
热门标签
热门文章
- 1Capture One快捷键
- 2查询优化的几种方法
- 3Windows基础命令_windows type命令
- 4sql去重复操作详解SQL中distinct的用法_distinct执行时间
- 5【FAQ】解决报错Could not initialize class org.bytedeco.javacpp.avutil
- 6【鸿蒙 HarmonyOS】UI 组件 ( 拖动条 Slider 组件 )_拖动条组件是
- 7新建ccs工程_ccs左侧目录如何弄出来
- 8一个很有意思的程序_程序挺有意思
- 9uniapp H5 $el.querySelectorAll is not a function
- 10Android进程间通信---AIDL
当前位置: article > 正文
whisper 语音识别项目部署_whisper部署
作者:weixin_40725706 | 2024-03-22 14:52:12
赞
踩
whisper部署
1.安装anaconda软件
在如下网盘免费获取软件:
链接:https://pan.baidu.com/s/1zOZCQOeiDhx6ebHh5zNasA
提取码:hfnd
2.使用conda命令创建python3.8环境
conda create -n whisper python==3.8
- 1
3.进入whisper虚拟环境
conda activate whisper
- 1
4.安装cuda10.0的PyTorch环境
pip --trusted-host pypi.tuna.tsinghua.edu.cn install torch==1.10.1+cu102 torchvision==0.11.2+cu102 torchaudio==0.10.1 -f https://download.pytorch.org/whl/torch_stable.html
- 1
5.使用命令安装whisper库包
pip install -U openai-whisper
- 1
6.简单使用命令识别一段语音:
whisper output.wav --model medium --language Chinese
- 1
6.安装和配置ffmpeg软件
在如下网盘免费获取软件:
配置只需要解压后将文件里面的bin路径放入系统环境变量Path中即可
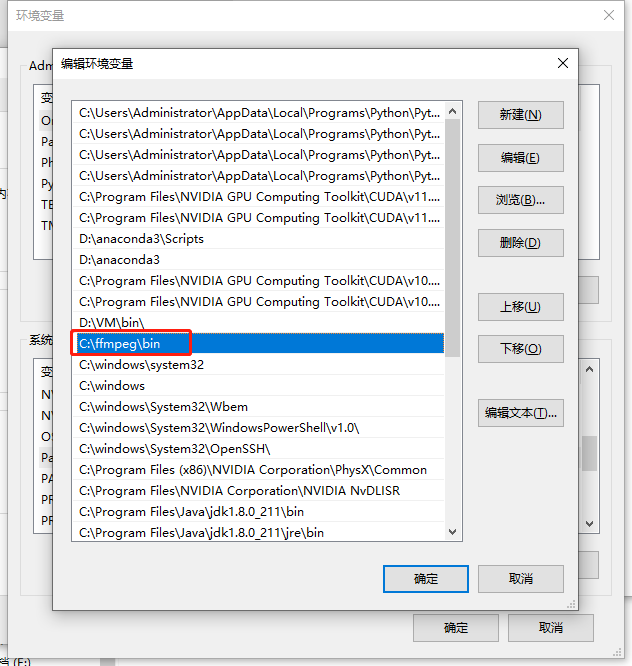
7.安装cuda软件
cuda11.0软件百度网盘获取:
链接:https://pan.baidu.com/s/1KOJfAVR6nKmVafNnmbsYDw
提取码:lblh
cudnn11.0百度网盘获取:
链接:https://pan.baidu.com/s/1CBuq7jflihEDuclSq-RTJA
提取码:efgu
6.打开pycharm软件编写代码
7.可以实时录音并且语音转中文的代码编写(使用cpu运行)
import whisper
import zhconv
import wave # 使用wave库可读、写wav类型的音频文件
import pyaudio # 使用pyaudio库可以进行录音,播放,生成wav文件
def record(time): # 录音程序
# 定义数据流块
CHUNK = 1024 # 音频帧率(也就是每次读取的数据是多少,默认1024)
FORMAT = pyaudio.paInt16 # 采样时生成wav文件正常格式
CHANNELS = 1 # 音轨数(每条音轨定义了该条音轨的属性,如音轨的音色、音色库、通道数、输入/输出端口、音量等。可以多个音轨,不唯一)
RATE = 16000 # 采样率(即每秒采样多少数据)
RECORD_SECONDS = time # 录音时间
WAVE_OUTPUT_FILENAME = "./output.wav" # 保存音频路径
p = pyaudio.PyAudio() # 创建PyAudio对象
stream = p.open(format=FORMAT, # 采样生成wav文件的正常格式
channels=CHANNELS, # 音轨数
rate=RATE, # 采样率
input=True, # Ture代表这是一条输入流,False代表这不是输入流
frames_per_buffer=CHUNK) # 每个缓冲多少帧
print("* recording") # 开始录音标志
frames = [] # 定义frames为一个空列表
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # 计算要读多少次,每秒的采样率/每次读多少数据*录音时间=需要读多少次
data = stream.read(CHUNK) # 每次读chunk个数据
frames.append(data) # 将读出的数据保存到列表中
print("* done recording") # 结束录音标志
stream.stop_stream() # 停止输入流
stream.close() # 关闭输入流
p.terminate() # 终止pyaudio
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') # 以’wb‘二进制流写的方式打开一个文件
wf.setnchannels(CHANNELS) # 设置音轨数
