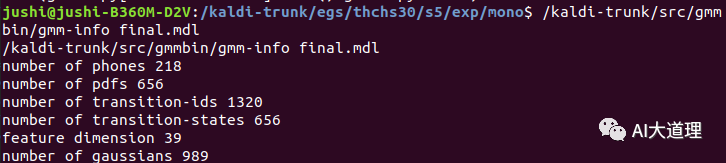
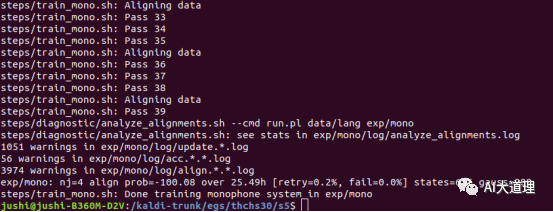
训练完毕。
4.2 thchs-30_decode.sh
测试单音素模型,实际使用mkgraph.sh建立完全的识别网络,并输出一个有限状态转换器,最后使用decode.sh以语言模型和测试数据为输入计算WER。

打开thchs-30_decode.sh
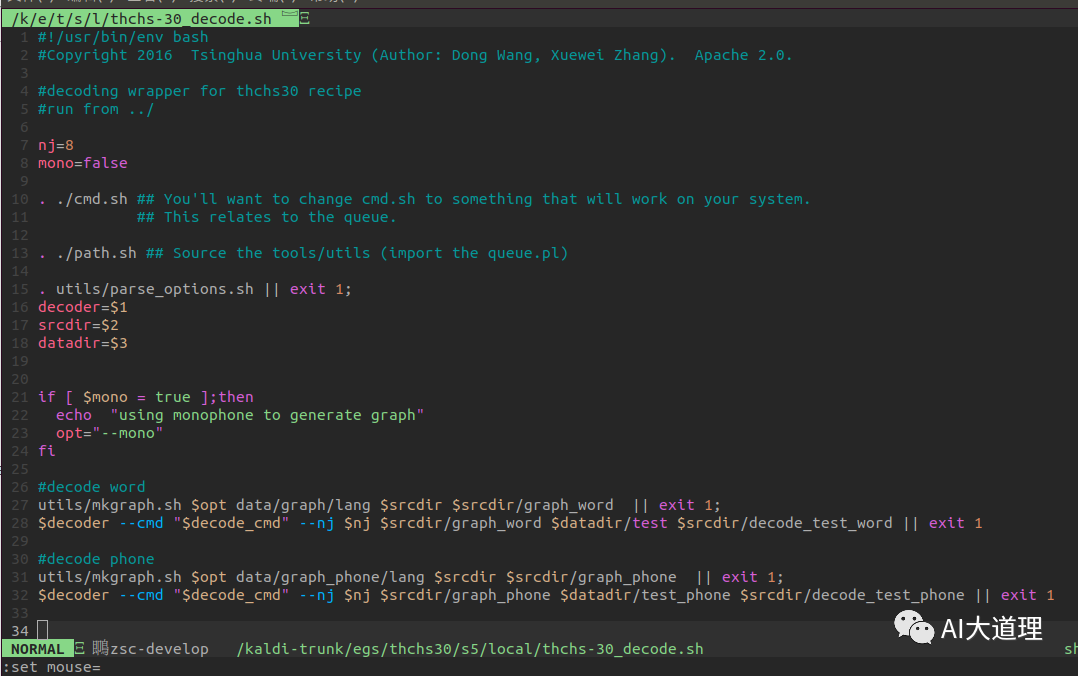
发现里面包含了构图和解码两个步骤。
mkgraph.sh构造出了HCLG.fst。
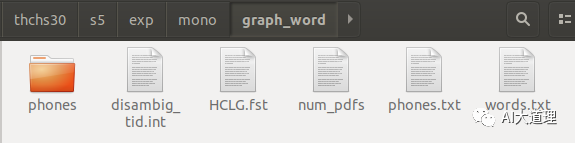
decode.sh进行解码识别测试模型识别率。
部分解码结果:
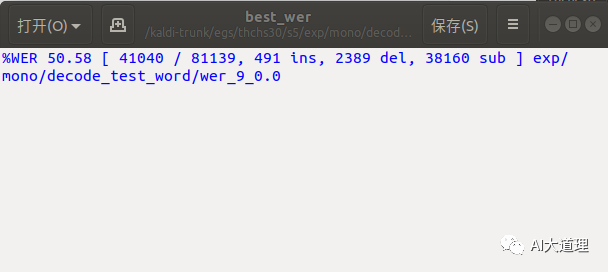
真正结果(标签):

可见识别结果不是很理想,词错误率高达50.58%
4.3 align_si.sh
之前YesNo是没有这一步的。
这一步是为了三音子训练提供对齐基础
用指定模型对指定数据进行对齐,一般在训练新模型前进行,以上一版本模型作为输入,输出在<align-dir>。

 真正进行对齐的地方。
真正进行对齐的地方。

4.4 compile-train-graphs
(在训练单音子模型的编译训练图中遇到过这个源码)
训练用每句话转换成一个FST结构,输入是音素,输出是整个句子。
输入:tree , transition_model ,L.fst(Lexicon),训练文件标注text。
输出:为图 HCLG.fst
标注文本text:

为了获得每一帧对应的状态号作为训练的标签,需要构建一个直线形的状态图。
在这个图上利用Viterbi算法求得最优路径,同时得到帧与状态的对齐。
源码解析:

4.5 gmm-align-compiled
对每一句话,根据这句话的特征和这句话的fst,生成对应的对齐状态序列。

对齐结果:
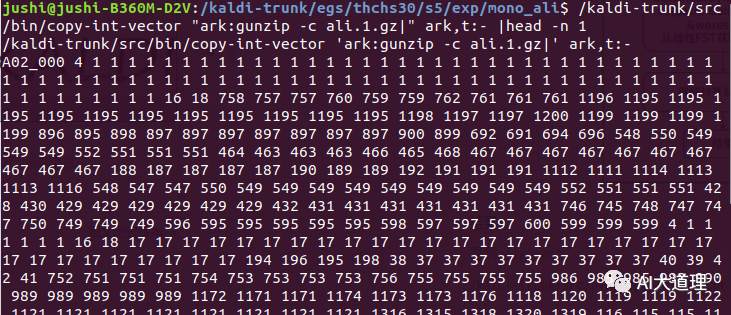
5 总结
训练好了单音素模型,得到一个对齐序列,接下来可以进行三音子模型的训练了。
三音子模型与单音素模型的主要差别在于三音子模型决策树状态的绑定。
单音素系统可以看成是上下文相关系统的一个特殊情况,窗的大小N=1和一个不做任何事情的树。

——————
浅谈则止,细致入微AI大道理
扫描下方“AI大道理”,选择“关注”公众号
—————————————————————

—————————————————————
- 相关标签
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

