
- 1vue写图片轮播图_uview轮播图怎么写本地下载的图片
- 2华为HuaweiCloudStack(一)介绍与架构_华为hcs部署
- 3如何通过pdb调试multiprocesses程序(by quqi99)_pdb 进入子进程
- 4每日新闻 | 鸿蒙有望成为安卓终结者甚至可能改变硅谷
- 5大数据毕设 机器视觉 opencv 深度学习 驾驶人脸疲劳检测系统 -python_人脸识别疲劳驾驶监测系统应用开发
- 6ffmpeg视频处理常用命令
- 7【云原生--Kubernetes】Helm 工具安装_helm 下载
- 82种Android图表的简单介绍+折线图、饼图的例子,高级程序员面试题_com.github.mikephil.charting.charts
- 9nginx 上配置二级目录访问 vue 项目_vue nginx配置二级目录
- 10eclipse,idea安装lombok,以及lombok的使用_lombok/launch/patchfixeshider myeclipse
AlexNet VGGNet ResNet 对比 简介_resnet与vgg对比
赞
踩
AlexNet
网络结构

- 输入层: 224 * 224, 3通道
- 第一层卷积: 96个11 * 11的卷积核, stride 是 4
- 可以利用计算公式
输出大小 = (输入大小 - 卷积核大小 + padding) / stride + 1来计算 - 参数数目: 3 * 11 * 11 * 96
- 可以利用计算公式
- 第二层卷积: 256个5*5的卷积核
- 第二层Max pooling
- …
- 第一层全连接: 4096
- 第二层全连接: 4096
- 输出层: 1000个数的向量, 表示总共1000种类别的概率值
多GPU
结构图中可以看到模型分为了上下两部分, 两部分分别用一个GPU来运算, 可以提高运行速度, 因此也可以增大网络的规模
Relu
数学表达
f
(
x
)
=
m
a
x
(
0
,
x
)
f(x) = max(0, x)
f(x)=max(0,x)
使用 Relu 训练速度更快
Dropout
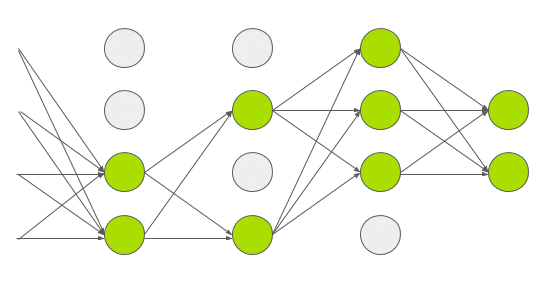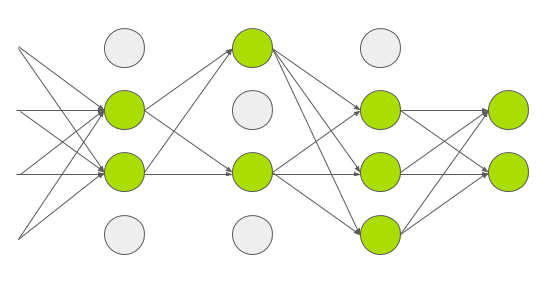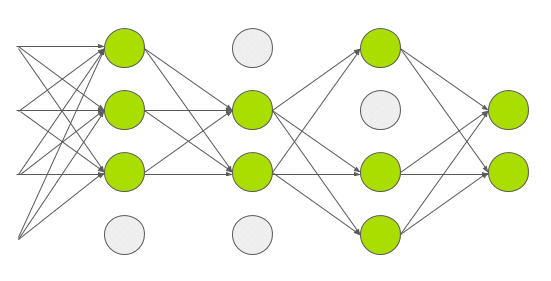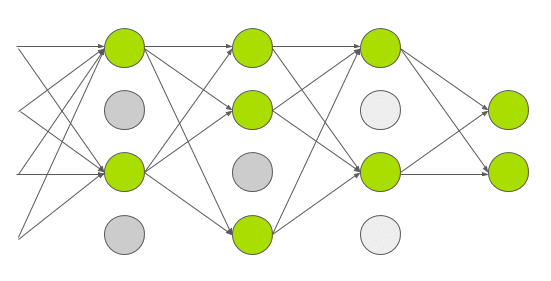
每一运算都会随机地将一些神经元置为 0
Dropout 用在了全连接层上, 因为全连接层的参数较多(4096 * 4096), 容易过拟合
AlexNet 中设置的 Dropout = 0.5
工作原理:
- 每次 Dropout 都相当于训练一个原来的网络的子网络, 最后的结果相当于很多子网络的组合, 所以训练的效果会好些
- 模型的泛化能力差的原因在于神经元记住了训练的样本, 要记住样本的特征显然需要多个神经元, 而 Dropout 是随机选择神经元的, 能够消除神经元之间的依赖关系, 增强泛化能力
- Dropout 也相当于数据增强
层叠池化
AlexNet 中使用的是 Overlapping Max Pooling, 池化的窗口每次移动的步长小于它的长度
AlexNet 使用的是 3 * 3 的正方形, 每次移动步长为 2, 重叠池化可以避免过拟合
但其实也可以用步长较大的卷积层代替
图片的随机采样
图片的原大小是[256, 256], 但是输入图片的大小为[224, 224], 每次只输入图像的一部分, 每次取原来图像的一部分, 相当于换了一个角度看图片, 也相当于增加了训练的数据(数据增强), 训练出来的模型泛化能力会更强
其他
- SGD momentum = 0.9 动量梯度下降
- Batch size = 128
- Learning rate = 0.01, 每训练一定次数, 学习率缩小10倍
- 训练读多个CNN模型, 然后做投票ensemble
VGGNet
Very Deep Convolutional Networks
网络结构

