
- 1HarmonyOS鸿蒙学习笔记(4)Tabs模仿安卓ViewPager+Fragment的效果_harmony viewpager
- 2paging从使用到放弃,再到使用_pagingconfig pagingsource
- 3【免费】如何考取《鲸鸿动能广告初级优化师》认证(详细教程)
- 4Linux网络协议原理_linux、tcp/ip、http、dns等常用协议的传输原理
- 5AndroidStudio 4.1 阿里网盘下载_android studio 4.1. 下载
- 6【笔记】微信小程序组件swiper实现跑马灯(marquee)效果_swiper走马灯
- 7Android架构之Paging组件(一)_android paging
- 8AI读懂说话人情绪,语音情感识别数据等你Pick!_ai 语音情绪分类
- 9open,write,read函数总结_python 查看open 打开的文件数量
- 10vue中this.$router.push路由2种传参以及获取方法_vuethis.$router.push 接收参数
深度学习:07 CNN经典模型总结(LeNet-5、AlexNet、VGG、GoogLeNet、ResNet)_cnn模型
赞
踩
目录
CNN经典网络模型
以下介绍了LeNet-5、AlexNet、VGG、GoogLeNet、ResNet等,它们通常用于图像的数据处理,那么卷积神经网络是否应用于自然语言分类任务呢,其实还有一种利用CNN进行自然语言处理的网络结构——TextCNN网络,感兴趣的大家可以去了解。
LeNet-5
1998, Yann LeCun 的 LeNet5 官网
卷积神经网路的开山之作,麻雀虽小,但五脏俱全,卷积层、pooling层、全连接层,这些都是现代CNN网络的基本组件
- 用卷积提取空间特征;
- 由空间平均得到子样本;
- 用 tanh 或 sigmoid 得到非线性;
- 用 multi-layer neural network(MLP)作为最终分类器;
- 层层之间用稀疏的连接矩阵,以避免大的计算成本。

输入:图像Size为32*32,这要比mnist数据库中最大的字母(28*28)还大。这样做的目的是希望潜在的明显特征,如笔画断续、角点能够出现在最高层特征监测子感受野的中心。
输出:10个类别,分别为0-9数字的概率
- C1层是一个卷积层,有6个卷积核(提取6种局部特征),核大小为5 * 5,针对一张32 * 32的灰度图像会输出6个28 * 28的特征映射。
- S2层是pooling层,下采样(区域:2 * 2 ),步长为2,将6个28 * 28的特征映射转化为6个14 * 14的特征映射,降低网络训练参数及模型的过拟合程度。
- C3层是第二个卷积层,使用16个卷积核,核大小:5 * 5 提取特征,不使用填补操作,将6个14 * 14的特征映射卷积运算后输出16个10 * 10的特征映射
- S4层也是一个pooling层,区域:2*2,步长为2,从而将16个10 * 10的特征映射转化为16个5 * 5的特征映射
- C5层是最后一个卷积层,卷积核大小:5 * 5 卷积核种类:120,神经元数量为120
- 最后使用全连接层,将C5的120个特征进行分类,最后输出0-9的概率,神经元数量为84
以下代码来自官方教程
- import torch
- import torch.nn as nn
- import torch.nn.functional as F
- class LeNet5(nn.Module):
-
- def __init__(self):
- super(LeNet5, self).__init__()
- # 1 input image channel, 6 output channels, 5x5 square convolution
- # kernel
- self.conv1 = nn.Conv2d(1, 6, 5)
- self.conv2 = nn.Conv2d(6, 16, 5)
- # an affine operation: y = Wx + b
- self.fc1 = nn.Linear(16 * 5 * 5, 120) # 这里论文上写的是conv,官方教程用了线性层
- self.fc2 = nn.Linear(120, 84)
- self.fc3 = nn.Linear(84, 10)
-
- def forward(self, x):
- # Max pooling over a (2, 2) window
- x = F.max_pool2d(F.relu(self.conv1(x)), (2, 2))
- # If the size is a square you can only specify a single number
- x = F.max_pool2d(F.relu(self.conv2(x)), 2)
- x = x.view(-1, self.num_flat_features(x))
- x = F.relu(self.fc1(x))
- x = F.relu(self.fc2(x))
- x = self.fc3(x)
- return x
-
- def num_flat_features(self, x):
- size = x.size()[1:] # all dimensions except the batch dimension
- num_features = 1
- for s in size:
- num_features *= s
- return num_features
-
-
- net = LeNet5()
- print(net)

输出:
- LeNet5(
- (conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))
- (conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))
- (fc1): Linear(in_features=400, out_features=120, bias=True)
- (fc2): Linear(in_features=120, out_features=84, bias=True)
- (fc3): Linear(in_features=84, out_features=10, bias=True)
- )
AlexNet
2012,Alex Krizhevsky 可以算作LeNet的一个更深和更广的版本,可以用来学习更复杂的对象 论文
- 用rectified linear units(ReLU)得到非线性;
