
- 1Python不能做游戏?一小时做出一个游戏!_python做游戏要多久
- 2如何通过 IP + 端口远程访问服务器上的jupyter notebook_ip加端口号怎么访问
- 3解决Pycharm打印结果折叠问题_pandas head print不折叠
- 4OpenBCI:Brainflow更新说明
- 5SpringBoot+Vue打包为war,以及在Tomcat部署后,页面访问不到静态资源_springboot前后端项目打成war包页面位置有问题
- 6苹果安卓鸿蒙对比,【华为Mate40Pro评测】为什么说鸿蒙与iOS、安卓不在一个赛道(全文)_华为 Mate40 Pro_手机评测-中关村在线...
- 7Linux那些事儿之我是Hub(3)
- 8学生类-构造函数
- 9在Android Studio3.0以上使用 Java 8 语言功能_android studio 3 默认java语言
- 10springboot 中websocket的使用_spring websocket 设置opcode
yolov7 mask训练笔记_yolo mask
赞
踩
目录
yolov7 mask python训练,tensorrt推理框架
训练过程:
https://github.com/chelsea456/yolov7_mask/tree/main/yolov7_mask
不要过早停止训练:
parser.add_argument('--patience', type=int, default=0, help='EarlyStopping patience (epochs without improvement)')yaml文件解析
3、backbone(骨干网络*)
# yolov7 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [32, 3, 1]], # 0
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [128, 3, 2]], # 3-P2/4
[-1, 1, Conv, [64, 1, 1]],
[-2, 1, Conv, [64, 1, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[-1, 1, Conv, [64, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [256, 1, 1]], # 11
[-1, 1, MP, []],
[-1, 1, Conv, [128, 1, 1]],
[-3, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 16-P3/8
[-1, 1, Conv, [128, 1, 1]],
[-2, 1, Conv, [128, 1, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[-1, 1, Conv, [128, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [512, 1, 1]], # 24
[-1, 1, MP, []],
[-1, 1, Conv, [256, 1, 1]],
[-3, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 29-P4/16
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 37
[-1, 1, MP, []],
[-1, 1, Conv, [512, 1, 1]],
[-3, 1, Conv, [512, 1, 1]],
[-1, 1, Conv, [512, 3, 2]],
[[-1, -3], 1, Concat, [1]], # 42-P5/32
[-1, 1, Conv, [256, 1, 1]],
[-2, 1, Conv, [256, 1, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[-1, 1, Conv, [256, 3, 1]],
[[-1, -3, -5, -6], 1, Concat, [1]],
[-1, 1, Conv, [1024, 1, 1]], # 50
]
from 表示该层的输入从哪来。-1表示输入取自上一层,-2表示上两层,3表示第3层(从0开始数),[-1, 4]表示取自上一层和第4层,依次类推。。。。。
number 表示该层模块堆叠的次数,对于C3、BottleneckCSP等模块,表示其子模块的堆叠,具体细节可以查看源代码。当然最终的次数还要乘上depth_multiple系数。
module 表示该层的模块是什么类型。Conv就是卷积+BN+激活模块。所有的模块在 model/common.py 中都有定义。
args 表示输入到模块的参数。例如Conv:[128, 3, 2] 表示输出通道128,卷积核尺寸3,strid=2,当然最终的输出通道数还要乘上 width_multiple,对于其他模块,第一个参数值一般都是指输出通道数,具体细节可以看 model/common.py 中的定义。
原文链接:https://blog.csdn.net/weixin_43397302/article/details/126708227
关于预训练:
提高了3个预训练:
yolov5s-seg.pt
yolov7-seg.pt
yolov7x-seg.pt
python segment/train.py --data coco.yaml --batch 16 --weights '' --cfg yolov7-seg.yaml --epochs 300 --name yolov7-seg --img 640 --hyp hyp.scratch-high.yaml
dataloader
labels, shapes, self.segments = zip(*cache.values())
image_detect/coco128-seg.yaml at master · HoyoenKim/image_detect · GitHub
coco128-seg.yaml
download: https://ultralytics.com/assets/coco128-seg.zip
- # YOLOv5 by Ultralytics, GPL-3.0 license
- # COCO128-seg dataset https://www.kaggle.com/ultralytics/coco128 (first 128 images from COCO train2017) by Ultralytics
- # Example usage: python train.py --data coco128.yaml
- # parent
- # ├── yolov5
- # └── datasets
- # └── coco128-seg ← downloads here (7 MB)
-
-
- # Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
- path: ../datasets/coco128-seg # dataset root dir
- train: images/train2017 # train images (relative to 'path') 128 images
- val: images/train2017 # val images (relative to 'path') 128 images
- test: # test images (optional)
-
- # Classes
- names:
- 0: person
- 1: bicycle
- 2: car
- 3: motorcycle
- 4: airplane
- 5: bus
- 6: train
- 7: truck
- 8: boat
- 9: traffic light
- 10: fire hydrant
- 11: stop sign
- 12: parking meter
- 13: bench
- 14: bird
- 15: cat
- 16: dog
- 17: horse
- 18: sheep
- 19: cow
- 20: elephant
- 21: bear
- 22: zebra
- 23: giraffe
- 24: backpack
- 25: umbrella
- 26: handbag
- 27: tie
- 28: suitcase
- 29: frisbee
- 30: skis
- 31: snowboard
- 32: sports ball
- 33: kite
- 34: baseball bat
- 35: baseball glove
- 36: skateboard
- 37: surfboard
- 38: tennis racket
- 39: bottle
- 40: wine glass
- 41: cup
- 42: fork
- 43: knife
- 44: spoon
- 45: bowl
- 46: banana
- 47: apple
- 48: sandwich
- 49: orange
- 50: broccoli
- 51: carrot
- 52: hot dog
- 53: pizza
- 54: donut
- 55: cake
- 56: chair
- 57: couch
- 58: potted plant
- 59: bed
- 60: dining table
- 61: toilet
- 62: tv
- 63: laptop
- 64: mouse
- 65: remote
- 66: keyboard
- 67: cell phone
- 68: microwave
- 69: oven
- 70: toaster
- 71: sink
- 72: refrigerator
- 73: book
- 74: clock
- 75: vase
- 76: scissors
- 77: teddy bear
- 78: hair drier
- 79: toothbrush
-
-
- # Download script/URL (optional)
- download: https://ultralytics.com/assets/coco128-seg.zip

segments 格式:
segments = [xyn2xy(x, w, h, padw, padh) for x in segments]
segments2boxes
-
- def segments2boxes(segments):
- # Convert segment labels to box labels, i.e. (cls, xy1, xy2, ...) to (cls, xywh)
- boxes = []
- for s in segments:
- x, y = s.T # segment xy
- boxes.append([x.min(), y.min(), x.max(), y.max()]) # cls, xyxy
- return xyxy2xywh(np.array(boxes)) # cls, xywh
解析json格式标签:
- def cache_labels(self, path=Path('./labels.cache'), prefix=''):
- # Cache dataset labels, check images and read shapes
- x = {} # dict
- nm, nf, ne, nc, msgs = 0, 0, 0, 0, [] # number missing, found, empty, corrupt, messages
- desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels..."
