
- 1实用篇 | 做自己的管理系统 :Pycharm+django+mysql_做管理系统要用到django吗
- 2贝叶斯神经网络对梯度攻击的鲁棒性
- 3第三讲 知识抽取与挖掘I_面向结构化的知识抽取是什么
- 4MISCONF Redis is configured to save RDB snapshots, but is currently not able to persist on disk
- 5[翻译Pytorch教程]NLP从零开始:使用字符级RNN进行姓名分类_nlp from scratch: classifying names with a charact
- 6c++优先队列(priority_queue)小顶堆 大顶堆_priority_queue默认大顶堆
- 7css设置文字铺满盒子
- 8全国计算机等级考试二级MS Office考试大纲(2023版)_计算机二级考试的考纲
- 9基于深度学习的木材表面缺陷检测系统(网页版+YOLOv8/v7/v6/v5代码+训练数据集)
- 10在Idea里,执行npm命令 : 无法加载文件 ***\Nodejs\node_global\npm.ps1,因为在此系统上禁止运行脚本_无法加载文件 nodejs\node_global\react-native.psl
数据库面试题总结——DBA面试battle指南_dba 面经
赞
踩
目录
xtrabackup和flush table with read lock
MYSQL查询缓存、change buffer、doublewrite buffer
前言
2年前数据库原理方面的东西学的比较多,广撒网面试了很多家公司,那个时候感觉自己的面试技术还是不错的,能跟面试官在数据库技术方面聊很久。
不过最近面了1家公司,只面了一家···基本是裸面,从忙碌的工作状态立马切换到面试,很多以前可以聊的比较清晰的技术发现自己不知道咋说了。我也没刷过题,很多问题是自己研究甚至写过文章的,答不上来确实非常可惜。所以这里写这篇文章,总结一下DBA面试比较喜欢问的问题和回答方式。
至今为止,主修oracle、mysql、pg、redis、tidb,问题和解答都围绕这几个库进行。
数据库复制
oracle和pg的同步原理
