
- 1【Android Studio程序开发】常用布局--线性布局LinearLayout_android studio linearlayout布局
- 2基础课5——垂直领域对话系统架构_垂直领域问答对话实现方法
- 3WPF RichTextBox的常用方法和属性(内容的读取/导入等)_wpf richtextbox 中超链接获取输入的值
- 4SI,SIS,SIR,SEIRD模型_si模型
- 5simpleitk打开dicom文件
- 6diffusion model原理和算法伪代码_diffusion loss
- 7国产中间件概述
- 8solidity Dapp ERC20添加即空投合约_erc20代币能不能加入联盟链
- 9自动化机器学习AutoML之flaml:利用flaml框架自动寻找最优算法及其对应最佳参数python
- 10速递|AI搜索引擎Perplexity AI再获融资7000万美元,估值达5.2亿美元
ChatGPT的前生: Prompting思想
赞
踩
Prompt的思想是语言模型通往真正大一统的关键一步 。
ChatGPT目前大火,然而不少人对于ChatGPT的前辈---Prompt范式却不了解。希望通过本文,可以让读者对Prompt范式所蕴含的思想有所了解。本文不侧重细节的讲解,而重点突出Prompt范式背后的思想和启发。
1. Prompting: NLP的最新范式
Prompting, 又称in-context learning,指的是“预训练-Prompt"这一NLP最新的范式,也属于Parameter Efficient(参数高效)学习方法的一种,但是把Prompting仅仅理解为Parameter Efficient学习方法我只能说格局小了。要理解Prompting的精髓,还是要从更高层面开始。
我先抛出这样一句话:
之前的范式下产生的模型从本质上决定了无法在任务级别拥有泛化能力,而Prompting在任务级别具有泛化能力,对之前的NLP范式降维打击。

说回NLP的预训练-微调范式:预训练模型主要使用大规模的非特定任务场景的语料进行训练,在微调步骤,使用特定领域的语料去对模型的参数进行精细调整,使得最终的模型可以很好地解决当前领域的问题。大量的研究工作已经表明:预训练+微调的范式可以大幅超越只使用特定任务数据训练的模型。这也很好理解;在潘小小:【NLP预训练】深入理解“预训练”语言模型这篇文章中,我用一句话简单概括了:
“使用尽可能多的训练数据,从中提取出尽可能多的共性特征,从而能让模型对特定任务的学习负担变轻。“
研究人员很快发现预训练模型的性能和模型的大小有关;简单地说,就是模型越大效果越好。但这样就带来了一个问题:传统的微调需要更新所有的模型参数,这显然训练效果并不会很好,因为很多时候和预训练模型的规模相比,特定任务的那点数据显然少得可怜。此外,当人们把微调好的模型用到线上的时候,问题又来了:每个任务甚至每个领域都需要单独部署一个微调好的模型,显然很不经济实惠。