wf.setsampwidth(p.get_sample_size(FORMAT)) # 设置采样点数据的格式,和FOMART保持一致
wf.setframerate(RATE) # 设置采样率与RATE要一致
wf.writeframes(b''.join(frames)) # 将声音数据写入文件
wf.close() # 数据流保存完,关闭文件
if __name__ == '__main__':
model = whisper.load_model("tiny")
record(3) # 定义录音时间,单位/s
result = model.transcribe("output.wav",language='Chinese',fp16 = True)
s = result["text"]
s1 = zhconv.convert(s, 'zh-cn')
print(s1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
8.可以实时录音并且语音转中文的代码编写(使用gpu运行)
import whisper
import zhconv
import wave # 使用wave库可读、写wav类型的音频文件
import pyaudio # 使用pyaudio库可以进行录音,播放,生成wav文件
def record(time): # 录音程序
# 定义数据流块
CHUNK = 1024 # 音频帧率(也就是每次读取的数据是多少,默认1024)
FORMAT = pyaudio.paInt16 # 采样时生成wav文件正常格式
CHANNELS = 1 # 音轨数(每条音轨定义了该条音轨的属性,如音轨的音色、音色库、通道数、输入/输出端口、音量等。可以多个音轨,不唯一)
RATE = 16000 # 采样率(即每秒采样多少数据)
RECORD_SECONDS = time # 录音时间
WAVE_OUTPUT_FILENAME = "./output.wav" # 保存音频路径
p = pyaudio.PyAudio() # 创建PyAudio对象
stream = p.open(format=FORMAT, # 采样生成wav文件的正常格式
channels=CHANNELS, # 音轨数
rate=RATE, # 采样率
input=True, # Ture代表这是一条输入流,False代表这不是输入流
frames_per_buffer=CHUNK) # 每个缓冲多少帧
print("* recording") # 开始录音标志
frames = [] # 定义frames为一个空列表
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)): # 计算要读多少次,每秒的采样率/每次读多少数据*录音时间=需要读多少次
data = stream.read(CHUNK) # 每次读chunk个数据
frames.append(data) # 将读出的数据保存到列表中
print("* done recording") # 结束录音标志
stream.stop_stream() # 停止输入流
stream.close() # 关闭输入流
p.terminate() # 终止pyaudio
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb') # 以’wb‘二进制流写的方式打开一个文件
wf.setnchannels(CHANNELS) # 设置音轨数
wf.setsampwidth(p.get_sample_size(FORMAT)) # 设置采样点数据的格式,和FOMART保持一致
wf.setframerate(RATE) # 设置采样率与RATE要一致
wf.writeframes(b''.join(frames)) # 将声音数据写入文件
wf.close() # 数据流保存完,关闭文件
if __name__ == '__main__':
model = whisper.load_model("base")
record(3) # 定义录音时间,单位/s
audio = whisper.load_audio("output.wav")
audio = whisper.pad_or_trim(audio)
mel = whisper.log_mel_spectrogram(audio).to(model.device)
_, probs = model.detect_language(mel)
print(f"Detected language: {max(probs, key=probs.get)}")
options = whisper.DecodingOptions(language='Chinese',fp16 = True)
result = whisper.decode(model, mel, options)
s1 = zhconv.convert(result.text, 'zh-cn')
print(s1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
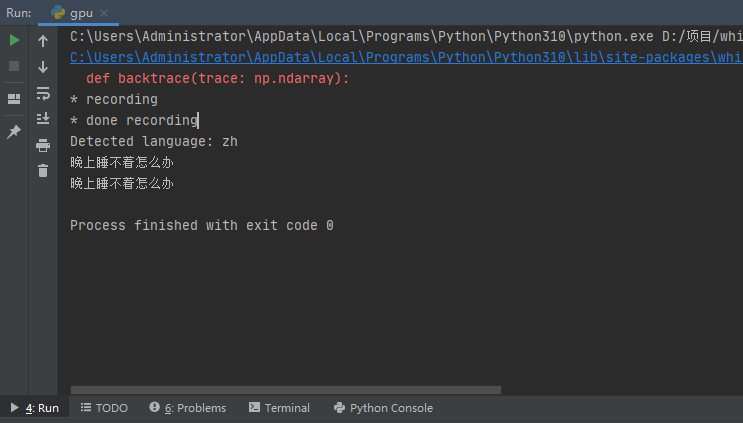
9.展示实时翻译结果
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/288891
推荐阅读
相关标签