oracle的DG和pg的流复制都是采用的物理复制,原理上是类似的,将主库上发生变更的数据块redo(或wal)传递给从库应用。
oracle和pg复制进程有不同:
oracle:LGWR(传递redo)->RFS(接收redo)->MRP(应用redo)
pg:walsender(传递wal)->walreceiver(接收wal)->startup(recover wal)

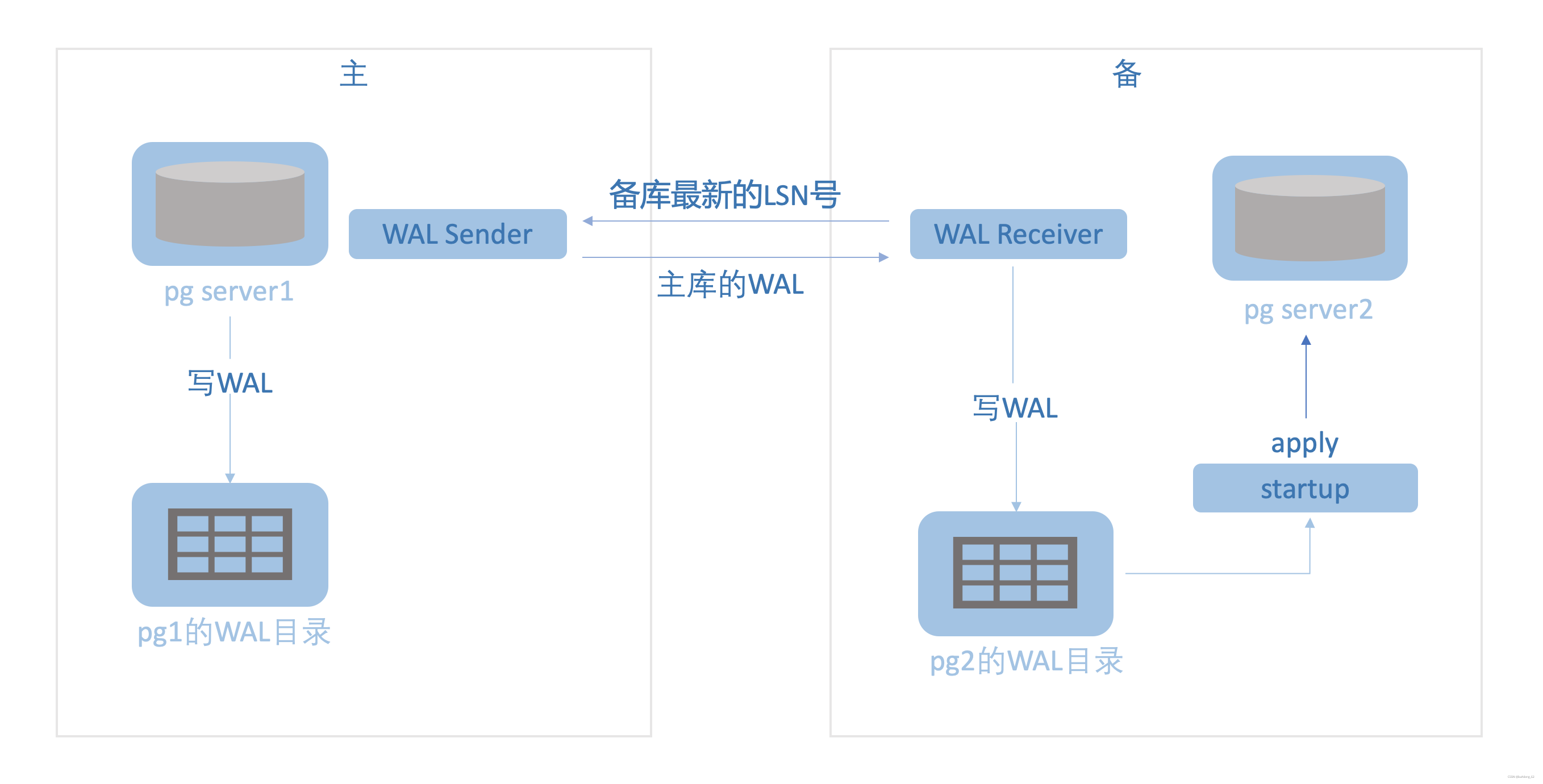
另外,oracle可以配置fal_server , 备库主动到主库拉取日志,这个是其他库做不到的。
mysql的同步原理
很多面试官非常喜欢问复制原理问题,特别是mysql。mysql的主从复制确实足够特殊。mysql也是有redo的,但是mysql不是用redo来传递日志的,而是用binlog。binlog是一种逻辑数据变更日志,记录了行的变更,不是物理变更日志。

(oracle的图是官网的,pg和mysql的图是我不同时期画的···搞的花里胡哨的将就看吧~)
mysql主库的dump线程将binlog传递给从库的IO线程,从库IO线程负责写入binlog数据至relay log文件,从库的sql线程读取relay log文件并在从库上重放
mysql的GTID
GTID是binlog中的事物ID,没有binlog就没有GTID,GTID是递增的用于在binlog中标识一个已提交的事务(mysql实例中事务ID transaction ID也用于标识事务,但是在开启事务的时候就有,跟binlog也没有太大关系)
在数据库没有打开GTID的情况下,备库只有通过pos(position,字节号)找到需要同步的开始时间点。pos同步可能会有问题,因为binlog和relay不一定是一一对应的,log号不一定对应,pos也不一定对应。但是如果开启GTID同步,备库中断只需要找到GTID即可恢复同步
主从架构如何保证数据不丢失
oracle的保护模式
oracle有3种保护模式:最大保护模式、最大可用模式、最大性能模式
最大保护模式:主备库必须都提交事务,事务才可以完成。备库延迟主库不可以单独写入。这种模式可以做到数据0丢失,缺点是备库状态会极大影响主库写入
最大可用模式:如果备库正常,为最大保护模式;如果备库失去连接,切换为最大性能模式