-
- if self.data_type=="json":
- pbar = tqdm(zip(self.im_files, self.label_files), desc='Scanning images', total=len(self.im_files))
- for i, (im_file, lb_file) in enumerate(pbar):
- try:
- annotations = np.zeros((0, 5), dtype=np.float32)
- shape = np.zeros((2,), dtype=np.int32)
- label = []
- segments=[]
- if lb_file.endswith(".json"):
-
- json_file = json.load(open(lb_file, "r", encoding="utf-8"))
- imageHeight = json_file['imageHeight']
- imageWidth = json_file['imageWidth']
- shape[0] = imageWidth
- shape[1] = imageHeight
- for multi in json_file["shapes"]:
- points = np.array(multi["points"])
- xmin = (min(points[:, 0]) if min(points[:, 0]) > 0 else 0) / imageWidth
- xmax = (max(points[:, 0]) if max(points[:, 0]) > 0 else 0) / imageWidth
- ymin = (min(points[:, 1]) if min(points[:, 1]) > 0 else 0) / imageHeight
- ymax = (max(points[:, 1]) if max(points[:, 1]) > 0 else 0) / imageHeight
- label = multi["label"]
- if xmax > xmin and ymax > ymin:
- annotation = np.zeros((1, 5), dtype=np.float32)
- annotation[0, 1] = (xmin + xmax) / 2
- annotation[0, 2] = (ymin + ymax) / 2
- annotation[0, 3] = xmax - xmin
- annotation[0, 4] = ymax - ymin
- # cls
- annotation[0, 0] = self.hyp['names'].index(label.lower().strip())
- # annotation[0, 0] = _class_to_ind[label.lower().strip()]
- # annotations = np.append(annotations, annotation, axis=0)
- annotations = np.row_stack((annotations, annotation))
- points = points.astype(np.float32)
-
- points[:, 0] = points[:, 0] / imageWidth
- points[:, 1] = points[:, 1] / imageHeight
- segments.append(points)
- if len(annotations) < 1:
- nm += 1
- print("json no obj------------")
- annotations = np.zeros((0, 5), dtype=np.float32)
- else:
- nf += 1
- x[im_file] = [annotations, shape, segments]
- except Exception as e:
- nc += 1
- print(f'{prefix}WARNING: Ignoring corrupted image and/or label {im_file}: {e}')
-
- pbar.desc = f"{prefix}Scanning '{path.parent / path.stem}' images and labels... " \
- f"{nf} found, {nm} missing, {ne} empty, {nc} corrupted"
- pbar.close()
-
- if nf == 0:
- print(f'{prefix}WARNING: No labels found in {path}.')
统计points个数:
- import glob
- import json
-
- import numpy as np
-
- if __name__ == '__main__':
-
- label_dir=r'F:\project\detect\yolov7\yolov7_mask\Y\train'
-
- lb_files= glob.glob(label_dir+ '/*.json', recursive=True) # f = list(p.rglob('*.*')) # pathlib
-
- annotations = np.zeros((0, 5), dtype=np.float32)
- shape = np.zeros((2,), dtype=np.int32)
- label = []
- for lb_file in lb_files:
- if lb_file.endswith(".json"):
-
- json_file = json.load(open(lb_file, "r", encoding="utf-8"))
- imageHeight = json_file['imageHeight']
- imageWidth = json_file['imageWidth']
- shape[0] = imageWidth
- shape[1] = imageHeight
- for multi in json_file["shapes"]:
- points = np.array(multi["points"])
- xmin = (min(points[:, 0]) if min(points[:, 0]) > 0 else 0) / imageWidth
- xmax = (max(points[:, 0]) if max(points[:, 0]) > 0 else 0) / imageWidth
- ymin = (min(points[:, 1]) if min(points[:, 1]) > 0 else 0) / imageHeight
- ymax = (max(points[:, 1]) if max(points[:, 1]) > 0 else 0) / imageHeight
- label = multi["label"]
- if xmax > xmin and ymax > ymin:
- print(lb_file,len(points))
- # points = points.astype(np.float32)
-
coco合并标签分离为独立文件:
- import json
- import os, cv2
-
- import numpy as np
-
- def visualization_bbox1(json_path, img_path): # 需要画的第num副图片, 对应的json路径和图片路径
- with open(json_path ,encoding='utf-8') as annos:
- annotation_json = json.load(annos)
-
- print('num_key is:', len(annotation_json) ,'json key is:', annotation_json.keys()) # 读出json文件的关键字
- print('json num_images is:', len(annotation_json['images'])) # json文件中包含的图片数量
- for img_i in range(len(annotation_json['images'])):
- image_name = annotation_json['images'][img_i]['file_name'] # 读取图片名
- id = annotation_json['images'][img_i]['id'] # 读取图片id
-
- image_path = os.path.join(img_path, str(image_name).zfill(5)) # 拼接图像路径
- image = cv2.imread(image_path, 1) # 保持原始格式的方式读取图像
- num_bbox = 0 # 统计一幅图片中bbox的数量
- coco_train = dict()
- coco_train['flags'] = {}
- coco_train['imagePath'] = os.path.basename(image_path)
- coco_train['shapes'] = []
- coco_train['imageData'] = None
- coco_train['imageHeight'] = image.shape[0]
- coco_train['imageWidth'] = image.shape[1]
-
- for i in range(len(annotation_json['annotations'][::])):
- if annotation_json['annotations'][i - 1]['image_id'] == id:
- num_bbox = num_bbox + 1
-
- box_dict={}
- box_dict["label"]="quexian"
- box_dict["shape_type"]="polygon"
- box_dict["points"]=[]
- x, y, w, h = annotation_json['annotations'][i - 1]['bbox'] # 读取边框
- image = cv2.rectangle(image, (int(x), int(y)), (int(x + w), int(y + h)), (0, 255, 255), 2)
- points = annotation_json['annotations'][i - 1]['segmentation'] # keypoints
-
- data_len =len(points[0] )//2
- for index in range(data_len):
