
- 1王姨劝我学HarmonyOS鸿蒙2.0系列教程之五布局方法&&点击响应!
- 2Flutter 按钮介绍 CupertinoButton、TextButton、ElevatedButton、OutlinedButton、IconButton
- 3android简单app实例代码_一个简单的部门案例详解(PHP代码实例)
- 4基于spring boot实现登录功能_spring boot 实现登录页面
- 5深入WPF中的图像画刷(ImageBrush)之1——ImageBrush使用举例
- 6微信小程序实现token登录_koa2 微信小程序登录 生成token
- 7Postgresql:查看表、索引、表空间大小,top 10_pgsql查看表空间
- 8Android 系统属性(SystemProperties)介绍
- 9python中可选参数和可变参数_Python函数中的可变长参数详解
- 10PYQT5 打包后无法显示jpg图片问题_pyqt5打包后graphicsview图片不显示
保姆级使用PyTorch训练与评估自己的SEResNet网络教程_se resnetxt pytorch
赞
踩

前言
项目地址:https://github.com/Fafa-DL/Awesome-Backbones
视频手把手教程:https://www.bilibili.com/video/BV1SY411P7Nd
SEResNet原论文:点我跳转
如果你以为该仓库仅支持训练一个模型那就大错特错了,我在项目地址放了目前支持的35种模型(LeNet5、AlexNet、VGG、DenseNet、ResNet、Wide-ResNet、ResNeXt、SEResNet、SEResNeXt、RegNet、MobileNetV2、MobileNetV3、ShuffleNetV1、ShuffleNetV2、EfficientNet、RepVGG、Res2Net、ConvNeXt、HRNet、ConvMixer、CSPNet、Swin-Transformer、Vision-Transformer、Transformer-in-Transformer、MLP-Mixer、DeiT、Conformer、T2T-ViT、Twins、PoolFormer、VAN、HorNet、EfficientFormer、Swin Transformer V2、MViT V2),使用方式一模一样,一个仓库涵盖上述全部模型,且满足了大部分图像分类需求,进度快的同学甚至论文已经在审了
0. 环境搭建&快速开始
- 这一步我也在最近录制了视频
- 不想看视频也将文字版放在此处。建议使用Anaconda进行环境管理,创建环境命令如下
conda create -n [name] python=3.6 其中[name]改成自己的环境名,如[name]->torch,conda create -n torch python=3.6
- 1
- 我的测试环境如下
torch==1.7.1
torchvision==0.8.2
scipy==1.4.1
numpy==1.19.2
matplotlib==3.2.1
opencv_python==3.4.1.15
tqdm==4.62.3
Pillow==8.4.0
h5py==3.1.0
terminaltables==3.1.0
packaging==21.3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 首先安装Pytorch。建议版本和我一致,进入Pytorch官网,点击
install previous versions of PyTorch,以1.7.1为例,官网给出的安装如下,选择合适的cuda版本
# CUDA 11.0
pip install torch==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
# CUDA 10.2
pip install torch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2
# CUDA 10.1
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
# CUDA 9.2
pip install torch==1.7.1+cu92 torchvision==0.8.2+cu92 torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
# CPU only
pip install torch==1.7.1+cpu torchvision==0.8.2+cpu torchaudio==0.7.2 -f https://download.pytorch.org/whl/torch_stable.html
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 安装完Pytorch后,再运行
pip install -r requirements.txt
- 1
- 下载MobileNetV3-Small权重至datas下
- Awesome-Backbones文件夹下终端输入
python tools/single_test.py datas/cat-dog.png models/mobilenet/mobilenet_v3_small.py --classes-map datas/imageNet1kAnnotation.txt
- 1
1. 数据集制作
1.1 标签文件制作
-
将项目代码下载到本地
-
本次演示以花卉数据集为例,目录结构如下:
├─flower_photos │ ├─daisy │ │ 100080576_f52e8ee070_n.jpg │ │ 10140303196_b88d3d6cec.jpg │ │ ... │ ├─dandelion │ │ 10043234166_e6dd915111_n.jpg │ │ 10200780773_c6051a7d71_n.jpg │ │ ... │ ├─roses │ │ 10090824183_d02c613f10_m.jpg │ │ 102501987_3cdb8e5394_n.jpg │ │ ... │ ├─sunflowers │ │ 1008566138_6927679c8a.jpg │ │ 1022552002_2b93faf9e7_n.jpg │ │ ... │ └─tulips │ │ 100930342_92e8746431_n.jpg │ │ 10094729603_eeca3f2cb6.jpg │ │ ...