最大性能模式:主库只管发送日志,备库是否接到、写入不会影响主库写入。这个模式最常见
pg的日志传输模式
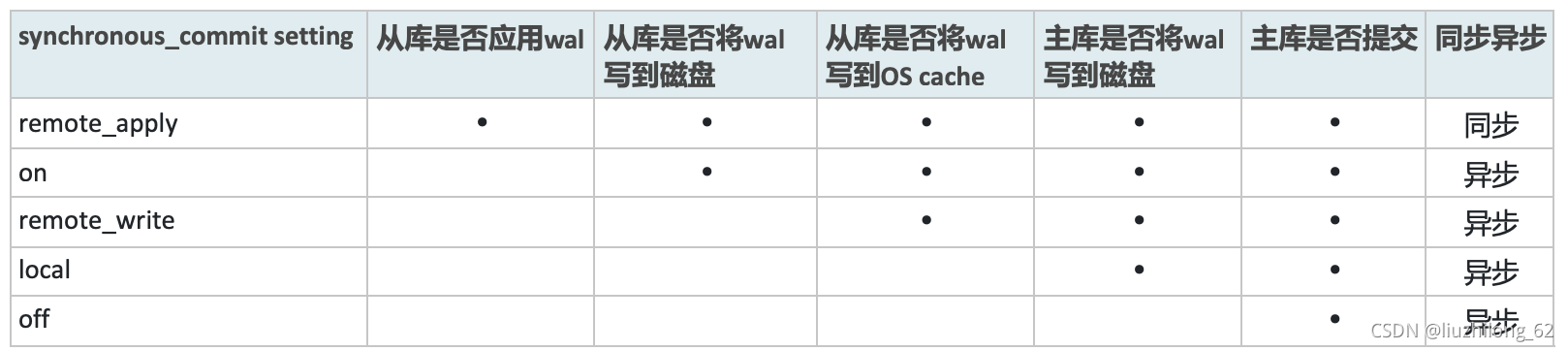
pg主从有5种模式,由synchronous_commit 参数控制
remote_apply:从库已应用了wal,主库才可以提交。这种模式主从是同步的。类似最大保护模式
on:default。主从的wal都写到磁盘上时,主库提交。类似半同步,不会丢数据。
remote_write:备库接收到wal并将wal日志写到文件系统cache上时,主库提交。此时从库的接收到wal但是还没有落盘,如果操作系统crash,会丢失数据。
local:主库wal刷到磁盘时提交。这种模式是异步的,主库不需要确认备库状态就可以提交。
off:本机wal没有刷到磁盘就可以提交,存在数据丢失风险,不推荐。
mysql同步模式
mysql有3中同步模式:全同步、半同步、异步
全同步复制:全同步一般通过组复制实现,需要安装group_replication插件。这种模式下同组的mysql实例需要都写入才能提交
半同步复制:半同步需要安装rpl_semi_sync插件。这种模式下主库只需要确认从库把日志写入到relaylog即可提交,不需要从库也应用日志
异步复制:默认模式,主库只负责传输日志,不管从库状态如何都可以正常提交
从库只读
oracle的只读
oracle备库只读时,被称为ADG,11g开始支持,需要以read only模式打开备库
pg的只读
pg流复制本身就可以查看从库数据,不需要设置什么。但是由于pg的mvcc特性,从库有查询冲突的问题。
查询冲突最常见的场景:从库正在查询表数据,此时主库vacuum了一个表,这个vacuum同步到从库,这时到底是应用vacuum清理死元组,还是保证查询事务继续执行就是一个问,这就是查询冲突。hot_standby_feedback可以发送从库xmin给主库,主库可以不执行vaccum,但是可能造成主库vacuum执行延迟问题。还有一些参数可以缓解查询冲突,但是都不能彻底解决问题。
mysql的只读
mysql本身是逻辑从库,从库甚至可以写入,一般会给从库设置readonly参数,此时外部连接从库时只读
索引结构和寻迹