- cv2.circle(image, (int(points[0][index *2]) ,int(points[0][index * 2 +1])), 3, (0, 0, 213), -1) # x,y,r,color
- box_dict["points"].append((int(points[0][index *2]) ,int(points[0][index * 2 +1])))
-
- coco_train['shapes'].append(box_dict)
-
-
- # cv2.imwrite(f"gt/{img_i}.jpg" ,image)
-
- # cv2.resizeWindow("image_name", 2500, 1250) # 创建500*500的窗口
-
- if is_show:
- print(os.path.basename(image_path))
- cv2.namedWindow("image_name", 0) # 创建窗口
- cv2.imshow("image_name", image)
- cv2.waitKey(0)
- else:
- train_file=image_path[:-4]+".json"
- with open(train_file, 'w') as write_f:
- write_f.write(json.dumps(coco_train, indent=2, ensure_ascii=False))
-
-
- if __name__ == "__main__":
- is_show=True
- os.makedirs("gt" ,exist_ok=True)
- train_json = r'D:\work\lbg\fenge\data/mark.json'
- train_path = r'D:\work\lbg\fenge\data\trainImage'
- visualization_bbox1(train_json, train_path)
-
-
coco标签转换成独立标签线性插值:
-
-
- import json
- import os, cv2
-
- import numpy as np
- from scipy.interpolate import interp1d
-
- def visualization_bbox1(json_path, img_path): # 需要画的第num副图片, 对应的json路径和图片路径
- with open(json_path ,encoding='utf-8') as annos:
- annotation_json = json.load(annos)
-
- print('num_key is:', len(annotation_json) ,'json key is:', annotation_json.keys()) # 读出json文件的关键字
- print('json num_images is:', len(annotation_json['images'])) # json文件中包含的图片数量
- for img_i in range(len(annotation_json['images'])):
- image_name = annotation_json['images'][img_i]['file_name'] # 读取图片名
- id = annotation_json['images'][img_i]['id'] # 读取图片id
-
- image_path = os.path.join(img_path, str(image_name).zfill(5)) # 拼接图像路径
- image = cv2.imread(image_path, 1) # 保持原始格式的方式读取图像
- num_bbox = 0 # 统计一幅图片中bbox的数量
- coco_train = dict()
- coco_train['flags'] = {}
- coco_train['imagePath'] = os.path.basename(image_path)
- coco_train['shapes'] = []
- coco_train['imageData'] = None
- coco_train['imageHeight'] = image.shape[0]
- coco_train['imageWidth'] = image.shape[1]
-
- for i in range(len(annotation_json['annotations'][::])):
- if annotation_json['annotations'][i - 1]['image_id'] == id:
- num_bbox = num_bbox + 1
-
- box_dict={}
- box_dict["label"]="quexian"
- box_dict["shape_type"]="polygon"
- box_dict["points"]=[]
- x, y, w, h = annotation_json['annotations'][i - 1]['bbox'] # 读取边框
- image = cv2.rectangle(image, (int(x), int(y)), (int(x + w), int(y + h)), (0, 255, 255), 2)
- points = annotation_json['annotations'][i - 1]['segmentation'] # keypoints
-
- data_len =len(points[0] )//2
- print('points len is:', data_len)
- data_o=[]
- y_row=[]
- for index in range(data_len):
- data_o.append((points[0][index *2],points[0][index * 2 +1]))
- cv2.circle(image, (int(points[0][index *2]) ,int(points[0][index * 2 +1])), 3, (0, 0, 213), -1) # x,y,r,color
- # box_dict["points"].append((int(points[0][index *2]) ,int(points[0][index * 2 +1])))
-
- coco_train['shapes'].append(box_dict)
- data_o=np.asarray(data_o)
- data_o=data_o[np.lexsort(data_o[:, ::-1].T)]
-
- for index, data_x in enumerate(data_o):
- if index==0:
- continue
- if data_x[0]<=data_o[index-1][0]:
- data_x[0] = data_o[index-1][0]+0.01
- # f1 = interp1d(data_o[:,0], data_o[:,1], kind='cubic')
- f1 = interp1d(data_o[:,0], data_o[:,1], kind='linear')
-
- x_pred = np.linspace(data_o[0][0], data_o[-1][0], num=155)
- y1 = f1(x_pred)
-
- for index,x_data in enumerate(x_pred):
- cv2.circle(image, (int(x_data), int(y1[index])), 2, (255, 0, 0), -1) # x,y,r,color
- box_dict["points"].append((int(x_data), int(y1[index])))
-
- # cv2.imwrite(f"gt/{img_i}.jpg" ,image)
- cv2.namedWindow("image_name", 0) # 创建窗口
- # cv2.resizeWindow("image_name", 2500, 1250) # 创建500*500的窗口
- cv2.imshow("image_name", image)
- cv2.waitKey(1)
-
-
- train_file=image_path[:-4]+".json"
- with open(train_file, 'w') as write_f:
- write_f.write(json.dumps(coco_train, indent=2, ensure_ascii=False))
-
-
-
- if __name__ == "__main__":
-
- os.makedirs("gt" ,exist_ok=True)
- train_json = r'D:\work\lbg\fenge\data/mark.json'
- train_path = r'D:\work\lbg\fenge\data\trainImage'
- visualization_bbox1(train_json, train_path)
-
-
导出onnx
- import argparse
- import json
- import os
- import platform
- import subprocess
- import sys
- import time
- import warnings
- from pathlib import Path
-
- import pandas as pd
- import torch
- import yaml
- from torch.utils.mobile_optimizer import optimize_for_mobile
-
- FILE = Path(__file__).resolve()
- ROOT = FILE.parents[0] # YOLOv5 root directory
- if str(ROOT) not in sys.path:
- sys.path.append(str(ROOT)) # add ROOT to PATH
- if platform.system() != 'Windows':
- ROOT = Path(os.path.relpath(ROOT, Path.cwd())) # relative
-
- from models.experimental import attempt_load
- from models.yolo import Detect
- from utils.dataloaders import LoadImages