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 在
Awesome-Backbones/datas/中创建标签文件annotations.txt,按行将类别名 索引写入文件;
daisy 0
dandelion 1
roses 2
sunflowers 3
tulips 4
- 1
- 2
- 3
- 4
- 5

1.2 数据集划分
- 打开
Awesome-Backbones/tools/split_data.py - 修改
原始数据集路径以及划分后的保存路径,强烈建议划分后的保存路径datasets不要改动,在下一步都是默认基于文件夹进行操作
init_dataset = 'A:/flower_photos'
new_dataset = 'A:/Awesome-Backbones/datasets'
- 1
- 2
- 在
Awesome-Backbones/下打开终端输入命令:
python tools/split_data.py
- 1
- 得到划分后的数据集格式如下:
├─...
├─datasets
│ ├─test
│ │ ├─daisy
│ │ ├─dandelion
│ │ ├─roses
│ │ ├─sunflowers
│ │ └─tulips
│ └─train
│ ├─daisy
│ ├─dandelion
│ ├─roses
│ ├─sunflowers
│ └─tulips
├─...
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
1.3 数据集信息文件制作
- 确保划分后的数据集是在
Awesome-Backbones/datasets下,若不在则在get_annotation.py下修改数据集路径;
datasets_path = '你的数据集路径'
- 1
- 在
Awesome-Backbones/下打开终端输入命令:
python tools/get_annotation.py
- 1
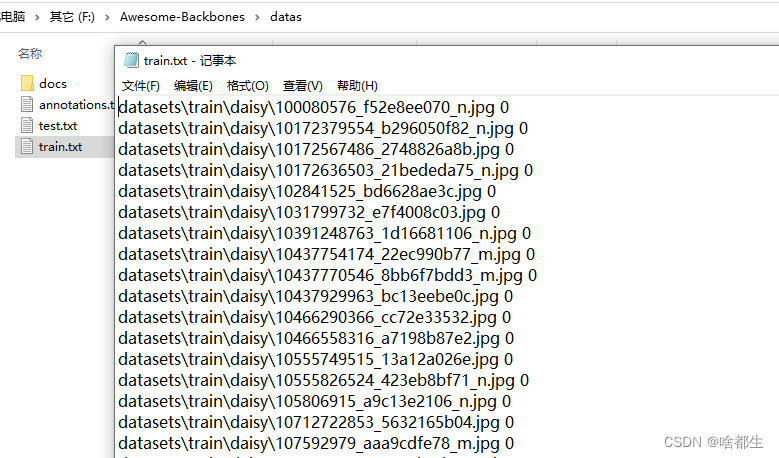
- 在
Awesome-Backbones/datas下得到生成的数据集信息文件train.txt与test.txt
2. 修改参数文件
-
每个模型均对应有各自的配置文件,保存在
Awesome-Backbones/models下 -
由
backbone、neck、head、head.loss构成一个完整模型 -
找到SEResNet参数配置文件,可以看到
所有支持的类型都在这
-
在
model_cfg中修改num_classes为自己数据集类别大小 -
按照自己电脑性能在
data_cfg中修改batch_size与num_workers -
若有预训练权重则可以将
pretrained_weights设置为True并将预训练权重的路径赋值给pretrained_weights -
若需要冻结训练则
freeze_flag设置为True,可选冻结的有backbone, neck, head -
在
optimizer_cfg中修改初始学习率,根据自己batch size调试,若使用了预训练权重,建议学习率调小 -
学习率更新详见视频教程
-
更具体配置文件修改可参考配置文件解释
3. 训练
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下train.txt与test.txt与annotations.txt对应 - 选择想要训练的模型,在
Awesome-Backbones/models/下找到对应配置文件,以SEResNet50为例 - 按照
配置文件解释修改参数 - 在
Awesome-Backbones打开终端运行
python tools/train.py models/seresnet/seresnet50.py
- 1

4. 评估
- 确认
Awesome-Backbones/datas/annotations.txt标签准备完毕 - 确认
Awesome-Backbones/datas/下test.txt与annotations.txt对应 - 在
Awesome-Backbones/models/下找到对应配置文件 - 在参数配置文件中
修改权重路径,其余不变
ckpt = '你的训练权重路径'
- 1
- 在
Awesome-Backbones打开终端运行
python tools/evaluation.py models/seresnet/seresnet50.py
- 1

- 单张图像测试,在
Awesome-Backbones打开终端运行
python tools/single_test.py datasets/test/dandelion/14283011_3e7452c5b2_n.jpg models/seresnet/seresnet50.py
- 1

至此完毕,实在没运行起来就去B站看我手把手带大家运行的视频教学吧~
5. 其他教程
除开上述,我还为大家准备了其他一定用到的操作教程,均放在了GitHub项目首页,为了你们方便为也粘贴过来
有任何更新均会在Github与B站进行通知,记得Star与三连关注噢~