说到索引结构,必须说说表存储模式。pg和oracle都是采用堆表存储,堆表数据一般都在磁盘上连续。mysql采用聚簇索引存储表,表必须有主键,表数据库以主键的顺序存储(这种结构就是oracle里的索引组织表IOT)
B+树索引
最最常见的索引就B+树索引。B+树索引可以帮助快速检索数据
mysql聚簇索引结构:

聚簇索引是一种数据结构,相当于以索引的方式管理数据。mysql在建表时如果不显示建主键的话会用隐式主键,这个主键就是用来构造聚簇索引的。
索引寻迹
聚簇索引的寻迹方式:root(主键范围)->分支节点(主键范围)->叶节点(主键和行数据)
先找到聚簇索引的root节点,通过root存放的主键范围找到分支节点,通过分支节点的主键范围找到叶节点,而叶节点上便是存储的主键和对应的行数据
oracle和mysql二级索引的结构也是B+树,但是叶节点存储的内容不同。oracle索引叶节点存储的是索引键和rowid;mysql二级索引叶节点存储的是索引键和主键
oracle索引寻迹方式:root(索引键范围)->分支节点(索引键范围)->叶节点(索引键和rowid)
先找到索引root节点,通过root存放的索引键范围找到分支节点,通过分支节点的索引键范围找到叶节点,而叶节点上存储索引键和rowid,rowid就是数据行的物理地址
mysql二级索引寻迹方式:root(索引键范围)->分支节点(索引键范围)->叶节点(索引键和主键)---->聚簇索引寻迹
先找到二级索引的root节点,通过索引键范围找到分支节点,通过分支节点的索引键范围找到叶节点,而叶节点上存储索引键和主键,然后通过主键再回到聚簇索引,再走一遍聚簇索引寻迹。
索引覆盖扫描:sql语句要找的数据列刚好都在索引叶节点上。
对于oracle来说,索引覆盖扫描的意思是不需要通过rowid找数据块,我们常说不用rowid回表。
对于mysql来说,只有二级索引有索引覆盖扫描。聚簇索引本身就存储数据了所以不存在索引覆盖扫描的说法,聚簇索引肯定是cover所有数据列的。对于二级索引来说,索引覆盖扫描表示不返回聚簇索引。二级索引的索引覆盖扫描会减少很多IO。
索引全扫描:
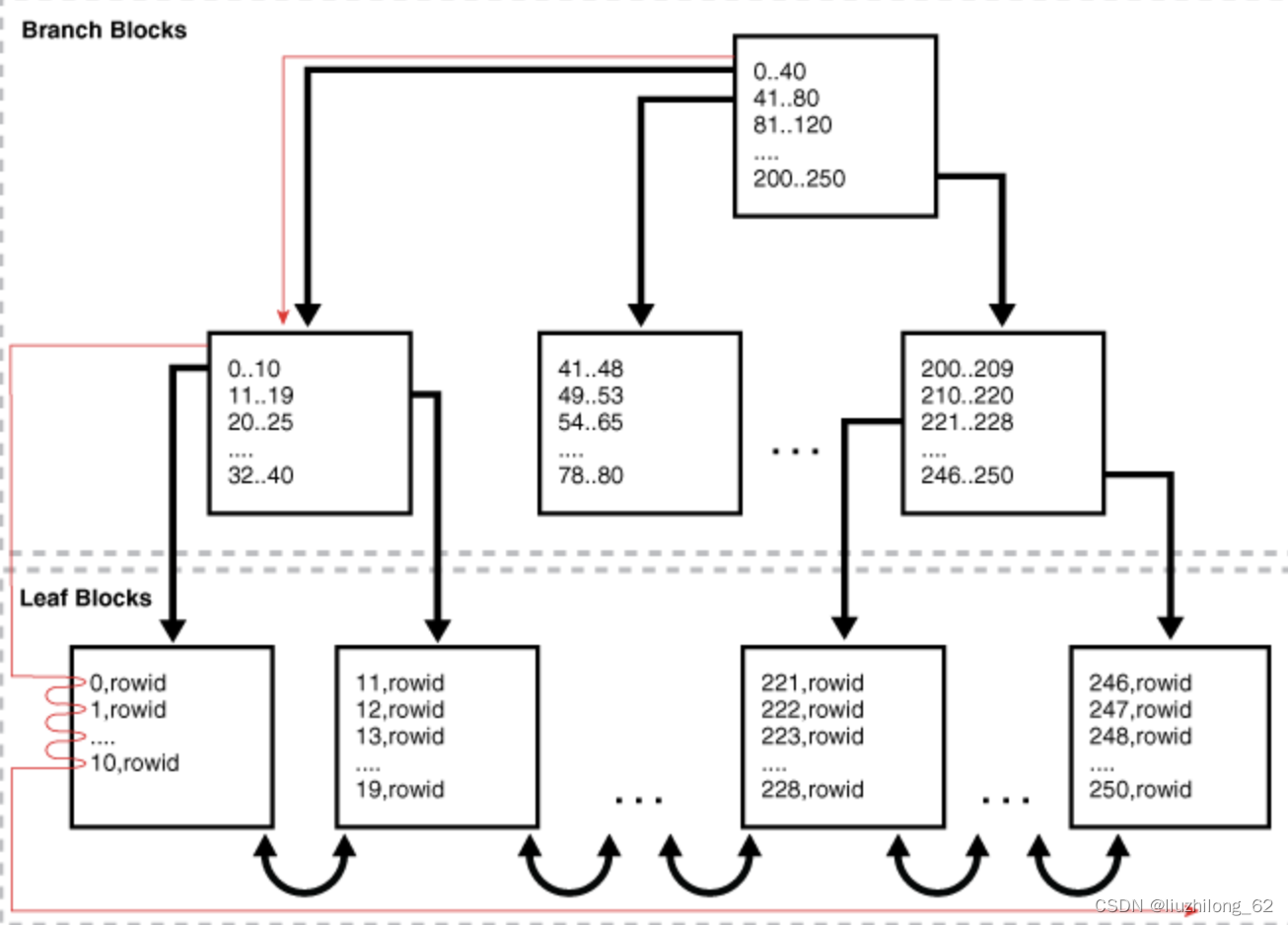
索引全扫描寻迹方式:root节点->分支节点->叶节点->叶节点->叶节点->...