- 使用 dropout 技巧在训练期间有选择性地忽略单个神经元,来减缓模型的过拟合;
- 重叠最大池,避免平均池的平均效果;
- 使用 GPU NVIDIA GTX 580 可以减少训练时间,这比用CPU处理快了 10 倍,所以可以被用于更大的数据集和图像上。
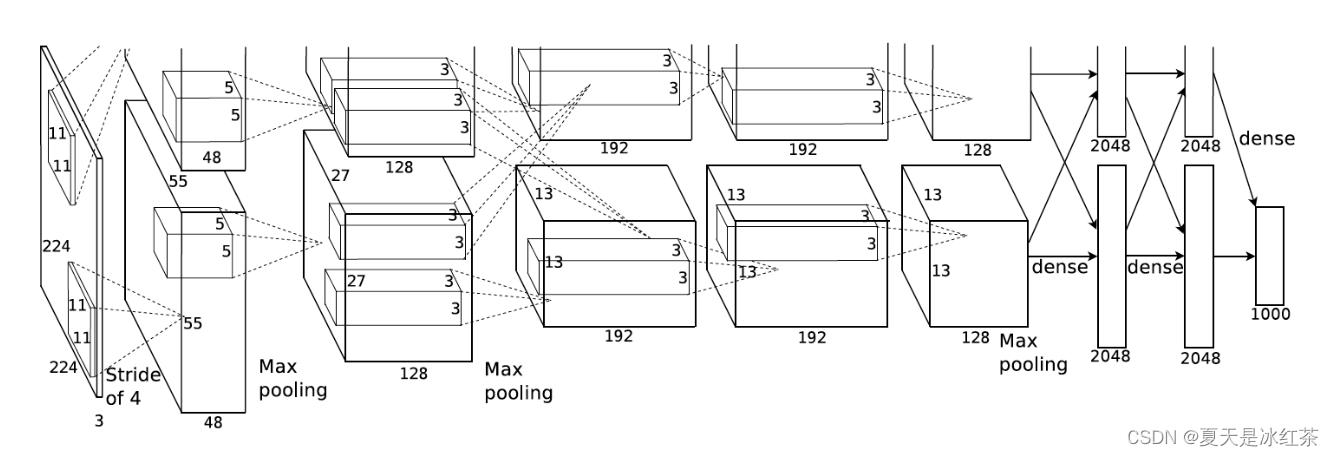 虽然 AlexNet只有8层,但是它有60M以上的参数总量,Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理,这里就不做详细介绍了, Alexnet的每一阶段(含一次卷积主要计算的算作一层)可以分为8层:
虽然 AlexNet只有8层,但是它有60M以上的参数总量,Alexnet有一个特殊的计算层,LRN层,做的事是对当前层的输出结果做平滑处理,这里就不做详细介绍了, Alexnet的每一阶段(含一次卷积主要计算的算作一层)可以分为8层: - con - relu - pooling - LRN : 要注意的是input层是227*227,而不是paper里面的224,这里可以算一下,主要是227可以整除后面的conv1计算,224不整除。如果一定要用224可以通过自动补边实现,不过在input就补边感觉没有意义,补得也是0,这就是我们上面说的公式的重要性。
- conv - relu - pool - LRN : group=2,这个属性强行把前面结果的feature map分开,卷积部分分成两部分做
- conv - relu
- conv - relu
- conv - relu - pool
- fc - relu - dropout : dropout层,在alexnet中是说在训练的以1/2概率使得隐藏层的某些neuron的输出为0,这样就丢到了一半节点的输出,BP的时候也不更新这些节点,防止过拟合。
- fc - relu - dropout
- fc - softmax
在Pytorch的vision包中是包含Alexnet的官方实现的,我们直接使用官方版本看下网络
- import torchvision
- model = torchvision.models.alexnet(pretrained=False) #我们不下载预训练权重
- print(model)
输出:
- AlexNet(
- (features): Sequential(
- (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))
- (1): ReLU(inplace=True)
- (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
- (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
- (4): ReLU(inplace=True)
- (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
- (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (7): ReLU(inplace=True)
- (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (9): ReLU(inplace=True)
- (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (11): ReLU(inplace=True)
- (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
- )
- (avgpool): AdaptiveAvgPool2d(output_size=(6, 6))
- (classifier): Sequential(
- (0): Dropout(p=0.5, inplace=False)
- (1): Linear(in_features=9216, out_features=4096, bias=True)
- (2): ReLU(inplace=True)
- (3): Dropout(p=0.5, inplace=False)
- (4): Linear(in_features=4096, out_features=4096, bias=True)
- (5): ReLU(inplace=True)
- (6): Linear(in_features=4096, out_features=1000, bias=True)
- )
- )
VGG
2015,牛津的 VGG。论文
- 每个卷积层中使用更小的 3×3 filters,并将它们组合成卷积序列
- 多个3×3卷积序列可以模拟更大的接收场的效果
- 每次的图像像素缩小一倍,卷积核的数量增加一倍
VGG有很多个版本,也算是比较稳定和经典的model。它的特点也是连续conv多计算量巨大,这里我们以VGG16为例.图片来源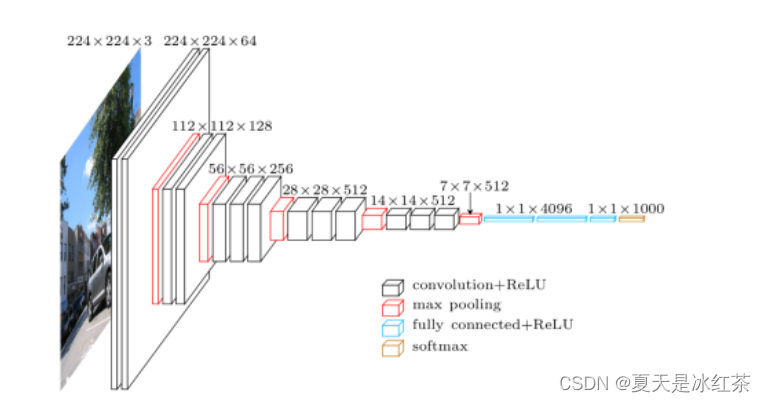 VGG清一色用小卷积核,结合作者和自己的观点,这里整理出小卷积核比用大卷积核的优势:
VGG清一色用小卷积核,结合作者和自己的观点,这里整理出小卷积核比用大卷积核的优势:
根据作者的观点,input8 -> 3层conv3x3后,output=2,等同于1层conv7x7的结果; input=8 -> 2层conv3x3后,output=2,等同于2层conv5x5的结果
卷积层的参数减少。相比5x5、7x7和11x11的大卷积核,3x3明显地减少了参数量
通过卷积和池化层后,图像的分辨率降低为原来的一半,但是图像的特征增加一倍,这是一个十分规整的操作: 分辨率由输入的224->112->56->28->14->7, 特征从原始的RGB3个通道-> 64 ->128 -> 256 -> 512
这为后面的网络提供了一个标准,我们依旧使用Pytorch官方实现版本来查看
- import torchvision
- model = torchvision.models.vgg16(pretrained=False) #我们不下载预训练权重
- print(model)
输出:
- VGG(
- (features): Sequential(
- (0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (1): ReLU(inplace=True)
- (2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (3): ReLU(inplace=True)