- from utils.general import (LOGGER, Profile, check_dataset, check_img_size, check_requirements, check_version,
- check_yaml, colorstr, file_size, get_default_args, print_args, url2file)
- from utils.torch_utils import select_device, smart_inference_mode
-
-
- def export_formats():
- # YOLOv5 export formats
- x = [['PyTorch', '-', '.pt', True, True], ['TorchScript', 'torchscript', '.torchscript', True, True],
- ['ONNX', 'onnx', '.onnx', True, True], ['OpenVINO', 'openvino', '_openvino_model', True, False],
- ['TensorRT', 'engine', '.engine', False, True], ['CoreML', 'coreml', '.mlmodel', True, False],
- ['TensorFlow SavedModel', 'saved_model', '_saved_model', True, True],
- ['TensorFlow GraphDef', 'pb', '.pb', True, True], ['TensorFlow Lite', 'tflite', '.tflite', True, False],
- ['TensorFlow Edge TPU', 'edgetpu', '_edgetpu.tflite', False, False],
- ['TensorFlow.js', 'tfjs', '_web_model', False, False], ]
- return pd.DataFrame(x, columns=['Format', 'Argument', 'Suffix', 'CPU', 'GPU'])
-
-
- def try_export(inner_func):
- # YOLOv5 export decorator, i..e @try_export
- inner_args = get_default_args(inner_func)
-
- def outer_func(*args, **kwargs):
- prefix = inner_args['prefix']
- try:
- with Profile() as dt:
- f, model = inner_func(*args, **kwargs)
- LOGGER.info(f'{prefix} export success ✅ {dt.t:.1f}s, saved as {f} ({file_size(f):.1f} MB)')
- return f, model
- except Exception as e:
- LOGGER.info(f'{prefix} export failure ❌ {dt.t:.1f}s: {e}')
- return None, None
-
- return outer_func
-
-
- @try_export
- def export_onnx(model, im, file, opset, train, dynamic, simplify, prefix=colorstr('ONNX:')):
- # YOLOv5 ONNX export
- check_requirements(('onnx',))
- import onnx
-
- LOGGER.info(f'\n{prefix} starting export with onnx {onnx.__version__}...')
- f = file.with_suffix('.onnx')
-
- torch.onnx.export(model.cpu() if dynamic else model, # --dynamic only compatible with cpu
- im.cpu() if dynamic else im, f, verbose=False, opset_version=opset,
- training=torch.onnx.TrainingMode.TRAINING if train else torch.onnx.TrainingMode.EVAL,
- do_constant_folding=not train, input_names=['images'], output_names=['output'],
- dynamic_axes={'images': {0: 'batch', 2: 'height', 3: 'width'}, # shape(1,3,640,640)
- 'output': {0: 'batch', 1: 'anchors'} # shape(1,25200,85)
- } if dynamic else None)
-
- # Checks
- model_onnx = onnx.load(f) # load onnx model
- onnx.checker.check_model(model_onnx) # check onnx model
-
- # Metadata
- d = {'stride': int(max(model.stride)), 'names': model.names}
- for k, v in d.items():
- meta = model_onnx.metadata_props.add()
- meta.key, meta.value = k, str(v)
- onnx.save(model_onnx, f)
-
- # Simplify
- if simplify:
- try:
- cuda = torch.cuda.is_available()
- check_requirements(('onnxruntime-gpu' if cuda else 'onnxruntime', 'onnx-simplifier>=0.4.1'))
- import onnxsim
-
- LOGGER.info(f'{prefix} simplifying with onnx-simplifier {onnxsim.__version__}...')
- model_onnx, check = onnxsim.simplify(model_onnx)
- assert check, 'assert check failed'
- onnx.save(model_onnx, f)
- except Exception as e:
- LOGGER.info(f'{prefix} simplifier failure: {e}')
- return f, model_onnx
-
-
- @try_export
- def export_openvino(model, file, half, prefix=colorstr('OpenVINO:')):
- # YOLOv5 OpenVINO export
- check_requirements(('openvino-dev',)) # requires openvino-dev: https://pypi.org/project/openvino-dev/
- import openvino.inference_engine as ie
-
- LOGGER.info(f'\n{prefix} starting export with openvino {ie.__version__}...')
- f = str(file).replace('.pt', f'_openvino_model{os.sep}')
-
- cmd = f"mo --input_model {file.with_suffix('.onnx')} --output_dir {f} --data_type {'FP16' if half else 'FP32'}"
- subprocess.check_output(cmd.split()) # export
- with open(Path(f) / file.with_suffix('.yaml').name, 'w') as g:
- yaml.dump({'stride': int(max(model.stride)), 'names': model.names}, g) # add metadata.yaml
- return f, None
-
-
- @try_export
- def export_coreml(model, im, file, int8, half, prefix=colorstr('CoreML:')):
- # YOLOv5 CoreML export
- check_requirements(('coremltools',))
- import coremltools as ct
-
- LOGGER.info(f'\n{prefix} starting export with coremltools {ct.__version__}...')
- f = file.with_suffix('.mlmodel')
-
- ts = torch.jit.trace(model, im, strict=False) # TorchScript model
- ct_model = ct.convert(ts, inputs=[ct.ImageType('image', shape=im.shape, scale=1 / 255, bias=[0, 0, 0])])
- bits, mode = (8, 'kmeans_lut') if int8 else (16, 'linear') if half else (32, None)
- if bits < 32:
- if platform.system() == 'Darwin': # quantization only supported on macOS
- with warnings.catch_warnings():
- warnings.filterwarnings("ignore", category=DeprecationWarning) # suppress numpy==1.20 float warning
- ct_model = ct.models.neural_network.quantization_utils.quantize_weights(ct_model, bits, mode)
- else:
- print(f'{prefix} quantization only supported on macOS, skipping...')