索引全扫描通过B+树索引叶节点的双向链表访问索引数据。因为索引是顺序的,所以索引全扫描的结果是有序的,一般发生在扫描范围较大且有排序的情况下
索引快速全扫描:索引快速扫描通过找到索引段的第一个块以磁盘顺序扫描索引所有叶节点。
索引快速全扫描不会经过索引结构访问索引数据,这种访问不是以索引本身逻辑顺序访问的,是以磁盘存储顺序访问,所以索引扫描结果是无序的。索引快速扫描可以使用多块读访问,可以减少IO访问次数,这也是索引快速访问的目的。
索引跳跃扫描:当sql没有索引前导列时,访问索引的效率还是好一点的话,可以使用索引跳跃扫描
在访问索引时,组合索引的前导列优先排序,优先过滤,所以也建议前导列用选择率较高的字段。在没有前导列时优化器一般都会直接访问表,但是也仍然可以访问索引。因为索引本身优先按前导列排序,非前导列分散到各个索引节点上排序,所以不过滤前导列而通过非前导列访问时,会扫描几乎全部索引节点,从而导致索引跳跃扫描访问效率一般都非常差。
索引范围扫描、索引唯一扫描 都比较简单,原理就是B+树寻迹,不过多介绍
绑定执行计划
hint
hint其实不算绑定执行计划,它只是对sql执行路径做出指引,并且sql文本本质上还是发生了变化,一般用于dba调试执行计划的时候。有时候也会用于应用比较好改sql文本的场景。
oracle和mysql的hint比较好使用,关键是pg的hint实在想吐槽~
pg使用hint需要安装插件。而且亲身经历pg hint很不好用,很多情况下无法走hint。pg官方也说postgresql数据库不会原生支持hint,因为使用hint是业务不懂优化的结果。OMG撒豆敢说
我肯定是hint的拥趸,hint对于搞优化的dba来说太重要了。优化器不可能100%没有差错,也基本没有业务在系统全生命周期的角度考虑sql优化,没有人能保证一条sql跑100年不出问题。
绑定执行计划的方法
oracle绑定执行计划最常用的是sql profile和SPM。sql profile在10g以前常用,可以将想要的sqlplan hash vaue导入sqlprofile。官方也提供了coe_xfr_sql_profile.sql 的脚本甚至可以自己编写outline,帮助绑定执行计划。11g以后SPM使用更加广泛,它可以管理多个执行计划而不是仅仅是替换一个执行计划。
mysql、pg都没有绑定执行计划的方法,只能用于hint
tidb可以绑定执行计划,逻辑比较简单,但是他能。
数据库备份
热备原理和一致性
在oracle中rman在线备份数据库,在备份过程中数据一直在改变,每一次变更都会更新数据块中的scn号,(scn单调递增,每一次事务都会增加scn的值,就是数据库完全没有事务,scn仍然会增加),只要在备份开始时的redo日志(归档)存在,那么在恢复时oracle可以找到那些在备份过程中变更的数据块,通过redo块去进行更新,这就是追归档的机制。如果没有归档,可以通过resetlog打开restore出来数据库,这个库就有可能丢失数据。
mysql的xtrabackup、postgresql的basebackup都是类似的,物理备份保障一致性需要先备份redo(or wal)日志,在备份数据的过程中持续备份日志。
xtrabackup和flush table with read lock
flush table with read lock可以看成两个部分功能,flush table和read lock。
flush table会将所有内存中的脏数据刷到磁盘。内存中存在大量脏数据会延时刷盘时间,在刷完所有内存中的脏数据后,xtrabackup再执行mysiam表的备份(包括mysiam元数据和mysiam表数据)、innodb元数据备份,备份完才会unlock tables。所以mysiam表的数据大小、内存中的脏数据量、数据字典的大小决定了锁数据库的时间。
如何减少read lock的时间?