- (4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- (5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (6): ReLU(inplace=True)
- (7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (8): ReLU(inplace=True)
- (9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- (10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (11): ReLU(inplace=True)
- (12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (13): ReLU(inplace=True)
- (14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (15): ReLU(inplace=True)
- (16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- (17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (18): ReLU(inplace=True)
- (19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (20): ReLU(inplace=True)
- (21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (22): ReLU(inplace=True)
- (23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- (24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (25): ReLU(inplace=True)
- (26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (27): ReLU(inplace=True)
- (28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
- (29): ReLU(inplace=True)
- (30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
- )
- (avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
- (classifier): Sequential(
- (0): Linear(in_features=25088, out_features=4096, bias=True)
- (1): ReLU(inplace=True)
- (2): Dropout(p=0.5, inplace=False)
- (3): Linear(in_features=4096, out_features=4096, bias=True)
- (4): ReLU(inplace=True)
- (5): Dropout(p=0.5, inplace=False)
- (6): Linear(in_features=4096, out_features=1000, bias=True)
- )
- )
GoogLeNet (Inception)
2014,Google Christian Szegedy 论文
- 使用1×1卷积块(NiN)来减少特征数量,这通常被称为“瓶颈”,可以减少深层神经网络的计算负担。
- 每个池化层之前,增加 feature maps,增加每一层的宽度来增多特征的组合性
googlenet最大的特点就是包含若干个inception模块,所以有时候也称作 inception net。 googlenet虽然层数要比VGG多很多,但是由于inception的设计,计算速度方面要快很多。
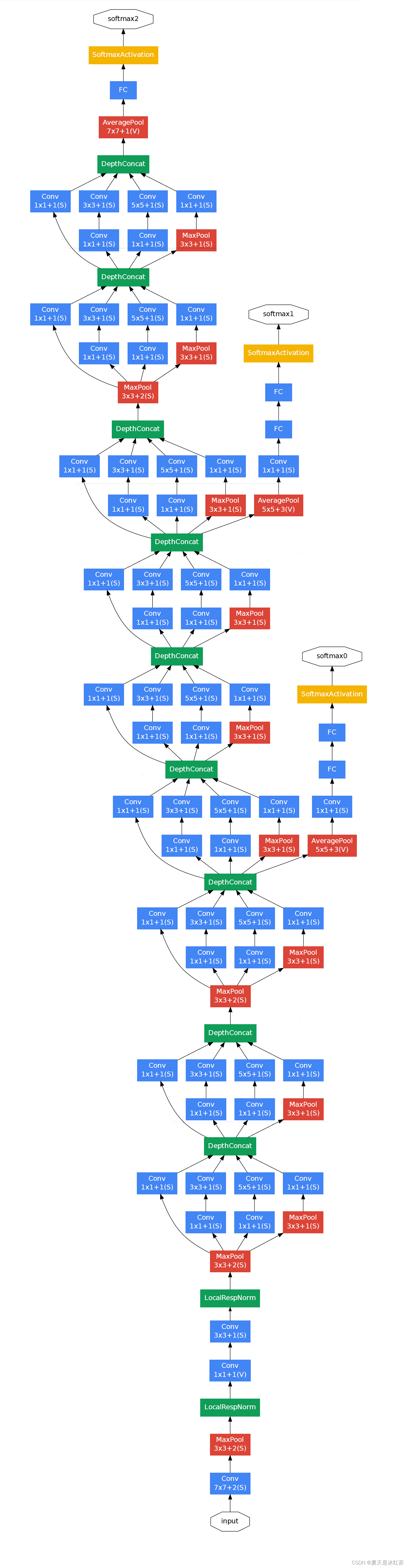
不要被这个图吓到,其实原理很简单
Inception架构的主要思想是找出如何让已有的稠密组件接近与覆盖卷积视觉网络中的最佳局部稀疏结构。现在需要找出最优的局部构造,并且重复几次。之前的一篇文献提出一个层与层的结构,在最后一层进行相关性统计,将高相关性的聚集到一起。这些聚类构成下一层的单元,且与上一层单元连接。假设前面层的每个单元对应于输入图像的某些区域,这些单元被分为滤波器组。在接近输入层的低层中,相关单元集中在某些局部区域,最终得到在单个区域中的大量聚类,在最后一层通过1x1的卷积覆盖。
上面的话听起来很生硬,其实解释起来很简单:每一模块我们都是用若干个不同的特征提取方式,例如 3x3卷积,5x5卷积,1x1的卷积,pooling等,都计算一下,最后再把这些结果通过Filter Concat来进行连接,找到这里面作用最大的。而网络里面包含了许多这样的模块,这样不用我们人为去判断哪个特征提取方式好,网络会自己解决(是不是有点像AUTO ML),在Pytorch中实现了InceptionA-E,还有InceptionAUX 模块。
- # inception_v3需要scipy,所以没有安装的话pip install scipy 一下
- import torchvision
- model = torchvision.models.inception_v3(pretrained=False) #我们不下载预训练权重
- print(model)
输出:
- Inception3(
- (Conv2d_1a_3x3): BasicConv2d(
- (conv): Conv2d(3, 32, kernel_size=(3, 3), stride=(2, 2), bias=False)
- (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (Conv2d_2a_3x3): BasicConv2d(
- (conv): Conv2d(32, 32, kernel_size=(3, 3), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (Conv2d_2b_3x3): BasicConv2d(