- ct_model.save(f)
- return f, ct_model
-
-
- @try_export
- def export_engine(model, im, file, half, dynamic, simplify, workspace=4, verbose=False, prefix=colorstr('TensorRT:')):
- # YOLOv5 TensorRT export https://developer.nvidia.com/tensorrt
- assert im.device.type != 'cpu', 'export running on CPU but must be on GPU, i.e. `python export.py --device 0`'
- try:
- import tensorrt as trt
- except Exception:
- if platform.system() == 'Linux':
- check_requirements(('nvidia-tensorrt',), cmds=('-U --index-url https://pypi.ngc.nvidia.com',))
- import tensorrt as trt
-
- if trt.__version__[0] == '7': # TensorRT 7 handling https://github.com/ultralytics/yolov5/issues/6012
- grid = model.model[-1].anchor_grid
- model.model[-1].anchor_grid = [a[..., :1, :1, :] for a in grid]
- export_onnx(model, im, file, 12, False, dynamic, simplify) # opset 12
- model.model[-1].anchor_grid = grid
- else: # TensorRT >= 8
- check_version(trt.__version__, '8.0.0', hard=True) # require tensorrt>=8.0.0
- export_onnx(model, im, file, 13, False, dynamic, simplify) # opset 13
- onnx = file.with_suffix('.onnx')
-
- LOGGER.info(f'\n{prefix} starting export with TensorRT {trt.__version__}...')
- assert onnx.exists(), f'failed to export ONNX file: {onnx}'
- f = file.with_suffix('.engine') # TensorRT engine file
- logger = trt.Logger(trt.Logger.INFO)
- if verbose:
- logger.min_severity = trt.Logger.Severity.VERBOSE
-
- builder = trt.Builder(logger)
- config = builder.create_builder_config()
- config.max_workspace_size = workspace * 1 << 30
- # config.set_memory_pool_limit(trt.MemoryPoolType.WORKSPACE, workspace << 30) # fix TRT 8.4 deprecation notice
-
- flag = (1 << int(trt.NetworkDefinitionCreationFlag.EXPLICIT_BATCH))
- network = builder.create_network(flag)
- parser = trt.OnnxParser(network, logger)
- if not parser.parse_from_file(str(onnx)):
- raise RuntimeError(f'failed to load ONNX file: {onnx}')
-
- inputs = [network.get_input(i) for i in range(network.num_inputs)]
- outputs = [network.get_output(i) for i in range(network.num_outputs)]
- LOGGER.info(f'{prefix} Network Description:')
- for inp in inputs:
- LOGGER.info(f'{prefix}\tinput "{inp.name}" with shape {inp.shape} and dtype {inp.dtype}')
- for out in outputs:
- LOGGER.info(f'{prefix}\toutput "{out.name}" with shape {out.shape} and dtype {out.dtype}')
-
- if dynamic:
- if im.shape[0] <= 1:
- LOGGER.warning(f"{prefix}WARNING: --dynamic model requires maximum --batch-size argument")
- profile = builder.create_optimization_profile()
- for inp in inputs:
- profile.set_shape(inp.name, (1, *im.shape[1:]), (max(1, im.shape[0] // 2), *im.shape[1:]), im.shape)
- config.add_optimization_profile(profile)
-
- LOGGER.info(f'{prefix} building FP{16 if builder.platform_has_fast_fp16 and half else 32} engine in {f}')
- if builder.platform_has_fast_fp16 and half:
- config.set_flag(trt.BuilderFlag.FP16)
- with builder.build_engine(network, config) as engine, open(f, 'wb') as t:
- t.write(engine.serialize())
- return f, None
-
-
- @try_export
- def export_saved_model(model, im, file, dynamic, tf_nms=False, agnostic_nms=False, topk_per_class=100, topk_all=100,
- iou_thres=0.45, conf_thres=0.25, keras=False, prefix=colorstr('TensorFlow SavedModel:')):
- # YOLOv5 TensorFlow SavedModel export
- import tensorflow as tf
- from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
-
- from models.tf import TFModel
-
- LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
- f = str(file).replace('.pt', '_saved_model')
- batch_size, ch, *imgsz = list(im.shape) # BCHW
-
- tf_model = TFModel(cfg=model.yaml, model=model, nc=model.nc, imgsz=imgsz)
- im = tf.zeros((batch_size, *imgsz, ch)) # BHWC order for TensorFlow
- _ = tf_model.predict(im, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
- inputs = tf.keras.Input(shape=(*imgsz, ch), batch_size=None if dynamic else batch_size)
- outputs = tf_model.predict(inputs, tf_nms, agnostic_nms, topk_per_class, topk_all, iou_thres, conf_thres)
- keras_model = tf.keras.Model(inputs=inputs, outputs=outputs)
- keras_model.trainable = False
- keras_model.summary()
- if keras:
- keras_model.save(f, save_format='tf')
- else:
- spec = tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype)
- m = tf.function(lambda x: keras_model(x)) # full model
- m = m.get_concrete_function(spec)
- frozen_func = convert_variables_to_constants_v2(m)
- tfm = tf.Module()
- tfm.__call__ = tf.function(lambda x: frozen_func(x)[:4] if tf_nms else frozen_func(x)[0], [spec])
- tfm.__call__(im)
- tf.saved_model.save(tfm, f,
- options=tf.saved_model.SaveOptions(experimental_custom_gradients=False) if check_version(
- tf.__version__, '2.6') else tf.saved_model.SaveOptions())
- return f, keras_model
-
-
- @try_export
- def export_pb(keras_model, file, prefix=colorstr('TensorFlow GraphDef:')):
- # YOLOv5 TensorFlow GraphDef *.pb export https://github.com/leimao/Frozen_Graph_TensorFlow
- import tensorflow as tf
- from tensorflow.python.framework.convert_to_constants import convert_variables_to_constants_v2
-
- LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
- f = file.with_suffix('.pb')
-
- m = tf.function(lambda x: keras_model(x)) # full model
- m = m.get_concrete_function(tf.TensorSpec(keras_model.inputs[0].shape, keras_model.inputs[0].dtype))
- frozen_func = convert_variables_to_constants_v2(m)
- frozen_func.graph.as_graph_def()
- tf.io.write_graph(graph_or_graph_def=frozen_func.graph, logdir=str(f.parent), name=f.name, as_text=False)
- return f, None
-
-
- @try_export
- def export_tflite(keras_model, im, file, int8, data, nms, agnostic_nms, prefix=colorstr('TensorFlow Lite:')):
- # YOLOv5 TensorFlow Lite export
- import tensorflow as tf
-
- LOGGER.info(f'\n{prefix} starting export with tensorflow {tf.__version__}...')