- 禁止应用使用mysiam表。dml更新数据时会锁整个mysiam表,所以这种表已经不适合现在的业务需求了。mysiam表是mysql server本身自带的,系统表有一部分就是mysiam表,这些表一般都不会太大。
- flush table with read lock会获取读锁等待所有锁的释放,等待所有事物(包括select)执行完,所以备份前最好先处理长事物。如果长事务没有解决,xtrabackup会一直获取不到read lock锁,拖长备份时间。
- 在执行备份前,先手动执行一次flush tables。这样可以减少xtrabackup内部的flush时间,也就减少了flushtable with read lock到unlock tables的时间段。
- mysql库中的对象数不宜过多,这样可以减少lock期间frm,myi等的备份时间
- 对xtrabackup进行优化,细化锁的粒度。在备份innodb表时,备份完innodb的frm就可以解锁innodb表了,不用在等待mysiam表备份完才解锁。先解锁innodb表可以减少业务停机时间。
增量备份和快追踪
增量备份
oracle rman在增量备份时,会扫描数据库的所有块。增量备份命令中的需要指定scn号,rman会找到大于该scn号的块并进行备份,这些块就是做过变更的块,恢复时将备份出来的变更块直接覆盖即可。
rman、xtrabackup、pg_probackup都支持增量备份。pg_basebackup不支持增量备份。
快追踪
oracle数据库可以开启块跟踪特性。当打开块跟踪特性后,oracle数据库会记录上次全备以来所有变更的块的地址,再增量备份时,rman就不需要扫描所有块去寻找变更块了,直接可以从数据库中找到变更块,直接进行备份,这样可以大量减少增量备份时的时间。这个特性在数据量特别大的数据库中会使用,因为扫描所有块的时间成本太高,在xtts迁移中一般都会开启该功能以减少每次追增量的时间。
xtrabackup有XtraDB Changed Page Tracking功能。xtrabackup会追踪块的变化,并记录到bitmapfiles中,同样可以减少找到变更页的时间。是xtraDB存储引擎才有的功能,innodb不支持。
所以,mysql、pg、tidb、OCEANBASE都不支持块追踪。
MVCC机制
ORACLE,mysql的mvcc
在rc模式下,oracle和mysql都可以通过undo块生成数据前镜像达到多版本并发控制的目的。
pg的mvcc
pg没有undo。pg在tuple中的x_min用于控制事务可见性规则
ORACLE解析
父游标、子游标、缓存游标
父游标、子游标存放在library cache中,缓存游标在pga中
父游标存放sql文本,子游标存放sql的执行计划,绑定变量等。一个sql可以有多个执行计划。
硬解析、软解析、软软解析
硬解析:在当前会话的 PGA 中找不到匹配的缓存会话游标,在 SGA 的库缓存(Library Cache)中没有找到匹配的父游标或是找到了匹配的父游标没有找到对应子游标。那么 oracle 就会重新开始解析该目标 SQL,那么 Oracle 就会新生成一个会话游标和一对共享游标(即父游标和子游标)解析目标 SQL,这种方式为硬解析
软解析:在当前会话的 PGA 中找不到匹配的缓存会话游标,但在库缓存中找到了匹配的父游标和子游标,那么 Oracle 会新生成一个会话游标并重用刚刚找到的父游标和子游标,直接调用解析树和执行计划解析目标 SQL,这种方式我们称之为软解析。