- (conv): Conv2d(32, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (maxpool1): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
- (Conv2d_3b_1x1): BasicConv2d(
- (conv): Conv2d(64, 80, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(80, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (Conv2d_4a_3x3): BasicConv2d(
- (conv): Conv2d(80, 192, kernel_size=(3, 3), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (maxpool2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False)
- (Mixed_5b): InceptionA(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch5x5_1): BasicConv2d(
- (conv): Conv2d(192, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch5x5_2): BasicConv2d(
- (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_1): BasicConv2d(
- (conv): Conv2d(192, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_2): BasicConv2d(
- (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_3): BasicConv2d(
- (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(192, 32, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(32, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_5c): InceptionA(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch5x5_1): BasicConv2d(
- (conv): Conv2d(256, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch5x5_2): BasicConv2d(
- (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_1): BasicConv2d(
- (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_2): BasicConv2d(
- (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_3): BasicConv2d(
- (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_5d): InceptionA(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch5x5_1): BasicConv2d(
- (conv): Conv2d(288, 48, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(48, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch5x5_2): BasicConv2d(
- (conv): Conv2d(48, 64, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_1): BasicConv2d(
- (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_2): BasicConv2d(
- (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_3): BasicConv2d(
- (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_6a): InceptionB(
- (branch3x3): BasicConv2d(
- (conv): Conv2d(288, 384, kernel_size=(3, 3), stride=(2, 2), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_1): BasicConv2d(
- (conv): Conv2d(288, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(64, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_2): BasicConv2d(
- (conv): Conv2d(64, 96, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_3): BasicConv2d(
- (conv): Conv2d(96, 96, kernel_size=(3, 3), stride=(2, 2), bias=False)
- (bn): BatchNorm2d(96, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_6b): InceptionC(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_1): BasicConv2d(
- (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_2): BasicConv2d(