- batch_size, ch, *imgsz = list(im.shape) # BCHW
- f = str(file).replace('.pt', '-fp16.tflite')
-
- converter = tf.lite.TFLiteConverter.from_keras_model(keras_model)
- converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS]
- converter.target_spec.supported_types = [tf.float16]
- converter.optimizations = [tf.lite.Optimize.DEFAULT]
- if int8:
- from models.tf import representative_dataset_gen
- dataset = LoadImages(check_dataset(check_yaml(data))['train'], img_size=imgsz, auto=False)
- converter.representative_dataset = lambda: representative_dataset_gen(dataset, ncalib=100)
- converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
- converter.target_spec.supported_types = []
- converter.inference_input_type = tf.uint8 # or tf.int8
- converter.inference_output_type = tf.uint8 # or tf.int8
- converter.experimental_new_quantizer = True
- f = str(file).replace('.pt', '-int8.tflite')
- if nms or agnostic_nms:
- converter.target_spec.supported_ops.append(tf.lite.OpsSet.SELECT_TF_OPS)
-
- tflite_model = converter.convert()
- open(f, "wb").write(tflite_model)
- return f, None
-
-
- @try_export
- def export_edgetpu(file, prefix=colorstr('Edge TPU:')):
- # YOLOv5 Edge TPU export https://coral.ai/docs/edgetpu/models-intro/
- cmd = 'edgetpu_compiler --version'
- help_url = 'https://coral.ai/docs/edgetpu/compiler/'
- assert platform.system() == 'Linux', f'export only supported on Linux. See {help_url}'
- if subprocess.run(f'{cmd} >/dev/null', shell=True).returncode != 0:
- LOGGER.info(f'\n{prefix} export requires Edge TPU compiler. Attempting install from {help_url}')
- sudo = subprocess.run('sudo --version >/dev/null', shell=True).returncode == 0 # sudo installed on system
- for c in ('curl https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -',
- 'echo "deb https://packages.cloud.google.com/apt coral-edgetpu-stable main" | sudo tee /etc/apt/sources.list.d/coral-edgetpu.list',
- 'sudo apt-get update', 'sudo apt-get install edgetpu-compiler'):
- subprocess.run(c if sudo else c.replace('sudo ', ''), shell=True, check=True)
- ver = subprocess.run(cmd, shell=True, capture_output=True, check=True).stdout.decode().split()[-1]
-
- LOGGER.info(f'\n{prefix} starting export with Edge TPU compiler {ver}...')
- f = str(file).replace('.pt', '-int8_edgetpu.tflite') # Edge TPU model
- f_tfl = str(file).replace('.pt', '-int8.tflite') # TFLite model
-
- cmd = f"edgetpu_compiler -s -d -k 10 --out_dir {file.parent} {f_tfl}"
- subprocess.run(cmd.split(), check=True)
- return f, None
-
-
- @try_export
- def export_tfjs(file, prefix=colorstr('TensorFlow.js:')):
- # YOLOv5 TensorFlow.js export
- check_requirements(('tensorflowjs',))
- import re
-
- import tensorflowjs as tfjs
-
- LOGGER.info(f'\n{prefix} starting export with tensorflowjs {tfjs.__version__}...')
- f = str(file).replace('.pt', '_web_model') # js dir
- f_pb = file.with_suffix('.pb') # *.pb path
- f_json = f'{f}/model.json' # *.json path
-
- cmd = f'tensorflowjs_converter --input_format=tf_frozen_model ' \
- f'--output_node_names=Identity,Identity_1,Identity_2,Identity_3 {f_pb} {f}'
- subprocess.run(cmd.split())
-
- json = Path(f_json).read_text()
- with open(f_json, 'w') as j: # sort JSON Identity_* in ascending order
- subst = re.sub(r'{"outputs": {"Identity.?.?": {"name": "Identity.?.?"}, '
- r'"Identity.?.?": {"name": "Identity.?.?"}, '
- r'"Identity.?.?": {"name": "Identity.?.?"}, '
- r'"Identity.?.?": {"name": "Identity.?.?"}}}', r'{"outputs": {"Identity": {"name": "Identity"}, '
- r'"Identity_1": {"name": "Identity_1"}, '
- r'"Identity_2": {"name": "Identity_2"}, '
- r'"Identity_3": {"name": "Identity_3"}}}', json)
- j.write(subst)
- return f, None
-
-
- @smart_inference_mode()
- def run(data=ROOT / 'data/coco128.yaml', # 'dataset.yaml path'
- weights=ROOT / 'yolov5s.pt', # weights path
- imgsz=(640, 640), # image (height, width)
- batch_size=1, # batch size
- device='cpu', # cuda device, i.e. 0 or 0,1,2,3 or cpu
- include=('torchscript', 'onnx'), # include formats
- half=False, # FP16 half-precision export
- inplace=False, # set YOLOv5 Detect() inplace=True
- train=False, # model.train() mode
- keras=False, # use Keras
- optimize=False, # TorchScript: optimize for mobile
- int8=False, # CoreML/TF INT8 quantization
- dynamic=False, # ONNX/TF/TensorRT: dynamic axes
- simplify=False, # ONNX: simplify model
- opset=12, # ONNX: opset version
- verbose=False, # TensorRT: verbose log
- workspace=4, # TensorRT: workspace size (GB)
- nms=False, # TF: add NMS to model
- agnostic_nms=False, # TF: add agnostic NMS to model
- topk_per_class=100, # TF.js NMS: topk per class to keep
- topk_all=100, # TF.js NMS: topk for all classes to keep
- iou_thres=0.45, # TF.js NMS: IoU threshold
- conf_thres=0.25, # TF.js NMS: confidence threshold
- ):
- t = time.time()
- include = [x.lower() for x in include] # to lowercase