软软解析:当命中PGA中的会话游标时,跳过解析的过程直接拿到执行计划执行sql语句
ORACLE GAP如何恢复
- oracle主库会主动发送日志给备库
- 如果主库没有再传日志而导致日志延迟,配置fal_sever参数备库可以主动到主库拉日志
- 如果主库的日志已经删除了,可以把备份中的归档日志恢复到备库,rman配置catalog使备库知道恢复的归档路径,备库就可以recover日志
- 如果备份也没有了,可以在主库上做增量备份,然后在备库恢复,继续同步日志
MYSQL查询缓存、change buffer、doublewrite buffer
查询缓存
query cache是一个内存池,用于缓存select语句的sql文本和结果集,当后面有相同的sql语句时(且表的数据未发生改变),mysql仅做语法和权限验证,然后会跳过解析、优化器、接口调用、innodb执行的阶段,直接到查询缓存中把对应的结果集返回给会话。相同sql是指sql文本完全一样,且没有变量和类似now()这样的函数。只要表有变动,qc就会被flush。qc也不支持分区表
表有数据更新时,qc会flush数据,如果qc size较大会消耗资源,对于交易类等频繁数据变更的业务不建议打开qc
change buffer
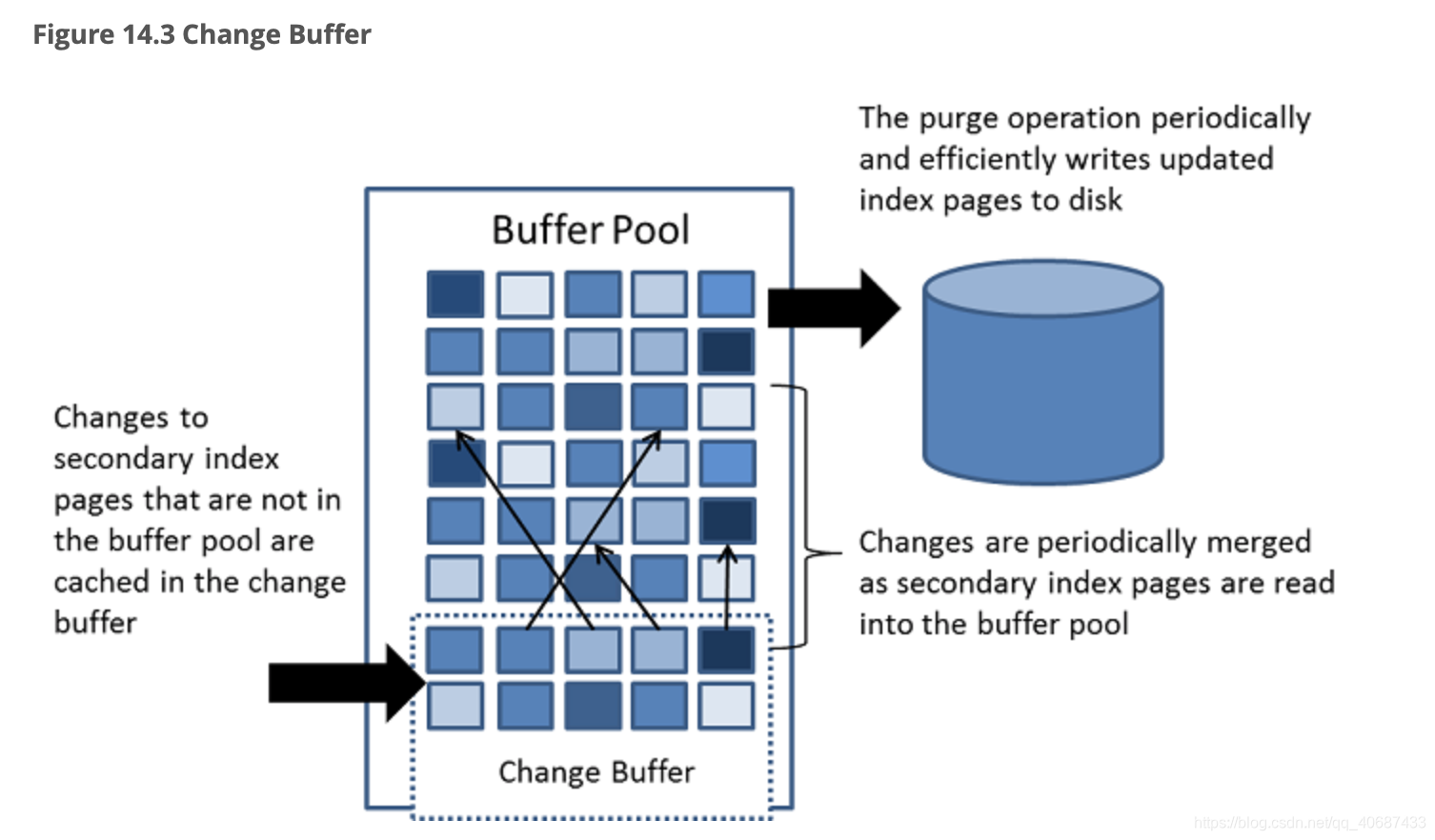
写缓冲区缓存那些不在buffer pool中但是变更了的二级索引页,这些变更来自DML语句。当有读操作时,相关页会合并并转移到buffer pool中。change buffer的目的是减少随机IO,顺序的写入二级索引,而不是每次都立即写入。change buffer以前叫insert buffer。
doublewrite buffer
共享表空间是ibdata文件中的划分出2M连续的空间,专门给double write刷脏页使用的。修改后的脏页先放到double write buffer区,等buffer空间满了,或者其他条件触发之后,再将double write buffer存的脏页写到共享表空间,之后再写入数据文件中。倘若,因为故障发生导致写入数据文件页数据不完整,则可以通过加载共享表空间中完整的页进行覆盖,数据页变得完整,再通过应用redo log进行恢复,数据就不会因此缺失
性能上doublewrite会占用10%左右的IO性能
oracle、pg都是没有doublewrite的,只有mysql有
mysql IO调度机制
pg和oracle IO调度知识点
pg和oracle其实也涉及到部分内容,但是基本都不会问。
关于pg、oracle的IO仍需要记住几点
- pg没有DIO,只能经过磁盘
- ORACLE ASM默认是DIO,但是trace文件是经过缓存的
mysql的IO调度机制
linux有内存结构叫页高速缓冲区,数据在写数据到文件系统时就会一般会经过这个页高速缓冲区。mysql参数innodb_flush_method用于控制mysql IO调用机制,它常用的值包括fsync、o_dsync、o_direct
- fsync:将特定的页高速缓冲区的数据刷到磁盘
- DIRECT IO:数据均直接在用户地址空间的缓冲区和磁盘之间直接进行传输,完全不需要页缓存。意思就是直接写到磁盘不经过操作系统缓存
- 同步IO:同步IO在接收到IO请求后不会返回任何信息,当写入完成后才会返回写入完成。在完成之前IO程序不可以做其他任务。
- 异步IO:进程发出数据传输请求之后,进程不会被阻塞,也不用等待任何操作完成,进程可以在数据传输的时候继续执行其他的操作。相对于同步访问文件的方式来说,异步访问文件的方式可以提高应用程序的效率,并且提高系统资源利用率。直接 I/O 经常会和异步访问文件的方式结合在一起使用
