- 1HarmonyOS应用开发者基础认证 试题及答案_下面哪一个事件方法可以获取到list滑动的偏移量
- 2关于argmin和argmax的一点说明_argmin和min的区别
- 3Qt的信号槽机制
- 4C#,人工智能,机器人,路径规划,A*(AStar Algorithm)算法、源代码及计算数据可视化_c# 人工智能
- 5flutter build hap打包编译时报错:hvigor ERROR: Failed :entry:default@CompileArkTS..._error: failed :entry:default@processlibs...
- 6华为北向网管NCE开发教程(3)CORBA协议开发
- 7STM32 位带操作 Bit-band operation详解_arm的bitband
- 8python100天-Python-100-Days
- 9Svelte之基础知识一
- 10重定向(redirect)与管道(pipe)_redirect.pipe
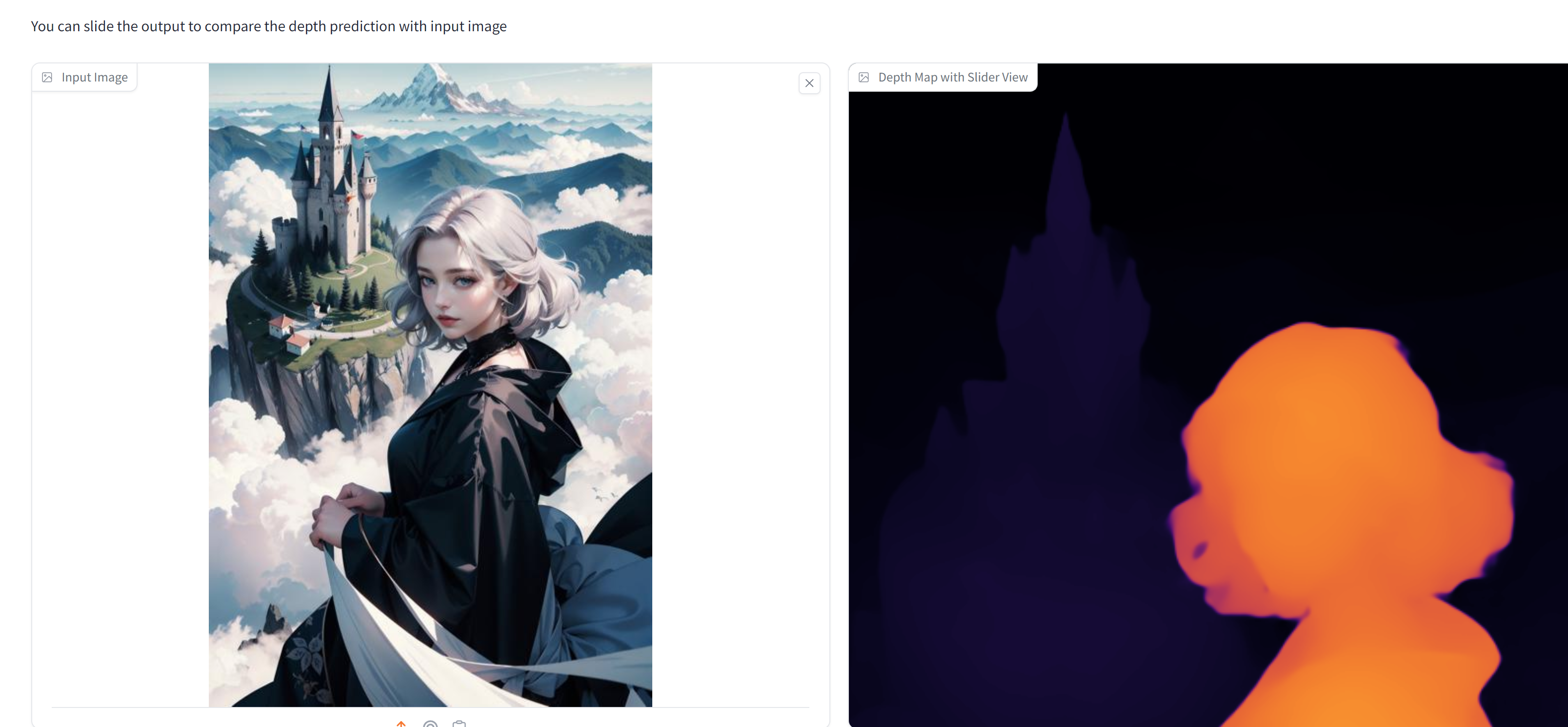
【深度学习】深度估计,Depth Anything Unleashing the Power of Large-Scale Unlabeled Data
赞
踩
论文标题:Depth Anything Unleashing the Power of Large-Scale Unlabeled Data
论文地址:https://arxiv.org/pdf/2401.10891.pdf
项目主页:https://depth-anything.github.io/
演示地址:https://huggingface.co/spaces/LiheYoung/Depth-Anything
这项工作提出了“Depth Anything”,一种用于鲁棒单目深度估计的高度实用的解决方案。我们的目标是构建一个基础模型,能够在任何情况下处理任何图像。为此,我们通过设计一个数据引擎来收集和自动注释大规模未标记数据(约6200万),显著扩大了数据覆盖范围,从而能够降低泛化误差。我们研究了两种简单但有效的策略,使得数据规模扩大成为可能。首先,通过利用数据增强工具创建了一个更具挑战性的优化目标,迫使模型主动寻求额外的视觉知识并获取鲁棒的表示。其次,开发了一个辅助监督,以强制模型继承来自预训练编码器的丰富语义先验。我们广泛评估了其零样本能力,包括六个公共数据集和随机捕获的照片。它展示了令人印象深刻的泛化能力。通过对NYUv2和KITTI进行微调,设置了新的最佳水平。我们的更好的深度模型还导致了一个更好的深度条件ControlNet。我们的模型在这里发布。