于是研究人员提出了部分参数微调/冻结部分参数的方法:我们可以采用关于模型参数分布的先验知识---模型的某些部分有特定的功能(或者说,偏向特定的功能)。比方说:Transformer模型用在机器翻译时,Encoder部分负责将源语言编码成高维向量,Decoder部分负责生成目标语种中的对应意思的句子。有了类似这样的假设之后,在微调模型的参数时,我们就可以利用这些先验知识,只更新和目标任务最相关的那部分。这样做的好处:(1)训练更快、更有针对性、效果也往往更好(2)部署的时候可以多个任务/领域共用一个背景预训练模型,只需针对每个任务/领域替换被更新的部分参数即可。
在上述”部分参数微调“方法的基础之上,研究人员提出了Adapter方法[1]。通过添加一个灵活的即插即用的可训练适配模块(Adaper Module),我们可以改变模型某一层(或某几层)的数据分布,从而让模型可以适用于各种各样的任务和领域。典型的做法就是每一任务或者每一领域对应了一个Adapter Module,训练的时候只更新对应任务Adapter的参数,推理的时候激活对应任务/领域的Adapter,其它任务/领域的Adapter直接忽视。和”部分参数微调“方法相比,Adapter方法的优势有(1)更轻量级(2)同样比例的参数效果更好。
以上方法都是基于”预训练-微调“的范式的方法,无论多么轻量级,每个任务都还是有一套特定的参数(即使大部分参数可以共享)。说到这里,大多数人其实并没有意识到,它的致命缺点正是:任务本身需要人为进行定义。但是现实生活中的知识,并不是完全地按照任务进行分类的,现实中大多数任务会涉及到多个任务的能力: 比如一个中国人阅读了一篇英文的文章,最后用中文写了个总结 --- 这就涉及到 翻译+总结 两个任务。
而Prompting可以做到模糊任务的界限---不需要人为对任务进行划分,相反,任务的描述会作为输入的一部分直接输入预训练模型。这其实就是为什么Prompting范式是”通往真正大一统语言模型的关键一步“。
下图摘录自一篇Survey:Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing[2]
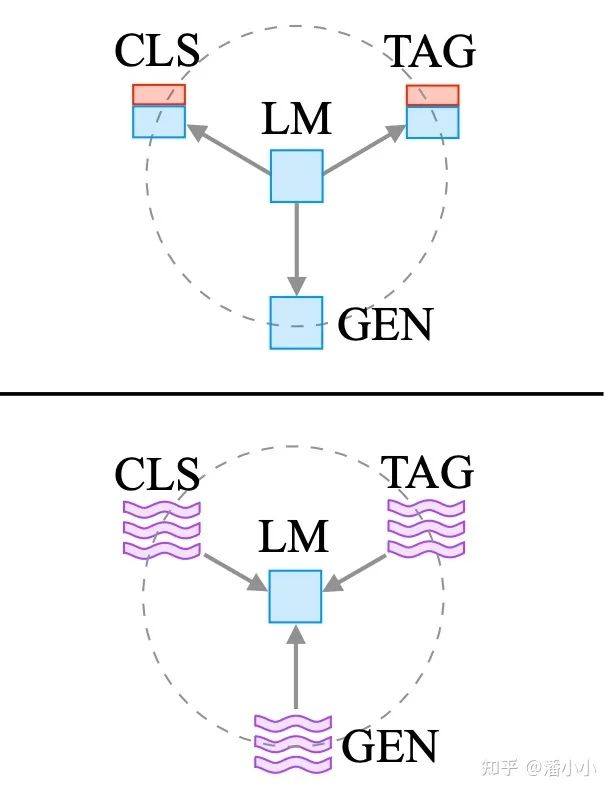
2. Prompting是什么
Prompting方法最初是在2020年和GPT-3[3]一同提出来的。Prompt范式认为预训练模型本身就可以完成很多任务,只需要在输入的时候对模型进行引导(又称:提供context)即可。怎么引导呢?其实很简单,最开始的Prompt版本只需要用自然语言将任务本身进行描述,将任务变为”填空“(针对双向模型BERT)或者”生成“(针对自回归模型GPT)的任务即可。举几个简单的例子:
文本情绪分类任务:任务本身的目的是任意输入一段文本,预测对应的情绪(正面、负面、中性)。经典的预训练-微调范式下的做法是:将在预训练模型的基础上增加分类器模块,使用特定任务数据进行微调分类器模块。在遇到输入“今天天气很好”时,模型输出“正面”。而在Prompt范式下,我们可以将如下文字直接输入没有经过微调的模型: "今天天气很好,我的心情是[MASK]的" ==> [MASK]预测值是"开心”,再将“开心”映射为"正面"就很容易了。
机器翻译任务:任务本身的目的是输入一种语言的一段文本,模型生成另一种语言的同义句。在Prompt范式下,我们可以将如下文字输入模型:“翻译成英语:今天天气真好”==>模型输出“This is a good day.”