- (conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_3): BasicConv2d(
- (conv): Conv2d(128, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_1): BasicConv2d(
- (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_2): BasicConv2d(
- (conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_3): BasicConv2d(
- (conv): Conv2d(128, 128, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_4): BasicConv2d(
- (conv): Conv2d(128, 128, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_5): BasicConv2d(
- (conv): Conv2d(128, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_6c): InceptionC(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_1): BasicConv2d(
- (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_2): BasicConv2d(
- (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_3): BasicConv2d(
- (conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_1): BasicConv2d(
- (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_2): BasicConv2d(
- (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_3): BasicConv2d(
- (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_4): BasicConv2d(
- (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_5): BasicConv2d(
- (conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_6d): InceptionC(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_1): BasicConv2d(
- (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_2): BasicConv2d(
- (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_3): BasicConv2d(
- (conv): Conv2d(160, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_1): BasicConv2d(
- (conv): Conv2d(768, 160, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_2): BasicConv2d(
- (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_3): BasicConv2d(
- (conv): Conv2d(160, 160, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_4): BasicConv2d(
- (conv): Conv2d(160, 160, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(160, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_5): BasicConv2d(
- (conv): Conv2d(160, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_6e): InceptionC(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_1): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_2): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7_3): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_1): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_2): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_3): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_4): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7dbl_5): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (AuxLogits): InceptionAux(
- (conv0): BasicConv2d(
- (conv): Conv2d(768, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(128, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (conv1): BasicConv2d(