该工作是在TikTok实习期间完成的。我们强调大规模、廉价和多样化的未标记图像数据的价值对于MDE(单目深度估计)而言。我们提出了在联合训练大规模标记和未标记图像时的一个关键实践。我们的模型展示了比MiDaS-BEiT L-512更强的零样本能力。此外,经过与度量深度的微调,它显著超过了ZoeDepth。
我们的工作使用了标记和未标记的图像来促进更好的单目深度估计(MDE)。具体来说,对于未标记的图像,我们提出通过在学习伪标签时对学生模型提出更具挑战性的优化目标,使其主动寻求额外的视觉知识并学习更鲁棒的表示。此外,我们通过简单的特征对齐损失保留了丰富的语义先验,而不是使用辅助的语义分割任务。这不仅增强了MDE性能,还为中高级感知任务产生了多任务编码器。
实验部分详细说明了我们的实现细节,展示了在零样本相对深度估计、微调后的度量深度估计和语义分割等方面的性能。我们的Depth Anything模型不仅在零样本深度估计中表现出色,而且还证明了作为下游度量深度估计和语义分割任务的有前途的权重初始化。通过大规模和高质量的MDE训练,我们的模型显著提高了DINOv2在下游任务中的性能,并提供了可视化结果以展示其鲁棒性和准确性。
这项工作提出了一个强大的框架,通过利用大规模未标记数据和继承丰富的语义先验,显著提高了单目深度估计的性能,同时为下游任务提供了一个强大的预训练模型。
实操:
clone项目:
git clone https://github.com/LiheYoung/Depth-Anything
cd Depth-Anything
pip install -r requirements.txt
- 1
- 2
- 3
运行:
# 大模型
python run.py --encoder vitl --img-path assets/examples --outdir depth_vis
# 中模型
python run.py --encoder vitb --img-path assets/examples --outdir depth_vis
# 小模型
python run.py --encoder vits --img-path assets/examples --outdir depth_vis
- 1
- 2
- 3
- 4
- 5
- 6
运行graidio:
python app.py
- 1