从上面的例子中我们很容易看出Prompt范式有如下特点:它无需特定领域的数据进行训练就可以用于各项NLP任务,并且无需在模型参数上做任何调整。Prompt的成功证明了在模型和训练数据量大到一定程度时,模型本身就更接近“百科全书”,而Prompt就是将“百科全书”里的知识金矿挖掘出来的各种钥匙。

3. Prompting方法分类
Prompt从大类来分,可以分为(1)手工Prompt (2)参数化Prompt。
手工Prompt就是上面提到的“对任务进行自然语言描述”的方法。主要分为“Prefix Prompt"和”Cloze Prompt“,其中"Prefix Prompt"一般针对生成式NLP任务(NLG),而Cloze Prompt针对理解式NLP任务(NLU) (p.s. 如果不了解什么是生成式NLP、什么是理解式NLP,强烈建议看看潘小小:【NLP预训练】深入理解“预训练”语言模型 的第3章:NLU任务的预训练 VS NLG任务的预训练)
Prefix Prompt举个例子就是上述提到的机器翻译任务的模板。其实在多语言机器翻译领域广泛使用很多年的language indicator(又称language id)就可以看作是一种Prefix prompt。
Cloze Prompt举个例子就是上述提到的文本情绪分类任务的模板。
参数化Prompt也叫"自动Prompt",主要分为离散Prompt和连续Prompt。所谓“离散”,指的是候选的Prompts依然是自然语言的词;所谓“连续”,指的是Prompts本身不需要是自然语言的序列,而可以是词表中的token的任意组合,甚至可以引入不在原来词表中的token。其中比较出名的就是Prefix Tuning[4]:在input层添加一串连续的向量(拥有独立embedding的新token)前缀,同时在每个hidden layer对应添加相同长度的前缀(这一步不引入额外参数,但是略微修改了模型结构)。训练时对每个独立的任务做分别的参数更新。需要注意的是,在下游任务上进行训练时,只有Prefix对应的Embedding参数进行更新。
Prompt Tuning[5]在Prefix Tuning的基础上进一步做了简化,每个hidden layer不再需要对应添加相同长度的前缀,因此模型结构完全没有改变,只是多了prefix token对应的embedding参数(大概占模型总参数的0.1%)。Prompt Tuning也因此更加灵活。

4. Prompt效果&总结
说了这么多,Prompt范式的效果怎么样?又有哪些重要结论呢?
预训练-Prompt能达到和预训练-微调相当的效果,即使可训练参数缩减了1000倍
模型的规模是决定性因素:模型越大,prompting的模型效果越好
对任务有泛化能力,即few-shot / zero-shot能力强
具体的效果可以去看几篇论文:MULTITASK PROMPTED TRAINING ENABLES ZERO-SHOT TASK GENERALIZATION[6], The Power of Scale of Parameter-Efficient Prompt Tuning[4], Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? [7]
5. 为什么Prompting可以演化出ChatGPT?
说了这么多,相信大家也都明白了为什么Prompting技术可以演化出ChatGPT这个好东西。
【一句话总结】Prompting技术突破了对”任务“的常规定义,使得复合任务的实现成为可能(也就是研究人员常说的”zero-shot")。大家可以回想一下,日常生活中大多数“任务”都不是常规NLP中一个个分门别类的子任务,因此Prompting这种无视任务本身的能力才是它演化出ChatGPT的根本。
ChatGPT使用的基础模型是GPT-3.5,就已经达到惊人的效果,而研发中的GPT-4参数量是GPT-3.5的几百倍……
Prompting 和 ChatGPT的诞生和成功实际上宣告了新时代的开始:NLP那些人为定义的针对子任务的独立研究将慢慢淡出历史舞台。
Reference
AI Box专栏:NLP新宠——浅谈Prompt的前世今生
GitHub - thunlp/PromptPapers: Must-read papers on prompt-based tuning for pre-trained language models.
参考
1. ^Parameter-Efficient Transfer Learning for NLP https://arxiv.org/pdf/1902.00751.pdf
2. ^Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing https://arxiv.org/abs/2107.13586
3. ^Language Models are Few-Shot Learners https://arxiv.org/pdf/2005.14165.pdf
4. ^abPrefix-Tuning: Optimizing Continuous Prompts for Generation https://arxiv.org/abs/2101.00190
5.^The Power of Scale for Parameter-Efficient Prompt Tuning https://aclanthology.org/2021.emnlp-main.243/
6.^Multitask Prompted Training Enables Zero-Shot Task Generalization https://arxiv.org/abs/2110.08207
7.^Rethinking the Role of Demonstrations: What Makes In-Context Learning Work? https://arxiv.org/abs/2202.12837
来源:知乎
作者:潘小小,亚马逊应用科学家
END
分享
收藏
点赞
在看