- (conv): Conv2d(128, 768, kernel_size=(5, 5), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(768, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (fc): Linear(in_features=768, out_features=1000, bias=True)
- )
- (Mixed_7a): InceptionD(
- (branch3x3_1): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3_2): BasicConv2d(
- (conv): Conv2d(192, 320, kernel_size=(3, 3), stride=(2, 2), bias=False)
- (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7x3_1): BasicConv2d(
- (conv): Conv2d(768, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7x3_2): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(1, 7), stride=(1, 1), padding=(0, 3), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7x3_3): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(7, 1), stride=(1, 1), padding=(3, 0), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch7x7x3_4): BasicConv2d(
- (conv): Conv2d(192, 192, kernel_size=(3, 3), stride=(2, 2), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_7b): InceptionE(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(1280, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3_1): BasicConv2d(
- (conv): Conv2d(1280, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3_2a): BasicConv2d(
- (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3_2b): BasicConv2d(
- (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_1): BasicConv2d(
- (conv): Conv2d(1280, 448, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_2): BasicConv2d(
- (conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_3a): BasicConv2d(
- (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_3b): BasicConv2d(
- (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(1280, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (Mixed_7c): InceptionE(
- (branch1x1): BasicConv2d(
- (conv): Conv2d(2048, 320, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(320, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3_1): BasicConv2d(
- (conv): Conv2d(2048, 384, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3_2a): BasicConv2d(
- (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3_2b): BasicConv2d(
- (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_1): BasicConv2d(
- (conv): Conv2d(2048, 448, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(448, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_2): BasicConv2d(
- (conv): Conv2d(448, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_3a): BasicConv2d(
- (conv): Conv2d(384, 384, kernel_size=(1, 3), stride=(1, 1), padding=(0, 1), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch3x3dbl_3b): BasicConv2d(
- (conv): Conv2d(384, 384, kernel_size=(3, 1), stride=(1, 1), padding=(1, 0), bias=False)
- (bn): BatchNorm2d(384, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- (branch_pool): BasicConv2d(
- (conv): Conv2d(2048, 192, kernel_size=(1, 1), stride=(1, 1), bias=False)
- (bn): BatchNorm2d(192, eps=0.001, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