- fmts = tuple(export_formats()['Argument'][1:]) # --include arguments
- flags = [x in include for x in fmts]
- assert sum(flags) == len(include), f'ERROR: Invalid --include {include}, valid --include arguments are {fmts}'
- jit, onnx, xml, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs = flags # export booleans
- file = Path(url2file(weights) if str(weights).startswith(('http:/', 'https:/')) else weights) # PyTorch weights
-
- # Load PyTorch model
- device = select_device(device)
- if half:
- assert device.type != 'cpu' or coreml, '--half only compatible with GPU export, i.e. use --device 0'
- assert not dynamic, '--half not compatible with --dynamic, i.e. use either --half or --dynamic but not both'
- model = attempt_load(weights, device=device, inplace=True, fuse=True) # load FP32 model
-
- # Checks
- imgsz *= 2 if len(imgsz) == 1 else 1 # expand
- if optimize:
- assert device.type == 'cpu', '--optimize not compatible with cuda devices, i.e. use --device cpu'
-
- # Input
- gs = int(max(model.stride)) # grid size (max stride)
- imgsz = [check_img_size(x, gs) for x in imgsz] # verify img_size are gs-multiples
- im = torch.zeros(batch_size, 3, *imgsz).to(device) # image size(1,3,320,192) BCHW iDetection
-
- # Update model
- model.train() if train else model.eval() # training mode = no Detect() layer grid construction
- for k, m in model.named_modules():
- if isinstance(m, Detect):
- m.inplace = inplace
- m.dynamic = dynamic
- m.export = True
-
- for _ in range(2):
- y = model(im) # dry runs
- if half and not coreml:
- im, model = im.half(), model.half() # to FP16
- shape = tuple((y[0] if isinstance(y, tuple) else y).shape) # model output shape
- LOGGER.info(f"\n{colorstr('PyTorch:')} starting from {file} with output shape {shape} ({file_size(file):.1f} MB)")
-
- # Exports
- f = [''] * 10 # exported filenames
- warnings.filterwarnings(action='ignore', category=torch.jit.TracerWarning) # suppress TracerWarning
-
- if engine: # TensorRT required before ONNX
- f[1], _ = export_engine(model, im, file, half, dynamic, simplify, workspace, verbose)
- if onnx or xml: # OpenVINO requires ONNX
- f[2], _ = export_onnx(model, im, file, opset, train, dynamic, simplify)
- if xml: # OpenVINO
- f[3], _ = export_openvino(model, file, half)
- if coreml:
- f[4], _ = export_coreml(model, im, file, int8, half)
-
- # TensorFlow Exports
- if any((saved_model, pb, tflite, edgetpu, tfjs)):
- if int8 or edgetpu: # TFLite --int8 bug https://github.com/ultralytics/yolov5/issues/5707
- check_requirements(('flatbuffers==1.12',)) # required before `import tensorflow`
- assert not tflite or not tfjs, 'TFLite and TF.js models must be exported separately, please pass only one type.'
- f[5], model = export_saved_model(model.cpu(), im, file, dynamic, tf_nms=nms or agnostic_nms or tfjs,
- agnostic_nms=agnostic_nms or tfjs, topk_per_class=topk_per_class,
- topk_all=topk_all, iou_thres=iou_thres, conf_thres=conf_thres, keras=keras)
- if pb or tfjs: # pb prerequisite to tfjs
- f[6], _ = export_pb(model, file)
- if tflite or edgetpu:
- f[7], _ = export_tflite(model, im, file, int8 or edgetpu, data=data, nms=nms, agnostic_nms=agnostic_nms)
- if edgetpu:
- f[8], _ = export_edgetpu(file)
- if tfjs:
- f[9], _ = export_tfjs(file)
-
- # Finish
- f = [str(x) for x in f if x] # filter out '' and None
- if any(f):
- h = '--half' if half else '' # --half FP16 inference arg
- LOGGER.info(f'\nExport complete ({time.time() - t:.1f}s)'
- f"\nResults saved to {colorstr('bold', file.parent.resolve())}"
- f"\nDetect: python detect.py --weights {f[-1]} {h}"
- f"\nValidate: python val.py --weights {f[-1]} {h}"
- f"\nPyTorch Hub: model = torch.hub.load('ultralytics/yolov5', 'custom', '{f[-1]}')"
- f"\nVisualize: https://netron.app")
- return f # return list of exported files/dirs
-
-
- def parse_opt():
- parser = argparse.ArgumentParser()
- parser.add_argument('--data', type=str, default='../data/data_y.yaml', help='dataset.yaml path')
- parser.add_argument('--weights', nargs='+', type=str, default='./runs/train-seg/exp/weights/best.pt',
- help='model.pt path(s)')
- parser.add_argument('--imgsz', '--img', '--img-size', nargs='+', type=int, default=[640, 640], help='image (h, w)')
- parser.add_argument('--batch-size', type=int, default=1, help='batch size')
- parser.add_argument('--device', default='cpu', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
- parser.add_argument('--half', action='store_true', help='FP16 half-precision export')
- parser.add_argument('--inplace', action='store_true', help='set YOLOv5 Detect() inplace=True')
- parser.add_argument('--train', action='store_true', help='model.train() mode')
- parser.add_argument('--keras', action='store_true', help='TF: use Keras')
- parser.add_argument('--optimize', action='store_true', help='TorchScript: optimize for mobile')