强烈推荐我之前写的文章,mysql IO控制_liuzhilong_62的博客-CSDN博客,对mysql IO调度机制作了详细说明。有位老面试官还问过我fsync和fdatasync的区别,我摸索着记忆回答了。
MYSQL都有什么锁
server端有表锁、元数据锁(DML)等
innodb有7种锁:共享锁和排他锁、意向锁、插入意向锁、自增锁、记录锁 、间隙锁 、临键锁
其中
- 记录锁,相当于行锁
- 间隙锁,只在rr模式下存在,锁住行数据的间隙GAP
- 临键锁,只在rr模式下存在,是间隙锁+记录锁
- rr模式下,临键锁会锁住“小于范围的最大存在值和大于范围的最小存在值”。如果没有实际存在值,innodb会给临键锁“超大值”或“超小值”去锁一个大范围。所以在某些情况下,一个update可以锁住整张表
redis
rdb和AOF
rdb相当于一次将内存中的可以全部dump下来,有业务影响
AOF会把key的变更写进aof文件,并定期对变更记录做合并已减少恢复时间和磁盘空间占用
rdb和aof文件都会消耗一定的IO,对于redis这种响应要求极高的缓存业务场景可能会有影响。所以一般都把落盘操作放在备库执行,或者根本不落盘对于很多业务也是可行的方案。
redis集群加减节点
redis集群通过redis-trib内置工具管理。redis共有16384个slot,每个slot一般都较平均的存放keys。在集群中slot会被分配在不同的节点上,在减节点时需要先移动slot上的key,然后再删除节点;在加节点时需要先加节点,再转移slot。在转移key时需要考虑大key的转移,因为大key转移较慢可能导致转移命令超时,此时slot状态需手动修复。
参考资料
mysql查询缓存_mysql 查询缓存_liuzhilong_62的博客-CSDN博客
MySQL索引原理_mysql索引原则_Dobbin Soong的博客-CSDN博客
index full scan/index fast full scan以及B+树索引_kevin_linshaojie的博客-CSDN博客
【Oracle】硬解析、软解析和软软解析_程序猿的向往的博客-CSDN博客
MySQL技术:InnoDB存储引擎关键特性之double write_mysql double write_陌隋的博客-CSDN博客
innodb锁详解_liuzhilong_62的博客-CSDN博客
xtrabackup的简单理解_xtarbackup_liuzhilong_62的博客-CSDN博客
xtrabackup的flush table with read lock_liuzhilong_62的博客-CSDN博客
mysql xtrabackup热备和oracle rman热备的区别_xtrabackup比rman_liuzhilong_62的博客-CSDN博客
mysql IO控制_liuzhilong_62的博客-CSDN博客
change buffer的概念与相关配置_changebuffer_liuzhilong_62的博客-CSDN博客
buffer pool内存结构、LRU、刷脏页机制详解_liuzhilong_62的博客-CSDN博客
mysql刷盘机制详解_liuzhilong_62的博客-CSDN博客
主流数据库主从复制差异——oracle、mysql、mongo、redis、oceanbase_redis和oracle的区别_liuzhilong_62的博客-CSDN博客