- 每经过一个pooling层, 通道数目翻倍, 因为pooling会丢失某些信息, 所以通过增加通道数来弥补, 但是增加到512后, 便不再增加了, 可能是考虑到算力, 内存的问题
- FC全连接层, 最后输出的是1000个类的分类结果
- 看D, E, 加卷积层都是在后面加, 因为前面的图片太大, 运算起来太耗时, maxpooling后, 神经图变小
- 纵向地看, 可以看到神经网络是由浅到深的. VGGNet采用递进式训练, 可以先训练浅层网络A, 然后用A初始化好的参数去训练后面深层的网络
3*3 卷积核


如图所示, 2层的 3*3 卷积核可以替代1层的 5*5 卷积核 (步长为1)
- 两种方式的视野域是一样的, 输入输出格式都不变
- 2层比1层多一次非线性变化, 网络深度增加也能够保证学习更复杂的模式
- 采用堆积的小卷积核还可以减少参数数目, 还是拿上图举例(一个绿色方形代表一个参数), 假定输入输出通道数都是 C C C, 那么两层结构的参数数目为 2*3*3* C 2 C^2 C2, 单层结构的参数数目是 5*5* C 2 C^2 C2, 多了28%的数目
如果上面两张图不能理解可以结合一下这张神图
(左边一列表示输入, 通道数3, 中间两列就是参数, 两个神经元, 右边是输出, 通道数2, 总共3*3*3*2个参数)
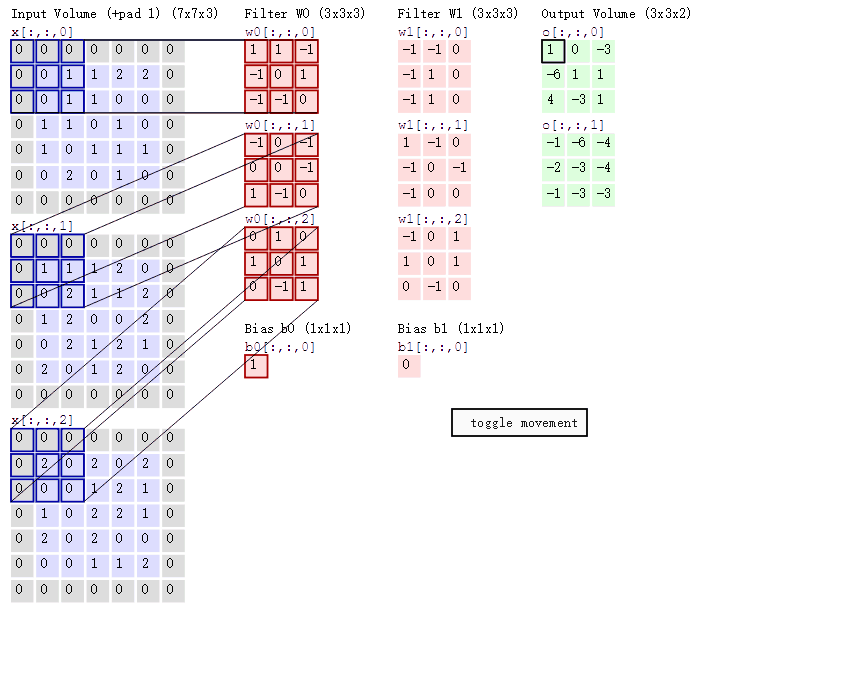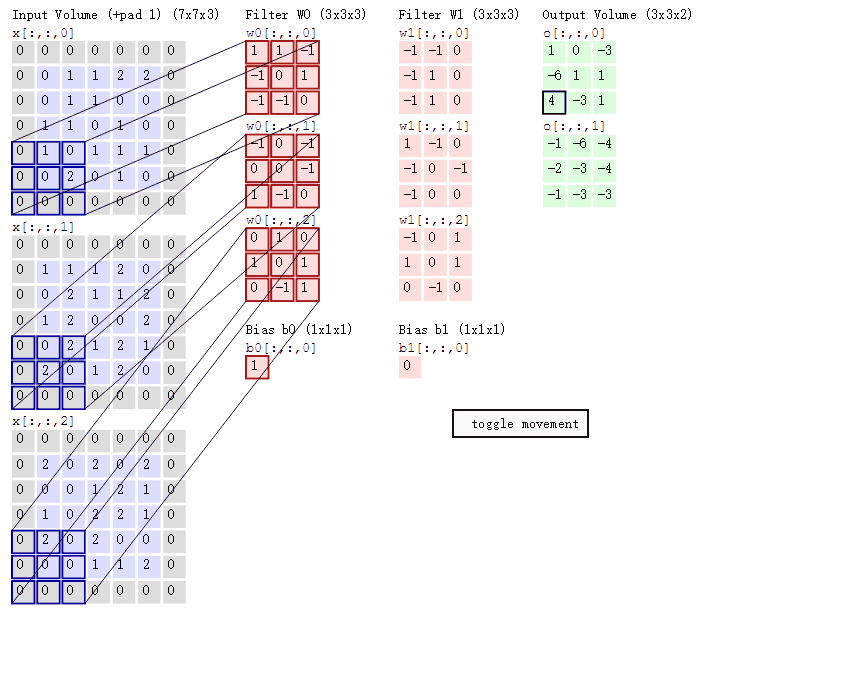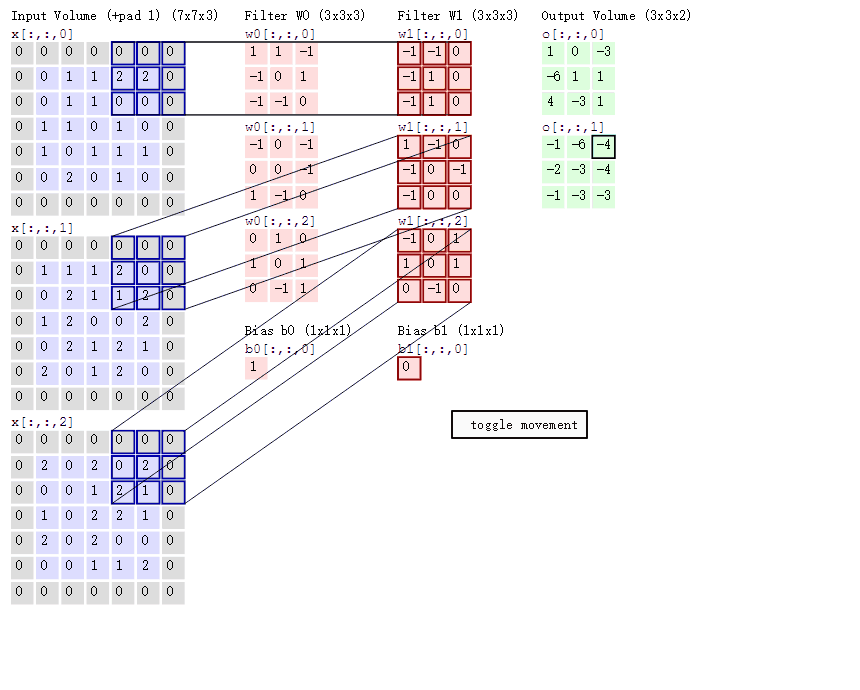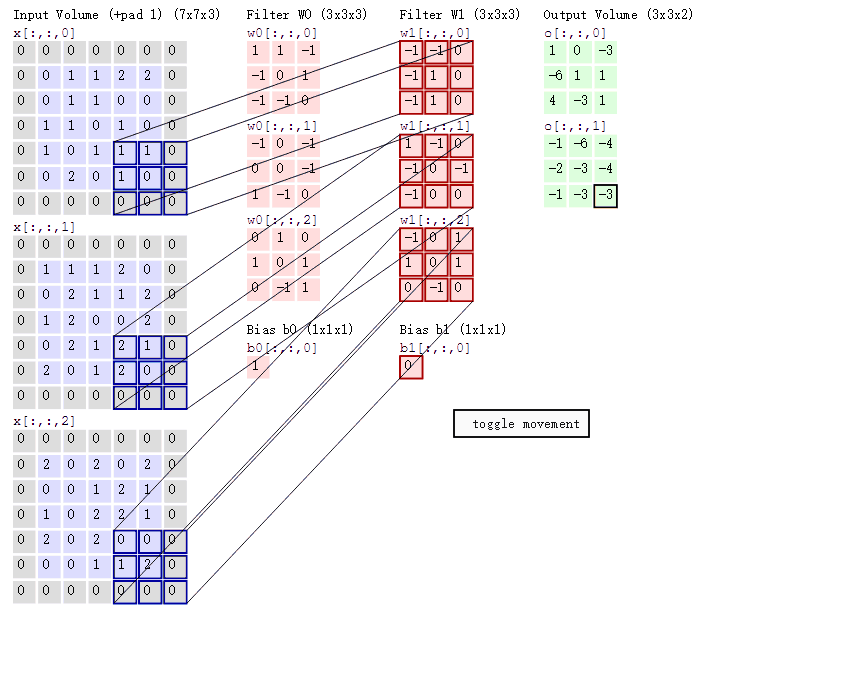
1*1 卷积核