- (dropout): Dropout(p=0.5, inplace=False)
- (fc): Linear(in_features=2048, out_features=1000, bias=True)
- )
ResNet
2015,Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun 论文 Kaiming He 何凯明(音译)这个大神大家一定要记住,现在很多论文都有他参与(mask rcnn, focal loss),Jian Sun孙剑老师就不用说了,现在旷视科技的首席科学家。 刚才的GoogLeNet已经很深了,ResNet可以做到更深,通过残差计算,可以训练超过1000层的网络,俗称跳连接
退化问题
网络层数增加,但是在训练集上的准确率却饱和甚至下降了。这个不能解释为overfitting,因为overfit应该表现为在训练集上表现更好才对。这个就是网络退化的问题,退化问题说明了深度网络不能很简单地被很好地优化
残差网络的解决办法
深层网络的后面那些层是恒等映射,那么模型就退化为一个浅层网络。那现在要解决的就是学习恒等映射函数了。让一些层去拟合一个潜在的恒等映射函数H(x) = x,比较困难。如果把网络设计为H(x) = F(x) + x。我们可以转换为学习一个残差函数F(x) = H(x) - x。 只要F(x)=0,就构成了一个恒等映射H(x) = x. 而且,拟合残差肯定更加容易。
以上又很不好理解,继续解释下,先看图:
我们在激活函数前将上一层(或几层)的输出与本层计算的输出相加,将求和的结果输入到激活函数中做为本层的输出,引入残差后的映射对输出的变化更敏感,其实就是看本层相对前几层是否有大的变化,相当于是一个差分放大器的作用。图中的曲线就是残差中的shoutcut,他将前一层的结果直接连接到了本层,也就是俗称的跳连接。
我们以经典的resnet18来看一下网络结构 图片来源

- import torchvision
- model = torchvision.models.resnet18(pretrained=False) #我们不下载预训练权重
- print(model)
输出:
- ResNet(
- (conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
- (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
- (layer1): Sequential(
- (0): BasicBlock(
- (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- (1): BasicBlock(
- (conv1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (layer2): Sequential(
- (0): BasicBlock(
- (conv1): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
- (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (downsample): Sequential(
- (0): Conv2d(64, 128, kernel_size=(1, 1), stride=(2, 2), bias=False)
- (1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (1): BasicBlock(
- (conv1): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (layer3): Sequential(
- (0): BasicBlock(
- (conv1): Conv2d(128, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
- (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (downsample): Sequential(
- (0): Conv2d(128, 256, kernel_size=(1, 1), stride=(2, 2), bias=False)
- (1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (1): BasicBlock(
- (conv1): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (layer4): Sequential(
- (0): BasicBlock(
- (conv1): Conv2d(256, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
- (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (downsample): Sequential(
- (0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
- (1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (1): BasicBlock(
- (conv1): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- (relu): ReLU(inplace=True)
- (conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
- (bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
- )
- )
- (avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
- (fc): Linear(in_features=512, out_features=1000, bias=True)
- )
如何选择网络
那么我们该如何选择网络呢? 来源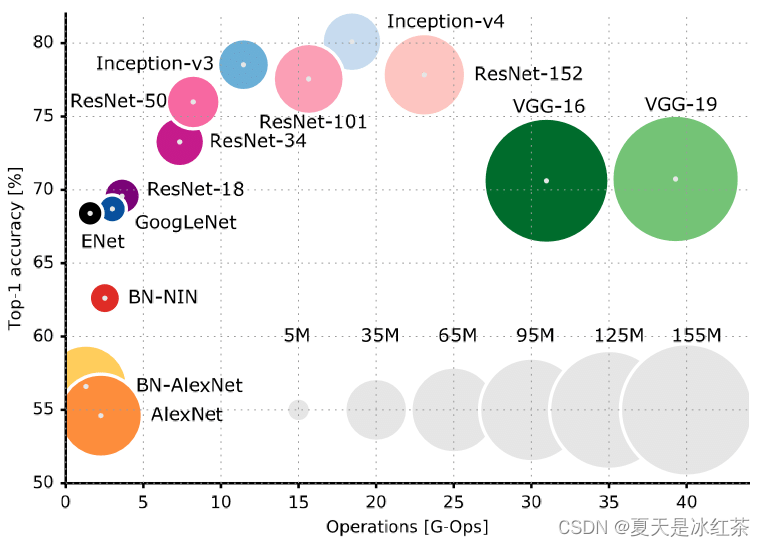
以上表格可以清楚的看到准确率和计算量之间的对比。我的建议是,小型图片分类任务,resnet18基本上已经可以了,如果真对准确度要求比较高,再选其他更好的网络架构。
另外有句俗话叫:穷人只能AlexNet,富人才用Res