- parser.add_argument('--int8', action='store_true', help='CoreML/TF INT8 quantization')
- parser.add_argument('--dynamic', action='store_true', help='ONNX/TF/TensorRT: dynamic axes')
- parser.add_argument('--simplify', action='store_true',default=True, help='ONNX: simplify model')
- parser.add_argument('--opset', type=int, default=12, help='ONNX: opset version')
- parser.add_argument('--verbose', action='store_true', help='TensorRT: verbose log')
- parser.add_argument('--workspace', type=int, default=4, help='TensorRT: workspace size (GB)')
- parser.add_argument('--nms', action='store_true', help='TF: add NMS to model')
- parser.add_argument('--agnostic-nms', action='store_true', help='TF: add agnostic NMS to model')
- parser.add_argument('--topk-per-class', type=int, default=100, help='TF.js NMS: topk per class to keep')
- parser.add_argument('--topk-all', type=int, default=100, help='TF.js NMS: topk for all classes to keep')
- parser.add_argument('--iou-thres', type=float, default=0.45, help='TF.js NMS: IoU threshold')
- parser.add_argument('--conf-thres', type=float, default=0.25, help='TF.js NMS: confidence threshold')
- parser.add_argument('--include', nargs='+', default=['onnx'],
- help='torchscript, onnx, openvino, engine, coreml, saved_model, pb, tflite, edgetpu, tfjs')
- opt = parser.parse_args()
- print_args(vars(opt))
- return opt
-
-
- if __name__ == "__main__":
- opt = parse_opt()
- for opt.weights in (opt.weights if isinstance(opt.weights, list) else [opt.weights]):
- run(**vars(opt))
onnx结构:
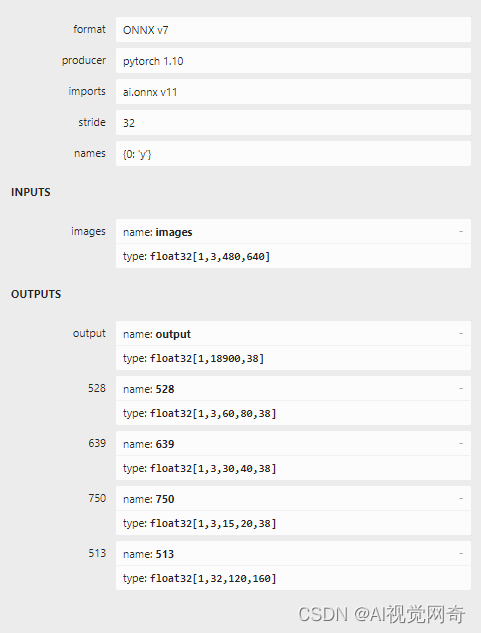
转ncnn:
onnx2ncnn yolov7_mask.onnx yolov7_mask.param yolov7_mask.bin
报错:
Unsupported slice axes !
ScatterND not supported yet!
Unsupported slice axes !
ScatterND not supported yet!
Unsupported slice axes !
ScatterND not supported yet!
yolov7 mask python训练,tensorrt推理框架
整套框架已跑通,有需要的私信联系 AI视觉网奇的博客_CSDN博客-python宝典,深度学习宝典,pytorch知识宝典领域博主。
python对比原图和结果:
-
- import json
- import os, cv2
-
- import numpy as np
-
- def visualization_bbox1(json_path, img_path): # 需要画的第num副图片, 对应的json路径和图片路径
- with open(json_path ,encoding='utf-8') as annos:
- annotation_json = json.load(annos)
-
- print('num_key is:', len(annotation_json) ,'json key is:', annotation_json.keys()) # 读出json文件的关键字
- print('json num_images is:', len(annotation_json['images'])) # json文件中包含的图片数量
- for img_i in range(len(annotation_json['images'])):
- image_name = annotation_json['images'][img_i]['file_name'] # 读取图片名
- id = annotation_json['images'][img_i]['id'] # 读取图片id
-
- image_path = os.path.join(img_path, str(image_name).zfill(5)) # 拼接图像路径
- image = cv2.imread(image_path, 1) # 保持原始格式的方式读取图像
- num_bbox = 0 # 统计一幅图片中bbox的数量
- coco_train = dict()
- coco_train['flags'] = {}
- coco_train['imagePath'] = os.path.basename(image_path)
- coco_train['shapes'] = []
- coco_train['imageData'] = None
- coco_train['imageHeight'] = image.shape[0]
- coco_train['imageWidth'] = image.shape[1]
-
- for i in range(len(annotation_json['annotations'][::])):
- if annotation_json['annotations'][i - 1]['image_id'] == id:
- num_bbox = num_bbox + 1
-
- box_dict={}
- box_dict["label"]="quexian"
- box_dict["shape_type"]="polygon"
- box_dict["points"]=[]
- x, y, w, h = annotation_json['annotations'][i - 1]['bbox'] # 读取边框
- image = cv2.rectangle(image, (int(x), int(y)), (int(x + w), int(y + h)), (0, 255, 255), 2)
- points = annotation_json['annotations'][i - 1]['segmentation'] # keypoints
-
- data_len =len(points[0] )//2
- for index in range(data_len):
- cv2.circle(image, (int(points[0][index *2]) ,int(points[0][index * 2 +1])), 3, (0, 0, 213), -1) # x,y,r,color
- box_dict["points"].append((int(points[0][index *2]) ,int(points[0][index * 2 +1])))
-
- coco_train['shapes'].append(box_dict)
-
-
- # cv2.imwrite(f"gt/{img_i}.jpg" ,image)
-
- # cv2.resizeWindow("image_name", 2500, 1250) # 创建500*500的窗口
-
- if is_show:
- print(os.path.basename(image_path))
- # cv2.namedWindow("image_name", 0) # 创建窗口
-
- if image.shape[1] > 1000:
- x_scale = 1000 / image.shape[1]
- image = cv2.resize(image, None, fx=x_scale, fy=x_scale, interpolation=cv2.INTER_AREA)
-
- cv2.imshow("image_name", image)
-
- img_result=cv2.imread(result_dir+os.path.basename(image_path))
-
- if img_result.shape[1] > 1000:
- x_scale = 1000 / img_result.shape[1]
- img_result = cv2.resize(img_result, None, fx=x_scale, fy=x_scale, interpolation=cv2.INTER_AREA)
-
- cv2.imshow("img_result", img_result)
- cv2.waitKey(0)
- else:
- train_file=image_path[:-4]+".json"
- with open(train_file, 'w') as write_f:
- write_f.write(json.dumps(coco_train, indent=2, ensure_ascii=False))
-
-
- if __name__ == "__main__":
- is_show=True
-
- result_dir=r'D:\work\lbg\fenge\yolov7_mask-main\segment\runs\predict-seg\exp10/'
- train_json = r'D:\work\lbg\fenge\data/mark.json'
- train_path = r'D:\work\lbg\fenge\data\trainImage'
- os.makedirs(train_path, exist_ok=True)
- visualization_bbox1(train_json, train_path)
-
-