- 1*1卷积核不改变长宽, 只改变通道数
- 1*1卷积核相当于通道间的非线性变化
- 可以对通道数降维, 同时不损失信息
- 比如原来是32*32*100, 经过1*1*20的卷积后得到32*32*20
LRN
局部归一化, 把相邻的几个通道进行归一化
快过时了
其他
- 多尺度输入: AlexNet中也有用到(就是从不同的角度看图片), VGGNet做的更极端, 它随机使用不同的尺度缩放训练多个分类器, 然后做ensemble
ResNet
Residual Network
退化问题

VGGNet中我们可以看出深度对于神经网络的重要性, 但从图中可以看出网络深度达到一定程度时, 深层网络的总体表现不如浅层网络, 这种现象称为退化问题(degradation problem)
为什么会这样?
如果是因为梯度消失, 梯度爆炸, 可以通过中间层标准化(batch normalization)等缓解
也不是过拟合造成的, 因为训练集上深层网络也不如浅层的
可能是因为网络越深, 参数越多, 优化也就更难
ResNet的提出就是为了解决这种退化问题
残差学习

- Identity: 恒等变换, shortcuts, 没有引入额外的参数, 不会增加计算复杂性
- H ( x ) H(x) H(x): 期望的结果
- F ( x ) = H ( x ) − x F(x) = H(x)-x F(x)=H(x)−x, 为残差 (残差定义: 数理统计上, 残差表示实际观测值与估计值(拟合值)的差, 蕴含模型的重要信息.), F F F通常包括卷积, 激活等操作, 上图是2层网络, 当然也可以更多层, 如果只有1层, 就退化为线性
H ( x ) − x H(x)-x H(x)−x对 x x x求偏导后会有一个恒等项1, 使用链式法则求导时,
残差网络子结构

网络结构
下图为VGG-19, 34层的普通卷积神经网络, 34层的ResNet网络的对比图


- conv1: 普通卷积层, 步长是2
- 经过3*3的maxpooling层, 就是一堆残差网络结构
- 深层网络相对于浅层网络主要是在conv4层增加了更多层
- 最后只有一个全连接层, 所以参数数目会少, 可以加到卷积层上
reference
- AlexNet: Sunita Nayak, https://www.learnopencv.com/understanding-alexnet/
- ResNet: nowgood, https://www.cnblogs.com/nowgood/p/resnet.html
- ResNet: Kaiming He, https://developer.aliyun.com/article/176771
- ResNet: 木瓜子, https://zhuanlan.zhihu.com/p/43200566
- ResNet 论文: Kaiming He, https://www.cv-foundation.org/openaccess/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
- KOUSTUBH, https://cv-tricks.com/cnn/understand-resnet-alexnet-vgg-inception/

